
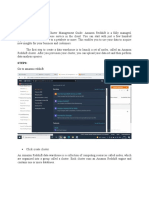
To Create A Crawler That Reads Files Stored On Amazon S3
To Create A Crawler That Reads Files Stored On Amazon S3
You might also like
- A Proposed Retreat Center Integrating Green Building MaterialsDocument52 pagesA Proposed Retreat Center Integrating Green Building MaterialsSteph Geronimo100% (7)
- Explore A Bigquery Public DatasetDocument21 pagesExplore A Bigquery Public DatasetS SarkarNo ratings yet
- AWS+Essentials+Student+Guide+Print+Out+V1 8Document56 pagesAWS+Essentials+Student+Guide+Print+Out+V1 8princechennai50% (2)
- Case Study ResearchDocument8 pagesCase Study ResearchDon Chiaw ManongdoNo ratings yet
- Exercise 3 - Processing Data in A Data LakeDocument6 pagesExercise 3 - Processing Data in A Data LakeFelipe Alejandro Morales MendivelsoNo ratings yet
- Lab Aws 14-10Document25 pagesLab Aws 14-10Ana MarroquínNo ratings yet
- Dropwodn List in GridviewDocument3 pagesDropwodn List in GridviewraghavakeshaNo ratings yet
- AWS GlueDocument10 pagesAWS GlueGnan ShettyNo ratings yet
- Walkthrough: Creating Master/Detail Web Pages in Visual StudioDocument9 pagesWalkthrough: Creating Master/Detail Web Pages in Visual StudioarchenigmaNo ratings yet
- Designer Developer - Exercises QlikViewDocument30 pagesDesigner Developer - Exercises QlikViewAlejandro FriasNo ratings yet
- Running Wordcount On AWS Elastic Map ReduceDocument26 pagesRunning Wordcount On AWS Elastic Map Reducejaytd27100% (2)
- Amazon S3 GuideDocument19 pagesAmazon S3 GuidekaredokNo ratings yet
- amazon redhsift.docxDocument25 pagesamazon redhsift.docxRishabh GuptaNo ratings yet
- Create A Regression Model With Azure Machine Learning DesignerDocument21 pagesCreate A Regression Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- Processing XML With AWS Glue and Databricks SparkDocument23 pagesProcessing XML With AWS Glue and Databricks SparksparkaredlaNo ratings yet
- SQLProfiler 2Document6 pagesSQLProfiler 2Derek YuenNo ratings yet
- Azure Data Factory For BeginnersDocument250 pagesAzure Data Factory For BeginnersRick VNo ratings yet
- Migração AWS Passo A PassoDocument125 pagesMigração AWS Passo A PassoRobson Silva AguiarNo ratings yet
- CognosDocument10 pagesCognosfriend0friend1friendNo ratings yet
- Best Tutorial of C#Document97 pagesBest Tutorial of C#dhwani1621No ratings yet
- AWS Cloud WatchDocument14 pagesAWS Cloud Watchilyas2sapNo ratings yet
- Labsforbootcamp 1682060063700Document27 pagesLabsforbootcamp 1682060063700Luis MedinelliNo ratings yet
- Create A Classification Model With Azure Machine Learning DesignerDocument19 pagesCreate A Classification Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- AthenaDocument13 pagesAthenak2shNo ratings yet
- Create A Clustering Model With Azure Machine Learning DesignerDocument22 pagesCreate A Clustering Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- AthnaDocument13 pagesAthnak2shNo ratings yet
- Exercise 8.2 - IOT AWSDocument9 pagesExercise 8.2 - IOT AWSAlexander ReyesNo ratings yet
- LAB Amazon Redshift: StepsDocument15 pagesLAB Amazon Redshift: StepsDeepasarathi MNo ratings yet
- Amazon Redshift-LabDocument14 pagesAmazon Redshift-LabDeepasarathi MNo ratings yet
- ADF Copy DataDocument85 pagesADF Copy Datavrjs27 vNo ratings yet
- Hive On Google CloudDocument16 pagesHive On Google CloudNiriNo ratings yet
- GIS & Visualisation - ArcGIS - Publishing Map Layers To ArcGIS OnlineDocument8 pagesGIS & Visualisation - ArcGIS - Publishing Map Layers To ArcGIS OnlineJamesNo ratings yet
- CC Assign5Document5 pagesCC Assign5113SOURYADIPTA DASNo ratings yet
- Migrate From On-Premises To Azure SQL DatabaseDocument20 pagesMigrate From On-Premises To Azure SQL Databaserajiv_ndpt8394No ratings yet
- Cloud Architecting Lab ManualDocument101 pagesCloud Architecting Lab ManualJsushNo ratings yet
- Elastic BeanstalkDocument8 pagesElastic BeanstalkTrinay trinayNo ratings yet
- Getting Started With Azure DevOpsDocument15 pagesGetting Started With Azure DevOpsHarishNo ratings yet
- Lab 1 - Getting Started With Azure MLDocument16 pagesLab 1 - Getting Started With Azure MLTuấn VuNo ratings yet
- Mslearn dp100 03Document3 pagesMslearn dp100 03Emily RapaniNo ratings yet
- Data Bound ComponentsDocument13 pagesData Bound ComponentsnyellutlaNo ratings yet
- MSSQL2005 Replication: Author Brijesh Kumar Date of Creation October, 2008 Email IdDocument69 pagesMSSQL2005 Replication: Author Brijesh Kumar Date of Creation October, 2008 Email IdVijay SharmaNo ratings yet
- Creating Reports Using SAS Web Analytics Aggregates and SAS Information MapsDocument20 pagesCreating Reports Using SAS Web Analytics Aggregates and SAS Information MapsDharti PatelNo ratings yet
- Azure Data Explorer From Synapse Analytics WorkspaceDocument22 pagesAzure Data Explorer From Synapse Analytics WorkspaceNataraju GaddamaduguNo ratings yet
- Us-East-1.durian - Bkr.team - Aws.training-Lab 5 Cost OptimizationDocument14 pagesUs-East-1.durian - Bkr.team - Aws.training-Lab 5 Cost OptimizationAlari AcbNo ratings yet
- My Interaction With My ChatGPTDocument6 pagesMy Interaction With My ChatGPTNageswar MakalaNo ratings yet
- Lab 7 - Orchestrating Data Movement With Azure Data FactoryDocument26 pagesLab 7 - Orchestrating Data Movement With Azure Data FactoryMangesh AbnaveNo ratings yet
- Rad SQL BrowseDocument51 pagesRad SQL Browsezpoturica569No ratings yet
- Exercise 1 - Creating An Amazon OpenSearch Service ClusterDocument11 pagesExercise 1 - Creating An Amazon OpenSearch Service ClusterFelipe Alejandro Morales MendivelsoNo ratings yet
- Understanding Parameters and PromptsDocument11 pagesUnderstanding Parameters and PromptsSwamy DanthuriNo ratings yet
- Running Azure Databricks Notebook On Synapse AnalyticsDocument12 pagesRunning Azure Databricks Notebook On Synapse AnalyticsNataraju GaddamaduguNo ratings yet
- Lab 1 - Amazon Simple Storage (S3)Document11 pagesLab 1 - Amazon Simple Storage (S3)Hector AndradeNo ratings yet
- OAF Table Region DML OperationsDocument34 pagesOAF Table Region DML Operationsnagarajuvcc123No ratings yet
- Cloud Computing Lab Tanushri (1)Document19 pagesCloud Computing Lab Tanushri (1)peacock156mstNo ratings yet
- Developing SQL and PLDocument50 pagesDeveloping SQL and PLCarlosNo ratings yet
- Lab 8 Network AnalystDocument11 pagesLab 8 Network AnalystrashmigodhaNo ratings yet
- Improve SSAS Performance With The Usage Based Optimization WizardDocument10 pagesImprove SSAS Performance With The Usage Based Optimization WizardNichaiNo ratings yet
- Building and Using Web Services JDeveloperDocument27 pagesBuilding and Using Web Services JDeveloperVivita ContrerasNo ratings yet
- Express Quantum Grid 6Document3,406 pagesExpress Quantum Grid 6Ortodoxia Tinerilor100% (1)
- Paging and Sorting Report DataDocument18 pagesPaging and Sorting Report DatasantoshNo ratings yet
- AWS - CloudFormationDocument19 pagesAWS - CloudFormationAniruddha DasguptaNo ratings yet
- Tiktok AdsDocument8 pagesTiktok AdsGaming MaFiANo ratings yet
- Third Sem (ML To AP) All PapersDocument5 pagesThird Sem (ML To AP) All PapersZERO HNo ratings yet
- IoT 22MCA304 Final IA Batch2022-24Document6 pagesIoT 22MCA304 Final IA Batch2022-24ZERO HNo ratings yet
- 4 ShapeDocument1 page4 ShapeZERO HNo ratings yet
- 1 CalculatorDocument3 pages1 CalculatorZERO HNo ratings yet
- 2.0 Intent MainDocument2 pages2.0 Intent MainZERO HNo ratings yet
- 2.1 Intent DisplayDocument1 page2.1 Intent DisplayZERO HNo ratings yet
- 3 KarnatakaDocument1 page3 KarnatakaZERO HNo ratings yet
- The Accidental Caseworker - How Digital Self-Service Influences Citizens' Administrative BurdenDocument11 pagesThe Accidental Caseworker - How Digital Self-Service Influences Citizens' Administrative BurdenIgorFilkoNo ratings yet
- Best Practices Artifactory Backups and DRDocument11 pagesBest Practices Artifactory Backups and DRSeshuNo ratings yet
- Interview Questions On MicrostrategyDocument5 pagesInterview Questions On MicrostrategySujeet NayakNo ratings yet
- Solutions For Tutorial Exercises Association Rule Mining.: Exercise 1. AprioriDocument4 pagesSolutions For Tutorial Exercises Association Rule Mining.: Exercise 1. AprioriJosé GermánNo ratings yet
- A Systematic Study On School Management and Teacher Staff Selection ProcessDocument63 pagesA Systematic Study On School Management and Teacher Staff Selection ProcessPankaj soniNo ratings yet
- Data Definition Language-DDLDocument4 pagesData Definition Language-DDLManjunatha KNo ratings yet
- AP Lab Report RubricDocument4 pagesAP Lab Report RubricIsabela MalazarteNo ratings yet
- Ey Broker Dealer Financial Regulatory ReportingDocument8 pagesEy Broker Dealer Financial Regulatory ReportingAvinash GanesanNo ratings yet
- SQL Basic Cheat SheetDocument1 pageSQL Basic Cheat SheetKunal Kashyap100% (1)
- Introducing New Oracle Features:: Oracle Database 21C, Exa X9M, Bigdatasql and Goldengate OciDocument60 pagesIntroducing New Oracle Features:: Oracle Database 21C, Exa X9M, Bigdatasql and Goldengate OciamartinbNo ratings yet
- Geographical Factors Affecting Real EstateDocument52 pagesGeographical Factors Affecting Real EstateAAPHBRSNo ratings yet
- Discover 12Document4 pagesDiscover 12Yadil Amin A. MNo ratings yet
- Annex MYCOM OSI GlossaryDocument6 pagesAnnex MYCOM OSI GlossaryRespati RanggaNo ratings yet
- (Download PDF) Digital Twin Driven Smart Design 1St Edition Fei Tao Editor Online Ebook All Chapter PDFDocument42 pages(Download PDF) Digital Twin Driven Smart Design 1St Edition Fei Tao Editor Online Ebook All Chapter PDFleslie.brooks363100% (15)
- You Have A Database That Is Experiencing Deadlock Issues When Users Run QueriesDocument3 pagesYou Have A Database That Is Experiencing Deadlock Issues When Users Run QueriesbharatNo ratings yet
- SAP BI DumpDocument16 pagesSAP BI DumpTuanNNgo100% (1)
- Seanewdim Ped Psy VII 80 Issue 198Document70 pagesSeanewdim Ped Psy VII 80 Issue 198seanewdimNo ratings yet
- RF Online Golden Mystery Setup LogDocument853 pagesRF Online Golden Mystery Setup LogSianipar Mangara Wahyu CharrosNo ratings yet
- #1 Active Research QuestionsDocument6 pages#1 Active Research QuestionsGabriela GNo ratings yet
- Redis CheatsheetDocument4 pagesRedis Cheatsheetfoobarbaz-2No ratings yet
- TCPDocument39 pagesTCPErnesto OrtizNo ratings yet
- 4.MD.4 Task 3Document2 pages4.MD.4 Task 3Nur NadzirahNo ratings yet
- Cs2302 - Computer Networks Question Bank 2-Marks Unit 1Document4 pagesCs2302 - Computer Networks Question Bank 2-Marks Unit 1Sam SureshNo ratings yet
- Pampanga - Statistical TablesDocument202 pagesPampanga - Statistical TablesShan Alay-ayNo ratings yet
- Forest Sector Market Survey - Forest InfMarkDocument23 pagesForest Sector Market Survey - Forest InfMarkHoracio LuzNo ratings yet
- Outline Seminar: Name: Ni Nyoman Ratih Purnama Sari NIM: 1701541077Document4 pagesOutline Seminar: Name: Ni Nyoman Ratih Purnama Sari NIM: 1701541077Ratih PurnamaNo ratings yet
- Geography Es 1 Sample UnitDocument4 pagesGeography Es 1 Sample UnitRomano LuisNo ratings yet
- DS ClearSee Analytics A4 LR Publish-1Document6 pagesDS ClearSee Analytics A4 LR Publish-1BronojackersNo ratings yet
































































































Download as pdf or txt
You might also like
- A Proposed Retreat Center Integrating Green Building MaterialsDocument52 pagesA Proposed Retreat Center Integrating Green Building MaterialsSteph Geronimo100% (7)
- Explore A Bigquery Public DatasetDocument21 pagesExplore A Bigquery Public DatasetS SarkarNo ratings yet
- AWS+Essentials+Student+Guide+Print+Out+V1 8Document56 pagesAWS+Essentials+Student+Guide+Print+Out+V1 8princechennai50% (2)
- Case Study ResearchDocument8 pagesCase Study ResearchDon Chiaw ManongdoNo ratings yet
- Exercise 3 - Processing Data in A Data LakeDocument6 pagesExercise 3 - Processing Data in A Data LakeFelipe Alejandro Morales MendivelsoNo ratings yet
- Lab Aws 14-10Document25 pagesLab Aws 14-10Ana MarroquínNo ratings yet
- Dropwodn List in GridviewDocument3 pagesDropwodn List in GridviewraghavakeshaNo ratings yet
- AWS GlueDocument10 pagesAWS GlueGnan ShettyNo ratings yet
- Walkthrough: Creating Master/Detail Web Pages in Visual StudioDocument9 pagesWalkthrough: Creating Master/Detail Web Pages in Visual StudioarchenigmaNo ratings yet
- Designer Developer - Exercises QlikViewDocument30 pagesDesigner Developer - Exercises QlikViewAlejandro FriasNo ratings yet
- Running Wordcount On AWS Elastic Map ReduceDocument26 pagesRunning Wordcount On AWS Elastic Map Reducejaytd27100% (2)
- Amazon S3 GuideDocument19 pagesAmazon S3 GuidekaredokNo ratings yet
- amazon redhsift.docxDocument25 pagesamazon redhsift.docxRishabh GuptaNo ratings yet
- Create A Regression Model With Azure Machine Learning DesignerDocument21 pagesCreate A Regression Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- Processing XML With AWS Glue and Databricks SparkDocument23 pagesProcessing XML With AWS Glue and Databricks SparksparkaredlaNo ratings yet
- SQLProfiler 2Document6 pagesSQLProfiler 2Derek YuenNo ratings yet
- Azure Data Factory For BeginnersDocument250 pagesAzure Data Factory For BeginnersRick VNo ratings yet
- Migração AWS Passo A PassoDocument125 pagesMigração AWS Passo A PassoRobson Silva AguiarNo ratings yet
- CognosDocument10 pagesCognosfriend0friend1friendNo ratings yet
- Best Tutorial of C#Document97 pagesBest Tutorial of C#dhwani1621No ratings yet
- AWS Cloud WatchDocument14 pagesAWS Cloud Watchilyas2sapNo ratings yet
- Labsforbootcamp 1682060063700Document27 pagesLabsforbootcamp 1682060063700Luis MedinelliNo ratings yet
- Create A Classification Model With Azure Machine Learning DesignerDocument19 pagesCreate A Classification Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- AthenaDocument13 pagesAthenak2shNo ratings yet
- Create A Clustering Model With Azure Machine Learning DesignerDocument22 pagesCreate A Clustering Model With Azure Machine Learning DesignerElanie BerghNo ratings yet
- AthnaDocument13 pagesAthnak2shNo ratings yet
- Exercise 8.2 - IOT AWSDocument9 pagesExercise 8.2 - IOT AWSAlexander ReyesNo ratings yet
- LAB Amazon Redshift: StepsDocument15 pagesLAB Amazon Redshift: StepsDeepasarathi MNo ratings yet
- Amazon Redshift-LabDocument14 pagesAmazon Redshift-LabDeepasarathi MNo ratings yet
- ADF Copy DataDocument85 pagesADF Copy Datavrjs27 vNo ratings yet
- Hive On Google CloudDocument16 pagesHive On Google CloudNiriNo ratings yet
- GIS & Visualisation - ArcGIS - Publishing Map Layers To ArcGIS OnlineDocument8 pagesGIS & Visualisation - ArcGIS - Publishing Map Layers To ArcGIS OnlineJamesNo ratings yet
- CC Assign5Document5 pagesCC Assign5113SOURYADIPTA DASNo ratings yet
- Migrate From On-Premises To Azure SQL DatabaseDocument20 pagesMigrate From On-Premises To Azure SQL Databaserajiv_ndpt8394No ratings yet
- Cloud Architecting Lab ManualDocument101 pagesCloud Architecting Lab ManualJsushNo ratings yet
- Elastic BeanstalkDocument8 pagesElastic BeanstalkTrinay trinayNo ratings yet
- Getting Started With Azure DevOpsDocument15 pagesGetting Started With Azure DevOpsHarishNo ratings yet
- Lab 1 - Getting Started With Azure MLDocument16 pagesLab 1 - Getting Started With Azure MLTuấn VuNo ratings yet
- Mslearn dp100 03Document3 pagesMslearn dp100 03Emily RapaniNo ratings yet
- Data Bound ComponentsDocument13 pagesData Bound ComponentsnyellutlaNo ratings yet
- MSSQL2005 Replication: Author Brijesh Kumar Date of Creation October, 2008 Email IdDocument69 pagesMSSQL2005 Replication: Author Brijesh Kumar Date of Creation October, 2008 Email IdVijay SharmaNo ratings yet
- Creating Reports Using SAS Web Analytics Aggregates and SAS Information MapsDocument20 pagesCreating Reports Using SAS Web Analytics Aggregates and SAS Information MapsDharti PatelNo ratings yet
- Azure Data Explorer From Synapse Analytics WorkspaceDocument22 pagesAzure Data Explorer From Synapse Analytics WorkspaceNataraju GaddamaduguNo ratings yet
- Us-East-1.durian - Bkr.team - Aws.training-Lab 5 Cost OptimizationDocument14 pagesUs-East-1.durian - Bkr.team - Aws.training-Lab 5 Cost OptimizationAlari AcbNo ratings yet
- My Interaction With My ChatGPTDocument6 pagesMy Interaction With My ChatGPTNageswar MakalaNo ratings yet
- Lab 7 - Orchestrating Data Movement With Azure Data FactoryDocument26 pagesLab 7 - Orchestrating Data Movement With Azure Data FactoryMangesh AbnaveNo ratings yet
- Rad SQL BrowseDocument51 pagesRad SQL Browsezpoturica569No ratings yet
- Exercise 1 - Creating An Amazon OpenSearch Service ClusterDocument11 pagesExercise 1 - Creating An Amazon OpenSearch Service ClusterFelipe Alejandro Morales MendivelsoNo ratings yet
- Understanding Parameters and PromptsDocument11 pagesUnderstanding Parameters and PromptsSwamy DanthuriNo ratings yet
- Running Azure Databricks Notebook On Synapse AnalyticsDocument12 pagesRunning Azure Databricks Notebook On Synapse AnalyticsNataraju GaddamaduguNo ratings yet
- Lab 1 - Amazon Simple Storage (S3)Document11 pagesLab 1 - Amazon Simple Storage (S3)Hector AndradeNo ratings yet
- OAF Table Region DML OperationsDocument34 pagesOAF Table Region DML Operationsnagarajuvcc123No ratings yet
- Cloud Computing Lab Tanushri (1)Document19 pagesCloud Computing Lab Tanushri (1)peacock156mstNo ratings yet
- Developing SQL and PLDocument50 pagesDeveloping SQL and PLCarlosNo ratings yet
- Lab 8 Network AnalystDocument11 pagesLab 8 Network AnalystrashmigodhaNo ratings yet
- Improve SSAS Performance With The Usage Based Optimization WizardDocument10 pagesImprove SSAS Performance With The Usage Based Optimization WizardNichaiNo ratings yet
- Building and Using Web Services JDeveloperDocument27 pagesBuilding and Using Web Services JDeveloperVivita ContrerasNo ratings yet
- Express Quantum Grid 6Document3,406 pagesExpress Quantum Grid 6Ortodoxia Tinerilor100% (1)
- Paging and Sorting Report DataDocument18 pagesPaging and Sorting Report DatasantoshNo ratings yet
- AWS - CloudFormationDocument19 pagesAWS - CloudFormationAniruddha DasguptaNo ratings yet
- Tiktok AdsDocument8 pagesTiktok AdsGaming MaFiANo ratings yet
- Third Sem (ML To AP) All PapersDocument5 pagesThird Sem (ML To AP) All PapersZERO HNo ratings yet
- IoT 22MCA304 Final IA Batch2022-24Document6 pagesIoT 22MCA304 Final IA Batch2022-24ZERO HNo ratings yet
- 4 ShapeDocument1 page4 ShapeZERO HNo ratings yet
- 1 CalculatorDocument3 pages1 CalculatorZERO HNo ratings yet
- 2.0 Intent MainDocument2 pages2.0 Intent MainZERO HNo ratings yet
- 2.1 Intent DisplayDocument1 page2.1 Intent DisplayZERO HNo ratings yet
- 3 KarnatakaDocument1 page3 KarnatakaZERO HNo ratings yet
- The Accidental Caseworker - How Digital Self-Service Influences Citizens' Administrative BurdenDocument11 pagesThe Accidental Caseworker - How Digital Self-Service Influences Citizens' Administrative BurdenIgorFilkoNo ratings yet
- Best Practices Artifactory Backups and DRDocument11 pagesBest Practices Artifactory Backups and DRSeshuNo ratings yet
- Interview Questions On MicrostrategyDocument5 pagesInterview Questions On MicrostrategySujeet NayakNo ratings yet
- Solutions For Tutorial Exercises Association Rule Mining.: Exercise 1. AprioriDocument4 pagesSolutions For Tutorial Exercises Association Rule Mining.: Exercise 1. AprioriJosé GermánNo ratings yet
- A Systematic Study On School Management and Teacher Staff Selection ProcessDocument63 pagesA Systematic Study On School Management and Teacher Staff Selection ProcessPankaj soniNo ratings yet
- Data Definition Language-DDLDocument4 pagesData Definition Language-DDLManjunatha KNo ratings yet
- AP Lab Report RubricDocument4 pagesAP Lab Report RubricIsabela MalazarteNo ratings yet
- Ey Broker Dealer Financial Regulatory ReportingDocument8 pagesEy Broker Dealer Financial Regulatory ReportingAvinash GanesanNo ratings yet
- SQL Basic Cheat SheetDocument1 pageSQL Basic Cheat SheetKunal Kashyap100% (1)
- Introducing New Oracle Features:: Oracle Database 21C, Exa X9M, Bigdatasql and Goldengate OciDocument60 pagesIntroducing New Oracle Features:: Oracle Database 21C, Exa X9M, Bigdatasql and Goldengate OciamartinbNo ratings yet
- Geographical Factors Affecting Real EstateDocument52 pagesGeographical Factors Affecting Real EstateAAPHBRSNo ratings yet
- Discover 12Document4 pagesDiscover 12Yadil Amin A. MNo ratings yet
- Annex MYCOM OSI GlossaryDocument6 pagesAnnex MYCOM OSI GlossaryRespati RanggaNo ratings yet
- (Download PDF) Digital Twin Driven Smart Design 1St Edition Fei Tao Editor Online Ebook All Chapter PDFDocument42 pages(Download PDF) Digital Twin Driven Smart Design 1St Edition Fei Tao Editor Online Ebook All Chapter PDFleslie.brooks363100% (15)
- You Have A Database That Is Experiencing Deadlock Issues When Users Run QueriesDocument3 pagesYou Have A Database That Is Experiencing Deadlock Issues When Users Run QueriesbharatNo ratings yet
- SAP BI DumpDocument16 pagesSAP BI DumpTuanNNgo100% (1)
- Seanewdim Ped Psy VII 80 Issue 198Document70 pagesSeanewdim Ped Psy VII 80 Issue 198seanewdimNo ratings yet
- RF Online Golden Mystery Setup LogDocument853 pagesRF Online Golden Mystery Setup LogSianipar Mangara Wahyu CharrosNo ratings yet
- #1 Active Research QuestionsDocument6 pages#1 Active Research QuestionsGabriela GNo ratings yet
- Redis CheatsheetDocument4 pagesRedis Cheatsheetfoobarbaz-2No ratings yet
- TCPDocument39 pagesTCPErnesto OrtizNo ratings yet
- 4.MD.4 Task 3Document2 pages4.MD.4 Task 3Nur NadzirahNo ratings yet
- Cs2302 - Computer Networks Question Bank 2-Marks Unit 1Document4 pagesCs2302 - Computer Networks Question Bank 2-Marks Unit 1Sam SureshNo ratings yet
- Pampanga - Statistical TablesDocument202 pagesPampanga - Statistical TablesShan Alay-ayNo ratings yet
- Forest Sector Market Survey - Forest InfMarkDocument23 pagesForest Sector Market Survey - Forest InfMarkHoracio LuzNo ratings yet
- Outline Seminar: Name: Ni Nyoman Ratih Purnama Sari NIM: 1701541077Document4 pagesOutline Seminar: Name: Ni Nyoman Ratih Purnama Sari NIM: 1701541077Ratih PurnamaNo ratings yet
- Geography Es 1 Sample UnitDocument4 pagesGeography Es 1 Sample UnitRomano LuisNo ratings yet
- DS ClearSee Analytics A4 LR Publish-1Document6 pagesDS ClearSee Analytics A4 LR Publish-1BronojackersNo ratings yet