
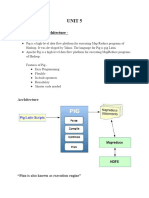
Pig
Pig
You might also like
- An Online Tax Management SystemDocument47 pagesAn Online Tax Management SystemThembo Jimmy87% (15)
- Pig and Pig LatinDocument16 pagesPig and Pig Latinshrina.jain.07No ratings yet
- BDT Assignment4Document4 pagesBDT Assignment4poorvaja.rNo ratings yet
- UNIT 5 Complete NotesDocument21 pagesUNIT 5 Complete Notesworks8606No ratings yet
- Bda (Mid-2)Document14 pagesBda (Mid-2)20jg1a4214.swapnaNo ratings yet
- BDP U4Document58 pagesBDP U4Durga BishtNo ratings yet
- Unit - V PIG Hadoop & Big Data: Pig Latin. This Language Provides Various Operators Using Which ProgrammersDocument9 pagesUnit - V PIG Hadoop & Big Data: Pig Latin. This Language Provides Various Operators Using Which ProgrammersAbhay DabhadeNo ratings yet
- Notes Unit 5 BigdataDocument21 pagesNotes Unit 5 BigdataSHRUTI NEMANo ratings yet
- BD 5Document28 pagesBD 5gaudav217No ratings yet
- Pig Latin ModesDocument3 pagesPig Latin ModesyohetadNo ratings yet
- Unit-3 Bda KalyanDocument1 pageUnit-3 Bda Kalyanrohit sai tech viewersNo ratings yet
- Unit Iv Part - 2Document59 pagesUnit Iv Part - 2Nithya NaraparajuNo ratings yet
- Apache PigDocument6 pagesApache PigMayank SinhaNo ratings yet
- Unit 4 BbaDocument10 pagesUnit 4 Bbarajendrameena172003No ratings yet
- Unit 5 BdaDocument10 pagesUnit 5 BdaVINAY AGGARWALNo ratings yet
- Scet Unit 5Document9 pagesScet Unit 5Devi KondavetiNo ratings yet
- Unit No. 8Document24 pagesUnit No. 8vishal phuleNo ratings yet
- Unit IV - Big Data ProgrammingDocument17 pagesUnit IV - Big Data ProgrammingjasmineNo ratings yet
- Big Data Unit IVDocument19 pagesBig Data Unit IVbeelogger4321No ratings yet
- Apache Pig: Pig Is The Abstraction Over MapreduceDocument4 pagesApache Pig: Pig Is The Abstraction Over Mapreduceprerna guptaNo ratings yet
- BDA - Unit-4 Part 1Document47 pagesBDA - Unit-4 Part 1teja.ksp1801No ratings yet
- Course On: Big Data AnalyticsDocument52 pagesCourse On: Big Data Analyticsmunish kumar agarwalNo ratings yet
- Notes Unit 5 BigdataDocument19 pagesNotes Unit 5 BigdataSHRUTI NEMANo ratings yet
- Apache Pig Components: ParserDocument3 pagesApache Pig Components: ParserRKNo ratings yet
- Pythontrainingtutorial 170613150508Document32 pagesPythontrainingtutorial 170613150508Ali M. RiyathNo ratings yet
- Unit IIIDocument118 pagesUnit IIIAlekhya AbbarajuNo ratings yet
- Integration of Python With Hadoop and SparkDocument10 pagesIntegration of Python With Hadoop and SparkRamon Vargas MontañesNo ratings yet
- 5 PIG Big Data Analytics Final YearDocument25 pages5 PIG Big Data Analytics Final YearRISHIKA ARORANo ratings yet
- Unit 4Document5 pagesUnit 4Prince RathoreNo ratings yet
- Hadoop Tools - A Brief OverviewDocument18 pagesHadoop Tools - A Brief OverviewSabbir Bin ShazidNo ratings yet
- Introduction To Apache Pig: GeeksforgeeksDocument5 pagesIntroduction To Apache Pig: Geeksforgeeksamitsachan47No ratings yet
- Hadoop PigDocument111 pagesHadoop PigJhumri TalaiyaNo ratings yet
- Pig Full LectureDocument38 pagesPig Full LectureAtharv ChaudhariNo ratings yet
- Apache Pig - A Data Flow Framework Based On Hadoop Map ReduceDocument6 pagesApache Pig - A Data Flow Framework Based On Hadoop Map ReduceSYED IBRAHIMNo ratings yet
- Unit Iv GCCDocument13 pagesUnit Iv GCCGobi NathanNo ratings yet
- Writing An Hadoop MapReduce Program in PythonDocument21 pagesWriting An Hadoop MapReduce Program in PythonVigneshwaran SundaresanNo ratings yet
- Pig, Grunt, Hive: Presented By:Akila 20Spcs01Document16 pagesPig, Grunt, Hive: Presented By:Akila 20Spcs01Tech Talk Paper PresentationNo ratings yet
- Unit 2 - Hadoop PDFDocument7 pagesUnit 2 - Hadoop PDFGopal AgarwalNo ratings yet
- Big Data Analytics Unit 4Document83 pagesBig Data Analytics Unit 418-1211 Apoorva GangyadaNo ratings yet
- Big Data Processing, 2014/15: Lecture 8: Pig Latin!Document58 pagesBig Data Processing, 2014/15: Lecture 8: Pig Latin!sridhiyaNo ratings yet
- Bda 2Document15 pagesBda 2B201001No ratings yet
- Assignment No 6Document6 pagesAssignment No 6darshan KeskarNo ratings yet
- BDA Module 2 PDFDocument123 pagesBDA Module 2 PDFNidhi SrivastavaNo ratings yet
- Unit 5 PIG&HIVEDocument115 pagesUnit 5 PIG&HIVEKishore ParimiNo ratings yet
- M /R, H & P: AP Educe Adoop IGDocument24 pagesM /R, H & P: AP Educe Adoop IGashish10mca9394No ratings yet
- Unit 5 BdaDocument18 pagesUnit 5 Bdajaya97548No ratings yet
- Big Data OverviewDocument39 pagesBig Data Overviewnoor khanNo ratings yet
- Module 4 - PigDocument65 pagesModule 4 - PigAditya RajNo ratings yet
- Expert SystemsDocument220 pagesExpert SystemsMD AFTAB HUSSAINNo ratings yet
- Cse 17CS82 M2 S1 PPTDocument35 pagesCse 17CS82 M2 S1 PPTVasanth KumarNo ratings yet
- PIg in BIg DataDocument28 pagesPIg in BIg DatamayurkshirsatNo ratings yet
- PIg in BIg DataDocument28 pagesPIg in BIg DatamayurkshirsatNo ratings yet
- АНГЛDocument4 pagesАНГЛ9312No ratings yet
- CH 6 BDADocument10 pagesCH 6 BDABinit KarmakarNo ratings yet
- Hadoop EcosystemDocument16 pagesHadoop Ecosystempoojan thakkarNo ratings yet
- IMTC634 - Data Science - Chapter 16Document20 pagesIMTC634 - Data Science - Chapter 16Invictus IndiansNo ratings yet
- Group 37Document28 pagesGroup 37Pooja BanNo ratings yet
- ResumeDocument7 pagesResumeMA100% (1)
- Pig SlidesDocument46 pagesPig SlidesSreedhar ArikatlaNo ratings yet
- Profiling Apache HIVE Query From Run Time Logs: Givanna Putri Haryono Ying ZhouDocument8 pagesProfiling Apache HIVE Query From Run Time Logs: Givanna Putri Haryono Ying ZhouragouNo ratings yet
- Notes Bug Data and of ApacheDocument10 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- Notes Bug Data and of ApacheDocument6 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- Notes Bug Data and of ApacheDocument4 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- APznzaZvwqYHGAlkYd3QRTJvvRV8LZEcONVi7Q8TqzaVxhBo ZPNF Vb9enJ9ddVzAXOUc6hPgBMdPOGRiPlyOMDpcx26TynElLRFlS1IfYmrHoD2OfNfa4RZ5ua69c4MlL29Un4R8lTmekZq6Ds6mWqzxUracaVlbq4Drb6vJ4AjeHqAL3ch1j7g YYxmxwsE 9b3PWpwWNIYkduQSia3XDocument43 pagesAPznzaZvwqYHGAlkYd3QRTJvvRV8LZEcONVi7Q8TqzaVxhBo ZPNF Vb9enJ9ddVzAXOUc6hPgBMdPOGRiPlyOMDpcx26TynElLRFlS1IfYmrHoD2OfNfa4RZ5ua69c4MlL29Un4R8lTmekZq6Ds6mWqzxUracaVlbq4Drb6vJ4AjeHqAL3ch1j7g YYxmxwsE 9b3PWpwWNIYkduQSia3Xysakhare94No ratings yet
- Technical Components of E-CommerceDocument9 pagesTechnical Components of E-Commerceysakhare94No ratings yet
- Symbiosis Skills & Professional University, Pune: Sr. No. Permenant Registration Number Full Name of The CandidateDocument2 pagesSymbiosis Skills & Professional University, Pune: Sr. No. Permenant Registration Number Full Name of The Candidateysakhare94No ratings yet
- Hercules Installation Guide v4.0Document249 pagesHercules Installation Guide v4.0Mustaffah KabelyyonNo ratings yet
- Form - Online and E-Learning Proposal AuthorizationDocument3 pagesForm - Online and E-Learning Proposal AuthorizationShankker KumarNo ratings yet
- Rightnow Service Descriptions 1885273 PDFDocument179 pagesRightnow Service Descriptions 1885273 PDFamoussaaNo ratings yet
- Micros Pos GuideDocument5 pagesMicros Pos Guidejorison cardozoNo ratings yet
- Powerpoint Template: " Add Your Company Slogan "Document20 pagesPowerpoint Template: " Add Your Company Slogan "Ngọc ThuầnNo ratings yet
- 006 Chemistry in Everyday Life Powerpoint TemplatesDocument48 pages006 Chemistry in Everyday Life Powerpoint Templatesg8440512No ratings yet
- Sw10 Drawing p51Document5 pagesSw10 Drawing p51chethanapraoNo ratings yet
- Samsung PC SpecificationDocument31 pagesSamsung PC SpecificationAnand Kumar GNo ratings yet
- Pan Graver PhotoDocument10 pagesPan Graver PhotoKapil ThakkarNo ratings yet
- Ngo Website Requirements and SpecsDocument2 pagesNgo Website Requirements and SpecsLateh Larry-Collins AkaNo ratings yet
- Inside Help & Manual - The Complete Guide To The Revolutionary Content Management SystemDocument869 pagesInside Help & Manual - The Complete Guide To The Revolutionary Content Management SystemecsoftwareNo ratings yet
- 03.3 The Android Support LibraryDocument25 pages03.3 The Android Support LibraryMohammad AlomariNo ratings yet
- The MagPi Issue 34Document70 pagesThe MagPi Issue 34LittleGameDeb100% (2)
- Thinkpad P15V Gen 1 and T15P Gen 1 User GuideDocument106 pagesThinkpad P15V Gen 1 and T15P Gen 1 User GuideErnesto Emilio Verástegui ÑahuizNo ratings yet
- 30.04 (L&T Reply)Document1 page30.04 (L&T Reply)Senthilkumar KNo ratings yet
- Multiple-Choice QuestionsDocument18 pagesMultiple-Choice Questionssahil maneNo ratings yet
- How Ale and Idocs Affect Sap in House Cash ConfigurationDocument14 pagesHow Ale and Idocs Affect Sap in House Cash ConfigurationShailesh SuranaNo ratings yet
- The Complete Android GuideDocument282 pagesThe Complete Android Guidedeisecairo100% (1)
- Paper 83 - Spe 117121-Pp Total Well Integrity - Column FormatDocument9 pagesPaper 83 - Spe 117121-Pp Total Well Integrity - Column FormatalizareiforoushNo ratings yet
- Online Test Manual of Mitsui Bussan Scholarship Program - 2Document16 pagesOnline Test Manual of Mitsui Bussan Scholarship Program - 2Lailatul MunawarohNo ratings yet
- D53942GC10 sg2Document390 pagesD53942GC10 sg2feders156No ratings yet
- Programming Using Python: Amey Karkare Dept. of CSE IIT KanpurDocument12 pagesProgramming Using Python: Amey Karkare Dept. of CSE IIT KanpurSuryanshNo ratings yet
- Migrate Database FILESYSTEM To ASMDocument4 pagesMigrate Database FILESYSTEM To ASMsrsr1981No ratings yet
- Tamara Stewart Resume 2016Document2 pagesTamara Stewart Resume 2016api-323478645No ratings yet
- WBS 84 Days Wed 18/03/15 Mon 13/07/15Document6 pagesWBS 84 Days Wed 18/03/15 Mon 13/07/15Ice DesperateNo ratings yet
- Stored Procedure Transformation in InformaticaDocument13 pagesStored Procedure Transformation in Informaticajazz440No ratings yet
- Data Analysis Project Plan TemplateDocument8 pagesData Analysis Project Plan Templateshrouk albermawyNo ratings yet
- Wait EventsDocument31 pagesWait Eventsprassu1No ratings yet




























































































Download as pdf or txt
You might also like
- An Online Tax Management SystemDocument47 pagesAn Online Tax Management SystemThembo Jimmy87% (15)
- Pig and Pig LatinDocument16 pagesPig and Pig Latinshrina.jain.07No ratings yet
- BDT Assignment4Document4 pagesBDT Assignment4poorvaja.rNo ratings yet
- UNIT 5 Complete NotesDocument21 pagesUNIT 5 Complete Notesworks8606No ratings yet
- Bda (Mid-2)Document14 pagesBda (Mid-2)20jg1a4214.swapnaNo ratings yet
- BDP U4Document58 pagesBDP U4Durga BishtNo ratings yet
- Unit - V PIG Hadoop & Big Data: Pig Latin. This Language Provides Various Operators Using Which ProgrammersDocument9 pagesUnit - V PIG Hadoop & Big Data: Pig Latin. This Language Provides Various Operators Using Which ProgrammersAbhay DabhadeNo ratings yet
- Notes Unit 5 BigdataDocument21 pagesNotes Unit 5 BigdataSHRUTI NEMANo ratings yet
- BD 5Document28 pagesBD 5gaudav217No ratings yet
- Pig Latin ModesDocument3 pagesPig Latin ModesyohetadNo ratings yet
- Unit-3 Bda KalyanDocument1 pageUnit-3 Bda Kalyanrohit sai tech viewersNo ratings yet
- Unit Iv Part - 2Document59 pagesUnit Iv Part - 2Nithya NaraparajuNo ratings yet
- Apache PigDocument6 pagesApache PigMayank SinhaNo ratings yet
- Unit 4 BbaDocument10 pagesUnit 4 Bbarajendrameena172003No ratings yet
- Unit 5 BdaDocument10 pagesUnit 5 BdaVINAY AGGARWALNo ratings yet
- Scet Unit 5Document9 pagesScet Unit 5Devi KondavetiNo ratings yet
- Unit No. 8Document24 pagesUnit No. 8vishal phuleNo ratings yet
- Unit IV - Big Data ProgrammingDocument17 pagesUnit IV - Big Data ProgrammingjasmineNo ratings yet
- Big Data Unit IVDocument19 pagesBig Data Unit IVbeelogger4321No ratings yet
- Apache Pig: Pig Is The Abstraction Over MapreduceDocument4 pagesApache Pig: Pig Is The Abstraction Over Mapreduceprerna guptaNo ratings yet
- BDA - Unit-4 Part 1Document47 pagesBDA - Unit-4 Part 1teja.ksp1801No ratings yet
- Course On: Big Data AnalyticsDocument52 pagesCourse On: Big Data Analyticsmunish kumar agarwalNo ratings yet
- Notes Unit 5 BigdataDocument19 pagesNotes Unit 5 BigdataSHRUTI NEMANo ratings yet
- Apache Pig Components: ParserDocument3 pagesApache Pig Components: ParserRKNo ratings yet
- Pythontrainingtutorial 170613150508Document32 pagesPythontrainingtutorial 170613150508Ali M. RiyathNo ratings yet
- Unit IIIDocument118 pagesUnit IIIAlekhya AbbarajuNo ratings yet
- Integration of Python With Hadoop and SparkDocument10 pagesIntegration of Python With Hadoop and SparkRamon Vargas MontañesNo ratings yet
- 5 PIG Big Data Analytics Final YearDocument25 pages5 PIG Big Data Analytics Final YearRISHIKA ARORANo ratings yet
- Unit 4Document5 pagesUnit 4Prince RathoreNo ratings yet
- Hadoop Tools - A Brief OverviewDocument18 pagesHadoop Tools - A Brief OverviewSabbir Bin ShazidNo ratings yet
- Introduction To Apache Pig: GeeksforgeeksDocument5 pagesIntroduction To Apache Pig: Geeksforgeeksamitsachan47No ratings yet
- Hadoop PigDocument111 pagesHadoop PigJhumri TalaiyaNo ratings yet
- Pig Full LectureDocument38 pagesPig Full LectureAtharv ChaudhariNo ratings yet
- Apache Pig - A Data Flow Framework Based On Hadoop Map ReduceDocument6 pagesApache Pig - A Data Flow Framework Based On Hadoop Map ReduceSYED IBRAHIMNo ratings yet
- Unit Iv GCCDocument13 pagesUnit Iv GCCGobi NathanNo ratings yet
- Writing An Hadoop MapReduce Program in PythonDocument21 pagesWriting An Hadoop MapReduce Program in PythonVigneshwaran SundaresanNo ratings yet
- Pig, Grunt, Hive: Presented By:Akila 20Spcs01Document16 pagesPig, Grunt, Hive: Presented By:Akila 20Spcs01Tech Talk Paper PresentationNo ratings yet
- Unit 2 - Hadoop PDFDocument7 pagesUnit 2 - Hadoop PDFGopal AgarwalNo ratings yet
- Big Data Analytics Unit 4Document83 pagesBig Data Analytics Unit 418-1211 Apoorva GangyadaNo ratings yet
- Big Data Processing, 2014/15: Lecture 8: Pig Latin!Document58 pagesBig Data Processing, 2014/15: Lecture 8: Pig Latin!sridhiyaNo ratings yet
- Bda 2Document15 pagesBda 2B201001No ratings yet
- Assignment No 6Document6 pagesAssignment No 6darshan KeskarNo ratings yet
- BDA Module 2 PDFDocument123 pagesBDA Module 2 PDFNidhi SrivastavaNo ratings yet
- Unit 5 PIG&HIVEDocument115 pagesUnit 5 PIG&HIVEKishore ParimiNo ratings yet
- M /R, H & P: AP Educe Adoop IGDocument24 pagesM /R, H & P: AP Educe Adoop IGashish10mca9394No ratings yet
- Unit 5 BdaDocument18 pagesUnit 5 Bdajaya97548No ratings yet
- Big Data OverviewDocument39 pagesBig Data Overviewnoor khanNo ratings yet
- Module 4 - PigDocument65 pagesModule 4 - PigAditya RajNo ratings yet
- Expert SystemsDocument220 pagesExpert SystemsMD AFTAB HUSSAINNo ratings yet
- Cse 17CS82 M2 S1 PPTDocument35 pagesCse 17CS82 M2 S1 PPTVasanth KumarNo ratings yet
- PIg in BIg DataDocument28 pagesPIg in BIg DatamayurkshirsatNo ratings yet
- PIg in BIg DataDocument28 pagesPIg in BIg DatamayurkshirsatNo ratings yet
- АНГЛDocument4 pagesАНГЛ9312No ratings yet
- CH 6 BDADocument10 pagesCH 6 BDABinit KarmakarNo ratings yet
- Hadoop EcosystemDocument16 pagesHadoop Ecosystempoojan thakkarNo ratings yet
- IMTC634 - Data Science - Chapter 16Document20 pagesIMTC634 - Data Science - Chapter 16Invictus IndiansNo ratings yet
- Group 37Document28 pagesGroup 37Pooja BanNo ratings yet
- ResumeDocument7 pagesResumeMA100% (1)
- Pig SlidesDocument46 pagesPig SlidesSreedhar ArikatlaNo ratings yet
- Profiling Apache HIVE Query From Run Time Logs: Givanna Putri Haryono Ying ZhouDocument8 pagesProfiling Apache HIVE Query From Run Time Logs: Givanna Putri Haryono Ying ZhouragouNo ratings yet
- Notes Bug Data and of ApacheDocument10 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- Notes Bug Data and of ApacheDocument6 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- Notes Bug Data and of ApacheDocument4 pagesNotes Bug Data and of Apacheysakhare94No ratings yet
- APznzaZvwqYHGAlkYd3QRTJvvRV8LZEcONVi7Q8TqzaVxhBo ZPNF Vb9enJ9ddVzAXOUc6hPgBMdPOGRiPlyOMDpcx26TynElLRFlS1IfYmrHoD2OfNfa4RZ5ua69c4MlL29Un4R8lTmekZq6Ds6mWqzxUracaVlbq4Drb6vJ4AjeHqAL3ch1j7g YYxmxwsE 9b3PWpwWNIYkduQSia3XDocument43 pagesAPznzaZvwqYHGAlkYd3QRTJvvRV8LZEcONVi7Q8TqzaVxhBo ZPNF Vb9enJ9ddVzAXOUc6hPgBMdPOGRiPlyOMDpcx26TynElLRFlS1IfYmrHoD2OfNfa4RZ5ua69c4MlL29Un4R8lTmekZq6Ds6mWqzxUracaVlbq4Drb6vJ4AjeHqAL3ch1j7g YYxmxwsE 9b3PWpwWNIYkduQSia3Xysakhare94No ratings yet
- Technical Components of E-CommerceDocument9 pagesTechnical Components of E-Commerceysakhare94No ratings yet
- Symbiosis Skills & Professional University, Pune: Sr. No. Permenant Registration Number Full Name of The CandidateDocument2 pagesSymbiosis Skills & Professional University, Pune: Sr. No. Permenant Registration Number Full Name of The Candidateysakhare94No ratings yet
- Hercules Installation Guide v4.0Document249 pagesHercules Installation Guide v4.0Mustaffah KabelyyonNo ratings yet
- Form - Online and E-Learning Proposal AuthorizationDocument3 pagesForm - Online and E-Learning Proposal AuthorizationShankker KumarNo ratings yet
- Rightnow Service Descriptions 1885273 PDFDocument179 pagesRightnow Service Descriptions 1885273 PDFamoussaaNo ratings yet
- Micros Pos GuideDocument5 pagesMicros Pos Guidejorison cardozoNo ratings yet
- Powerpoint Template: " Add Your Company Slogan "Document20 pagesPowerpoint Template: " Add Your Company Slogan "Ngọc ThuầnNo ratings yet
- 006 Chemistry in Everyday Life Powerpoint TemplatesDocument48 pages006 Chemistry in Everyday Life Powerpoint Templatesg8440512No ratings yet
- Sw10 Drawing p51Document5 pagesSw10 Drawing p51chethanapraoNo ratings yet
- Samsung PC SpecificationDocument31 pagesSamsung PC SpecificationAnand Kumar GNo ratings yet
- Pan Graver PhotoDocument10 pagesPan Graver PhotoKapil ThakkarNo ratings yet
- Ngo Website Requirements and SpecsDocument2 pagesNgo Website Requirements and SpecsLateh Larry-Collins AkaNo ratings yet
- Inside Help & Manual - The Complete Guide To The Revolutionary Content Management SystemDocument869 pagesInside Help & Manual - The Complete Guide To The Revolutionary Content Management SystemecsoftwareNo ratings yet
- 03.3 The Android Support LibraryDocument25 pages03.3 The Android Support LibraryMohammad AlomariNo ratings yet
- The MagPi Issue 34Document70 pagesThe MagPi Issue 34LittleGameDeb100% (2)
- Thinkpad P15V Gen 1 and T15P Gen 1 User GuideDocument106 pagesThinkpad P15V Gen 1 and T15P Gen 1 User GuideErnesto Emilio Verástegui ÑahuizNo ratings yet
- 30.04 (L&T Reply)Document1 page30.04 (L&T Reply)Senthilkumar KNo ratings yet
- Multiple-Choice QuestionsDocument18 pagesMultiple-Choice Questionssahil maneNo ratings yet
- How Ale and Idocs Affect Sap in House Cash ConfigurationDocument14 pagesHow Ale and Idocs Affect Sap in House Cash ConfigurationShailesh SuranaNo ratings yet
- The Complete Android GuideDocument282 pagesThe Complete Android Guidedeisecairo100% (1)
- Paper 83 - Spe 117121-Pp Total Well Integrity - Column FormatDocument9 pagesPaper 83 - Spe 117121-Pp Total Well Integrity - Column FormatalizareiforoushNo ratings yet
- Online Test Manual of Mitsui Bussan Scholarship Program - 2Document16 pagesOnline Test Manual of Mitsui Bussan Scholarship Program - 2Lailatul MunawarohNo ratings yet
- D53942GC10 sg2Document390 pagesD53942GC10 sg2feders156No ratings yet
- Programming Using Python: Amey Karkare Dept. of CSE IIT KanpurDocument12 pagesProgramming Using Python: Amey Karkare Dept. of CSE IIT KanpurSuryanshNo ratings yet
- Migrate Database FILESYSTEM To ASMDocument4 pagesMigrate Database FILESYSTEM To ASMsrsr1981No ratings yet
- Tamara Stewart Resume 2016Document2 pagesTamara Stewart Resume 2016api-323478645No ratings yet
- WBS 84 Days Wed 18/03/15 Mon 13/07/15Document6 pagesWBS 84 Days Wed 18/03/15 Mon 13/07/15Ice DesperateNo ratings yet
- Stored Procedure Transformation in InformaticaDocument13 pagesStored Procedure Transformation in Informaticajazz440No ratings yet
- Data Analysis Project Plan TemplateDocument8 pagesData Analysis Project Plan Templateshrouk albermawyNo ratings yet
- Wait EventsDocument31 pagesWait Eventsprassu1No ratings yet