Download as pdf or txt
You might also like
- CSA 2019 CED FRQs Quesonly PDFDocument6 pagesCSA 2019 CED FRQs Quesonly PDFNadiaNo ratings yet
- Machine Learning AssignmentsDocument3 pagesMachine Learning AssignmentsUjesh MauryaNo ratings yet
- ELEN4903 hw1 Spring2018Document2 pagesELEN4903 hw1 Spring2018Azraf AnwarNo ratings yet
- Ass 2 DSBDLDocument29 pagesAss 2 DSBDLAnviNo ratings yet
- ML - LAB - FILE PankajDocument13 pagesML - LAB - FILE PankajkhatmalmainNo ratings yet
- PRML Assignment1 2022Document2 pagesPRML Assignment1 2022Basil Azeem ed20b009No ratings yet
- Introduction To Python and Computer Programming 1704298503Document44 pagesIntroduction To Python and Computer Programming 1704298503el.tico.138623No ratings yet
- ML - LAB - FILE AmritDocument13 pagesML - LAB - FILE AmritkhatmalmainNo ratings yet
- ML With Python PracticalDocument22 pagesML With Python Practicaln58648017No ratings yet
- ML LabDocument45 pagesML Labkarriganeshvarma1No ratings yet
- Assignment No 1dda-LineDocument4 pagesAssignment No 1dda-LineShrikant NavaleNo ratings yet
- CS5785 Homework 4: .PDF .Py .IpynbDocument5 pagesCS5785 Homework 4: .PDF .Py .IpynbAl TarinoNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- Deep Learning (R20A6610)Document46 pagesDeep Learning (R20A6610)barakNo ratings yet
- Solution First Point ML-HW4Document6 pagesSolution First Point ML-HW4Juan Sebastian Otálora Montenegro100% (1)
- DAA Labmanual 2022-23 4semDocument76 pagesDAA Labmanual 2022-23 4semSanj AmmanagiNo ratings yet
- 30 Assignments PDFDocument5 pages30 Assignments PDFAgent SharonNo ratings yet
- ML Lab 11 Manual - Neural Networks (Ver4)Document8 pagesML Lab 11 Manual - Neural Networks (Ver4)dodela6303No ratings yet
- LR2 1Document7 pagesLR2 1Shree ShreeNo ratings yet
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- DEV Lab MaterialDocument16 pagesDEV Lab Materialdharun0704No ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- Reagrding Lab TestDocument8 pagesReagrding Lab Testaman rajNo ratings yet
- My ML Lab ManualDocument21 pagesMy ML Lab ManualAnonymous qZP5Zyb2No ratings yet
- 17csl47 2018 19 LPD PDFDocument3 pages17csl47 2018 19 LPD PDFvishwa darshiniNo ratings yet
- Assignment PDFDocument5 pagesAssignment PDFSaurabh Raghuvanshi0% (1)
- Vtu 4th Sem Design and Analysis of Algorithm ObservationDocument96 pagesVtu 4th Sem Design and Analysis of Algorithm Observationbhargav dancerNo ratings yet
- 178 hw1Document4 pages178 hw1Vijay kumarNo ratings yet
- Lab Manual: Department of Computer Science and EngineeringDocument30 pagesLab Manual: Department of Computer Science and EngineeringPARIKNo ratings yet
- Untitled 9Document17 pagesUntitled 9Vijayalakshmi GovindarajaluNo ratings yet
- PawandeepSingh AIMLDocument86 pagesPawandeepSingh AIML312poojaNo ratings yet
- Soft Computing Lab ManualDocument24 pagesSoft Computing Lab Manual[TE A-1] Chandan SinghNo ratings yet
- Deep Learning Lab (Ai&ds)Document39 pagesDeep Learning Lab (Ai&ds)BELMER GLADSON Asst. Prof. (CSE)No ratings yet
- LP III Lab ManualDocument8 pagesLP III Lab Manualsaket bharati100% (1)
- CISC520 Data Engineering and Mining: Homework 2Document1 pageCISC520 Data Engineering and Mining: Homework 2Nick PhamNo ratings yet
- 4.2.2.6 Lab - Evaluating Fit Errors in Linear RegressionDocument4 pages4.2.2.6 Lab - Evaluating Fit Errors in Linear RegressionNurul Fadillah JannahNo ratings yet
- Week10 KNN PracticalDocument4 pagesWeek10 KNN Practicalseerungen jordiNo ratings yet
- K-Nearest Neighbor (KNN) Algorithm For Machine LearningDocument17 pagesK-Nearest Neighbor (KNN) Algorithm For Machine LearningVijayalakshmi GovindarajaluNo ratings yet
- Binomial CoefficentDocument14 pagesBinomial CoefficentHarsh TibrewalNo ratings yet
- Assignment 02Document5 pagesAssignment 02Muhammad HusnainNo ratings yet
- AIML LabDocument48 pagesAIML LabD-67-Anirudh BharadwajNo ratings yet
- Unit 3 - Data ComputationDocument42 pagesUnit 3 - Data ComputationVedant GavhaneNo ratings yet
- BITS - AIML-Cohort 10 - Regression - Assignment 1Document2 pagesBITS - AIML-Cohort 10 - Regression - Assignment 1kirtikarandikar1No ratings yet
- Vishal AIML 2.2Document4 pagesVishal AIML 2.2Vishal SinghNo ratings yet
- Machine Learning: E0270 2015 Assignment 4: Due March 24 Before ClassDocument3 pagesMachine Learning: E0270 2015 Assignment 4: Due March 24 Before ClassMahesh YadaNo ratings yet
- Final Lab ManualDocument34 pagesFinal Lab ManualSNEHAL RALEBHATNo ratings yet
- 178 hw3Document3 pages178 hw3jagaenatorNo ratings yet
- ML Lab Manual TE 2021-22Document43 pagesML Lab Manual TE 2021-22FD04 Alok KaduNo ratings yet
- DTEXP5Document8 pagesDTEXP5Sanya SinghNo ratings yet
- A Study On Software Effort Prediction Using Machine Learning TechniquesDocument15 pagesA Study On Software Effort Prediction Using Machine Learning TechniquesFranckNo ratings yet
- Machine Learning Lab Manual 7Document8 pagesMachine Learning Lab Manual 7Raheel Aslam100% (1)
- Cs294a 2011 AssignmentDocument5 pagesCs294a 2011 AssignmentJoseNo ratings yet
- Exercise 02 RadonovIvan 5967988Document1 pageExercise 02 RadonovIvan 5967988ErikaNo ratings yet
- Advance Machine LearningDocument4 pagesAdvance Machine Learningranjit.e10947No ratings yet
- OOP Group C1Document7 pagesOOP Group C1Aarti ThombareNo ratings yet
- Practice Final sp22Document10 pagesPractice Final sp22Ajue RamliNo ratings yet
- DAA Lab Manual Simplified VersionDocument31 pagesDAA Lab Manual Simplified Versiondeepzd517No ratings yet
- Int AI TW-PW 04Document1 pageInt AI TW-PW 04khalilkhalilb9No ratings yet
- Soft Computing Lab ManualDocument13 pagesSoft Computing Lab ManualSwarnim ShuklaNo ratings yet
- DEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABFrom EverandDEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABNo ratings yet
- Object Oriented MetricsDocument8 pagesObject Oriented Metricskamna1604No ratings yet
- Amazon Interview QuestionsDocument1 pageAmazon Interview QuestionsDeepanshu SharmaNo ratings yet
- ATHENA DEMO - November 24, 2015Document5 pagesATHENA DEMO - November 24, 2015NonaNo ratings yet
- Sample Cover Letter For Fresher Software EngineerDocument7 pagesSample Cover Letter For Fresher Software Engineergt58x6w9100% (1)
- Class Running Notes 14th 15th and 16th JulyDocument26 pagesClass Running Notes 14th 15th and 16th Julynilesh kumarNo ratings yet
- Raspberry Pi ClusterDocument22 pagesRaspberry Pi Clusterwastewater PlantnontNo ratings yet
- 6 Stack and SubroutinesDocument33 pages6 Stack and SubroutinesRajat BoraNo ratings yet
- 978 3 030 99524 9 PDFDocument591 pages978 3 030 99524 9 PDFMasala NetshivhodzaNo ratings yet
- CyberAces Module1-Windows 7 RegistryDocument13 pagesCyberAces Module1-Windows 7 RegistryAbiodun AmusatNo ratings yet
- Excel Data TableDocument4 pagesExcel Data TableClark DomingoNo ratings yet
- Viva PPT Final-1Document31 pagesViva PPT Final-1ashritha prakashNo ratings yet
- 2016 Alpine Promotion CatalogueDocument12 pages2016 Alpine Promotion CataloguePopp Laurentiu LiviuNo ratings yet
- Multiprogramming: Concurrency Improves ThroughputDocument38 pagesMultiprogramming: Concurrency Improves ThroughputFiroj AnsariNo ratings yet
- Mis CH13 PDFDocument12 pagesMis CH13 PDFMd.tanvir Rahat 1921421030No ratings yet
- Von Neumann ArchitectureDocument2 pagesVon Neumann ArchitectureAakash Floydian JoshiNo ratings yet
- Work Experience Experience: Microsoft Dynamics 365 CRMDocument1 pageWork Experience Experience: Microsoft Dynamics 365 CRMKamal9078No ratings yet
- Bus Reservation SystemDocument9 pagesBus Reservation SystemPratyush Garg100% (1)
- Assam Bio Refinery Private Limited: AccountabilityDocument6 pagesAssam Bio Refinery Private Limited: AccountabilitySiva Ram kambapuNo ratings yet
- 13.physical SecurityDocument20 pages13.physical SecurityRukhsana KousarNo ratings yet
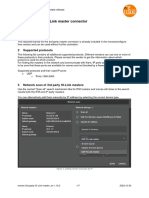
- Moneo 3rd Party IO-Link Master en 1.13.2Document7 pagesMoneo 3rd Party IO-Link Master en 1.13.2James SpadavecchiaNo ratings yet
- Foxit PDF Editor - Quick GuideDocument454 pagesFoxit PDF Editor - Quick Guideiud wahyudiNo ratings yet
- 500 Jobs in Pakistan Institute of Medical Science IslamabadDocument10 pages500 Jobs in Pakistan Institute of Medical Science IslamabadAli AsgharNo ratings yet
- Current LogDocument4 pagesCurrent Logjhonnier.cl2010No ratings yet
- Essay Artificial IntelligenceDocument2 pagesEssay Artificial IntelligenceBagas Sadewo100% (1)
- DCIT 65 Midterm ExamDocument4 pagesDCIT 65 Midterm ExamAriel AsunsionNo ratings yet
- 12 Cs Practical QP-finalDocument11 pages12 Cs Practical QP-finalJASWINDER SINGHNo ratings yet
- Arithmetic and Logic Instructions: Task PerformanceDocument2 pagesArithmetic and Logic Instructions: Task Performancekyle jezreel RubicaNo ratings yet
- At The End of The Session You Will Have Adequate Knowledge To UnderstandDocument248 pagesAt The End of The Session You Will Have Adequate Knowledge To Understandrobel100% (1)
- Arduino and DHT22 Temperature and Humidity SensorDocument36 pagesArduino and DHT22 Temperature and Humidity SensorShahana sayyedNo ratings yet