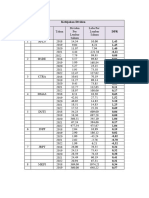
Download as docx, pdf, or txt
You might also like
- Fanuc BasicDocument0 pagesFanuc BasicMarco A. Miranda RamírezNo ratings yet
- MGT555 Group Assignment - Ba2523b - 30%Document28 pagesMGT555 Group Assignment - Ba2523b - 30%syifa azhari 3BaNo ratings yet
- Lampiran SkripsiDocument7 pagesLampiran SkripsiAlip Ba TaNo ratings yet
- Shower Bath Fullpagedownload StatistaDocument11 pagesShower Bath Fullpagedownload StatistafadNo ratings yet
- Datos Iboca Suba Enero-Junio 2020Document6 pagesDatos Iboca Suba Enero-Junio 2020Juan Esteban Moreno GarzonNo ratings yet
- From Given Dataset We Have F' As A Data Set.: Experiential Learning AssignmentDocument4 pagesFrom Given Dataset We Have F' As A Data Set.: Experiential Learning AssignmentAditya ChaudharyNo ratings yet
- Year Program Code Program Name Number of Students Appeared in The Final Year Examination Number of Students Passed in Final Year ExaminationDocument1 pageYear Program Code Program Name Number of Students Appeared in The Final Year Examination Number of Students Passed in Final Year ExaminationvijayNo ratings yet
- 1202 - ثانوية الاخلاء الاهلية للبنينDocument2 pages1202 - ثانوية الاخلاء الاهلية للبنينMatheo JohnNo ratings yet
- Annual CalendarDocument1 pageAnnual CalendarTrizia BelzaNo ratings yet
- Year Name of The Capacity Development and Skills Enhancement ProgramDocument3 pagesYear Name of The Capacity Development and Skills Enhancement Programsurya9965512212No ratings yet
- Data Meteorológica PDFDocument281 pagesData Meteorológica PDFFCISA FENIXNo ratings yet
- HectorDocument42 pagesHectorJehPoyNo ratings yet
- Group Activities g5 1Document281 pagesGroup Activities g5 12021-108960No ratings yet
- Prostate Cancer. 131020Document3 pagesProstate Cancer. 131020Jaundice henryNo ratings yet
- Vedanta LimitedDocument16 pagesVedanta LimitedtanyaNo ratings yet
- Worldwide: Acoustic Pianos & Stringed Keyboard InstrumentsDocument11 pagesWorldwide: Acoustic Pianos & Stringed Keyboard InstrumentsFernando LPNo ratings yet
- Jonathan Math SBA (Incompleted)Document7 pagesJonathan Math SBA (Incompleted)Sᴛʀᴀᴡʙᴇʀʀʏ ᴛᴀᴇNo ratings yet
- 1.2 Migration and CitizenshipDocument11 pages1.2 Migration and CitizenshipAlexander GonzálezNo ratings yet
- UntitledDocument16 pagesUntitledAlejandra Duarte GuzmanNo ratings yet
- 2018 - اعدادية مريم العذراء للبناتDocument2 pages2018 - اعدادية مريم العذراء للبناتdany.shoniNo ratings yet
- Source: Capitaline Database: Company Long Name Industry Year End Net SalesDocument9 pagesSource: Capitaline Database: Company Long Name Industry Year End Net SalesMadhuram SharmaNo ratings yet
- Notas Contabildiad 2 IP23Document1 pageNotas Contabildiad 2 IP23JavierMNS7 MTZNo ratings yet
- Assignment 1 2020 SVDocument19 pagesAssignment 1 2020 SVNguyen Dinh Quang MinhNo ratings yet
- Sheets Sheet Type Description Link Model List Ops KPI Data Calc Chart Check DashDocument15 pagesSheets Sheet Type Description Link Model List Ops KPI Data Calc Chart Check DashJesus CacharucoNo ratings yet
- RAW Data 2022-06-12T0115Document535 pagesRAW Data 2022-06-12T0115Oku SoebiyantoroNo ratings yet
- Tabulasi Data 4Document21 pagesTabulasi Data 4Nanang AdraverycildNo ratings yet
- Book 2Document4 pagesBook 2Aniket KolheNo ratings yet
- Estadísticas COVID-19 Chile: Total de Contagios Fallecidos % MortalidadDocument4 pagesEstadísticas COVID-19 Chile: Total de Contagios Fallecidos % MortalidadMartín RíosNo ratings yet
- Bangkok Expressway and Metro Public Company Limited (BEM) Opportunity Day Ye2022Document25 pagesBangkok Expressway and Metro Public Company Limited (BEM) Opportunity Day Ye2022sozodaaaNo ratings yet
- Olah Data FixDocument7 pagesOlah Data FixcikalaqilahNo ratings yet
- Worldwide: Acoustic Pianos & Stringed Keyboard InstrumentsDocument12 pagesWorldwide: Acoustic Pianos & Stringed Keyboard InstrumentsFernando LPNo ratings yet
- Reporte Pinterest Video CPCDocument7 pagesReporte Pinterest Video CPCgerson.toroNo ratings yet
- Pesto AssignmentDocument11 pagesPesto AssignmentakshiNo ratings yet
- Model 03 2 5Document16 pagesModel 03 2 5fawwad_46No ratings yet
- 34 Mail-1Document8 pages34 Mail-1shifaanjum321No ratings yet
- Notas Taller de Programacion I/2020: Nro CódigoDocument1 pageNotas Taller de Programacion I/2020: Nro CódigoHediľ M. HerreraNo ratings yet
- Lampiran Tabulasi BaruDocument3 pagesLampiran Tabulasi BaruBulan Sri AisyahNo ratings yet
- Reporte Pinterest Pin CPMDocument6 pagesReporte Pinterest Pin CPMgerson.toroNo ratings yet
- Borang HCT4 2022 MATEMATIKDocument49 pagesBorang HCT4 2022 MATEMATIKNORZALIZAH BINTI ABD. GHANI MoeNo ratings yet
- Ord - Final Conc. Ed. Inicial 2018 2019 2020-PubDocument1 pageOrd - Final Conc. Ed. Inicial 2018 2019 2020-PubJeremy BrownNo ratings yet
- Hoja de Cuantificacion de LetrasDocument1 pageHoja de Cuantificacion de LetrasJose BuesoNo ratings yet
- PTM HarianDocument11 pagesPTM Harianastuti aepNo ratings yet
- CPR The-Evolution-of-Indias-Welfare-System-from-2008-2023Document23 pagesCPR The-Evolution-of-Indias-Welfare-System-from-2008-2023rrajesh31No ratings yet
- FS3 Tuna-EmbutidoDocument3 pagesFS3 Tuna-EmbutidoManto RoderickNo ratings yet
- Ea MilkslushieDocument124 pagesEa MilkslushieFind DeviceNo ratings yet
- BOCA AssignmentDocument6 pagesBOCA AssignmentIshan AgarwalNo ratings yet
- Kape Kultura - Industry Analysis - FINALDocument8 pagesKape Kultura - Industry Analysis - FINALAndrea Lyn Salonga CacayNo ratings yet
- Suspected Active Daily Date (Current) Increase in Active Confirmed CasesDocument1 pageSuspected Active Daily Date (Current) Increase in Active Confirmed CasesGabriel Zebaoth Krisopras PutraNo ratings yet
- Suspected Active Daily Date (Current) Increase in Active Confirmed CasesDocument1 pageSuspected Active Daily Date (Current) Increase in Active Confirmed CasesGabriel Zebaoth Krisopras PutraNo ratings yet
- UntitledDocument9 pagesUntitledMariana CamargoNo ratings yet
- PROGRAMDocument1 pagePROGRAMJennifer MacefaNo ratings yet
- Luxury Fashion Fullpagedownload StatistaDocument11 pagesLuxury Fashion Fullpagedownload StatistaZoë PóvoaNo ratings yet
- Business Case Example 1.1Document15 pagesBusiness Case Example 1.1Sergei MoshenkovNo ratings yet
- Graph Project 5Document93 pagesGraph Project 5230771No ratings yet
- M2 September 2023Document8 pagesM2 September 2023Lika MalikaNo ratings yet
- Reporte Pinterest Video CPMDocument7 pagesReporte Pinterest Video CPMgerson.toroNo ratings yet
- Core Surgical Training Intake Data 2020-2023Document12 pagesCore Surgical Training Intake Data 2020-2023caelinus.augustinusNo ratings yet
- Model 01,2,3Document35 pagesModel 01,2,3fawwad_46No ratings yet
- 2019+c2year 1 700 680: EnrolmentDocument2 pages2019+c2year 1 700 680: EnrolmentRACELIE NARIDONo ratings yet
- Economic Insights from Input–Output Tables for Asia and the PacificFrom EverandEconomic Insights from Input–Output Tables for Asia and the PacificNo ratings yet
- Individual Assignment Howard SchultzDocument8 pagesIndividual Assignment Howard Schultzsyifa azhari 3BaNo ratings yet
- DGM541 Sulam Report (30%)Document18 pagesDGM541 Sulam Report (30%)syifa azhari 3BaNo ratings yet
- Fin420 Set 1 Syifa Cash BudgetDocument2 pagesFin420 Set 1 Syifa Cash Budgetsyifa azhari 3BaNo ratings yet
- ASM452 Week 1 ActivityDocument4 pagesASM452 Week 1 Activitysyifa azhari 3BaNo ratings yet
- DGM541 Final TestDocument4 pagesDGM541 Final Testsyifa azhari 3BaNo ratings yet
- INS510 Answer Tutorial Takaful ProductsDocument3 pagesINS510 Answer Tutorial Takaful Productssyifa azhari 3BaNo ratings yet
- Acc 106 Ebook Answer Topic 2Document6 pagesAcc 106 Ebook Answer Topic 2syifa azhari 3BaNo ratings yet
- Acc 106 Ebook Answer Topic 4Document13 pagesAcc 106 Ebook Answer Topic 4syifa azhari 3BaNo ratings yet
- Westernacher Consulting Global Roll Out Presentation enDocument18 pagesWesternacher Consulting Global Roll Out Presentation enStelioEduardoMucaveleNo ratings yet
- Heckler & Kock - G3 Armorer's ManualDocument50 pagesHeckler & Kock - G3 Armorer's ManualRicardo C TorresNo ratings yet
- Initial Environmental Examination: Section No. 1: Jalalabad-Kunar 220 KV Double Circuit Transmission Line ProjectDocument129 pagesInitial Environmental Examination: Section No. 1: Jalalabad-Kunar 220 KV Double Circuit Transmission Line ProjectfazailNo ratings yet
- Communication Letter - LivelihoodDocument34 pagesCommunication Letter - LivelihoodlzymxNo ratings yet
- NHM Acknowledgment of A CSR Activity by Oil India LTDDocument2 pagesNHM Acknowledgment of A CSR Activity by Oil India LTDThe WireNo ratings yet
- Combined SpecsheetDocument1 pageCombined SpecsheetApurva PatelNo ratings yet
- Book Keeping F3Document5 pagesBook Keeping F3Mohammed B.S. MakimuNo ratings yet
- Private Equity and Debt in Real EstateDocument86 pagesPrivate Equity and Debt in Real EstateashokmoryaNo ratings yet
- Duplichecker Plagiarism ReportDocument2 pagesDuplichecker Plagiarism ReportHENRYNo ratings yet
- Concept Note PSD LAB - PHARMA API PLANTDocument17 pagesConcept Note PSD LAB - PHARMA API PLANTRishabh VermaNo ratings yet
- 26-Ra Fire Fighting Pipes Threading, Grooving & PaintingDocument5 pages26-Ra Fire Fighting Pipes Threading, Grooving & PaintingAsad AyazNo ratings yet
- Comparison of Jute Fiber Over Glass FibeDocument5 pagesComparison of Jute Fiber Over Glass FibeBobby LupangoNo ratings yet
- BiometricDocument14 pagesBiometricsriram_adapaNo ratings yet
- Aonla Cultivation Is Profitable SereddyDocument3 pagesAonla Cultivation Is Profitable SereddyDr.Eswara Reddy SiddareddyNo ratings yet
- Cisco 3Document396 pagesCisco 3Vihaga JayalathNo ratings yet
- Testing and Commissioning of Current TransformerDocument1 pageTesting and Commissioning of Current Transformerjitendra jhaNo ratings yet
- LB 7 300 - Antwerp - Datasheet - EN - 2935082041 2Document2 pagesLB 7 300 - Antwerp - Datasheet - EN - 2935082041 2Ayman MedaneyNo ratings yet
- Acc Book 1st SemDocument74 pagesAcc Book 1st Semlanguage hub100% (1)
- 30V 100ah Vrla Battery & ChargerDocument11 pages30V 100ah Vrla Battery & ChargersamarbtechNo ratings yet
- SQL WindowsDocument424 pagesSQL WindowsjNo ratings yet
- Oblicon Review COMPLETE TSN 2020Document111 pagesOblicon Review COMPLETE TSN 2020Devilleres Eliza Den100% (2)
- 15mec243 - Tool Design: VII Semester - Elective Mechanical EngineeringDocument17 pages15mec243 - Tool Design: VII Semester - Elective Mechanical Engineeringvignesh100% (1)
- Student Pilot LessonsDocument1 pageStudent Pilot LessonsJunior Mebude SimbaNo ratings yet
- Ojt Questions AnswersDocument1 pageOjt Questions Answersapi-127186411No ratings yet
- Brain ChildDocument8 pagesBrain ChildGabriel PiticasNo ratings yet
- Swimming Pool Form and SOPsDocument5 pagesSwimming Pool Form and SOPsSaad AbbasiNo ratings yet
- Malena RomeroDocument1 pageMalena RomeroMaale GríaNo ratings yet
- NORDSON MINI Blue 4Document82 pagesNORDSON MINI Blue 4Gabriel ArmasNo ratings yet
- Supporting Your Small Business ClientsDocument13 pagesSupporting Your Small Business ClientsRichard Rhamil Carganillo Garcia Jr.No ratings yet