
Unit 2 (New Syll)
Unit 2 (New Syll)
You might also like
- 2-3-Process SyncDocument64 pages2-3-Process SyncTharun RevinthNo ratings yet
- OS Lec 11 Peterson SoutionDocument16 pagesOS Lec 11 Peterson Soutionvibivo3532No ratings yet
- Process Synchronization: Chapter-6Document3 pagesProcess Synchronization: Chapter-6draveeNo ratings yet
- Process SynchronizationDocument15 pagesProcess Synchronizationaishwarya sajiNo ratings yet
- WINSEM2020-21 CSE2005 ETH VL2020210504638 Reference Material II 17-Mar-2021 OS L7 PSync 2017 8Document69 pagesWINSEM2020-21 CSE2005 ETH VL2020210504638 Reference Material II 17-Mar-2021 OS L7 PSync 2017 8Aayush ParajuliNo ratings yet
- Process SynchronizationDocument12 pagesProcess SynchronizationParkhi AcchrejaNo ratings yet
- OS L7 PSync 2017Document19 pagesOS L7 PSync 2017RiajiminNo ratings yet
- 5TH Operating System NotesDocument10 pages5TH Operating System NotesNeha Chinni50% (2)
- OS Assignment 3 (Edited)Document7 pagesOS Assignment 3 (Edited)Fahid WaseemNo ratings yet
- Chap06 1 SynchronizationDocument27 pagesChap06 1 Synchronization089- SnehilNo ratings yet
- Os-Ece (Unit 4)Document25 pagesOs-Ece (Unit 4)Shaik Khalifa biNo ratings yet
- 5 Process SynchronizaionDocument58 pages5 Process SynchronizaionLokesh SainiNo ratings yet
- 2-3-Process Sync-1Document64 pages2-3-Process Sync-1M.Micheal BerdinanthNo ratings yet
- CSt206-OS-module 3 - Part1Document14 pagesCSt206-OS-module 3 - Part1Faris BashaNo ratings yet
- CS204-OS-module 3Document14 pagesCS204-OS-module 3Abitha SajanNo ratings yet
- 1 Interprocess SynchronizationDocument91 pages1 Interprocess SynchronizationSoumya VijoyNo ratings yet
- CS211 Lec 14Document25 pagesCS211 Lec 14Muhammad RafayNo ratings yet
- Chapter 7: Process SynchronizationDocument21 pagesChapter 7: Process Synchronizationvivek gaurNo ratings yet
- 6.os Unit-Ii (Process Synchronization)Document15 pages6.os Unit-Ii (Process Synchronization)Bishnu PrasadNo ratings yet
- Module 3.1Document16 pagesModule 3.1nida61325No ratings yet
- SynchroDocument65 pagesSynchrosumitNo ratings yet
- ch6: Operating System Process SynchronizationDocument36 pagesch6: Operating System Process Synchronizationsyedabdulalishah.786No ratings yet
- ICS 143 - Principles of Operating SystemsDocument58 pagesICS 143 - Principles of Operating SystemspalegreatNo ratings yet
- Unit 3 Process SynchronizationDocument74 pagesUnit 3 Process SynchronizationHARSHITHA URS S NNo ratings yet
- AssignmentDocument3 pagesAssignmentPriya Bhatnagar100% (1)
- Operating SystemDocument2 pagesOperating SystemNijin Vinod0% (1)
- Ch-6 - Process SynchronizationDocument31 pagesCh-6 - Process SynchronizationsankarkvdcNo ratings yet
- Process SynchronizationDocument33 pagesProcess Synchronizationh4nnrtmNo ratings yet
- Dhuku NerchukoniDocument33 pagesDhuku NerchukoniRaj vamsi SrigakulamNo ratings yet
- Process Synchronization-Race Conditions - Critical Section Problem - Peterson's SolutionDocument44 pagesProcess Synchronization-Race Conditions - Critical Section Problem - Peterson's SolutionAlthaf AsharafNo ratings yet
- Process SynchronizationDocument17 pagesProcess SynchronizationManga AnimeNo ratings yet
- 6 SyncronizationDocument63 pages6 SyncronizationMuhammad SairNo ratings yet
- Synchronization ToolsDocument48 pagesSynchronization ToolsupeshithaNo ratings yet
- Interprocess Communication (IPC)Document31 pagesInterprocess Communication (IPC)elipet89No ratings yet
- 6.process SynchronizationDocument66 pages6.process Synchronizationlalithnivas2363No ratings yet
- Chapter 6 - Synchronization Tools - Part 1Document24 pagesChapter 6 - Synchronization Tools - Part 1اس اسNo ratings yet
- 9 - Critical Section ProblemDocument4 pages9 - Critical Section ProblemmanoNo ratings yet
- 1 - OS Process SynchronizationDocument23 pages1 - OS Process Synchronizationmanjeshsingh0245No ratings yet
- GM-3 1Document41 pagesGM-3 1geetha megharajNo ratings yet
- Chapter 2: Process SynchronizationDocument42 pagesChapter 2: Process SynchronizationJojoNo ratings yet
- Os Unit 2-1Document12 pagesOs Unit 2-1vy820743No ratings yet
- UNIT - III O.S NotesDocument15 pagesUNIT - III O.S NotesBapuji DCP1No ratings yet
- Operating System: Inter Process CommunicationDocument38 pagesOperating System: Inter Process CommunicationMubaraka KundawalaNo ratings yet
- Module 3 PDFDocument75 pagesModule 3 PDFRajadorai DsNo ratings yet
- Lecture 4 - Process SynchronizationDocument30 pagesLecture 4 - Process Synchronizationabdillahi binagilNo ratings yet
- OS Module2.3 SynchronizationDocument97 pagesOS Module2.3 SynchronizationDavidNo ratings yet
- OSolutionDocument4 pagesOSolutionKong Ang Li FrhNewsNo ratings yet
- 6 Process SynchronizationDocument31 pages6 Process SynchronizationPrajwal KandelNo ratings yet
- OS Process SynchronizationDocument85 pagesOS Process SynchronizationManik AnandNo ratings yet
- Unit 3 QBDocument4 pagesUnit 3 QBJashu JackNo ratings yet
- ch5 NewDocument44 pagesch5 NewShivani AppiNo ratings yet
- Os 03Document107 pagesOs 03alekhyamanda6No ratings yet
- Synchronization Tools: SemaphoresDocument50 pagesSynchronization Tools: SemaphoresWEBSITE NINJANo ratings yet
- The Critical-Section Problem: N Processes All Competing To Use Some Shared DataDocument17 pagesThe Critical-Section Problem: N Processes All Competing To Use Some Shared DataSan ChaurasiaNo ratings yet
- Module3 OSDocument66 pagesModule3 OSabinrj123No ratings yet
- ch7 Process SynchronizationDocument22 pagesch7 Process SynchronizationGeojeet tomNo ratings yet
- PROCESS SYNCHRONIZATION DsatmDocument6 pagesPROCESS SYNCHRONIZATION DsatmM.A rajaNo ratings yet
- السادسةDocument39 pagesالسادسةعزالدين صادق علي احمد الجلالNo ratings yet
- Operating System: By: Vandana KateDocument22 pagesOperating System: By: Vandana KatePriyanshu PareekNo ratings yet
- 4 455 202310301115 The Quantum Financial System What To KnowDocument2 pages4 455 202310301115 The Quantum Financial System What To KnowwepobidNo ratings yet
- Available BusyBox CommandsDocument45 pagesAvailable BusyBox CommandsSlyfester KurniawanNo ratings yet
- NWSAssignment Coppa - 022021 16022021Document9 pagesNWSAssignment Coppa - 022021 16022021456 2121No ratings yet
- IoT in Five Days - v1.1 20160627 (1) - 1-160-128-136Document9 pagesIoT in Five Days - v1.1 20160627 (1) - 1-160-128-136pham phuNo ratings yet
- Chapter 2 OS by GagneDocument12 pagesChapter 2 OS by GagneKing BoiNo ratings yet
- Copy On Write Based File Systems Performance Analysis and ImplementationDocument94 pagesCopy On Write Based File Systems Performance Analysis and ImplementationTewei Robert LuoNo ratings yet
- Wab TacnlogeyDocument70 pagesWab Tacnlogeyابن المرولهNo ratings yet
- Test Drive Fortiweb Azure CloudDocument17 pagesTest Drive Fortiweb Azure Cloudrakyat mataramNo ratings yet
- OperatorsDocument10 pagesOperatorsManas GhoshNo ratings yet
- LSMW - Valuation and NCM ChangeDocument4 pagesLSMW - Valuation and NCM ChangeRoberto RamiresNo ratings yet
- Interchange SortDocument32 pagesInterchange Sortnur_anis_8No ratings yet
- IAA202 - LAB1 - SE140442: RISK, Threats and VulnerabilitiesDocument11 pagesIAA202 - LAB1 - SE140442: RISK, Threats and VulnerabilitiesĐinh Khánh LinhNo ratings yet
- Part 1 Programming Languages C, C++, PythonDocument31 pagesPart 1 Programming Languages C, C++, PythonRamya NarayananNo ratings yet
- 1 Report of Python Programming (Manish Jangid)Document6 pages1 Report of Python Programming (Manish Jangid)Manish JangidNo ratings yet
- AWS+Partner+ +SAP+on+AWS+ (Technical) +v2.1.0+Student+GuideDocument289 pagesAWS+Partner+ +SAP+on+AWS+ (Technical) +v2.1.0+Student+GuideAndrés Rodríguez R.No ratings yet
- Barry Stinson - PostgreSQL Essential Reference-Sams (2001)Document475 pagesBarry Stinson - PostgreSQL Essential Reference-Sams (2001)Sam HydeNo ratings yet
- Lab 04 Eclipse and Git Branch MergeDocument25 pagesLab 04 Eclipse and Git Branch MergePC BhaskarNo ratings yet
- Midterm 2 Practice A KeyDocument11 pagesMidterm 2 Practice A KeysalmanshokhaNo ratings yet
- L&B Gel 8230y005Document36 pagesL&B Gel 8230y005Martinas EduardNo ratings yet
- The ICT Lounge: Computer VirusesDocument3 pagesThe ICT Lounge: Computer VirusesJedediah PhiriNo ratings yet
- Xiaomi M2101K6G Sweet 2022-10-15 21-22-23Document22 pagesXiaomi M2101K6G Sweet 2022-10-15 21-22-23Gabriel AcostaNo ratings yet
- Redp5707 - IBM Storage Scale - EncryptionDocument82 pagesRedp5707 - IBM Storage Scale - EncryptionRamon BarriosNo ratings yet
- Datasheet Controllino Mega: Ordering Information: Controllino Maxi, Art - NR: 100-200-00Document4 pagesDatasheet Controllino Mega: Ordering Information: Controllino Maxi, Art - NR: 100-200-00عبد الكريم ملوحNo ratings yet
- NotesDocument3 pagesNotesmarvsvillanNo ratings yet
- TypeScript CheatsheetsDocument10 pagesTypeScript CheatsheetsMiliNo ratings yet
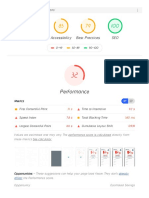
- Performance: Performance Accessibility Best Practices SEODocument6 pagesPerformance: Performance Accessibility Best Practices SEODhrumil MistryNo ratings yet
- Let Us C SolnDocument15 pagesLet Us C SolnSrinivas Surapaneni50% (2)
- PIC16F1847 Microcontroller-Based Programmable Logic Controller Hardware and Basic Concepts (Murat Uzam)Document521 pagesPIC16F1847 Microcontroller-Based Programmable Logic Controller Hardware and Basic Concepts (Murat Uzam)Andres Emilio Veloso RamirezNo ratings yet
- What Every Engineer Should Know About Software Engineering Phillip A Laplante Mohamad Kassab Online Ebook Texxtbook Full Chapter PDFDocument68 pagesWhat Every Engineer Should Know About Software Engineering Phillip A Laplante Mohamad Kassab Online Ebook Texxtbook Full Chapter PDFjdssamindbdavdr774100% (7)
- Mad QB For Practicle 2023-24Document4 pagesMad QB For Practicle 2023-24HARSH MAGHNANINo ratings yet

























































































Download as doc, pdf, or txt
You might also like
- 2-3-Process SyncDocument64 pages2-3-Process SyncTharun RevinthNo ratings yet
- OS Lec 11 Peterson SoutionDocument16 pagesOS Lec 11 Peterson Soutionvibivo3532No ratings yet
- Process Synchronization: Chapter-6Document3 pagesProcess Synchronization: Chapter-6draveeNo ratings yet
- Process SynchronizationDocument15 pagesProcess Synchronizationaishwarya sajiNo ratings yet
- WINSEM2020-21 CSE2005 ETH VL2020210504638 Reference Material II 17-Mar-2021 OS L7 PSync 2017 8Document69 pagesWINSEM2020-21 CSE2005 ETH VL2020210504638 Reference Material II 17-Mar-2021 OS L7 PSync 2017 8Aayush ParajuliNo ratings yet
- Process SynchronizationDocument12 pagesProcess SynchronizationParkhi AcchrejaNo ratings yet
- OS L7 PSync 2017Document19 pagesOS L7 PSync 2017RiajiminNo ratings yet
- 5TH Operating System NotesDocument10 pages5TH Operating System NotesNeha Chinni50% (2)
- OS Assignment 3 (Edited)Document7 pagesOS Assignment 3 (Edited)Fahid WaseemNo ratings yet
- Chap06 1 SynchronizationDocument27 pagesChap06 1 Synchronization089- SnehilNo ratings yet
- Os-Ece (Unit 4)Document25 pagesOs-Ece (Unit 4)Shaik Khalifa biNo ratings yet
- 5 Process SynchronizaionDocument58 pages5 Process SynchronizaionLokesh SainiNo ratings yet
- 2-3-Process Sync-1Document64 pages2-3-Process Sync-1M.Micheal BerdinanthNo ratings yet
- CSt206-OS-module 3 - Part1Document14 pagesCSt206-OS-module 3 - Part1Faris BashaNo ratings yet
- CS204-OS-module 3Document14 pagesCS204-OS-module 3Abitha SajanNo ratings yet
- 1 Interprocess SynchronizationDocument91 pages1 Interprocess SynchronizationSoumya VijoyNo ratings yet
- CS211 Lec 14Document25 pagesCS211 Lec 14Muhammad RafayNo ratings yet
- Chapter 7: Process SynchronizationDocument21 pagesChapter 7: Process Synchronizationvivek gaurNo ratings yet
- 6.os Unit-Ii (Process Synchronization)Document15 pages6.os Unit-Ii (Process Synchronization)Bishnu PrasadNo ratings yet
- Module 3.1Document16 pagesModule 3.1nida61325No ratings yet
- SynchroDocument65 pagesSynchrosumitNo ratings yet
- ch6: Operating System Process SynchronizationDocument36 pagesch6: Operating System Process Synchronizationsyedabdulalishah.786No ratings yet
- ICS 143 - Principles of Operating SystemsDocument58 pagesICS 143 - Principles of Operating SystemspalegreatNo ratings yet
- Unit 3 Process SynchronizationDocument74 pagesUnit 3 Process SynchronizationHARSHITHA URS S NNo ratings yet
- AssignmentDocument3 pagesAssignmentPriya Bhatnagar100% (1)
- Operating SystemDocument2 pagesOperating SystemNijin Vinod0% (1)
- Ch-6 - Process SynchronizationDocument31 pagesCh-6 - Process SynchronizationsankarkvdcNo ratings yet
- Process SynchronizationDocument33 pagesProcess Synchronizationh4nnrtmNo ratings yet
- Dhuku NerchukoniDocument33 pagesDhuku NerchukoniRaj vamsi SrigakulamNo ratings yet
- Process Synchronization-Race Conditions - Critical Section Problem - Peterson's SolutionDocument44 pagesProcess Synchronization-Race Conditions - Critical Section Problem - Peterson's SolutionAlthaf AsharafNo ratings yet
- Process SynchronizationDocument17 pagesProcess SynchronizationManga AnimeNo ratings yet
- 6 SyncronizationDocument63 pages6 SyncronizationMuhammad SairNo ratings yet
- Synchronization ToolsDocument48 pagesSynchronization ToolsupeshithaNo ratings yet
- Interprocess Communication (IPC)Document31 pagesInterprocess Communication (IPC)elipet89No ratings yet
- 6.process SynchronizationDocument66 pages6.process Synchronizationlalithnivas2363No ratings yet
- Chapter 6 - Synchronization Tools - Part 1Document24 pagesChapter 6 - Synchronization Tools - Part 1اس اسNo ratings yet
- 9 - Critical Section ProblemDocument4 pages9 - Critical Section ProblemmanoNo ratings yet
- 1 - OS Process SynchronizationDocument23 pages1 - OS Process Synchronizationmanjeshsingh0245No ratings yet
- GM-3 1Document41 pagesGM-3 1geetha megharajNo ratings yet
- Chapter 2: Process SynchronizationDocument42 pagesChapter 2: Process SynchronizationJojoNo ratings yet
- Os Unit 2-1Document12 pagesOs Unit 2-1vy820743No ratings yet
- UNIT - III O.S NotesDocument15 pagesUNIT - III O.S NotesBapuji DCP1No ratings yet
- Operating System: Inter Process CommunicationDocument38 pagesOperating System: Inter Process CommunicationMubaraka KundawalaNo ratings yet
- Module 3 PDFDocument75 pagesModule 3 PDFRajadorai DsNo ratings yet
- Lecture 4 - Process SynchronizationDocument30 pagesLecture 4 - Process Synchronizationabdillahi binagilNo ratings yet
- OS Module2.3 SynchronizationDocument97 pagesOS Module2.3 SynchronizationDavidNo ratings yet
- OSolutionDocument4 pagesOSolutionKong Ang Li FrhNewsNo ratings yet
- 6 Process SynchronizationDocument31 pages6 Process SynchronizationPrajwal KandelNo ratings yet
- OS Process SynchronizationDocument85 pagesOS Process SynchronizationManik AnandNo ratings yet
- Unit 3 QBDocument4 pagesUnit 3 QBJashu JackNo ratings yet
- ch5 NewDocument44 pagesch5 NewShivani AppiNo ratings yet
- Os 03Document107 pagesOs 03alekhyamanda6No ratings yet
- Synchronization Tools: SemaphoresDocument50 pagesSynchronization Tools: SemaphoresWEBSITE NINJANo ratings yet
- The Critical-Section Problem: N Processes All Competing To Use Some Shared DataDocument17 pagesThe Critical-Section Problem: N Processes All Competing To Use Some Shared DataSan ChaurasiaNo ratings yet
- Module3 OSDocument66 pagesModule3 OSabinrj123No ratings yet
- ch7 Process SynchronizationDocument22 pagesch7 Process SynchronizationGeojeet tomNo ratings yet
- PROCESS SYNCHRONIZATION DsatmDocument6 pagesPROCESS SYNCHRONIZATION DsatmM.A rajaNo ratings yet
- السادسةDocument39 pagesالسادسةعزالدين صادق علي احمد الجلالNo ratings yet
- Operating System: By: Vandana KateDocument22 pagesOperating System: By: Vandana KatePriyanshu PareekNo ratings yet
- 4 455 202310301115 The Quantum Financial System What To KnowDocument2 pages4 455 202310301115 The Quantum Financial System What To KnowwepobidNo ratings yet
- Available BusyBox CommandsDocument45 pagesAvailable BusyBox CommandsSlyfester KurniawanNo ratings yet
- NWSAssignment Coppa - 022021 16022021Document9 pagesNWSAssignment Coppa - 022021 16022021456 2121No ratings yet
- IoT in Five Days - v1.1 20160627 (1) - 1-160-128-136Document9 pagesIoT in Five Days - v1.1 20160627 (1) - 1-160-128-136pham phuNo ratings yet
- Chapter 2 OS by GagneDocument12 pagesChapter 2 OS by GagneKing BoiNo ratings yet
- Copy On Write Based File Systems Performance Analysis and ImplementationDocument94 pagesCopy On Write Based File Systems Performance Analysis and ImplementationTewei Robert LuoNo ratings yet
- Wab TacnlogeyDocument70 pagesWab Tacnlogeyابن المرولهNo ratings yet
- Test Drive Fortiweb Azure CloudDocument17 pagesTest Drive Fortiweb Azure Cloudrakyat mataramNo ratings yet
- OperatorsDocument10 pagesOperatorsManas GhoshNo ratings yet
- LSMW - Valuation and NCM ChangeDocument4 pagesLSMW - Valuation and NCM ChangeRoberto RamiresNo ratings yet
- Interchange SortDocument32 pagesInterchange Sortnur_anis_8No ratings yet
- IAA202 - LAB1 - SE140442: RISK, Threats and VulnerabilitiesDocument11 pagesIAA202 - LAB1 - SE140442: RISK, Threats and VulnerabilitiesĐinh Khánh LinhNo ratings yet
- Part 1 Programming Languages C, C++, PythonDocument31 pagesPart 1 Programming Languages C, C++, PythonRamya NarayananNo ratings yet
- 1 Report of Python Programming (Manish Jangid)Document6 pages1 Report of Python Programming (Manish Jangid)Manish JangidNo ratings yet
- AWS+Partner+ +SAP+on+AWS+ (Technical) +v2.1.0+Student+GuideDocument289 pagesAWS+Partner+ +SAP+on+AWS+ (Technical) +v2.1.0+Student+GuideAndrés Rodríguez R.No ratings yet
- Barry Stinson - PostgreSQL Essential Reference-Sams (2001)Document475 pagesBarry Stinson - PostgreSQL Essential Reference-Sams (2001)Sam HydeNo ratings yet
- Lab 04 Eclipse and Git Branch MergeDocument25 pagesLab 04 Eclipse and Git Branch MergePC BhaskarNo ratings yet
- Midterm 2 Practice A KeyDocument11 pagesMidterm 2 Practice A KeysalmanshokhaNo ratings yet
- L&B Gel 8230y005Document36 pagesL&B Gel 8230y005Martinas EduardNo ratings yet
- The ICT Lounge: Computer VirusesDocument3 pagesThe ICT Lounge: Computer VirusesJedediah PhiriNo ratings yet
- Xiaomi M2101K6G Sweet 2022-10-15 21-22-23Document22 pagesXiaomi M2101K6G Sweet 2022-10-15 21-22-23Gabriel AcostaNo ratings yet
- Redp5707 - IBM Storage Scale - EncryptionDocument82 pagesRedp5707 - IBM Storage Scale - EncryptionRamon BarriosNo ratings yet
- Datasheet Controllino Mega: Ordering Information: Controllino Maxi, Art - NR: 100-200-00Document4 pagesDatasheet Controllino Mega: Ordering Information: Controllino Maxi, Art - NR: 100-200-00عبد الكريم ملوحNo ratings yet
- NotesDocument3 pagesNotesmarvsvillanNo ratings yet
- TypeScript CheatsheetsDocument10 pagesTypeScript CheatsheetsMiliNo ratings yet
- Performance: Performance Accessibility Best Practices SEODocument6 pagesPerformance: Performance Accessibility Best Practices SEODhrumil MistryNo ratings yet
- Let Us C SolnDocument15 pagesLet Us C SolnSrinivas Surapaneni50% (2)
- PIC16F1847 Microcontroller-Based Programmable Logic Controller Hardware and Basic Concepts (Murat Uzam)Document521 pagesPIC16F1847 Microcontroller-Based Programmable Logic Controller Hardware and Basic Concepts (Murat Uzam)Andres Emilio Veloso RamirezNo ratings yet
- What Every Engineer Should Know About Software Engineering Phillip A Laplante Mohamad Kassab Online Ebook Texxtbook Full Chapter PDFDocument68 pagesWhat Every Engineer Should Know About Software Engineering Phillip A Laplante Mohamad Kassab Online Ebook Texxtbook Full Chapter PDFjdssamindbdavdr774100% (7)
- Mad QB For Practicle 2023-24Document4 pagesMad QB For Practicle 2023-24HARSH MAGHNANINo ratings yet