Download as pdf or txt
You might also like
- Mechanical and Metal Trades Handbook PDFDocument432 pagesMechanical and Metal Trades Handbook PDFmorcego151061100% (1)
- Level 3 B37-9021Document1 pageLevel 3 B37-9021chrisNo ratings yet
- 16 DE OCTUBRE DEL 2021 ANTEPROYECTO HUANUCO-ModelDocument1 page16 DE OCTUBRE DEL 2021 ANTEPROYECTO HUANUCO-ModelErwin EleraNo ratings yet
- Razvan 2 ParterDocument1 pageRazvan 2 ParterMaria MateiNo ratings yet
- Pieza AirtecDocument1 pagePieza AirtecFaustoNo ratings yet
- Plano de Viv. Segunda Planta PDFDocument1 pagePlano de Viv. Segunda Planta PDFRivera Quispe , MiltonNo ratings yet
- 7.baza e Katit 111Document1 page7.baza e Katit 111burimNo ratings yet
- R717 NH3 AmmoniaDocument1 pageR717 NH3 Ammoniaas9900276No ratings yet
- Proyecto Discoteca Actualizado 08-01-23Document1 pageProyecto Discoteca Actualizado 08-01-23Jhoz Alexander Cantos LitumaNo ratings yet
- Valve PDFDocument1 pageValve PDFJim TsikasNo ratings yet
- Diseño EstructuralDocument1 pageDiseño EstructuralKevin Angos H.No ratings yet
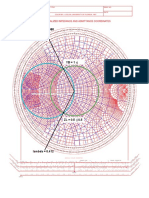
- Lambda 0.088: Normalized Impedance and Admittance CoordinatesDocument1 pageLambda 0.088: Normalized Impedance and Admittance CoordinatesAndrés VallejoNo ratings yet
- PRIMERDocument1 pagePRIMERPercy Sucno TorreNo ratings yet
- Juni 2021 Opg 1 - Log - P - HDocument1 pageJuni 2021 Opg 1 - Log - P - HkombarespamNo ratings yet
- Plano 8Document1 pagePlano 8Kerly RamirezNo ratings yet
- Port RodamientDocument1 pagePort RodamientVilca Carrera DvcNo ratings yet
- 쎲 SP AF28-75mm F/2.8 XR Di LD Aspherical (IF) Macro (Model A09)Document2 pages쎲 SP AF28-75mm F/2.8 XR Di LD Aspherical (IF) Macro (Model A09)Erick Maciel AmezcuaNo ratings yet
- Cimentacion PDFDocument1 pageCimentacion PDFDeysi Cajo GómezNo ratings yet
- Cimentacion PDFDocument1 pageCimentacion PDFDeysi Cajo GómezNo ratings yet
- Arbore Cotit DesenDocument1 pageArbore Cotit DesenIonel Bogdan NeacșuNo ratings yet
- plantaDocument1 pageplantaVictor FernandoNo ratings yet
- Contactos Pa SorrentoDocument1 pageContactos Pa SorrentoOriana RodríguezNo ratings yet
- Reporting VerbsDocument10 pagesReporting VerbsAchmad RNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978Document1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 19-09-04 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978Trần ViệtNo ratings yet
- R717Document1 pageR717Thu Hoài Nguyễn ThịNo ratings yet
- NH3 PDFDocument1 pageNH3 PDFvi văn tâmNo ratings yet
- Appendix A Statistical Tables and ChartsDocument9 pagesAppendix A Statistical Tables and ChartsPilar de la CruzNo ratings yet
- Fala El PDF Gaaaaaa 1Document1 pageFala El PDF Gaaaaaa 1andrecutimbo24No ratings yet
- PH AmoniacoDocument1 pagePH AmoniacoLeonardo AndresNo ratings yet
- SLD 02 Lock Plate 430Document1 pageSLD 02 Lock Plate 430Stefan MilojevicNo ratings yet
- TDOT SR 70 StudyDocument66 pagesTDOT SR 70 StudyAnonymous ROc32R1gNo ratings yet
- Soal WSC CNC Milling Tahun 2001,2005,2007Document9 pagesSoal WSC CNC Milling Tahun 2001,2005,2007adichNo ratings yet
- Piston 80 MMDocument1 pagePiston 80 MMNegreteg MarioNo ratings yet
- A.02 Plan Parter 2Document1 pageA.02 Plan Parter 2AidaPopescuNo ratings yet
- Etaj 1: Sala de ClasaDocument1 pageEtaj 1: Sala de ClasaMaria MateiNo ratings yet
- 2 49 PDFDocument2 pages2 49 PDFBeny SimpsonNo ratings yet
- 7 Anéis: Egberto Gismonti Adaptação Daniel Murray 76Document8 pages7 Anéis: Egberto Gismonti Adaptação Daniel Murray 76Gustavo Mendes100% (1)
- Ex 1Document1 pageEx 122010732No ratings yet
- ACDC - Problem-ChildDocument5 pagesACDC - Problem-ChildJean CUADNo ratings yet
- Sup - Effect of Refinement and Production Technology On The Molecular Composition of Edible Cottonseed Oils From A Large Industrial Scale ProductionDocument7 pagesSup - Effect of Refinement and Production Technology On The Molecular Composition of Edible Cottonseed Oils From A Large Industrial Scale ProductionumrbekfoodomeNo ratings yet
- DTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 10-11-07 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978Document1 pageDTU, Department of Energy Engineering S in (KJ/ (KG K) ) - V in (M 3/kg) - T in (ºC) M.J. Skovrup & H.J.H Knudsen. 10-11-07 Ref:R.Döring. Klima+Kälte Ingenieur Ki-Extra 5, 1978Willian SouzaNo ratings yet
- Smith Chart 02Document1 pageSmith Chart 02api-3764170No ratings yet
- SLD 02 Guide 430Document1 pageSLD 02 Guide 430Stefan MilojevicNo ratings yet
- Cimentaciones de 5ta Maria-ModeloDocument1 pageCimentaciones de 5ta Maria-Modelomiguel rosasNo ratings yet
- Hydraulic Mobile Pick N' Carry CraneDocument2 pagesHydraulic Mobile Pick N' Carry CranesaranrajNo ratings yet
- Earl Scruggs - Will The Circle Be UnbrokenDocument1 pageEarl Scruggs - Will The Circle Be UnbrokenJonathan BrunoNo ratings yet
- LKS2019 TP07 M2Document1 pageLKS2019 TP07 M2riscaawalia08No ratings yet
- ACM - Ug Rev.01Document24 pagesACM - Ug Rev.01Marcelo Almeida0% (1)
- Minor Rag: The Brooklyn SessionDocument3 pagesMinor Rag: The Brooklyn Sessionmatiaszloto4118No ratings yet
- SituacijaDocument1 pageSituacijaErlang dooNo ratings yet
- Taras PHD Full2011Document329 pagesTaras PHD Full2011Seymur AkbarovNo ratings yet
- CremonaDocument1 pageCremonaProductos HERSANo ratings yet
- Generalized Nonconvex Nonsmooth Low-Rank MinimizationDocument8 pagesGeneralized Nonconvex Nonsmooth Low-Rank MinimizationSourish SarkarNo ratings yet
- Ground FloorDocument1 pageGround Floor200407459No ratings yet
- Fatimah Osamah 200407459Document2 pagesFatimah Osamah 200407459200407459No ratings yet
- Decir Adios Decir Adios: Amen AmenDocument2 pagesDecir Adios Decir Adios: Amen AmenRRodas BulejeNo ratings yet
- Casa rodDocument1 pageCasa rodMadara LpNo ratings yet
- Gus CarroDocument1 pageGus CarroAlexis Juarez VelazquezNo ratings yet
- Machine Afzar Shams: Bearing HousingDocument8 pagesMachine Afzar Shams: Bearing HousingmasoodkamaliNo ratings yet
- Core 422Document1 pageCore 422Stefan MilojevicNo ratings yet
- PocketCAS ManualDocument27 pagesPocketCAS Manualccouy123No ratings yet
- TDH - Records and Information Management Training UpdatedDocument57 pagesTDH - Records and Information Management Training UpdatedSunshine CupoNo ratings yet
- Cover Letter For Addendum NO.3Document31 pagesCover Letter For Addendum NO.3AbelNo ratings yet
- 2.1.1 HTCZ452750 - A Control Cable ListDocument4 pages2.1.1 HTCZ452750 - A Control Cable ListViswanathPvNo ratings yet
- Introduction To Computational Fluid DynamicsDocument3 pagesIntroduction To Computational Fluid DynamicsJonyzhitop TenorioNo ratings yet
- ThisbeDocument6 pagesThisbeHelenNo ratings yet
- MDT V8i Intro To Microstation ExtDocument180 pagesMDT V8i Intro To Microstation Extbojanb171No ratings yet
- ERP Project Discussion With MR Srikanth - 1Document2 pagesERP Project Discussion With MR Srikanth - 1ambady_mmNo ratings yet
- Ssp005 Module 2 Monitoring and Mentoring p1 Sas - Docx 1Document2 pagesSsp005 Module 2 Monitoring and Mentoring p1 Sas - Docx 1Maria AnngelouNo ratings yet
- Stage 2 EvidenceDocument1 pageStage 2 Evidenceyoonyohan4486No ratings yet
- G For SAPDocument76 pagesG For SAPbonuanuNo ratings yet
- What The Fortune 500 ReadDocument264 pagesWhat The Fortune 500 Readnafiz100% (2)
- Fundamental of Nursing SyllabusDocument4 pagesFundamental of Nursing Syllabusabunab1983No ratings yet
- Great Essays in Science (Gnv64)Document442 pagesGreat Essays in Science (Gnv64)Chrome Picasso100% (2)
- Acp 856Document14 pagesAcp 856Maria SuterNo ratings yet
- Autocad Command Aliases, Page 1 Filename: C:/Users/Minpc-02/Appdata/Roaming/Autodesk/Autocad 2013 - English/R19.0/Enu/SuDocument8 pagesAutocad Command Aliases, Page 1 Filename: C:/Users/Minpc-02/Appdata/Roaming/Autodesk/Autocad 2013 - English/R19.0/Enu/SujimmycabreraNo ratings yet
- Safety Committee ConstitutionDocument3 pagesSafety Committee ConstitutionHarsh VaidyaNo ratings yet
- Dunn and Goodnights Model 3Document9 pagesDunn and Goodnights Model 3Julia Lopez100% (4)
- Measures of Central Tendency & Dispersion ExamplesDocument7 pagesMeasures of Central Tendency & Dispersion ExamplesJuliana IpoNo ratings yet
- Hs Cornell Notes PoweDocument13 pagesHs Cornell Notes PoweC Derick VarnNo ratings yet
- Lesson 3 Classifying OrganismsDocument33 pagesLesson 3 Classifying OrganismsosamaNo ratings yet
- Dell OptiPlex 9030 AIO Spec Sheet PDFDocument2 pagesDell OptiPlex 9030 AIO Spec Sheet PDFKahlil SmithNo ratings yet
- Level 8 Diploma in Strategic Management and LeadershipDocument3 pagesLevel 8 Diploma in Strategic Management and LeadershipGibsonNo ratings yet
- Form 5 Chapter 2 ElectricityDocument7 pagesForm 5 Chapter 2 Electricitykhangsiean890% (1)
- Module 16 Siebel Data ModelDocument21 pagesModule 16 Siebel Data Modelfreecharge100% (1)
- Guidance and CounsellingDocument21 pagesGuidance and CounsellingKomala Manimaran100% (1)
- Building A Web Store With Struts & ADF FrameworksDocument132 pagesBuilding A Web Store With Struts & ADF Frameworksapi-3771999100% (1)
- DocDocument2 pagesDocKeshav YadavNo ratings yet
- Dilbert 2002 PDFDocument122 pagesDilbert 2002 PDFapi-374402983% (6)