Download as pdf or txt
You might also like
- EMC Tools Universe 3.2Document2 pagesEMC Tools Universe 3.2Biju ChandraboseNo ratings yet
- Ntjoin: Fast and Lightweight Assembly-Guided Scaffolding Using Minimizer GraphsDocument3 pagesNtjoin: Fast and Lightweight Assembly-Guided Scaffolding Using Minimizer GraphsjacorvarNo ratings yet
- Crop-Coordinated Panel Visualization For Biological Networks AnalysisDocument2 pagesCrop-Coordinated Panel Visualization For Biological Networks AnalysisJoel ArraisNo ratings yet
- Extracted Pages From An Overview of Multiple Sequence AlignmentsDocument6 pagesExtracted Pages From An Overview of Multiple Sequence AlignmentsCristina MendozaNo ratings yet
- 2021 Arxiv - TransGAN Two Transformers Can Make One Strong GANDocument13 pages2021 Arxiv - TransGAN Two Transformers Can Make One Strong GANFengShiNo ratings yet
- 1810 05997 PDFDocument15 pages1810 05997 PDFBlake XiaoNo ratings yet
- SCIBER A Simple Method For Removing Batch EffectsDocument8 pagesSCIBER A Simple Method For Removing Batch EffectsNealNo ratings yet
- Bulk Analyse RDocument7 pagesBulk Analyse R809600520No ratings yet
- 9 - AriDocument21 pages9 - AriNabila LabraouiNo ratings yet
- 1 s2.0 S131915782300099X MainDocument13 pages1 s2.0 S131915782300099X MainYahidNo ratings yet
- Engineering Science and Technology, An International JournalDocument11 pagesEngineering Science and Technology, An International JournalNader JalalNo ratings yet
- Fauna Image ClasificationDocument10 pagesFauna Image Clasificationanggun.pambudiNo ratings yet
- Comparation Analysis of Ensemble Technique With Boosting (Xgboost) and Bagging (Randomforest) For Classify Splice Junction Dna Sequence CategoryDocument10 pagesComparation Analysis of Ensemble Technique With Boosting (Xgboost) and Bagging (Randomforest) For Classify Splice Junction Dna Sequence CategoryFatrinaNo ratings yet
- Coupled Patch Alignment For Matching Cross-View GaitsDocument16 pagesCoupled Patch Alignment For Matching Cross-View Gaitswenhao zhangNo ratings yet
- And The Bit Goes DownDocument11 pagesAnd The Bit Goes Downgireesh123123No ratings yet
- Multi-Behavior Enhanced Heterogeneous Graph Convolutional Networks Recommendation Algorithm Based On Feature-InteractionDocument20 pagesMulti-Behavior Enhanced Heterogeneous Graph Convolutional Networks Recommendation Algorithm Based On Feature-Interactiongholamalinejad69No ratings yet
- Tao Et Al. - 2020 - MGAT Multimodal Graph Attention Network For RecomDocument11 pagesTao Et Al. - 2020 - MGAT Multimodal Graph Attention Network For Recomrivob45206No ratings yet
- 12329-Article Text-15857-1-2-20201228Document8 pages12329-Article Text-15857-1-2-20201228anuNo ratings yet
- Image Compression Using Single Layer Linear Neural Networks: Procedia Computer ScienceDocument8 pagesImage Compression Using Single Layer Linear Neural Networks: Procedia Computer SciencejuanNo ratings yet
- 590 Pruning Filters For EfficientDocument13 pages590 Pruning Filters For EfficientTiago LimaNo ratings yet
- A Fast and Flexible Framework For Network-Assisted Genomic AssociationDocument12 pagesA Fast and Flexible Framework For Network-Assisted Genomic AssociationFrancesco GualdiNo ratings yet
- TMP 1387Document18 pagesTMP 1387FrontiersNo ratings yet
- Calm Water Resistance With ANN (2018)Document10 pagesCalm Water Resistance With ANN (2018)GUSTAVO SILVEIRA DE ARAUJONo ratings yet
- Research Work 2023Document19 pagesResearch Work 2023Rahul JhaNo ratings yet
- Automatica: P. Yang R.A. Freeman G.J. Gordon K.M. Lynch S.S. Srinivasa R. SukthankarDocument7 pagesAutomatica: P. Yang R.A. Freeman G.J. Gordon K.M. Lynch S.S. Srinivasa R. SukthankarSmith TomNo ratings yet
- Spectral Normalization For GANsDocument26 pagesSpectral Normalization For GANsYasuru ThiwankaNo ratings yet
- Yang 20 ADocument16 pagesYang 20 AArielIporreRivasNo ratings yet
- 1 s2.0 S0149197022000567 MainDocument18 pages1 s2.0 S0149197022000567 MainSripriyan K 100507No ratings yet
- Computers 12 00035 v2Document17 pagesComputers 12 00035 v2Mossafir MossafirNo ratings yet
- Efficient Solutions To The Placement and Chaining Problem of User PlaneDocument16 pagesEfficient Solutions To The Placement and Chaining Problem of User PlaneOussema OUERFELLINo ratings yet
- Comparison of CNN ArchitecutresDocument7 pagesComparison of CNN Architecutresfeamaebano02287No ratings yet
- Computer Communications: Hsin-Yao Hsu, Gautam Srivastava, Hsin-Te Wu, Mu-Yen ChenDocument10 pagesComputer Communications: Hsin-Yao Hsu, Gautam Srivastava, Hsin-Te Wu, Mu-Yen Chen8c354be21dNo ratings yet
- Visual Cross-Image Fusion Using Deep Neural Networks For Image Edge DetectionDocument12 pagesVisual Cross-Image Fusion Using Deep Neural Networks For Image Edge DetectionWilluNo ratings yet
- 1 s2.0 S0925231216302673 MainDocument11 pages1 s2.0 S0925231216302673 MainSuba SelviNo ratings yet
- Applsci 12 10156Document23 pagesApplsci 12 10156sharmaharsh506325No ratings yet
- GRUUNetDocument12 pagesGRUUNetAshish SinghNo ratings yet
- 2020 Arxiv - Masked Label Prediction - Unified Message Passing Model For Semi-Supervised ClassificationDocument9 pages2020 Arxiv - Masked Label Prediction - Unified Message Passing Model For Semi-Supervised ClassificationFengShiNo ratings yet
- Mapreduce-Based Backpropagation Neural Network Over Large Scale Mobile DataDocument5 pagesMapreduce-Based Backpropagation Neural Network Over Large Scale Mobile DataNisa KhumairohNo ratings yet
- Dynamic Link Prediction by Learning The Representatio - 2024 - Expert Systems WiDocument8 pagesDynamic Link Prediction by Learning The Representatio - 2024 - Expert Systems WiPhi MaiNo ratings yet
- 10 1016@j Isprsjprs 2019 04 016Document19 pages10 1016@j Isprsjprs 2019 04 016sardinard BobNo ratings yet
- 1 s2.0 S0893608022002234 MainDocument14 pages1 s2.0 S0893608022002234 MainChen JasonNo ratings yet
- C N: B - A P H C A: HIP ET Udget Ware Runing With Eaviside Ontinuous PproximationsDocument18 pagesC N: B - A P H C A: HIP ET Udget Ware Runing With Eaviside Ontinuous Pproximations20je0434IshaanChaturvediNo ratings yet
- AnalogDocument14 pagesAnalogKrisna ArgadewaNo ratings yet
- 代表性期刊论文Document20 pages代表性期刊论文zhaoqc418No ratings yet
- VGGIN-Net Deep Transfer Network For Imbalanced Breast Cancer DatasetDocument12 pagesVGGIN-Net Deep Transfer Network For Imbalanced Breast Cancer DatasetKeren Evangeline. INo ratings yet
- Fnins 16 991851Document13 pagesFnins 16 991851Alex AssisNo ratings yet
- 【Paper - 8】mbe-19-10-469-Liu Xin-Mathematical Biosciences and EngineeringDocument23 pages【Paper - 8】mbe-19-10-469-Liu Xin-Mathematical Biosciences and Engineering2430478126No ratings yet
- G AF: F - A M M G G: Raph A LOW Based Utoregressive Odel For Olecular Raph EnerationDocument18 pagesG AF: F - A M M G G: Raph A LOW Based Utoregressive Odel For Olecular Raph Enerationericchen859No ratings yet
- Futureinternet 15 00392Document5 pagesFutureinternet 15 00392felipaoNo ratings yet
- Fast GCNDocument15 pagesFast GCNsiva79srmNo ratings yet
- 1 s2.0 S0020768323002160 MainDocument10 pages1 s2.0 S0020768323002160 MainNazanin iraniNo ratings yet
- Systematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Document9 pagesSystematic Evaluation of Convolution Neural Network Advances On The Imagenet-2017Jorge Velasquez RamosNo ratings yet
- NeurIPS 2021 Multi View Contrastive Graph Clustering PaperDocument12 pagesNeurIPS 2021 Multi View Contrastive Graph Clustering PaperYijian FanNo ratings yet
- Content Augmented Graph Neural NetworksDocument15 pagesContent Augmented Graph Neural Networkspegahzahedi97No ratings yet
- Recent Research in Cloud Radio Access Network (C-RAN) For 5G CellularDocument18 pagesRecent Research in Cloud Radio Access Network (C-RAN) For 5G CellularMAwais QarniNo ratings yet
- I G: U S - G - L R L M - I MDocument16 pagesI G: U S - G - L R L M - I MvikNo ratings yet
- Cdtrans Cross-Domain Transformer For Unsupervised Domain AdaptationDocument14 pagesCdtrans Cross-Domain Transformer For Unsupervised Domain AdaptationnilNo ratings yet
- Reconstructing Nodal Pressures in Water Distribution Systems With Graph Neural NetworksDocument12 pagesReconstructing Nodal Pressures in Water Distribution Systems With Graph Neural Networks阙绮东No ratings yet
- Dental X Ray AnalysisDocument5 pagesDental X Ray Analysisviden20965No ratings yet
- 1 s2.0 S2213138822001102 MainDocument8 pages1 s2.0 S2213138822001102 MainGuru VelmathiNo ratings yet
- Node-to-Node Approaching in Wireless Mesh ConnectivityFrom EverandNode-to-Node Approaching in Wireless Mesh ConnectivityRating: 5 out of 5 stars5/5 (1)
- Heart Disease Prediction Using Machine Learning Techniques: Master of Technology in Computer Science & EngineeringDocument1 pageHeart Disease Prediction Using Machine Learning Techniques: Master of Technology in Computer Science & Engineeringtemp tempNo ratings yet
- Pdf&rendition 1Document2 pagesPdf&rendition 1temp tempNo ratings yet
- Css PDFDocument26 pagesCss PDFtemp tempNo ratings yet
- Runtime Stack Lab 5-Su22Document1 pageRuntime Stack Lab 5-Su22temp tempNo ratings yet
- My Account - BillingDocument2 pagesMy Account - Billingtemp tempNo ratings yet
- DS Lab SyllabusDocument1 pageDS Lab Syllabustemp tempNo ratings yet
- 5.collections GenericDocument16 pages5.collections Generictemp tempNo ratings yet
- TestDocument1 pageTesttemp tempNo ratings yet
- De-240109-150231-Notification For Project Thesis Uploading MTech MPharm II Phase Jan 2024Document2 pagesDe-240109-150231-Notification For Project Thesis Uploading MTech MPharm II Phase Jan 2024temp tempNo ratings yet
- 02 M.Tech (MD) Project Report Front PagesDocument12 pages02 M.Tech (MD) Project Report Front Pagestemp tempNo ratings yet
- On The Analyses of Medical Images Using Traditional Machine Learning Techniques and Convolutional Neural NetworksDocument61 pagesOn The Analyses of Medical Images Using Traditional Machine Learning Techniques and Convolutional Neural Networkstemp tempNo ratings yet
- Wildfire Real Time Detection System Using Satellite Imagery: Disha An Data Scientist - ShellDocument9 pagesWildfire Real Time Detection System Using Satellite Imagery: Disha An Data Scientist - Shelltemp tempNo ratings yet
- Transport Phenomena - Monash University Final - Exam - 2010 - SolutionDocument15 pagesTransport Phenomena - Monash University Final - Exam - 2010 - SolutionKunal BhardwajNo ratings yet
- Reconfigurable Intelligent Surfaces-Assisted Multiuser MIMO Uplink Transmission With Partial CSIDocument15 pagesReconfigurable Intelligent Surfaces-Assisted Multiuser MIMO Uplink Transmission With Partial CSIAgent NiharikaNo ratings yet
- Laplace Transform Example Solution PDFDocument105 pagesLaplace Transform Example Solution PDFBhoszx Carl DoradoNo ratings yet
- JS85 1Document6 pagesJS85 1Anangtri Wahyudi100% (1)
- Superbolt Dimension-List Torque-Guidelines MT UncDocument1 pageSuperbolt Dimension-List Torque-Guidelines MT UncaputraNo ratings yet
- 9.21 Pivot Table Slicer Chart DashboardDocument78 pages9.21 Pivot Table Slicer Chart DashboardrafaelsgNo ratings yet
- Business Portal Online Print 10-11-2020Document283 pagesBusiness Portal Online Print 10-11-2020sxturbo100% (1)
- 8051 Micro Controller TrainerDocument2 pages8051 Micro Controller Trainerkira_yamato999999542No ratings yet
- Bending of PlatesDocument72 pagesBending of PlatesPrajeesh Raj100% (1)
- G3306 Gas Engine Generator Set: Continuous Power Caterpillar Engine SpecificationsDocument4 pagesG3306 Gas Engine Generator Set: Continuous Power Caterpillar Engine SpecificationsVYNZ StoreNo ratings yet
- Can Protocol Uvm PDFDocument5 pagesCan Protocol Uvm PDFMayank JaiswalNo ratings yet
- Chapter 7-Slope Stability-09Document19 pagesChapter 7-Slope Stability-09Alexander AlexanderNo ratings yet
- Semi Detailed Lesson Plan: (Finite Sequence) (Infinite Sequence)Document3 pagesSemi Detailed Lesson Plan: (Finite Sequence) (Infinite Sequence)Jayl 22100% (6)
- IC-A23 Service ManualDocument38 pagesIC-A23 Service ManualgeorgeclimaNo ratings yet
- mid考古題Document11 pagesmid考古題N ANo ratings yet
- Master PL-C 18W/865/2P 1CTDocument3 pagesMaster PL-C 18W/865/2P 1CTgegerkalongciwaruaNo ratings yet
- 2020 Keystone Catalog Low 1Document60 pages2020 Keystone Catalog Low 1sddsdNo ratings yet
- Validation Based ProtocolDocument7 pagesValidation Based ProtocolTerimaaNo ratings yet
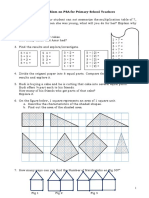
- Problem On PSA Primary SchoolDocument2 pagesProblem On PSA Primary SchoolMangleswary SalbarajaNo ratings yet
- Cavitation PaperDocument6 pagesCavitation PaperTony KadatzNo ratings yet
- L15 IRSW EvaluationDocument49 pagesL15 IRSW EvaluationSaurabh MorNo ratings yet
- Week II FlotationDocument23 pagesWeek II FlotationAamir SirohiNo ratings yet
- Guitar Alternate Tuning Guide PDFDocument96 pagesGuitar Alternate Tuning Guide PDFAmirpasha Fatemi100% (3)
- Statistics-Linear Regression and Correlation AnalysisDocument50 pagesStatistics-Linear Regression and Correlation AnalysisDr Rushen SinghNo ratings yet
- Fire Safety and Alert System Using Arduino Sensors With Iot IntegrationDocument6 pagesFire Safety and Alert System Using Arduino Sensors With Iot IntegrationSAURAV PANDEYNo ratings yet
- Sperm Count ProtocolDocument3 pagesSperm Count ProtocolGeoemilia1No ratings yet
- PSX24 Enatel MicroCOMPACT Power SystemDocument2 pagesPSX24 Enatel MicroCOMPACT Power SystemAldo Dario BeguiristainNo ratings yet
- Operational Amplifier (Phe-10)Document50 pagesOperational Amplifier (Phe-10)abhinavthedhimanNo ratings yet
- Registration of The Digital Signature of The Authorized Signatories of T...Document10 pagesRegistration of The Digital Signature of The Authorized Signatories of T...madhu chippalapallyNo ratings yet