Download as docx, pdf, or txt
You might also like
- 0057 Olivia Lancaster - Extended EssayDocument18 pages0057 Olivia Lancaster - Extended Essayapi-38378364875% (4)
- Sample Sizes - Cannon & RoeDocument14 pagesSample Sizes - Cannon & Roeapi-3835746100% (5)
- Life Extension: A Practical Scientific Approach - The Life Extension Weight Loss Program - Pearson, Durk Shaw, SandyDocument392 pagesLife Extension: A Practical Scientific Approach - The Life Extension Weight Loss Program - Pearson, Durk Shaw, Sandypdf ebook free download100% (4)
- Sample Marketing PlanDocument28 pagesSample Marketing Plananon-29817596% (24)
- Manul PMM MoriseikiDocument8 pagesManul PMM MoriseikiPhong HuynhNo ratings yet
- Result-PMDC-NEB (Medical) Basic-Step-I-20141011Document1 pageResult-PMDC-NEB (Medical) Basic-Step-I-20141011S SNo ratings yet
- Combined Prov Select List 170910Document422 pagesCombined Prov Select List 170910reachranandNo ratings yet
- ISO Hazard SymbolsDocument105 pagesISO Hazard SymbolsburggrayNo ratings yet
- SKDR Rsu KertayasaDocument222 pagesSKDR Rsu Kertayasaanon_507132438No ratings yet
- Random Start: ST ND RD TH THDocument3 pagesRandom Start: ST ND RD TH THrom keroNo ratings yet
- For Correction of Data CDRAProfileGADGAD DatabaseDocument272 pagesFor Correction of Data CDRAProfileGADGAD DatabaseTifanny Kristel Ann GalaponNo ratings yet
- Calgary Seniors Population Profiles 2011Document37 pagesCalgary Seniors Population Profiles 201169399olyNo ratings yet
- Results 2009 DSSSB Je NetDocument6 pagesResults 2009 DSSSB Je Netro4uonline2090100% (1)
- Factors Kindergarten Grade 1 Grade 2 Lardos Lardos LardosDocument13 pagesFactors Kindergarten Grade 1 Grade 2 Lardos Lardos LardosCHAPEL JUN PACIENTENo ratings yet
- Ealing JSNA 2017: Population Characteristics: Lead Author: Mira MangaraDocument44 pagesEaling JSNA 2017: Population Characteristics: Lead Author: Mira MangaraSerdar AldanmazlarNo ratings yet
- e802a24e5f5c224437b95c75aefda4ca (1)Document2 pagese802a24e5f5c224437b95c75aefda4ca (1)Salsabila 1414No ratings yet
- 40513-PG2 Mise en Route.o7000LKMdbmDocument17 pages40513-PG2 Mise en Route.o7000LKMdbmJustin PathatyNo ratings yet
- MatrizDocument3 pagesMatrizNATALIA CHAMORRO DELGADONo ratings yet
- CDW ReportDocument4 pagesCDW ReportMike Zoren BalicocoNo ratings yet
- OMB 2004 SpreadsheetDocument700 pagesOMB 2004 Spreadsheetrs314861100% (2)
- Maquina de Estado Finito Con MooreDocument12 pagesMaquina de Estado Finito Con MooreJuandiego Nuñez SalasNo ratings yet
- BattleTech Inner Spher at War 2786Document1 pageBattleTech Inner Spher at War 2786William RodriguesNo ratings yet
- Group Project - Corona Virus MAS291 - Group 1 - AI1603 Lecturer: Lê Thị Hồng ThơmDocument94 pagesGroup Project - Corona Virus MAS291 - Group 1 - AI1603 Lecturer: Lê Thị Hồng ThơmThăng Long HàNo ratings yet
- DES Full ExampleDocument8 pagesDES Full ExampleDr.Ekhlas Abbas Albahrani100% (1)
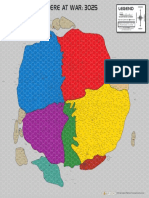
- BattleTech Inner Spher at War 3025Document1 pageBattleTech Inner Spher at War 3025William RodriguesNo ratings yet
- Population Ecology - DemographicsDocument23 pagesPopulation Ecology - Demographicsajkennedy001No ratings yet
- Isaw Hexmap Is 2830Document1 pageIsaw Hexmap Is 2830William RodriguesNo ratings yet
- TABLE: Story Response TABLE: Story Response Story Elevation Location X-Dir Y-Dir Story Elevation LocationDocument4 pagesTABLE: Story Response TABLE: Story Response Story Elevation Location X-Dir Y-Dir Story Elevation Locationप्रतीक राज पण्डितNo ratings yet
- Data PDFDocument12 pagesData PDFmd Syful islamNo ratings yet
- Catalogue TexturesCD06Document11 pagesCatalogue TexturesCD06BET GOUASNo ratings yet
- Rekapitulasi Penderita TB Di Puskesmas Dan Jejaringnya Puskesmas Mano Kabupaten Manggarai Timur Bulan Januari - Juni Tahun 2019Document2 pagesRekapitulasi Penderita TB Di Puskesmas Dan Jejaringnya Puskesmas Mano Kabupaten Manggarai Timur Bulan Januari - Juni Tahun 2019florensia gimanNo ratings yet
- Examen SistemasDocument6 pagesExamen SistemasMauro LozNo ratings yet
- Sample Tally Sheet Family Tool Guide TallyDocument14 pagesSample Tally Sheet Family Tool Guide TallyJessica Lois TuralbaNo ratings yet
- Forma Polar Forma Rectangular Mag Ang Real Compleja I1 I2 I3 I4 I5 I6 I7 I8 0.9889Document6 pagesForma Polar Forma Rectangular Mag Ang Real Compleja I1 I2 I3 I4 I5 I6 I7 I8 0.9889Mauro LozNo ratings yet
- Civil Services (Main) Examination 2010Document8 pagesCivil Services (Main) Examination 2010D.k. MeenaNo ratings yet
- Ielts GraphsDocument31 pagesIelts GraphssabeghiafshinNo ratings yet
- OP Artifacts CommandsDocument8 pagesOP Artifacts CommandsMARCOS PÉREZ GEANo ratings yet
- Period 4 Ayleen Perez - Lesson 14 Flippy Do - 8626364Document2 pagesPeriod 4 Ayleen Perez - Lesson 14 Flippy Do - 8626364api-460598943No ratings yet
- Graphs Book For PrintingDocument112 pagesGraphs Book For PrintingHarshVavadiya67% (3)
- TabulasiDocument108 pagesTabulasiFitrinurul PramestiNo ratings yet
- PDDocument16 pagesPDetaferaw beyeneNo ratings yet
- Project MAS291 - Nhóm 1Document95 pagesProject MAS291 - Nhóm 1Nam Khanh Do VanNo ratings yet
- Cups Mapi Soat A CupsDocument1,400 pagesCups Mapi Soat A CupsmiguelrodriguezrealeNo ratings yet
- Catalogue TexturesCD03Document12 pagesCatalogue TexturesCD03BET GOUASNo ratings yet
- Catalogue TexturesCD05Document12 pagesCatalogue TexturesCD05BET GOUASNo ratings yet
- Catalogue TexturesCD02Document12 pagesCatalogue TexturesCD02BET GOUASNo ratings yet
- T1 - Area Under Standard Normal CurveDocument1 pageT1 - Area Under Standard Normal Curvevirendra navadiyaNo ratings yet
- A.G.A.P. Statistical Report CY: 2014: Santol DistrictDocument2 pagesA.G.A.P. Statistical Report CY: 2014: Santol DistrictConnie LopicoNo ratings yet
- Sa Maths Um ZP 29-5-11Document7 pagesSa Maths Um ZP 29-5-11Narasimha SastryNo ratings yet
- Socio Economic Status and Health in KeralaDocument17 pagesSocio Economic Status and Health in Keralasafraj5003No ratings yet
- Gauge and Weight Chart For Sheet SteelDocument2 pagesGauge and Weight Chart For Sheet SteelFrancisco Carbone-Mora Campos0% (1)
- LisDocument74 pagesLisFernando L. EscobarNo ratings yet
- 14 Point s1 Eee - DEcDocument9 pages14 Point s1 Eee - DEcMichael CampbellNo ratings yet
- Sheet Metal Thickness ChartDocument1 pageSheet Metal Thickness CharttylerstearnsNo ratings yet
- Wuxi Otto Auto Parts Co.,Ltd: Your Trusted Common Rail Parts Supplier!Document5 pagesWuxi Otto Auto Parts Co.,Ltd: Your Trusted Common Rail Parts Supplier!jhonnyvasquez31No ratings yet
- Friendship BraceletsDocument5 pagesFriendship Braceletskanuncio4No ratings yet
- 27-09-2020 070201am News PDFDocument32 pages27-09-2020 070201am News PDFAman ChaurasiaNo ratings yet
- 19 Fincs Sin Ec SP 2Document4 pages19 Fincs Sin Ec SP 2Bernard Garcia OrihuelaNo ratings yet
- Transparency DPDocument1 pageTransparency DPERICA JEAN ROSADANo ratings yet
- Category Minimum Qualifying Marks Paper - II 50 Marks Paper - II 50 Marks Aggregate Paper - I + Paper - II 100 Marks General Sebc/Obc ST/ ST/ PH/ VHDocument2 pagesCategory Minimum Qualifying Marks Paper - II 50 Marks Paper - II 50 Marks Aggregate Paper - I + Paper - II 100 Marks General Sebc/Obc ST/ ST/ PH/ VHsrijubasu1121No ratings yet
- Multipliers To Compute For Age-Specific Population Projections by Province Region 6Document9 pagesMultipliers To Compute For Age-Specific Population Projections by Province Region 6Shin PaNo ratings yet
- Dictionary of Spoken Words With UsagesDocument377 pagesDictionary of Spoken Words With UsageskszonyiNo ratings yet
- Ccts Maine Standards Rev 11 20Document11 pagesCcts Maine Standards Rev 11 20api-607068017No ratings yet
- Vastushant - SamagriDocument6 pagesVastushant - Samagrirajeshjoshi23No ratings yet
- Algorithm2e.sty - Package For AlgorithmsDocument26 pagesAlgorithm2e.sty - Package For AlgorithmsJordi NinNo ratings yet
- Rosario Vs Auditor GeneralDocument2 pagesRosario Vs Auditor GeneralAnonymous eqJkcbhHNo ratings yet
- Bullguard: Internet Security 9.0: Certified ProductDocument4 pagesBullguard: Internet Security 9.0: Certified ProductwhomanulikeNo ratings yet
- Tanween (Nunation) of The Arabic Nouns in 25 Sayings of Prophet Muhammad (PBUH)Document22 pagesTanween (Nunation) of The Arabic Nouns in 25 Sayings of Prophet Muhammad (PBUH)Jonathan MorganNo ratings yet
- IUFD For 4th Year Medical StudentsDocument19 pagesIUFD For 4th Year Medical StudentsDegefaw BikoyNo ratings yet
- Chapter 5 Part 3 - 202205161151Document6 pagesChapter 5 Part 3 - 202205161151ClydeNo ratings yet
- CSC 2105: D S I: ATA Tructure NtroductionDocument22 pagesCSC 2105: D S I: ATA Tructure NtroductionFahim AhmedNo ratings yet
- Terri Stegmiller Art and Design - Art For SaleDocument1 pageTerri Stegmiller Art and Design - Art For Salemeethi_andreaNo ratings yet
- PYTHON FOR KIDS - Learn To Code Quickly With This Beginner's Guide To Computer ProgrammingDocument116 pagesPYTHON FOR KIDS - Learn To Code Quickly With This Beginner's Guide To Computer ProgrammingMakijavely67% (3)
- Culture of HaryanaDocument2 pagesCulture of HaryanaanittaNo ratings yet
- Worksheet For Chris Bailey Hyperfocus Secrets For Better Productivity Episode 247Document12 pagesWorksheet For Chris Bailey Hyperfocus Secrets For Better Productivity Episode 247Abigail LorenzanaNo ratings yet
- Nojpetén: EtymologyDocument6 pagesNojpetén: EtymologyOrgito LekaNo ratings yet
- Physics DPP 5Document3 pagesPhysics DPP 5Hitesh KumarNo ratings yet
- Pre-Partition Freedom Movement of India (Comprehensive Notes)Document27 pagesPre-Partition Freedom Movement of India (Comprehensive Notes)Ali NawazNo ratings yet
- Padanan KataDocument3 pagesPadanan Katabk28oktober19282 smkNo ratings yet
- The Best Casinos Perform Slots in VegasvzyijDocument2 pagesThe Best Casinos Perform Slots in Vegasvzyijpumaorchid83No ratings yet
- Phillips, Crystals, Defects and Microstructures (CUP, 2004) (ISBN 0521790050)Document808 pagesPhillips, Crystals, Defects and Microstructures (CUP, 2004) (ISBN 0521790050)Ebru Coşkun100% (1)
- Valuation Models: Aswath DamodaranDocument20 pagesValuation Models: Aswath Damodaranmohitsinghal26No ratings yet
- Liquid Marijuana Cocktail Recipe - How To Make A Liquid Marijuana Cocktail - Drink Lab Cocktail & Drink RecipesDocument1 pageLiquid Marijuana Cocktail Recipe - How To Make A Liquid Marijuana Cocktail - Drink Lab Cocktail & Drink RecipesJazymine WrightNo ratings yet
- AWS-PRACT AWS Cloud Practitioner EssentialsDocument1 pageAWS-PRACT AWS Cloud Practitioner EssentialsEdwin VasquezNo ratings yet
- Selene MonologueDocument2 pagesSelene MonologueReign Isabel ValeraNo ratings yet
- Course Application Form: Celta at Ih Bogotá: Cambridge Certificate ELT To AdultsDocument5 pagesCourse Application Form: Celta at Ih Bogotá: Cambridge Certificate ELT To AdultsAndrea Marcela Peña SegoviaNo ratings yet
- Perfect Tense PowerPointDocument18 pagesPerfect Tense PowerPointAlejo Chamba100% (1)