Download as pdf or txt
You might also like
- Comparative Study ChecklistDocument2 pagesComparative Study Checklist242467No ratings yet
- Lecture 5 (Bivariate ND & Error Ellipses)Document5 pagesLecture 5 (Bivariate ND & Error Ellipses)Kismet100% (4)
- OK Trigonometry 2nd Edition Blitzer Solutions Manual PDFDocument120 pagesOK Trigonometry 2nd Edition Blitzer Solutions Manual PDFRuben MejiaNo ratings yet
- The Backward Span of The Corsi Block-Tapping Task and Its Association With The WAIS-III Digit SpanDocument10 pagesThe Backward Span of The Corsi Block-Tapping Task and Its Association With The WAIS-III Digit SpanLidio ClementeNo ratings yet
- EVPA Measuring and Managing ImpactDocument140 pagesEVPA Measuring and Managing ImpactJeremiahOmwoyoNo ratings yet
- Ordinary Least Squares Linear Regression Review: Week 4Document10 pagesOrdinary Least Squares Linear Regression Review: Week 4Lalji ChandraNo ratings yet
- Corr and RegressDocument42 pagesCorr and Regresspasan lahiruNo ratings yet
- Statistics Formulas CheatsheetDocument2 pagesStatistics Formulas Cheatsheetsonsuzakadarccc100% (1)
- Topic10 WrittenDocument27 pagesTopic10 Writtenoreowhite111No ratings yet
- MATH1710 - Probability and Statistics I - Full Notes: Harry Collins 2021Document18 pagesMATH1710 - Probability and Statistics I - Full Notes: Harry Collins 2021bananacompNo ratings yet
- Notes: Section 1: Exploratory Data AnalysisDocument6 pagesNotes: Section 1: Exploratory Data AnalysisbananacompNo ratings yet
- Corr and RegressDocument61 pagesCorr and Regresskamendra chauhanNo ratings yet
- Simple Linear Regression and Its Properties 82Document8 pagesSimple Linear Regression and Its Properties 82ttvignesuwarNo ratings yet
- ECOM20001: Econometrics 1: Tutorial 2: Visualising and Describing Data in R, Summation Practice ProblemsDocument3 pagesECOM20001: Econometrics 1: Tutorial 2: Visualising and Describing Data in R, Summation Practice ProblemsalyssaNo ratings yet
- Measure of Central Tendency: Chapetr - ThreeDocument25 pagesMeasure of Central Tendency: Chapetr - Threetot stephenNo ratings yet
- General SummaryDocument55 pagesGeneral SummaryaQwhpe0fgwa0No ratings yet
- Dwnload Full Trigonometry 2nd Edition Blitzer Solutions Manual PDFDocument36 pagesDwnload Full Trigonometry 2nd Edition Blitzer Solutions Manual PDFblemzenaida2441100% (12)
- Graphs: Inflection PointsDocument36 pagesGraphs: Inflection PointsSamarjeet SalujaNo ratings yet
- Linear RegressionDocument61 pagesLinear RegressionAymen AlAwadyNo ratings yet
- Probability - Why Is $ - Bar X (1 - Bar X) + - Frac (S 2) (N) $ An Unbiased Estimator of $ - Mu (1 - Mu) $ - Mathematics Stack ExchangeDocument4 pagesProbability - Why Is $ - Bar X (1 - Bar X) + - Frac (S 2) (N) $ An Unbiased Estimator of $ - Mu (1 - Mu) $ - Mathematics Stack ExchangeScarfaceXXXNo ratings yet
- Week9 PDFDocument34 pagesWeek9 PDFosmanfıratNo ratings yet
- Chapter-3-Measures of Central TendencyDocument20 pagesChapter-3-Measures of Central TendencySimeon solomonNo ratings yet
- InferenceDocument50 pagesInferencemahdieh.toodehNo ratings yet
- TGT PGT Math Ghatna Chakra Part 2Document312 pagesTGT PGT Math Ghatna Chakra Part 2yijat18183No ratings yet
- Linear Transformation and Rank Nullity Theorem 2 LecturesDocument32 pagesLinear Transformation and Rank Nullity Theorem 2 Lecturespratyay gangulyNo ratings yet
- Statistics Formulas Cheatsheet UspceuDocument3 pagesStatistics Formulas Cheatsheet UspceukomalaNo ratings yet
- Chapter 5. Two-Dimensional Finite Elements: Plane Stress (Thin Members) Out-Of-Plane Normal and Shear Stress Are Zero X yDocument16 pagesChapter 5. Two-Dimensional Finite Elements: Plane Stress (Thin Members) Out-Of-Plane Normal and Shear Stress Are Zero X ysakeriraq81No ratings yet
- Chapter 3measures of C. TDocument26 pagesChapter 3measures of C. Tyegle TesemaNo ratings yet
- What Is Regression?Document13 pagesWhat Is Regression?Mohammad Omar FaruqNo ratings yet
- Simple RegressionDocument8 pagesSimple RegressionDlo PereraNo ratings yet
- R300 - Summer 2018 Advanced Econometric Methods Study AidDocument9 pagesR300 - Summer 2018 Advanced Econometric Methods Study AidMarco BrolliNo ratings yet
- MatricesAndVectors PDFDocument53 pagesMatricesAndVectors PDFjaslinNo ratings yet
- Aula 03 PE Eng 2S ISUTCDocument18 pagesAula 03 PE Eng 2S ISUTCTito MapireNo ratings yet
- Geometrical Transformations 2D Geometrical Transformations: TranslationDocument5 pagesGeometrical Transformations 2D Geometrical Transformations: TranslationmaheshNo ratings yet
- Math 21 SamplexDocument2 pagesMath 21 Samplexvectorredz10No ratings yet
- 311 Maths Eng Lesson12Document14 pages311 Maths Eng Lesson12Audie T. Mata0% (1)
- Interpolation and Polynomial Approximation: Professor Henry ArguelloDocument96 pagesInterpolation and Polynomial Approximation: Professor Henry ArguelloCristian MartinezNo ratings yet
- UNIT 3 Stat IDocument24 pagesUNIT 3 Stat INasri IBRAHIMNo ratings yet
- Ib Mathai HL+Document161 pagesIb Mathai HL+jobyvallikunnelNo ratings yet
- Shape 3 4Document9 pagesShape 3 4Seng HeangNo ratings yet
- Statistics Formulas CheatsheetDocument3 pagesStatistics Formulas CheatsheetCarmen Bl100% (1)
- Trigonometry 2nd Edition Blitzer Solutions ManualDocument26 pagesTrigonometry 2nd Edition Blitzer Solutions ManualSeanMorrisonsipn100% (40)
- Chapter 5 - Correlation and RegressionDocument3 pagesChapter 5 - Correlation and RegressionSayar HeinNo ratings yet
- Numerical Methodes - Chapter 4Document25 pagesNumerical Methodes - Chapter 4Eyuel BiniNo ratings yet
- Correlation Regression TheoryDocument8 pagesCorrelation Regression TheorySushree srabani SwainNo ratings yet
- AttachmentDocument97 pagesAttachmentCriss JasonNo ratings yet
- Algebra 2 Finding Inverses of Exponential FunctionsDocument2 pagesAlgebra 2 Finding Inverses of Exponential FunctionsneloNo ratings yet
- Econometrics: Problem Set 2: Professor: Mauricio SarriasDocument10 pagesEconometrics: Problem Set 2: Professor: Mauricio Sarriaspcr123No ratings yet
- Lec 9 Linear Correlation and Linear RegressionDocument71 pagesLec 9 Linear Correlation and Linear RegressionAliul HassanNo ratings yet
- Graphs of Trigonometric FunctionsDocument14 pagesGraphs of Trigonometric Functionscharlessabulao758No ratings yet
- Y9 Summer Block 5 WO3 Investigate Graphs of Simultaneous Equations H 2021Document2 pagesY9 Summer Block 5 WO3 Investigate Graphs of Simultaneous Equations H 2021Titus AnaghoNo ratings yet
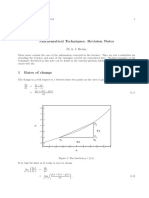
- Mathematical Techniques: Revision Notes: DR A. J. BevanDocument11 pagesMathematical Techniques: Revision Notes: DR A. J. BevanRoy VeseyNo ratings yet
- Production Planning and ControlDocument44 pagesProduction Planning and ControlShanu ShaNo ratings yet
- Properties of Sums: Problem Set 1 - Due July 16th ECON 139/239 2010 Summer Term IIDocument17 pagesProperties of Sums: Problem Set 1 - Due July 16th ECON 139/239 2010 Summer Term IIMike KaplanNo ratings yet
- Math 100 (MMW) - Activity 04Document2 pagesMath 100 (MMW) - Activity 04Lorene bbyNo ratings yet
- 033 SurbhiGole A1Document18 pages033 SurbhiGole A1Surbhi GoleNo ratings yet
- ETF2100 5910 Tutorial Week 1 SOLUTIONDocument7 pagesETF2100 5910 Tutorial Week 1 SOLUTIONFira SyawaliaNo ratings yet
- 09 01 19 Evening Paper With Answer Solution Maths PDFDocument7 pages09 01 19 Evening Paper With Answer Solution Maths PDFM jhansiNo ratings yet
- Regresion and CorrelationDocument3 pagesRegresion and CorrelationSaad Mahmud ShuvoNo ratings yet
- Correlation: We Take Two Measurements, of Two Different Physical Properties Are They Related?Document27 pagesCorrelation: We Take Two Measurements, of Two Different Physical Properties Are They Related?Jean RangelNo ratings yet
- 1 PDFDocument10 pages1 PDFLuis SahuaNo ratings yet
- Nonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970From EverandNonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Louis B. RallNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Aqa Gcse Product Design Coursework Mark SchemeDocument7 pagesAqa Gcse Product Design Coursework Mark Schemeafayepezt100% (1)
- Screening, Diagnosis and Early Intervention in Autism Spectrum DisordersDocument5 pagesScreening, Diagnosis and Early Intervention in Autism Spectrum DisordersDaniele PendezaNo ratings yet
- Site Suitability Analysis To Identify The Potential Site For Thermal Power PlantDocument9 pagesSite Suitability Analysis To Identify The Potential Site For Thermal Power PlantThayalan S KalirajNo ratings yet
- PG Growth Factory Impact Story InnosightDocument2 pagesPG Growth Factory Impact Story InnosightVishal LaheriNo ratings yet
- Chemical Wash-Saudi AramcoDocument37 pagesChemical Wash-Saudi AramcoOmid LarkiNo ratings yet
- 1 Deepa RajaDocument5 pages1 Deepa RajaAnonymous CwJeBCAXpNo ratings yet
- Brochure Performax Mental Health ServicesDocument2 pagesBrochure Performax Mental Health ServicesPerformax Health Group in Burnaby, B.C.No ratings yet
- 2.sustainable Financial Performance of Select Banks - AJBER - Dr. K. Bhavana RajDocument7 pages2.sustainable Financial Performance of Select Banks - AJBER - Dr. K. Bhavana RajDr. Bhavana Raj KNo ratings yet
- 2015 Determinants of DietarybehaviorDocument32 pages2015 Determinants of DietarybehaviorSonia Ruiz de PazNo ratings yet
- DESHABHIMANI DeffyDocument93 pagesDESHABHIMANI Deffylamiya laljiNo ratings yet
- Variabel ModeratDocument26 pagesVariabel ModeratraudhahNo ratings yet
- Final Research Group 4Document31 pagesFinal Research Group 4Kise RyotaNo ratings yet
- Advances in Advertising Research Vol 4 - The Changing Roles of AdvertisingDocument406 pagesAdvances in Advertising Research Vol 4 - The Changing Roles of AdvertisingNoam MaoniNo ratings yet
- Ge2 Readings in Philippine History Module 1Document7 pagesGe2 Readings in Philippine History Module 1Lhota AlmirolNo ratings yet
- The Genre of DescribingDocument15 pagesThe Genre of DescribingTazqia Aulia ZakhraNo ratings yet
- Teacher Guide To AssessmentDocument16 pagesTeacher Guide To AssessmentBryan James Aguirre DalawampuNo ratings yet
- Ekawati Et Al., 2023Document10 pagesEkawati Et Al., 2023Aplicacion MovilNo ratings yet
- A Project On StaffingDocument23 pagesA Project On StaffingPratyush DekaNo ratings yet
- Eastern Versus Western Culture Pricing Strategy: Superstition, Lucky Numbers, and LocalizationDocument19 pagesEastern Versus Western Culture Pricing Strategy: Superstition, Lucky Numbers, and LocalizationGeorges E. KalfatNo ratings yet
- Liaison Lesson Plan Mixed OperationsDocument3 pagesLiaison Lesson Plan Mixed Operationsapi-301812560No ratings yet
- SEG Newsletter Views Siegfried MuessigDocument3 pagesSEG Newsletter Views Siegfried MuessigCristopferENo ratings yet
- Ansari-Bradley TestDocument32 pagesAnsari-Bradley TestRohaila Rohani100% (1)
- Session1 - Introduction To Business ResearchDocument17 pagesSession1 - Introduction To Business ResearchjavoleNo ratings yet
- Alai ProtocolDocument34 pagesAlai ProtocolbillacomputersNo ratings yet
- Flowers For Algernon QuestDocument6 pagesFlowers For Algernon Questjeanna7novemberNo ratings yet
- Management Information System: - by Group IDocument15 pagesManagement Information System: - by Group Iashwinishanbhag1987No ratings yet
- 11 Gender Issues in Language ChangeDocument15 pages11 Gender Issues in Language ChangeSam LongNo ratings yet