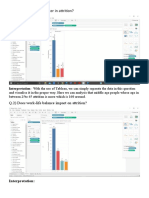
Download as docx, pdf, or txt
You might also like
- Linear Regression AssignmentDocument8 pagesLinear Regression Assignmentkdeepika2704No ratings yet
- Econ 251 PS2 SolutionsDocument11 pagesEcon 251 PS2 SolutionsPeter ShangNo ratings yet
- London School of Commerce (LSC) : Name: Anika Thasin Binti Course Title: QTBDocument13 pagesLondon School of Commerce (LSC) : Name: Anika Thasin Binti Course Title: QTBanikaNo ratings yet
- Study GuideDocument16 pagesStudy GuideKalama KitsaoNo ratings yet
- Stat - Lesson 1 Concepts and DefinitionsDocument5 pagesStat - Lesson 1 Concepts and DefinitionsChed PerezNo ratings yet
- Notes #1Document30 pagesNotes #1Sharon Rose MedezNo ratings yet
- Lesson 5 1Document28 pagesLesson 5 1Bien BibasNo ratings yet
- Statistics in DetailsDocument283 pagesStatistics in Detailsyousef shaban100% (1)
- Lesson 5ADocument9 pagesLesson 5AJulius JunioNo ratings yet
- Income ProjectDocument4 pagesIncome Projectapi-416858668No ratings yet
- Lecture 3,4,&5Sumg&Presenting DataDocument57 pagesLecture 3,4,&5Sumg&Presenting DataMijja Coll BulamuNo ratings yet
- My ScriptDocument2 pagesMy Scriptfawadahmed4040No ratings yet
- An Introduction To Genetic Algorithms: AbstractDocument9 pagesAn Introduction To Genetic Algorithms: AbstractsaurabhNo ratings yet
- Classification of DataDocument46 pagesClassification of DatargaNo ratings yet
- Chapters 1 and 2Document12 pagesChapters 1 and 2tarek mahmoudNo ratings yet
- Conditional Logit ApplicabilityDocument5 pagesConditional Logit ApplicabilitySujit ChauhanNo ratings yet
- SmartAlAnswers ALLDocument322 pagesSmartAlAnswers ALLEyosyas Woldekidan50% (2)
- Gkos 2017Document88 pagesGkos 2017PippoNo ratings yet
- Marketiing ReasrhDocument17 pagesMarketiing ReasrhVilayat AliNo ratings yet
- Lesson 5.1Document43 pagesLesson 5.1Katrina Chariss CaubalejoNo ratings yet
- Regression With STATADocument17 pagesRegression With STATAdoanhnghiep171No ratings yet
- StatsDocument20 pagesStatsCharl BaranganNo ratings yet
- HLTH2024 Exam Practice2Document39 pagesHLTH2024 Exam Practice2Mena HamadiNo ratings yet
- IGCSE-IQR and CumulativeFrequency For GX (Girls)Document36 pagesIGCSE-IQR and CumulativeFrequency For GX (Girls)ABU HASHEMNo ratings yet
- Quantitative Methods Assignment HelpDocument7 pagesQuantitative Methods Assignment HelpStatistics Homework SolverNo ratings yet
- Simple Linear RegressionDocument20 pagesSimple Linear RegressionLarry MaiNo ratings yet
- Effect of Covid-19 Pandemic To The Spending Habits of Employees in Lanao Del SurDocument25 pagesEffect of Covid-19 Pandemic To The Spending Habits of Employees in Lanao Del SurArhjiiNo ratings yet
- Averages (Solutions)Document15 pagesAverages (Solutions)sahittiNo ratings yet
- A Detailed Lesson Plan in Mathematics 10: Measures-Of-Position-Ungrouped-DataDocument6 pagesA Detailed Lesson Plan in Mathematics 10: Measures-Of-Position-Ungrouped-DataJIMERSON RAMPOLANo ratings yet
- Manishka Jain - Tableau Assignment 1Document6 pagesManishka Jain - Tableau Assignment 1Isha AggarwalNo ratings yet
- Pitanje 14 PDFDocument48 pagesPitanje 14 PDFAnonymous kpTRbAGeeNo ratings yet
- Classification of DataDocument34 pagesClassification of Dataayushmishra.222skpNo ratings yet
- Chapter 3. Mean, Median and Standard DeviationDocument66 pagesChapter 3. Mean, Median and Standard DeviationjuanNo ratings yet
- StatisticsDocument69 pagesStatisticsNIXE SHANNELLE CUSAPNo ratings yet
- Horizon Group Eco 204 Term PaperDocument10 pagesHorizon Group Eco 204 Term Paperআহনাফ গালিবNo ratings yet
- Research Methods (Quantitative and Qualitative) Week 10 Online Tutorial - Autumn 2021Document12 pagesResearch Methods (Quantitative and Qualitative) Week 10 Online Tutorial - Autumn 2021JoelNo ratings yet
- CA Report TemplateDocument12 pagesCA Report Templatemicropig1234No ratings yet
- Research MethodologyDocument41 pagesResearch MethodologyJohn OnyeakaziNo ratings yet
- Untitled 1 1Document12 pagesUntitled 1 1massimo borrioneNo ratings yet
- What Is The Difference Between OrdinalDocument3 pagesWhat Is The Difference Between Ordinalomar alimuddinNo ratings yet
- UTS Business Statistics: Desciptive StatsDocument7 pagesUTS Business Statistics: Desciptive StatsemilyNo ratings yet
- Homework 7Document3 pagesHomework 7DiAundra DavisNo ratings yet
- Problem Set 1: Worms: 1. Nutrition LevelsDocument6 pagesProblem Set 1: Worms: 1. Nutrition LevelsMarco PastaNo ratings yet
- Applied Econometrics For Managers (MBAA-II, AY: 2023-24) IIM KashipurDocument3 pagesApplied Econometrics For Managers (MBAA-II, AY: 2023-24) IIM KashipurSHAMBHAVI GUPTANo ratings yet
- T Test and ANOVA - Test: (Use Demo Discriptive - Sav Data File)Document5 pagesT Test and ANOVA - Test: (Use Demo Discriptive - Sav Data File)ishwaryaNo ratings yet
- BUS 308 Weeks 1Document43 pagesBUS 308 Weeks 1menefiemNo ratings yet
- Homework 02 AnswersDocument12 pagesHomework 02 Answersornelaabegaj_83152390% (1)
- BU1007 Report RoddyDocument19 pagesBU1007 Report Roddy陈文轩No ratings yet
- Data Analysis: What's The Arithmetic Mean of 3, - 5, 7, and 0?Document26 pagesData Analysis: What's The Arithmetic Mean of 3, - 5, 7, and 0?Divya GersappaNo ratings yet
- Lesson 1 NotesDocument27 pagesLesson 1 NotesAnonyvousNo ratings yet
- Draft - Assignment 1 ReportDocument8 pagesDraft - Assignment 1 ReportfuriousranaNo ratings yet
- StatisticsDocument272 pagesStatisticsAnonymous hYMWbA100% (2)
- 1 IntroductionDocument6 pages1 Introductionfuertes.janchristopher1525No ratings yet
- Economics Data Analysis ExcelDocument6 pagesEconomics Data Analysis Excelsahsa.kakaNo ratings yet
- BAYLEY 4 NotesDocument2 pagesBAYLEY 4 NotesSatria Faye RespicioNo ratings yet
- CU ASwR Lab12 SolDocument6 pagesCU ASwR Lab12 Soltabesadze23No ratings yet
- Behavioral Variability - Leary Fall 2015Document18 pagesBehavioral Variability - Leary Fall 2015Joicelyn BarrientosNo ratings yet
- Detailed Lesson Plan in Mathematics Grade 5Document11 pagesDetailed Lesson Plan in Mathematics Grade 5DemzDanmer Zann Paulite CerdeñaNo ratings yet
- Interdepartmental Integration. A Definition With Implications For Product Development PerformanceDocument15 pagesInterdepartmental Integration. A Definition With Implications For Product Development PerformanceBloxorz GamingNo ratings yet
- UKP6053 - L8 Multiple RegressionDocument105 pagesUKP6053 - L8 Multiple RegressionFiq Razali100% (2)
- Ex08 PDFDocument29 pagesEx08 PDFSalman FarooqNo ratings yet
- A1388404476 - 64039 - 23 - 2023 - Machine Learning IIDocument10 pagesA1388404476 - 64039 - 23 - 2023 - Machine Learning IIraj241299No ratings yet
- Insights From Creator Interactivity PerspectiveDocument17 pagesInsights From Creator Interactivity PerspectivesemanurbiladaNo ratings yet
- Investment Behavior in Generation Z and MillennialDocument15 pagesInvestment Behavior in Generation Z and MillennialbutuhtugasNo ratings yet
- Effect of Access To Health Services On Neonatal Mortality in UganDocument156 pagesEffect of Access To Health Services On Neonatal Mortality in Ugankamba bryanNo ratings yet
- Journal of Consumer MarketingDocument32 pagesJournal of Consumer MarketingAsif MahmudNo ratings yet
- PSYC3010 Tutorial 8: Moderated Multiple Regression (MMR) Activity 6: Exercises 4, 5 & 6Document42 pagesPSYC3010 Tutorial 8: Moderated Multiple Regression (MMR) Activity 6: Exercises 4, 5 & 6gfsgfsdNo ratings yet
- Six Sigma ToolsDocument9 pagesSix Sigma ToolsKimberly virgineza100% (1)
- Factors Affecting Return On Assets of Us Technology and Financial CorporationsDocument11 pagesFactors Affecting Return On Assets of Us Technology and Financial CorporationsDennis OngNo ratings yet
- Impact of Credit Risk Management On Bank Performance of Nepalese Commercial BankDocument8 pagesImpact of Credit Risk Management On Bank Performance of Nepalese Commercial BankVivi OktaviaNo ratings yet
- Fraternity/sorority Membership: Good News About First-Year Impact.Document12 pagesFraternity/sorority Membership: Good News About First-Year Impact.Gabrielle BilliotNo ratings yet
- Greening Competitiveness For HDocument23 pagesGreening Competitiveness For Hthumai510No ratings yet
- Relationship Marketing and The Amount of The Cafe in Optimizing Customer Loyalty Oase CoffeeDocument6 pagesRelationship Marketing and The Amount of The Cafe in Optimizing Customer Loyalty Oase CoffeeInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 2015 - Impact of Green Human Resource Factors On Environmental PerformanceDocument9 pages2015 - Impact of Green Human Resource Factors On Environmental PerformanceHussniNo ratings yet
- 7 RegressionDocument96 pages7 RegressionPushp ToshniwalNo ratings yet
- Subjective QuestionsDocument8 pagesSubjective QuestionsKeerthan kNo ratings yet
- 6.sick Child Feeding Practice and Associated Factors Among Mothers of Children Less Than 24 Months Old, in Burayu Tow, EthiopiaDocument8 pages6.sick Child Feeding Practice and Associated Factors Among Mothers of Children Less Than 24 Months Old, in Burayu Tow, EthiopiaTomas YeheisNo ratings yet
- Ioannis Lazar The Relationship Between Working Capital Management and Profitability of Listed Companies in The Athens Stock ExchangeDocument12 pagesIoannis Lazar The Relationship Between Working Capital Management and Profitability of Listed Companies in The Athens Stock ExchangedwighyNo ratings yet
- Resume 190922 - Restri Ayu SafarinaDocument3 pagesResume 190922 - Restri Ayu SafarinaRestri Ayu SafarinaNo ratings yet
- ESG and Corporate Financial PeDocument17 pagesESG and Corporate Financial PeHuan GaoNo ratings yet
- Freeman Et Al 2007 Sense of BelongingDocument19 pagesFreeman Et Al 2007 Sense of BelongingperryNo ratings yet
- Bitcoin Stochastic Stock To Flow ModelDocument21 pagesBitcoin Stochastic Stock To Flow ModelNathaniel FowlerNo ratings yet
- Sample Final SolutionsDocument12 pagesSample Final SolutionsKhushboo KhanejaNo ratings yet
- A Meta-Analysis of The Milk-Production Response After Anthelmintic Treatment in Naturally Infected Adult Dairy CowsDocument20 pagesA Meta-Analysis of The Milk-Production Response After Anthelmintic Treatment in Naturally Infected Adult Dairy CowsVenny PatriciaNo ratings yet
- Solutions For Homework Accounting 311 CostDocument128 pagesSolutions For Homework Accounting 311 Costblack272727No ratings yet
- Journal 4 - Management of Logistics AlbaniaDocument7 pagesJournal 4 - Management of Logistics AlbaniaRuhul HilyatiNo ratings yet
- Week 14 - Data AnalysisDocument7 pagesWeek 14 - Data AnalysisFadhilah IstiqomahNo ratings yet