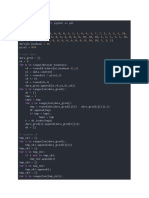
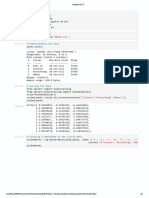
Download as pdf or txt
You might also like
- Model Assisted Survey SamplingDocument8 pagesModel Assisted Survey SamplingAnonymous UE1TSL0% (4)
- qbus 5001 quiz 答案Document30 pagesqbus 5001 quiz 答案Lijun ZhengNo ratings yet
- MinutelyDocument1 pageMinutelyAnonymous CDd9eukAxNNo ratings yet
- AGNES and SPECTRAL CLUSTERING IN R PDFDocument1 pageAGNES and SPECTRAL CLUSTERING IN R PDFSahas ParabNo ratings yet
- Program 4 Lu Decomposition C ProgrammingDocument13 pagesProgram 4 Lu Decomposition C ProgrammingPraveen DNo ratings yet
- Punto1 - Taller - Ipynb - ColaboratoryDocument4 pagesPunto1 - Taller - Ipynb - ColaboratoryYardlenis SanchezNo ratings yet
- Runge Kutta 4 Order - With - Solution PDFDocument4 pagesRunge Kutta 4 Order - With - Solution PDFhuma razaNo ratings yet
- Prison Break S01E01 Pilot 720p BluRay x265-HaxxOrDocument51 pagesPrison Break S01E01 Pilot 720p BluRay x265-HaxxOrPatoSilvaNo ratings yet
- Prison Break S01E01 Pilot 720p BluRay x265-HaxxOrDocument51 pagesPrison Break S01E01 Pilot 720p BluRay x265-HaxxOrPatoSilvaNo ratings yet
- Runge-Kutta: Numerical Solving MethodDocument7 pagesRunge-Kutta: Numerical Solving MethodKundan AnandNo ratings yet
- Assignment No-3Document12 pagesAssignment No-3Prashant DhandeNo ratings yet
- BabaDocument9 pagesBabaapi-285777244No ratings yet
- Data Mining ProjectDocument33 pagesData Mining ProjectRavi RanjanNo ratings yet
- Excel para Parcial 01Document63 pagesExcel para Parcial 01Diego SanFerNo ratings yet
- Analisis Dinamico Eje XDocument24 pagesAnalisis Dinamico Eje XVICTOR MANUEL PAITAN MENDEZNo ratings yet
- ARIMA Predict ForecastDocument1 pageARIMA Predict ForecastManoj MNo ratings yet
- Responsi PJJ 25 April 2022-2st1-Anareg PDocument9 pagesResponsi PJJ 25 April 2022-2st1-Anareg Pvnoyy icebearNo ratings yet
- 20BCE1205 Lab8Document13 pages20BCE1205 Lab8SHUBHAM OJHANo ratings yet
- Nps Table Welded Seamless Stainless Steel PipeDocument3 pagesNps Table Welded Seamless Stainless Steel PipeOmar HasounNo ratings yet
- Example FRPpyDocument150 pagesExample FRPpyf puglieseNo ratings yet
- Steel TestingDocument19 pagesSteel TestingNazishNo ratings yet
- Google - Colab Pyspark - Ml.classification Pyspark - Context Pyspark - Sql.sessionDocument3 pagesGoogle - Colab Pyspark - Ml.classification Pyspark - Context Pyspark - Sql.sessionDarpan SarodeNo ratings yet
- 2023-01-15Document15 pages2023-01-15Ali iNo ratings yet
- Kenpave 1Document1 pageKenpave 1Hizbawi SisayNo ratings yet
- Output - Group - Work - Project - 4652 - GWP1.ipynb - ColaboratoryDocument6 pagesOutput - Group - Work - Project - 4652 - GWP1.ipynb - ColaboratoryGaurav ChakrabortyNo ratings yet
- M0519064 - Muhammad Syahru Aulia - 4Document4 pagesM0519064 - Muhammad Syahru Aulia - 4SalimulhadiNo ratings yet
- DL Output Ass2Document5 pagesDL Output Ass2Ayush PayalNo ratings yet
- Divergencia PDFDocument8 pagesDivergencia PDFDuane AliagaNo ratings yet
- Jeffrey Williams (20221013) 3Document21 pagesJeffrey Williams (20221013) 3JEFFREY WILLIAMS P M 20221013No ratings yet
- Chapter 6. Product Limit Stimator Peter Smith: Required LibrariesDocument9 pagesChapter 6. Product Limit Stimator Peter Smith: Required LibrariesYosef GUEVARA SALAMANCANo ratings yet
- Midas Gen: Project TitleDocument5 pagesMidas Gen: Project TitleGooddayBybsNo ratings yet
- Data Science Comp 2Document13 pagesData Science Comp 2tobiasNo ratings yet
- SollicitationsDocument3 pagesSollicitationsjoseph diomNo ratings yet
- Useful ScriptsDocument3 pagesUseful ScriptsAjay KumarNo ratings yet
- Portico - Solucion - Numerica: 1 Matriz de Rigidez de Los Elementos y La EstructuraDocument4 pagesPortico - Solucion - Numerica: 1 Matriz de Rigidez de Los Elementos y La EstructuraWilockNo ratings yet
- Ps AuxDocument11 pagesPs AuxAndrei AndrewNo ratings yet
- ESO205P ASSIGNMENT 1: Report Name-Ashish Kumar Roll: 180148Document19 pagesESO205P ASSIGNMENT 1: Report Name-Ashish Kumar Roll: 180148Vrahant NagoriaNo ratings yet
- Page RankDocument2 pagesPage Rankdse22119082No ratings yet
- Shutdown Profile.1Document1 pageShutdown Profile.1Valentina VenturaNo ratings yet
- Multiple RegressionDocument4 pagesMultiple Regressionpedropinto8400No ratings yet
- Spectrum Data Print Report: Wavelength Nm. Rawdata ..Document12 pagesSpectrum Data Print Report: Wavelength Nm. Rawdata ..Camilo MartinezNo ratings yet
- Spectrum Data Print Report: Wavelength Nm. Rawdata ..Document12 pagesSpectrum Data Print Report: Wavelength Nm. Rawdata ..Camilo MartinezNo ratings yet
- Contigencia 1Document3 pagesContigencia 1keveny2000No ratings yet
- Debarghya Das (Ba-1), 18021141033Document12 pagesDebarghya Das (Ba-1), 18021141033Rocking Heartbroker DebNo ratings yet
- 1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingDocument4 pages1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingAsmar HajizadaNo ratings yet
- 2 Numpy BasicsDocument14 pages2 Numpy BasicsGirraj DohareNo ratings yet
- SCL K05-MS-MOR - Pressure-0Document1 pageSCL K05-MS-MOR - Pressure-0kushalkaushalNo ratings yet
- TM Xime PGDM QT IDocument40 pagesTM Xime PGDM QT IRiya SinghNo ratings yet
- Data EntryDocument4 pagesData Entry2147033No ratings yet
- Jio Home LoaderDocument36 pagesJio Home LoaderKokiNo ratings yet
- 销售业绩提成表 根据业绩跳点1Document126 pages销售业绩提成表 根据业绩跳点1houzi3090No ratings yet
- Visualizing Correlations With Corrgrams - FontDocument10 pagesVisualizing Correlations With Corrgrams - FontSebastian Lar. 【ViolinxBass】No ratings yet
- 1 2-FramDocument8 pages1 2-Framkrishparakh23No ratings yet
- DATA SCIENCE IDC 302 End Sem ProjectDocument1 pageDATA SCIENCE IDC 302 End Sem Projectsoniakar3000No ratings yet
- Import As: Numpy NPDocument5 pagesImport As: Numpy NPGilang SaputraNo ratings yet
- Customer Churn in TelecomDocument9 pagesCustomer Churn in TelecomSubrahmanyam JonnalagaddaNo ratings yet
- ML ProjectDocument10 pagesML ProjectVaishnavi B VNo ratings yet
- Resultados SeparadosDocument692 pagesResultados SeparadosAlyssonFloresSoaresNo ratings yet
- 2 - Fourier - Transforms-Correction: 1 Lab 2: Fourier Transform and SpectrumDocument4 pages2 - Fourier - Transforms-Correction: 1 Lab 2: Fourier Transform and SpectrumCəvahir AğazadəNo ratings yet
- TJMod 4Document98 pagesTJMod 4Liew Wen JingNo ratings yet
- Codigo Ojiva de Horas para La FamiliaDocument5 pagesCodigo Ojiva de Horas para La FamiliaEVELYN DAIANA GALVIS ZARABANDANo ratings yet
- 1 Characteristics of Time Series 1.4 Stationary Time SeriesDocument15 pages1 Characteristics of Time Series 1.4 Stationary Time SeriesTrịnh TâmNo ratings yet
- 1 Characteristics of Time Series 1.2 Time Series Statistical ModelsDocument11 pages1 Characteristics of Time Series 1.2 Time Series Statistical ModelsTrịnh TâmNo ratings yet
- 1 Characteristics of Time Series 1.3 Measures of DependenceDocument10 pages1 Characteristics of Time Series 1.3 Measures of DependenceTrịnh TâmNo ratings yet
- 3 ARIMA Models - 3.1 Autoregressive Moving Average Models - 3.4.3 Forecasting ARMA ProcessesDocument8 pages3 ARIMA Models - 3.1 Autoregressive Moving Average Models - 3.4.3 Forecasting ARMA ProcessesTrịnh TâmNo ratings yet
- 2 Time Series Regression and Exploratory Data Analysis 2.3 Smoothing in The Time Series ContextDocument11 pages2 Time Series Regression and Exploratory Data Analysis 2.3 Smoothing in The Time Series ContextTrịnh TâmNo ratings yet
- 1 Characteristics of Time Series 1.5 Estimation of CorrelationDocument29 pages1 Characteristics of Time Series 1.5 Estimation of CorrelationTrịnh TâmNo ratings yet
- 1.1 The Nature of Time Series DataDocument19 pages1.1 The Nature of Time Series DataTrịnh TâmNo ratings yet
- TutorialDocument42 pagesTutorialRevathi BelurNo ratings yet
- WP AssignmentDocument6 pagesWP AssignmentVarunNo ratings yet
- Davison Full CVDocument18 pagesDavison Full CVVishnu Prakash SinghNo ratings yet
- CEE 201 Syllabus - 2012Document3 pagesCEE 201 Syllabus - 2012Khaldoun AtassiNo ratings yet
- Regression Models: 4.1 Literature ReviewDocument16 pagesRegression Models: 4.1 Literature ReviewBridge Iit At RanchiNo ratings yet
- Poisson Regression Analysis 136Document8 pagesPoisson Regression Analysis 136George AdongoNo ratings yet
- Hotel Spss DataDocument42 pagesHotel Spss Dataarshad alyNo ratings yet
- CV KurchinDocument6 pagesCV KurchinAnirudh NatarajanNo ratings yet
- Chapter 6Document9 pagesChapter 6Claire TaborNo ratings yet
- Structured Probabilistic Reasoning: (Incomplete Draft)Document495 pagesStructured Probabilistic Reasoning: (Incomplete Draft)Ariel MorgensternNo ratings yet
- Bluman 5th - Chapter 8 HW Soln For My ClassDocument11 pagesBluman 5th - Chapter 8 HW Soln For My Classbill power100% (1)
- CH10 Regression and Correlation TUTOR QDocument6 pagesCH10 Regression and Correlation TUTOR Qainafiqaa17No ratings yet
- Stat AssignmentDocument4 pagesStat AssignmentMaria ZenypherNo ratings yet
- STAT 3001/7301: Mathematical Statistics: Week 3 - Lecture 8Document20 pagesSTAT 3001/7301: Mathematical Statistics: Week 3 - Lecture 8Li NguyenNo ratings yet
- Project of SPSS: (Project No 01 3 Semester Fall-2018)Document19 pagesProject of SPSS: (Project No 01 3 Semester Fall-2018)MEHWASH ANSARNo ratings yet
- Biostat Chapter 1-7Document85 pagesBiostat Chapter 1-7Kassa GebreyesusNo ratings yet
- Linear Regression - Numpy and SklearnDocument7 pagesLinear Regression - Numpy and SklearnArala FolaNo ratings yet
- Solutions For Homework 4: Two-Way ANOVA: Response Versus Solution, DaysDocument13 pagesSolutions For Homework 4: Two-Way ANOVA: Response Versus Solution, DaysVIKRAM KUMARNo ratings yet
- ML 1Document51 pagesML 1DipNo ratings yet
- Al Ghurair University - 016 - Statistics - Final.substitutedocxDocument10 pagesAl Ghurair University - 016 - Statistics - Final.substitutedocxosama hasanNo ratings yet
- ESO 209: Probability and Statistics 2019-2020-II Semester Assignment No. 7Document18 pagesESO 209: Probability and Statistics 2019-2020-II Semester Assignment No. 7Adarsh BanthNo ratings yet
- 405 Econometrics: by Domodar N. GujaratiDocument47 pages405 Econometrics: by Domodar N. Gujaratimuhendis_8900No ratings yet
- Two-Sample Tests of Hypothesis: Prior Written Consent of Mcgraw-Hill EducationDocument26 pagesTwo-Sample Tests of Hypothesis: Prior Written Consent of Mcgraw-Hill EducationFrida ArifahNo ratings yet
- Core Banking Article ReviewDocument4 pagesCore Banking Article Reviewbiresaw birhanuNo ratings yet
- A. Probability Sampling 1. .Simple Random SamplingDocument3 pagesA. Probability Sampling 1. .Simple Random SamplingheyheyNo ratings yet
- Type I and Type II ErrorsDocument11 pagesType I and Type II ErrorsRetchelle Tejoso PremiaNo ratings yet
- Eckhardt TradingDocument30 pagesEckhardt Tradingfredtag4393No ratings yet
- Activity 1.0 - Statistical Analysis and DesignDocument22 pagesActivity 1.0 - Statistical Analysis and DesignJericka Christine AlsonNo ratings yet