
LDA Code
LDA Code
You might also like
- Assignment 8Document6 pagesAssignment 8Ray GuoNo ratings yet
- Twitter Sentiment AnalysisDocument13 pagesTwitter Sentiment AnalysisamnwqNo ratings yet
- Fetal Health Analysis Dense Model: # Importing The DependinceDocument35 pagesFetal Health Analysis Dense Model: # Importing The DependinceRony Arturo Bocangel Salas100% (1)
- Output1Document8 pagesOutput1Laptop-Dimas-249No ratings yet
- PDF To JpegDocument7 pagesPDF To Jpegdarshanram.g9141No ratings yet
- M5 ArraysDocument31 pagesM5 Arraysdonemoremaregere376No ratings yet
- APC - Arrays 2 ProgramsDocument25 pagesAPC - Arrays 2 ProgramsJoel NathanaelNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Calculating P-ValueDocument3 pagesCalculating P-ValueMuhammad IsmaelNo ratings yet
- Assignment 1Document6 pagesAssignment 1Akshata ChopadeNo ratings yet
- Swe-102 Lab 04!Document6 pagesSwe-102 Lab 04!Hammad QamarNo ratings yet
- Machine Learning Lab Assignment CSE-716: S. M. Shafkat Raihan ID: 16701041 SESSION: 2015-16Document9 pagesMachine Learning Lab Assignment CSE-716: S. M. Shafkat Raihan ID: 16701041 SESSION: 2015-16Enaqkat PainavNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- CSEE1121: Computer Programming Lab: ObjectiveDocument11 pagesCSEE1121: Computer Programming Lab: ObjectiveRana JahanzaibNo ratings yet
- ML BusinessReport SukanyaDocument26 pagesML BusinessReport SukanyaSukanya ManickavelNo ratings yet
- 6 - 10 PythonDocument6 pages6 - 10 PythonVasudevanNo ratings yet
- Assignment: Name: Md. Nasim Uddin ID: 15162103276 Intake: 32 Section: 07Document8 pagesAssignment: Name: Md. Nasim Uddin ID: 15162103276 Intake: 32 Section: 07Md NasimNo ratings yet
- MIT6 00SCS11 Lec20 PDFDocument3 pagesMIT6 00SCS11 Lec20 PDFmedropyNo ratings yet
- Art With Python: TurtleDocument72 pagesArt With Python: TurtleManoj m emcsNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- Arrays and StringsDocument25 pagesArrays and StringsNaveen ReddyNo ratings yet
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- 'Iris': Import As Import As Import As Import AsDocument5 pages'Iris': Import As Import As Import As Import Asadel hanyNo ratings yet
- Serban Nichifor - Signals 5 (Echoes) For Taragot or ClarinetDocument2 pagesSerban Nichifor - Signals 5 (Echoes) For Taragot or ClarinetOrkay PazarcıNo ratings yet
- Daily Task 9 - Statistical Tests - Jupyter NotebookDocument12 pagesDaily Task 9 - Statistical Tests - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Python VariablesDocument21 pagesPython VariablesTomNo ratings yet
- Swe-102 Lab 09Document10 pagesSwe-102 Lab 09Huzaifa Ali KhanNo ratings yet
- Class 10 LoopDocument16 pagesClass 10 LoopTheAncient01No ratings yet
- Practice TestDocument12 pagesPractice TestSanjayNo ratings yet
- ML AssignmentDocument8 pagesML AssignmentHimalaya SagarNo ratings yet
- CP1 - Unit 10 ArrayDocument11 pagesCP1 - Unit 10 ArrayNathaniel NapayNo ratings yet
- 8 - Logistic - Regression - Multiclass - Ipynb - ColaboratoryDocument6 pages8 - Logistic - Regression - Multiclass - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Live Problem Solving Session (21!12!2022)Document1 pageLive Problem Solving Session (21!12!2022)deckcadet4No ratings yet
- Lab - 5 (CB - En.u4ece22115)Document5 pagesLab - 5 (CB - En.u4ece22115)Daejuswaram GopinathNo ratings yet
- Import Import As Import As: #Default To CSVDocument6 pagesImport Import As Import As: #Default To CSVNekomancer DavionNo ratings yet
- Arrays II: 12.1 More Array BasicsDocument23 pagesArrays II: 12.1 More Array BasicsconstantrazNo ratings yet
- Exercise Univariate Analysis - Andoni Fikri - 13118111Document9 pagesExercise Univariate Analysis - Andoni Fikri - 13118111andonifikriNo ratings yet
- Day89 90 Loan Predictions Model 1706059551Document25 pagesDay89 90 Loan Predictions Model 1706059551Eliana MoralesNo ratings yet
- DataCamp-Chapter 4Document39 pagesDataCamp-Chapter 4tesisNo ratings yet
- Computing Fundamentals: Dr. Muhammad Yousaf HamzaDocument45 pagesComputing Fundamentals: Dr. Muhammad Yousaf HamzaAr rehmanNo ratings yet
- Chapter4 ArraysDocument57 pagesChapter4 Arrayssuccess SuccessNo ratings yet
- Tutorial 2 - HistogramDocument9 pagesTutorial 2 - HistogramAnwar ZainuddinNo ratings yet
- BasuDocument14 pagesBasubasavarajparapur514No ratings yet
- Linear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsDocument2 pagesLinear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsmansiNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- MLprac 3Document2 pagesMLprac 3T42 BEIT3OO43 Kundalia Harsh H.No ratings yet
- Software Technology and Quality Assurance Lab ETCS 453: Faculty Name: Enrolment No: 07814802717 Semester: 7 SemDocument67 pagesSoftware Technology and Quality Assurance Lab ETCS 453: Faculty Name: Enrolment No: 07814802717 Semester: 7 SemAkshat AjayNo ratings yet
- Course Title: Computer Programming and Computations SessionalDocument20 pagesCourse Title: Computer Programming and Computations SessionalShifat RashidNo ratings yet
- Assignment2 PDFDocument4 pagesAssignment2 PDFJavier GonzalezNo ratings yet
- Sample of University of Michigan School of Information Masters of Applied Data Science Python and Statistics AssessmentsDocument5 pagesSample of University of Michigan School of Information Masters of Applied Data Science Python and Statistics AssessmentsJake SternNo ratings yet
- Chapter 4Document34 pagesChapter 4Javier GonzalezNo ratings yet
- Lecture 2 - Control Statements in PythonDocument29 pagesLecture 2 - Control Statements in Pythondidarulislam2460No ratings yet
- The Normal DistributionDocument94 pagesThe Normal DistributionwexoutletbrandNo ratings yet
- Experiment 8 & 9Document14 pagesExperiment 8 & 9Sharath ChandanNo ratings yet
- 1 - All Python Codes + Neo4j SamplesDocument16 pages1 - All Python Codes + Neo4j SamplesSadaf FarooqNo ratings yet
- Designing Machine Learning Workflows in Python Chapter4Document38 pagesDesigning Machine Learning Workflows in Python Chapter4FgpeqwNo ratings yet
- Lecture 9 Arrays IDocument27 pagesLecture 9 Arrays IMahmoud HossamNo ratings yet
- Capitulo2 RDocument8 pagesCapitulo2 Ringdatu1No ratings yet
- Operastion On Sets and Venn DiagramDocument19 pagesOperastion On Sets and Venn DiagramsamiNo ratings yet
- Aas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)Document3 pagesAas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)John P. BandoquilloNo ratings yet
- Airport Service TimesDocument19 pagesAirport Service Timesnartha wayneNo ratings yet
- Obv Ma Histo MTF Arrows + Alerts - mq4Document7 pagesObv Ma Histo MTF Arrows + Alerts - mq4Luís MarceloNo ratings yet
- Tugas Praktikum Metode ElektromagnetikDocument6 pagesTugas Praktikum Metode ElektromagnetikIkhsan CahyadiNo ratings yet
- Scater DiagramDocument3 pagesScater Diagramanita tri hastutiNo ratings yet
- X-Bar & R Chart Template RevDocument8 pagesX-Bar & R Chart Template RevmanjushreeNo ratings yet
- B4 NotesDocument12 pagesB4 NotesyashNo ratings yet
- Data Visualization Using RDocument26 pagesData Visualization Using Rshiva shangariNo ratings yet
- Histogram ExampleDocument7 pagesHistogram Exampletomar_muditNo ratings yet
- Data Visualisation Lab Digital Assignment 2: Name: Samar Abbas Naqvi Registration Number: 19BCE0456Document7 pagesData Visualisation Lab Digital Assignment 2: Name: Samar Abbas Naqvi Registration Number: 19BCE0456SAMAR ABBAS NAQVI 19BCE0456No ratings yet
- Box Plot: 1º Quartil Mediana 3º Quartil Box Plot Haste Inferior Haste SuperiorDocument23 pagesBox Plot: 1º Quartil Mediana 3º Quartil Box Plot Haste Inferior Haste SuperiorMATHEUSNo ratings yet
- T4 Maths Bab 4Document13 pagesT4 Maths Bab 4KOW ZHEN QUAN MoeNo ratings yet
- 3 5 7 MovingAveragesDocument2 pages3 5 7 MovingAveragesMuhammad Nauman KhanNo ratings yet
- Modeling Class X AIDocument24 pagesModeling Class X AIAYUSH DEYNo ratings yet
- Assignment Histogram - AnswerNur NadiraDocument3 pagesAssignment Histogram - AnswerNur NadiraziqnisNo ratings yet
- Data VisualizationDocument24 pagesData VisualizationJEFFREY WILLIAMS P M 20221013No ratings yet
- Operations On Sets: Operas SetDocument7 pagesOperations On Sets: Operas SetNikkun NazzNo ratings yet
- Multi-Vari Chart (Graphing Using Minitab)Document57 pagesMulti-Vari Chart (Graphing Using Minitab)ClarkRMNo ratings yet
- Python 3 Plotting Simple GraphsDocument22 pagesPython 3 Plotting Simple Graphselz0rr0No ratings yet
- Errors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Document5 pagesErrors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Ragunathan SmgNo ratings yet
- 300 Data Interpretation D I MATHEMATICS HISTOGRAM & MISSING D IDocument8 pages300 Data Interpretation D I MATHEMATICS HISTOGRAM & MISSING D IMayank KumarNo ratings yet
- Graphical Presentation: Different Types of GraphsDocument15 pagesGraphical Presentation: Different Types of Graphsvada_soNo ratings yet
- Beyond Pie Charts Tutorial1Document81 pagesBeyond Pie Charts Tutorial1Saad MasoodNo ratings yet
- Data Visualization Short Explanation With PicturesDocument6 pagesData Visualization Short Explanation With Picturesni dewiNo ratings yet
- Nama UAS UTS Tugas Nilai AkhirDocument11 pagesNama UAS UTS Tugas Nilai AkhirRay NaramNo ratings yet
- Lesson 05 Types of Charts in TableauDocument122 pagesLesson 05 Types of Charts in Tableaumilan22mehtaNo ratings yet
- Sabirin Xidig Maxamed B5210039Document4 pagesSabirin Xidig Maxamed B5210039Sabina MaxamedNo ratings yet
- Minitab Manual 04Document4 pagesMinitab Manual 04oblex99No ratings yet




































































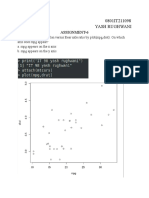




















Download as docx, pdf, or txt
You might also like
- Assignment 8Document6 pagesAssignment 8Ray GuoNo ratings yet
- Twitter Sentiment AnalysisDocument13 pagesTwitter Sentiment AnalysisamnwqNo ratings yet
- Fetal Health Analysis Dense Model: # Importing The DependinceDocument35 pagesFetal Health Analysis Dense Model: # Importing The DependinceRony Arturo Bocangel Salas100% (1)
- Output1Document8 pagesOutput1Laptop-Dimas-249No ratings yet
- PDF To JpegDocument7 pagesPDF To Jpegdarshanram.g9141No ratings yet
- M5 ArraysDocument31 pagesM5 Arraysdonemoremaregere376No ratings yet
- APC - Arrays 2 ProgramsDocument25 pagesAPC - Arrays 2 ProgramsJoel NathanaelNo ratings yet
- Effect SizeDocument9 pagesEffect Sizeapi-362845526No ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Calculating P-ValueDocument3 pagesCalculating P-ValueMuhammad IsmaelNo ratings yet
- Assignment 1Document6 pagesAssignment 1Akshata ChopadeNo ratings yet
- Swe-102 Lab 04!Document6 pagesSwe-102 Lab 04!Hammad QamarNo ratings yet
- Machine Learning Lab Assignment CSE-716: S. M. Shafkat Raihan ID: 16701041 SESSION: 2015-16Document9 pagesMachine Learning Lab Assignment CSE-716: S. M. Shafkat Raihan ID: 16701041 SESSION: 2015-16Enaqkat PainavNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- CSEE1121: Computer Programming Lab: ObjectiveDocument11 pagesCSEE1121: Computer Programming Lab: ObjectiveRana JahanzaibNo ratings yet
- ML BusinessReport SukanyaDocument26 pagesML BusinessReport SukanyaSukanya ManickavelNo ratings yet
- 6 - 10 PythonDocument6 pages6 - 10 PythonVasudevanNo ratings yet
- Assignment: Name: Md. Nasim Uddin ID: 15162103276 Intake: 32 Section: 07Document8 pagesAssignment: Name: Md. Nasim Uddin ID: 15162103276 Intake: 32 Section: 07Md NasimNo ratings yet
- MIT6 00SCS11 Lec20 PDFDocument3 pagesMIT6 00SCS11 Lec20 PDFmedropyNo ratings yet
- Art With Python: TurtleDocument72 pagesArt With Python: TurtleManoj m emcsNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- Arrays and StringsDocument25 pagesArrays and StringsNaveen ReddyNo ratings yet
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- 'Iris': Import As Import As Import As Import AsDocument5 pages'Iris': Import As Import As Import As Import Asadel hanyNo ratings yet
- Serban Nichifor - Signals 5 (Echoes) For Taragot or ClarinetDocument2 pagesSerban Nichifor - Signals 5 (Echoes) For Taragot or ClarinetOrkay PazarcıNo ratings yet
- Daily Task 9 - Statistical Tests - Jupyter NotebookDocument12 pagesDaily Task 9 - Statistical Tests - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Python VariablesDocument21 pagesPython VariablesTomNo ratings yet
- Swe-102 Lab 09Document10 pagesSwe-102 Lab 09Huzaifa Ali KhanNo ratings yet
- Class 10 LoopDocument16 pagesClass 10 LoopTheAncient01No ratings yet
- Practice TestDocument12 pagesPractice TestSanjayNo ratings yet
- ML AssignmentDocument8 pagesML AssignmentHimalaya SagarNo ratings yet
- CP1 - Unit 10 ArrayDocument11 pagesCP1 - Unit 10 ArrayNathaniel NapayNo ratings yet
- 8 - Logistic - Regression - Multiclass - Ipynb - ColaboratoryDocument6 pages8 - Logistic - Regression - Multiclass - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Live Problem Solving Session (21!12!2022)Document1 pageLive Problem Solving Session (21!12!2022)deckcadet4No ratings yet
- Lab - 5 (CB - En.u4ece22115)Document5 pagesLab - 5 (CB - En.u4ece22115)Daejuswaram GopinathNo ratings yet
- Import Import As Import As: #Default To CSVDocument6 pagesImport Import As Import As: #Default To CSVNekomancer DavionNo ratings yet
- Arrays II: 12.1 More Array BasicsDocument23 pagesArrays II: 12.1 More Array BasicsconstantrazNo ratings yet
- Exercise Univariate Analysis - Andoni Fikri - 13118111Document9 pagesExercise Univariate Analysis - Andoni Fikri - 13118111andonifikriNo ratings yet
- Day89 90 Loan Predictions Model 1706059551Document25 pagesDay89 90 Loan Predictions Model 1706059551Eliana MoralesNo ratings yet
- DataCamp-Chapter 4Document39 pagesDataCamp-Chapter 4tesisNo ratings yet
- Computing Fundamentals: Dr. Muhammad Yousaf HamzaDocument45 pagesComputing Fundamentals: Dr. Muhammad Yousaf HamzaAr rehmanNo ratings yet
- Chapter4 ArraysDocument57 pagesChapter4 Arrayssuccess SuccessNo ratings yet
- Tutorial 2 - HistogramDocument9 pagesTutorial 2 - HistogramAnwar ZainuddinNo ratings yet
- BasuDocument14 pagesBasubasavarajparapur514No ratings yet
- Linear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsDocument2 pagesLinear Regression On Iris Dataset: Sklearn - Linear - Model Sklearn - Model - Selection Sklearn - MetricsmansiNo ratings yet
- Diabetes Case Study - Jupyter NotebookDocument10 pagesDiabetes Case Study - Jupyter NotebookAbhising100% (1)
- MLprac 3Document2 pagesMLprac 3T42 BEIT3OO43 Kundalia Harsh H.No ratings yet
- Software Technology and Quality Assurance Lab ETCS 453: Faculty Name: Enrolment No: 07814802717 Semester: 7 SemDocument67 pagesSoftware Technology and Quality Assurance Lab ETCS 453: Faculty Name: Enrolment No: 07814802717 Semester: 7 SemAkshat AjayNo ratings yet
- Course Title: Computer Programming and Computations SessionalDocument20 pagesCourse Title: Computer Programming and Computations SessionalShifat RashidNo ratings yet
- Assignment2 PDFDocument4 pagesAssignment2 PDFJavier GonzalezNo ratings yet
- Sample of University of Michigan School of Information Masters of Applied Data Science Python and Statistics AssessmentsDocument5 pagesSample of University of Michigan School of Information Masters of Applied Data Science Python and Statistics AssessmentsJake SternNo ratings yet
- Chapter 4Document34 pagesChapter 4Javier GonzalezNo ratings yet
- Lecture 2 - Control Statements in PythonDocument29 pagesLecture 2 - Control Statements in Pythondidarulislam2460No ratings yet
- The Normal DistributionDocument94 pagesThe Normal DistributionwexoutletbrandNo ratings yet
- Experiment 8 & 9Document14 pagesExperiment 8 & 9Sharath ChandanNo ratings yet
- 1 - All Python Codes + Neo4j SamplesDocument16 pages1 - All Python Codes + Neo4j SamplesSadaf FarooqNo ratings yet
- Designing Machine Learning Workflows in Python Chapter4Document38 pagesDesigning Machine Learning Workflows in Python Chapter4FgpeqwNo ratings yet
- Lecture 9 Arrays IDocument27 pagesLecture 9 Arrays IMahmoud HossamNo ratings yet
- Capitulo2 RDocument8 pagesCapitulo2 Ringdatu1No ratings yet
- Operastion On Sets and Venn DiagramDocument19 pagesOperastion On Sets and Venn DiagramsamiNo ratings yet
- Aas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)Document3 pagesAas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)John P. BandoquilloNo ratings yet
- Airport Service TimesDocument19 pagesAirport Service Timesnartha wayneNo ratings yet
- Obv Ma Histo MTF Arrows + Alerts - mq4Document7 pagesObv Ma Histo MTF Arrows + Alerts - mq4Luís MarceloNo ratings yet
- Tugas Praktikum Metode ElektromagnetikDocument6 pagesTugas Praktikum Metode ElektromagnetikIkhsan CahyadiNo ratings yet
- Scater DiagramDocument3 pagesScater Diagramanita tri hastutiNo ratings yet
- X-Bar & R Chart Template RevDocument8 pagesX-Bar & R Chart Template RevmanjushreeNo ratings yet
- B4 NotesDocument12 pagesB4 NotesyashNo ratings yet
- Data Visualization Using RDocument26 pagesData Visualization Using Rshiva shangariNo ratings yet
- Histogram ExampleDocument7 pagesHistogram Exampletomar_muditNo ratings yet
- Data Visualisation Lab Digital Assignment 2: Name: Samar Abbas Naqvi Registration Number: 19BCE0456Document7 pagesData Visualisation Lab Digital Assignment 2: Name: Samar Abbas Naqvi Registration Number: 19BCE0456SAMAR ABBAS NAQVI 19BCE0456No ratings yet
- Box Plot: 1º Quartil Mediana 3º Quartil Box Plot Haste Inferior Haste SuperiorDocument23 pagesBox Plot: 1º Quartil Mediana 3º Quartil Box Plot Haste Inferior Haste SuperiorMATHEUSNo ratings yet
- T4 Maths Bab 4Document13 pagesT4 Maths Bab 4KOW ZHEN QUAN MoeNo ratings yet
- 3 5 7 MovingAveragesDocument2 pages3 5 7 MovingAveragesMuhammad Nauman KhanNo ratings yet
- Modeling Class X AIDocument24 pagesModeling Class X AIAYUSH DEYNo ratings yet
- Assignment Histogram - AnswerNur NadiraDocument3 pagesAssignment Histogram - AnswerNur NadiraziqnisNo ratings yet
- Data VisualizationDocument24 pagesData VisualizationJEFFREY WILLIAMS P M 20221013No ratings yet
- Operations On Sets: Operas SetDocument7 pagesOperations On Sets: Operas SetNikkun NazzNo ratings yet
- Multi-Vari Chart (Graphing Using Minitab)Document57 pagesMulti-Vari Chart (Graphing Using Minitab)ClarkRMNo ratings yet
- Python 3 Plotting Simple GraphsDocument22 pagesPython 3 Plotting Simple Graphselz0rr0No ratings yet
- Errors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Document5 pagesErrors While Importing Matplotlib:: General FAQ's of Week-3 (PDS)Ragunathan SmgNo ratings yet
- 300 Data Interpretation D I MATHEMATICS HISTOGRAM & MISSING D IDocument8 pages300 Data Interpretation D I MATHEMATICS HISTOGRAM & MISSING D IMayank KumarNo ratings yet
- Graphical Presentation: Different Types of GraphsDocument15 pagesGraphical Presentation: Different Types of Graphsvada_soNo ratings yet
- Beyond Pie Charts Tutorial1Document81 pagesBeyond Pie Charts Tutorial1Saad MasoodNo ratings yet
- Data Visualization Short Explanation With PicturesDocument6 pagesData Visualization Short Explanation With Picturesni dewiNo ratings yet
- Nama UAS UTS Tugas Nilai AkhirDocument11 pagesNama UAS UTS Tugas Nilai AkhirRay NaramNo ratings yet
- Lesson 05 Types of Charts in TableauDocument122 pagesLesson 05 Types of Charts in Tableaumilan22mehtaNo ratings yet
- Sabirin Xidig Maxamed B5210039Document4 pagesSabirin Xidig Maxamed B5210039Sabina MaxamedNo ratings yet
- Minitab Manual 04Document4 pagesMinitab Manual 04oblex99No ratings yet