Download as pdf or txt
You might also like
- Howl's Moving Castle PatternDocument18 pagesHowl's Moving Castle PatternCeleste100% (1)
- SQC Chapter 6 11Document39 pagesSQC Chapter 6 11qwert 12345No ratings yet
- Monte Carlo Simulations Using Matlab: Vincent Leclercq, Application Engineer Email: Vincent - Leclercq@Document29 pagesMonte Carlo Simulations Using Matlab: Vincent Leclercq, Application Engineer Email: Vincent - Leclercq@Shan DevaNo ratings yet
- New Microsoft Office Excel WorksheetDocument3 pagesNew Microsoft Office Excel WorksheethungvietleNo ratings yet
- Growth Chart - AchondroplasiaDocument8 pagesGrowth Chart - AchondroplasiaEva ArdianahNo ratings yet
- Global Customer Support Manager Salaries (Ogive) : Salary Range Frequency Class Limits Cumulative FrequencyDocument2 pagesGlobal Customer Support Manager Salaries (Ogive) : Salary Range Frequency Class Limits Cumulative FrequencyAdam ZafryNo ratings yet
- Global Customer Support Manager Salaries (Ogive) : Salary Range Frequency Class Limits Cumulative FrequencyDocument2 pagesGlobal Customer Support Manager Salaries (Ogive) : Salary Range Frequency Class Limits Cumulative FrequencyAdam ZafryNo ratings yet
- Y5 Autumn Block 3 WO2 Draw Line Graphs 2019Document2 pagesY5 Autumn Block 3 WO2 Draw Line Graphs 2019eddie zhouNo ratings yet
- Ogive ChartDocument1 pageOgive ChartjobsindiaconsultancybharattiwaNo ratings yet
- Determination of Corrosion Rate of The Carbon Steel in Atmospheric ExposureDocument4 pagesDetermination of Corrosion Rate of The Carbon Steel in Atmospheric ExposureForood TorabianNo ratings yet
- Ogive ChartDocument1 pageOgive ChartBharat TiwariNo ratings yet
- PercentagesDocument5 pagesPercentagesapi-333976163No ratings yet
- Mario Ages PDFDocument7 pagesMario Ages PDFNancy CarSanNo ratings yet
- Raul Garcia Zarate - Virgenes Del Sol (Guitar Pro)Document4 pagesRaul Garcia Zarate - Virgenes Del Sol (Guitar Pro)Cat CvNo ratings yet
- Elber Delaney Soares SantiagoDocument3 pagesElber Delaney Soares SantiagoelberdssantiagoNo ratings yet
- Elber Delaney Soares SantiagoDocument3 pagesElber Delaney Soares SantiagoelberdssantiagoNo ratings yet
- 4th Edition Ch4, AppliedDocument42 pages4th Edition Ch4, AppliedAthar Hussain TanwriNo ratings yet
- Mean 3.3 Mean 3.4 Mean 3.4Document8 pagesMean 3.3 Mean 3.4 Mean 3.4Hugo Pereira Da CostaNo ratings yet
- Chart 1Document4 pagesChart 1Gerald GarciaNo ratings yet
- Stained Glass Gates of ArgonathDocument43 pagesStained Glass Gates of Argonathyk85gfgp9vNo ratings yet
- Sem4 Group 1 - SQ Set 2Document48 pagesSem4 Group 1 - SQ Set 2melodysim2002No ratings yet
- Dashboard 2Document3 pagesDashboard 2Veallu JagadaseenNo ratings yet
- Lot h LorienDocument43 pagesLot h Lorienyk85gfgp9vNo ratings yet
- Sample Risk Assessment Form - AlternateDocument2 pagesSample Risk Assessment Form - AlternateMuhammadJamshaidIqbalNo ratings yet
- DeaSalsabila.J.22.23.ITDL - PESP.2022.TR-06.Data ProcessingDocument4 pagesDeaSalsabila.J.22.23.ITDL - PESP.2022.TR-06.Data ProcessingDea Salsabila siregarNo ratings yet
- Delta Green PC OliverasDocument1 pageDelta Green PC Oliveraszed2323No ratings yet
- 1571 Vata Well - Pile Driving Chart (29 07 2014)Document1 page1571 Vata Well - Pile Driving Chart (29 07 2014)tibismtxNo ratings yet
- Chart TitleDocument3 pagesChart TitlegieeNo ratings yet
- Ejemplo Tipo IIIDocument8 pagesEjemplo Tipo IIIGuille Wilburn HallNo ratings yet
- 1379 Vata Well - Pile Driving Chart (06 07 2014)Document1 page1379 Vata Well - Pile Driving Chart (06 07 2014)tibismtxNo ratings yet
- Ternary Diagram REV1Document6 pagesTernary Diagram REV1agus izzaNo ratings yet
- Gernot Hoffmann PS-Swatch CMYKDocument19 pagesGernot Hoffmann PS-Swatch CMYKchristian_kesselheimNo ratings yet
- Chart TitleDocument1 pageChart Titleanon_365067642No ratings yet
- Humidity Stability Test ChambersDocument5 pagesHumidity Stability Test ChambersCarlos ReisNo ratings yet
- ParticleDocument2 pagesParticlesumeetkug22No ratings yet
- BookDocument7 pagesBookbalajiNo ratings yet
- Curve V-T - Equivis ZS 15-22-32Document1 pageCurve V-T - Equivis ZS 15-22-32enricomolari76No ratings yet
- Applied Thermodynamics Lab GraphDocument2 pagesApplied Thermodynamics Lab GraphRana ZoraizNo ratings yet
- Salwa Othman 1973-01-01Document1 pageSalwa Othman 1973-01-01haluk bilginNo ratings yet
- Fractions and DivisionDocument4 pagesFractions and DivisionNuzulul HidayahNo ratings yet
- 3.sieve Analysis in Fine AggregateDocument1 page3.sieve Analysis in Fine AggregateLakshithaGonapinuwalaWithanageNo ratings yet
- 1374 Vata Well - Pile Driving Chart (07 07 2014)Document1 page1374 Vata Well - Pile Driving Chart (07 07 2014)tibismtxNo ratings yet
- 1368 Vata Well - Pile Driving Chart (06 07 2014)Document1 page1368 Vata Well - Pile Driving Chart (06 07 2014)tibismtxNo ratings yet
- SkyrimmappatternDocument14 pagesSkyrimmappatternJack KelleyNo ratings yet
- Field Trip ReportDocument9 pagesField Trip ReportChristina TauauveaNo ratings yet
- MHWI 1 HR Tokens 280x140mm FrontDocument1 pageMHWI 1 HR Tokens 280x140mm FrontPolski ZwierzuNo ratings yet
- Hanse 470 Polar DiagramDocument1 pageHanse 470 Polar DiagramAlzieNo ratings yet
- Pages From 0625 - s16 - QP - 42 - 06Document2 pagesPages From 0625 - s16 - QP - 42 - 06lelon ongNo ratings yet
- BMW 1200C - R850C 1200CDocument288 pagesBMW 1200C - R850C 1200COscar De Almeida VazNo ratings yet
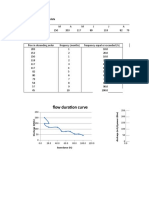
- Flow and Load Duration CurveDocument4 pagesFlow and Load Duration Curveyared sitotawNo ratings yet
- Method of Statement Instrumented MLT (Fibre)Document17 pagesMethod of Statement Instrumented MLT (Fibre)Syazu StylzerNo ratings yet
- CE 3510 Quiz 2 - SolutionsDocument3 pagesCE 3510 Quiz 2 - Solutionsnassim BenaissaNo ratings yet
- Diagrams and Graphs Part 4Document4 pagesDiagrams and Graphs Part 4masternote.777No ratings yet
- Financial Vs Physical PercentageDocument4 pagesFinancial Vs Physical PercentageRome GentaNo ratings yet
- # Bus 1-Feb 2-Feb 3-Feb 4-Feb 5-Feb 6-Feb 7-Feb 8-Feb 9-Feb ### 7 27 29 30 47 51 59 71 82 85 87 88 89 90 94 122 123 TC TotalDocument20 pages# Bus 1-Feb 2-Feb 3-Feb 4-Feb 5-Feb 6-Feb 7-Feb 8-Feb 9-Feb ### 7 27 29 30 47 51 59 71 82 85 87 88 89 90 94 122 123 TC Totalcristian caicedoNo ratings yet
- 24 Sep M1Document1 page24 Sep M1uday kumarNo ratings yet
- Risk Return and Capital Allocation To Risky AssetDocument39 pagesRisk Return and Capital Allocation To Risky AssetJay GuptaNo ratings yet
- Assignment 1 A. Problem A Language Teacher Taught Reading To A Group of Students at The Ninth Grade in TheDocument3 pagesAssignment 1 A. Problem A Language Teacher Taught Reading To A Group of Students at The Ninth Grade in TheCandra wirawNo ratings yet
- Plot Ternary DiagramDocument6 pagesPlot Ternary DiagramAnonymous QmT5xMPzGNo ratings yet
- Crisil Rating Default Study 2011Document28 pagesCrisil Rating Default Study 2011anilnair88No ratings yet
- Gini Indices and Two New Sparsity Measures and Their Applications To Machine Condition MonitoringDocument12 pagesGini Indices and Two New Sparsity Measures and Their Applications To Machine Condition MonitoringkNo ratings yet
- Economic GlobalizationDocument41 pagesEconomic GlobalizationMarjorie O. MalinaoNo ratings yet
- The Rapid Rise of Supermarkets?: W. Bruce TraillDocument12 pagesThe Rapid Rise of Supermarkets?: W. Bruce TraillDimitris SergiannisNo ratings yet
- Economist Globaization InequalityDocument2 pagesEconomist Globaization InequalityJuan Sebastián Sanchez100% (1)
- AD P M C L V P: EEP Robabilistic Odel For Ustomer Ifetime Alue RedictionDocument17 pagesAD P M C L V P: EEP Robabilistic Odel For Ustomer Ifetime Alue RedictionDounia SolaiNo ratings yet
- GR 11 Economics P1 (English) November 2022 Question PaperDocument13 pagesGR 11 Economics P1 (English) November 2022 Question Papersimphiwe dubeNo ratings yet
- Unit 3 Growth and Structural Change: 3.0 ObjectivesDocument17 pagesUnit 3 Growth and Structural Change: 3.0 ObjectivesDurgesh JhariyaNo ratings yet
- Chapter-7 Lovewell KPPDocument21 pagesChapter-7 Lovewell KPPAbid HossainNo ratings yet
- EI05 P21 ExamDocument17 pagesEI05 P21 ExamKhánh Đàm Nguyễn QuốcNo ratings yet
- Race, Equity and Inclusion in San Diego Febraury 10, 2017Document23 pagesRace, Equity and Inclusion in San Diego Febraury 10, 2017Ralph DimarucutNo ratings yet
- Gini CoefficientDocument8 pagesGini Coefficientgarinps@telkom.netNo ratings yet
- Markscheme: November 2016Document17 pagesMarkscheme: November 2016Jiwoo ChoiNo ratings yet
- The Spanish Fiscal Transition Tax Reform and Inequality in The Late Twentieth Century 1St Edition Sara Torregrosa Hetland Full ChapterDocument68 pagesThe Spanish Fiscal Transition Tax Reform and Inequality in The Late Twentieth Century 1St Edition Sara Torregrosa Hetland Full Chapterbarbara.ayers807100% (7)
- The Evils of GlobalizationDocument17 pagesThe Evils of GlobalizationDiego AndrésNo ratings yet
- Barro 2000 - Inequality and Growth in A Panel of CountriesDocument28 pagesBarro 2000 - Inequality and Growth in A Panel of Countriesbb_tt_AANo ratings yet
- An East Asian Model of Economic DevelopmentDocument34 pagesAn East Asian Model of Economic DevelopmentEdmund Khovey100% (1)
- 2-Iman WidhiyantoDocument36 pages2-Iman WidhiyantoIin Mochamad SolihinNo ratings yet
- Popov: Mixed Fortunes (2014)Document206 pagesPopov: Mixed Fortunes (2014)dusan.pavlovicNo ratings yet
- Comparing Power - An Appraisal of Comparative Government and PoliticsDocument90 pagesComparing Power - An Appraisal of Comparative Government and PoliticsSiddharth GianchandaniNo ratings yet
- DNL AfricaDocument6 pagesDNL AfricaGuillaume DiopNo ratings yet
- Socialist Fight No 10Document32 pagesSocialist Fight No 10Gerald J DowningNo ratings yet
- Supplementary Vol IIA - Research StudiesDocument1,237 pagesSupplementary Vol IIA - Research StudiesAbhishek SharmaNo ratings yet
- Jamaica Mental HealthDocument14 pagesJamaica Mental HealthSaniese GreenNo ratings yet
- University of Chicago ECON 20300 Problem SetDocument23 pagesUniversity of Chicago ECON 20300 Problem SetR. KrogerNo ratings yet
- Gasto CatastroficoDocument72 pagesGasto CatastroficoGuillermo AdrianzénNo ratings yet
- Week 9.1 - Welfare Policy and Income DistributionDocument30 pagesWeek 9.1 - Welfare Policy and Income DistributionPedro Almeida LoureiroNo ratings yet
- Regional Income Disparity in Indonesia - A Panel Data AnalysisDocument25 pagesRegional Income Disparity in Indonesia - A Panel Data AnalysisAzkaNo ratings yet
- Perceived Tensions and SynergiesDocument18 pagesPerceived Tensions and SynergiesAnusha SeelNo ratings yet
- Economic History of PakistanDocument27 pagesEconomic History of PakistanGulraiz Hanif100% (21)