
Quiz2 05 Ans
Quiz2 05 Ans
You might also like
- Amazon Web Services (AWS) Interview Questions and AnswersFrom EverandAmazon Web Services (AWS) Interview Questions and AnswersRating: 4.5 out of 5 stars4.5/5 (3)
- Cis016-2, Cis116-2 & Pat001-2Document5 pagesCis016-2, Cis116-2 & Pat001-2ruslanas reNo ratings yet
- Configuration Checklist For SAP PPDocument11 pagesConfiguration Checklist For SAP PPshishir174No ratings yet
- Builders AddressDocument42 pagesBuilders AddressAshima Lamba0% (1)
- Fisac Os 2024Document2 pagesFisac Os 2024Rohit AgrawalNo ratings yet
- Mca 4th AssignDocument9 pagesMca 4th AssignSmriti SinghNo ratings yet
- Quiz II: Massachusetts Institute of Technology 6.858 Fall 2012Document9 pagesQuiz II: Massachusetts Institute of Technology 6.858 Fall 2012jarod_kyleNo ratings yet
- Quiz I: Massachusetts Institute of Technology 6.858 Fall 2010Document11 pagesQuiz I: Massachusetts Institute of Technology 6.858 Fall 2010jarod_kyleNo ratings yet
- DCN Final Assessment Spring 2020 29062020 034156pmDocument3 pagesDCN Final Assessment Spring 2020 29062020 034156pmap9aadtau5No ratings yet
- Wireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossDocument5 pagesWireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossN Azzati LabibahNo ratings yet
- Wireshark 802.11 v7.0Document5 pagesWireshark 802.11 v7.0Hoàng ĐăngNo ratings yet
- CMP4011 T2 PORT1 Main 2023-24Document8 pagesCMP4011 T2 PORT1 Main 2023-24herocreeperbrplaysNo ratings yet
- MIT6 858F14 q10-1 SolDocument11 pagesMIT6 858F14 q10-1 Soljarod_kyleNo ratings yet
- Wireshark 802.11 v6.0Document6 pagesWireshark 802.11 v6.0moshealoNo ratings yet
- MCT 1 - CC - QP 28 Mar'24Document8 pagesMCT 1 - CC - QP 28 Mar'24Vishnu .SNo ratings yet
- Final Question Paper - CCN Spring 2021Document4 pagesFinal Question Paper - CCN Spring 2021Abdul RaufNo ratings yet
- MIT6 858F14 q13 2 SolDocument15 pagesMIT6 858F14 q13 2 Soljarod_kyleNo ratings yet
- Interview: Question-Answer PHPDocument19 pagesInterview: Question-Answer PHPnivya inventateqNo ratings yet
- Final Exam Fall 2020 PDFDocument4 pagesFinal Exam Fall 2020 PDFRatul BiswasNo ratings yet
- EC360 - Computer CommunicationDocument9 pagesEC360 - Computer CommunicationTtfcfgbbNo ratings yet
- College of Computing and Information Sciences: Mid-Term Assessment Fall 2020 SemesterDocument15 pagesCollege of Computing and Information Sciences: Mid-Term Assessment Fall 2020 Semestertalha khanNo ratings yet
- Most Imp-1Document11 pagesMost Imp-1The Trading FreakNo ratings yet
- Capability Based Addressing?Document3 pagesCapability Based Addressing?sindu_lawrenceNo ratings yet
- CS101 Final Term Current Papers Downloaded From VurankDocument5 pagesCS101 Final Term Current Papers Downloaded From VurankAhmadNo ratings yet
- Routing and Switching Hourly 1 Syed Kashan Bukhari 38182Document7 pagesRouting and Switching Hourly 1 Syed Kashan Bukhari 38182mucers.influencerNo ratings yet
- MCS 41, MCS 42, MCS 43, MCS 44, MCS 45Document13 pagesMCS 41, MCS 42, MCS 43, MCS 44, MCS 45Anup Kumar Verma0% (1)
- CE-303 Operating Systems Final Spring 2021Document3 pagesCE-303 Operating Systems Final Spring 2021nawal 109No ratings yet
- Midterm1 Fall04Document5 pagesMidterm1 Fall04daveparagNo ratings yet
- 19Cs2108S - Database Management Systems: Time: Max - Marks: 100Document4 pages19Cs2108S - Database Management Systems: Time: Max - Marks: 100vamsi krishna mNo ratings yet
- MIT6 858F14 q11-1 SolDocument16 pagesMIT6 858F14 q11-1 Soljarod_kyleNo ratings yet
- CS 502 - DBMS - LABORATORY MANUAL - Final - 1659942271 - 1694237975Document25 pagesCS 502 - DBMS - LABORATORY MANUAL - Final - 1659942271 - 1694237975xyz705638No ratings yet
- 2016 FinalDocument13 pages2016 FinalMd. Asaduzzaman TaifurNo ratings yet
- IS 322 Final Exam 20160607Document3 pagesIS 322 Final Exam 20160607tokka mohamedNo ratings yet
- Final ReportDocument29 pagesFinal ReportJAYDEEP DASNo ratings yet
- Final2011 SolveDocument14 pagesFinal2011 SolveHarsh MohanNo ratings yet
- Homework 7 and 8 SolutionsDocument3 pagesHomework 7 and 8 SolutionsNebojsa Aksentijevic100% (1)
- Final Paper - W3 (Solved)Document9 pagesFinal Paper - W3 (Solved)MASTER JIINo ratings yet
- Instructions: Assignment-01 Spring 2023Document6 pagesInstructions: Assignment-01 Spring 2023Developement LearningsNo ratings yet
- C++ Multithreading TutorialDocument7 pagesC++ Multithreading Tutorialt1888No ratings yet
- CN, LR 03Document8 pagesCN, LR 03Maksuda SarkerNo ratings yet
- MIT6 858F14 q10-2 SolDocument12 pagesMIT6 858F14 q10-2 Soljarod_kyleNo ratings yet
- Final2011 SolveDocument15 pagesFinal2011 SolveHarsh MohanNo ratings yet
- JavaSockets 2Document27 pagesJavaSockets 2cute_guddyNo ratings yet
- PHP Interview Questions and AnswersDocument10 pagesPHP Interview Questions and AnswersAkhilesh KhareNo ratings yet
- 2 Sem II Mtech Ete 27 May 2017Document2 pages2 Sem II Mtech Ete 27 May 2017VSNo ratings yet
- Solutions - OS TS1Document3 pagesSolutions - OS TS1Mugdha KolheNo ratings yet
- Wireless 802.11 LabDocument4 pagesWireless 802.11 LabOscar Alberto García LópezNo ratings yet
- Tribhuvan University Institute of Science and Technology 2068Document5 pagesTribhuvan University Institute of Science and Technology 2068Sarose MahatNo ratings yet
- CS2308 System Software Lab VECCSE2Document45 pagesCS2308 System Software Lab VECCSE2Prema SelvamNo ratings yet
- 3 Cse Ai&ds 20it403 DBMS 07.02.2022 FNDocument3 pages3 Cse Ai&ds 20it403 DBMS 07.02.2022 FNPreethi PadmanabanNo ratings yet
- Az 101Document140 pagesAz 101Ruben Dario Pinzon ErasoNo ratings yet
- Final Examination: This Is A Closed Book, Closed Notes, No Calculator ExamDocument10 pagesFinal Examination: This Is A Closed Book, Closed Notes, No Calculator Exambunty daNo ratings yet
- Arid Agriculture University, RawalpindiDocument7 pagesArid Agriculture University, RawalpindiRao HarisNo ratings yet
- University of Mumbai University of Mumbai University of MumbaiDocument19 pagesUniversity of Mumbai University of Mumbai University of MumbaiJaya PillaiNo ratings yet
- Wide Area ComputingDocument46 pagesWide Area ComputingAlexandros ValavanisNo ratings yet
- EECS 485, Fall 2013 Midterm ExamDocument11 pagesEECS 485, Fall 2013 Midterm Examkakazzz2No ratings yet
- CSE 380: Introduction To Operating Systems: Final Exam 17 December 2003Document6 pagesCSE 380: Introduction To Operating Systems: Final Exam 17 December 2003Yosef GalavizNo ratings yet
- F001 English CLC f1Document6 pagesF001 English CLC f1phu.buiphubui2k2No ratings yet
- Nited Nstitute of EchnologyDocument11 pagesNited Nstitute of Echnologykeerthi3214No ratings yet
- CS MSC Entrance Exam 2006 PDFDocument12 pagesCS MSC Entrance Exam 2006 PDFRahel EshetuNo ratings yet
- Quiz I: Massachusetts Institute of Technology 6.858 Fall 2011Document15 pagesQuiz I: Massachusetts Institute of Technology 6.858 Fall 2011jarod_kyleNo ratings yet
- MCA CN Lab Manual 2019 VtuDocument22 pagesMCA CN Lab Manual 2019 VtuHemanth Aradhya0% (1)
- High-Contrast Gratings For Integrated Optoelectronics: Connie J. Chang-Hasnain and Weijian YangDocument62 pagesHigh-Contrast Gratings For Integrated Optoelectronics: Connie J. Chang-Hasnain and Weijian YangMohit SinhaNo ratings yet
- The Perfect Server - Debian 8 Jessie (Apache2, BIND, Dovecot, IsPConfig 3)Document23 pagesThe Perfect Server - Debian 8 Jessie (Apache2, BIND, Dovecot, IsPConfig 3)Charly DecanoNo ratings yet
- Master Thesis On Brand ExtensionDocument170 pagesMaster Thesis On Brand Extensiondijam_786100% (6)
- Brides-Today Magazine March 2021 EditionDocument93 pagesBrides-Today Magazine March 2021 EditionYajurv Gupta0% (1)
- Tesla Body Repair Program Operating Standards 20180205Document15 pagesTesla Body Repair Program Operating Standards 20180205sdefor01100% (1)
- Symphonie eDocument4 pagesSymphonie enainoNo ratings yet
- Positioning Document-CloudreplicationDocument1 pagePositioning Document-Cloudreplicationapi-272402477No ratings yet
- Aboitiz Shipping Vs New India AssuranceDocument1 pageAboitiz Shipping Vs New India AssuranceDi ko alam100% (2)
- App12 - ACI Meshed Slab and Wall DesignDocument51 pagesApp12 - ACI Meshed Slab and Wall DesignDario Manrique GamarraNo ratings yet
- Chapter VI. Independent Demand Inventory SystemsDocument12 pagesChapter VI. Independent Demand Inventory Systemssimi1690No ratings yet
- Tutorial Chapter 17 - 18 Accounting For Overhead Costs - Job Order and Process CostingDocument48 pagesTutorial Chapter 17 - 18 Accounting For Overhead Costs - Job Order and Process CostingNaKib NahriNo ratings yet
- Game U8 123Document9 pagesGame U8 123Hồng ThắmNo ratings yet
- GerNP 0000 1 0221 E 1 01Document392 pagesGerNP 0000 1 0221 E 1 01tata3No ratings yet
- Fundamentals of Advanced Accounting 8th Edition Hoyle Test Bank 1Document30 pagesFundamentals of Advanced Accounting 8th Edition Hoyle Test Bank 1toddvaldezamzxfwnrtq100% (38)
- PSSR Pre-Commissioning SafetyDocument6 pagesPSSR Pre-Commissioning SafetymanuNo ratings yet
- OOAD Interview Questions-Answers NewDocument6 pagesOOAD Interview Questions-Answers NewUtsav ShahNo ratings yet
- Ane Publish Ahead of Print 10.1213.ane.0000000000005043Document13 pagesAne Publish Ahead of Print 10.1213.ane.0000000000005043khalisahnNo ratings yet
- Final RodentDocument7 pagesFinal Rodentamazingmoves20No ratings yet
- CDI NORSOK Testing Elastomers Tech Report WebDocument2 pagesCDI NORSOK Testing Elastomers Tech Report WebwholenumberNo ratings yet
- MULTIPLE CHOICE (1 Point Each)Document10 pagesMULTIPLE CHOICE (1 Point Each)Mitch Regencia100% (1)
- MP15 User ManualDocument36 pagesMP15 User Manualr_leonNo ratings yet
- CSMSI Cash Handling PolicyDocument3 pagesCSMSI Cash Handling PolicyJayson MaleroNo ratings yet
- M-CHAT-R F TamilDocument27 pagesM-CHAT-R F TamilSASIKUMAR SNo ratings yet
- The Concept of Jurisdiction Under The Indian Penal Code 1860Document9 pagesThe Concept of Jurisdiction Under The Indian Penal Code 1860Rahul JaiswarNo ratings yet
- Vibrant PU CollegeDocument10 pagesVibrant PU CollegemeghaonecityvibrantNo ratings yet
- 81221H Pressure ENGDocument11 pages81221H Pressure ENGGopal HegdeNo ratings yet
- Miller Proheat 35 CE ManualDocument1 pageMiller Proheat 35 CE ManualcarlosNo ratings yet
- 5 Combined Tension and Shear Loads (EN 1992-4, Section 7.2.3)Document1 page5 Combined Tension and Shear Loads (EN 1992-4, Section 7.2.3)Shashank PatoleNo ratings yet












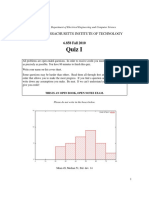
















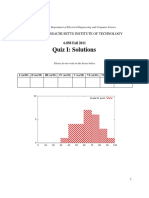










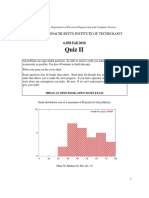

















































Download as pdf or txt
You might also like
- Amazon Web Services (AWS) Interview Questions and AnswersFrom EverandAmazon Web Services (AWS) Interview Questions and AnswersRating: 4.5 out of 5 stars4.5/5 (3)
- Cis016-2, Cis116-2 & Pat001-2Document5 pagesCis016-2, Cis116-2 & Pat001-2ruslanas reNo ratings yet
- Configuration Checklist For SAP PPDocument11 pagesConfiguration Checklist For SAP PPshishir174No ratings yet
- Builders AddressDocument42 pagesBuilders AddressAshima Lamba0% (1)
- Fisac Os 2024Document2 pagesFisac Os 2024Rohit AgrawalNo ratings yet
- Mca 4th AssignDocument9 pagesMca 4th AssignSmriti SinghNo ratings yet
- Quiz II: Massachusetts Institute of Technology 6.858 Fall 2012Document9 pagesQuiz II: Massachusetts Institute of Technology 6.858 Fall 2012jarod_kyleNo ratings yet
- Quiz I: Massachusetts Institute of Technology 6.858 Fall 2010Document11 pagesQuiz I: Massachusetts Institute of Technology 6.858 Fall 2010jarod_kyleNo ratings yet
- DCN Final Assessment Spring 2020 29062020 034156pmDocument3 pagesDCN Final Assessment Spring 2020 29062020 034156pmap9aadtau5No ratings yet
- Wireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossDocument5 pagesWireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossN Azzati LabibahNo ratings yet
- Wireshark 802.11 v7.0Document5 pagesWireshark 802.11 v7.0Hoàng ĐăngNo ratings yet
- CMP4011 T2 PORT1 Main 2023-24Document8 pagesCMP4011 T2 PORT1 Main 2023-24herocreeperbrplaysNo ratings yet
- MIT6 858F14 q10-1 SolDocument11 pagesMIT6 858F14 q10-1 Soljarod_kyleNo ratings yet
- Wireshark 802.11 v6.0Document6 pagesWireshark 802.11 v6.0moshealoNo ratings yet
- MCT 1 - CC - QP 28 Mar'24Document8 pagesMCT 1 - CC - QP 28 Mar'24Vishnu .SNo ratings yet
- Final Question Paper - CCN Spring 2021Document4 pagesFinal Question Paper - CCN Spring 2021Abdul RaufNo ratings yet
- MIT6 858F14 q13 2 SolDocument15 pagesMIT6 858F14 q13 2 Soljarod_kyleNo ratings yet
- Interview: Question-Answer PHPDocument19 pagesInterview: Question-Answer PHPnivya inventateqNo ratings yet
- Final Exam Fall 2020 PDFDocument4 pagesFinal Exam Fall 2020 PDFRatul BiswasNo ratings yet
- EC360 - Computer CommunicationDocument9 pagesEC360 - Computer CommunicationTtfcfgbbNo ratings yet
- College of Computing and Information Sciences: Mid-Term Assessment Fall 2020 SemesterDocument15 pagesCollege of Computing and Information Sciences: Mid-Term Assessment Fall 2020 Semestertalha khanNo ratings yet
- Most Imp-1Document11 pagesMost Imp-1The Trading FreakNo ratings yet
- Capability Based Addressing?Document3 pagesCapability Based Addressing?sindu_lawrenceNo ratings yet
- CS101 Final Term Current Papers Downloaded From VurankDocument5 pagesCS101 Final Term Current Papers Downloaded From VurankAhmadNo ratings yet
- Routing and Switching Hourly 1 Syed Kashan Bukhari 38182Document7 pagesRouting and Switching Hourly 1 Syed Kashan Bukhari 38182mucers.influencerNo ratings yet
- MCS 41, MCS 42, MCS 43, MCS 44, MCS 45Document13 pagesMCS 41, MCS 42, MCS 43, MCS 44, MCS 45Anup Kumar Verma0% (1)
- CE-303 Operating Systems Final Spring 2021Document3 pagesCE-303 Operating Systems Final Spring 2021nawal 109No ratings yet
- Midterm1 Fall04Document5 pagesMidterm1 Fall04daveparagNo ratings yet
- 19Cs2108S - Database Management Systems: Time: Max - Marks: 100Document4 pages19Cs2108S - Database Management Systems: Time: Max - Marks: 100vamsi krishna mNo ratings yet
- MIT6 858F14 q11-1 SolDocument16 pagesMIT6 858F14 q11-1 Soljarod_kyleNo ratings yet
- CS 502 - DBMS - LABORATORY MANUAL - Final - 1659942271 - 1694237975Document25 pagesCS 502 - DBMS - LABORATORY MANUAL - Final - 1659942271 - 1694237975xyz705638No ratings yet
- 2016 FinalDocument13 pages2016 FinalMd. Asaduzzaman TaifurNo ratings yet
- IS 322 Final Exam 20160607Document3 pagesIS 322 Final Exam 20160607tokka mohamedNo ratings yet
- Final ReportDocument29 pagesFinal ReportJAYDEEP DASNo ratings yet
- Final2011 SolveDocument14 pagesFinal2011 SolveHarsh MohanNo ratings yet
- Homework 7 and 8 SolutionsDocument3 pagesHomework 7 and 8 SolutionsNebojsa Aksentijevic100% (1)
- Final Paper - W3 (Solved)Document9 pagesFinal Paper - W3 (Solved)MASTER JIINo ratings yet
- Instructions: Assignment-01 Spring 2023Document6 pagesInstructions: Assignment-01 Spring 2023Developement LearningsNo ratings yet
- C++ Multithreading TutorialDocument7 pagesC++ Multithreading Tutorialt1888No ratings yet
- CN, LR 03Document8 pagesCN, LR 03Maksuda SarkerNo ratings yet
- MIT6 858F14 q10-2 SolDocument12 pagesMIT6 858F14 q10-2 Soljarod_kyleNo ratings yet
- Final2011 SolveDocument15 pagesFinal2011 SolveHarsh MohanNo ratings yet
- JavaSockets 2Document27 pagesJavaSockets 2cute_guddyNo ratings yet
- PHP Interview Questions and AnswersDocument10 pagesPHP Interview Questions and AnswersAkhilesh KhareNo ratings yet
- 2 Sem II Mtech Ete 27 May 2017Document2 pages2 Sem II Mtech Ete 27 May 2017VSNo ratings yet
- Solutions - OS TS1Document3 pagesSolutions - OS TS1Mugdha KolheNo ratings yet
- Wireless 802.11 LabDocument4 pagesWireless 802.11 LabOscar Alberto García LópezNo ratings yet
- Tribhuvan University Institute of Science and Technology 2068Document5 pagesTribhuvan University Institute of Science and Technology 2068Sarose MahatNo ratings yet
- CS2308 System Software Lab VECCSE2Document45 pagesCS2308 System Software Lab VECCSE2Prema SelvamNo ratings yet
- 3 Cse Ai&ds 20it403 DBMS 07.02.2022 FNDocument3 pages3 Cse Ai&ds 20it403 DBMS 07.02.2022 FNPreethi PadmanabanNo ratings yet
- Az 101Document140 pagesAz 101Ruben Dario Pinzon ErasoNo ratings yet
- Final Examination: This Is A Closed Book, Closed Notes, No Calculator ExamDocument10 pagesFinal Examination: This Is A Closed Book, Closed Notes, No Calculator Exambunty daNo ratings yet
- Arid Agriculture University, RawalpindiDocument7 pagesArid Agriculture University, RawalpindiRao HarisNo ratings yet
- University of Mumbai University of Mumbai University of MumbaiDocument19 pagesUniversity of Mumbai University of Mumbai University of MumbaiJaya PillaiNo ratings yet
- Wide Area ComputingDocument46 pagesWide Area ComputingAlexandros ValavanisNo ratings yet
- EECS 485, Fall 2013 Midterm ExamDocument11 pagesEECS 485, Fall 2013 Midterm Examkakazzz2No ratings yet
- CSE 380: Introduction To Operating Systems: Final Exam 17 December 2003Document6 pagesCSE 380: Introduction To Operating Systems: Final Exam 17 December 2003Yosef GalavizNo ratings yet
- F001 English CLC f1Document6 pagesF001 English CLC f1phu.buiphubui2k2No ratings yet
- Nited Nstitute of EchnologyDocument11 pagesNited Nstitute of Echnologykeerthi3214No ratings yet
- CS MSC Entrance Exam 2006 PDFDocument12 pagesCS MSC Entrance Exam 2006 PDFRahel EshetuNo ratings yet
- Quiz I: Massachusetts Institute of Technology 6.858 Fall 2011Document15 pagesQuiz I: Massachusetts Institute of Technology 6.858 Fall 2011jarod_kyleNo ratings yet
- MCA CN Lab Manual 2019 VtuDocument22 pagesMCA CN Lab Manual 2019 VtuHemanth Aradhya0% (1)
- High-Contrast Gratings For Integrated Optoelectronics: Connie J. Chang-Hasnain and Weijian YangDocument62 pagesHigh-Contrast Gratings For Integrated Optoelectronics: Connie J. Chang-Hasnain and Weijian YangMohit SinhaNo ratings yet
- The Perfect Server - Debian 8 Jessie (Apache2, BIND, Dovecot, IsPConfig 3)Document23 pagesThe Perfect Server - Debian 8 Jessie (Apache2, BIND, Dovecot, IsPConfig 3)Charly DecanoNo ratings yet
- Master Thesis On Brand ExtensionDocument170 pagesMaster Thesis On Brand Extensiondijam_786100% (6)
- Brides-Today Magazine March 2021 EditionDocument93 pagesBrides-Today Magazine March 2021 EditionYajurv Gupta0% (1)
- Tesla Body Repair Program Operating Standards 20180205Document15 pagesTesla Body Repair Program Operating Standards 20180205sdefor01100% (1)
- Symphonie eDocument4 pagesSymphonie enainoNo ratings yet
- Positioning Document-CloudreplicationDocument1 pagePositioning Document-Cloudreplicationapi-272402477No ratings yet
- Aboitiz Shipping Vs New India AssuranceDocument1 pageAboitiz Shipping Vs New India AssuranceDi ko alam100% (2)
- App12 - ACI Meshed Slab and Wall DesignDocument51 pagesApp12 - ACI Meshed Slab and Wall DesignDario Manrique GamarraNo ratings yet
- Chapter VI. Independent Demand Inventory SystemsDocument12 pagesChapter VI. Independent Demand Inventory Systemssimi1690No ratings yet
- Tutorial Chapter 17 - 18 Accounting For Overhead Costs - Job Order and Process CostingDocument48 pagesTutorial Chapter 17 - 18 Accounting For Overhead Costs - Job Order and Process CostingNaKib NahriNo ratings yet
- Game U8 123Document9 pagesGame U8 123Hồng ThắmNo ratings yet
- GerNP 0000 1 0221 E 1 01Document392 pagesGerNP 0000 1 0221 E 1 01tata3No ratings yet
- Fundamentals of Advanced Accounting 8th Edition Hoyle Test Bank 1Document30 pagesFundamentals of Advanced Accounting 8th Edition Hoyle Test Bank 1toddvaldezamzxfwnrtq100% (38)
- PSSR Pre-Commissioning SafetyDocument6 pagesPSSR Pre-Commissioning SafetymanuNo ratings yet
- OOAD Interview Questions-Answers NewDocument6 pagesOOAD Interview Questions-Answers NewUtsav ShahNo ratings yet
- Ane Publish Ahead of Print 10.1213.ane.0000000000005043Document13 pagesAne Publish Ahead of Print 10.1213.ane.0000000000005043khalisahnNo ratings yet
- Final RodentDocument7 pagesFinal Rodentamazingmoves20No ratings yet
- CDI NORSOK Testing Elastomers Tech Report WebDocument2 pagesCDI NORSOK Testing Elastomers Tech Report WebwholenumberNo ratings yet
- MULTIPLE CHOICE (1 Point Each)Document10 pagesMULTIPLE CHOICE (1 Point Each)Mitch Regencia100% (1)
- MP15 User ManualDocument36 pagesMP15 User Manualr_leonNo ratings yet
- CSMSI Cash Handling PolicyDocument3 pagesCSMSI Cash Handling PolicyJayson MaleroNo ratings yet
- M-CHAT-R F TamilDocument27 pagesM-CHAT-R F TamilSASIKUMAR SNo ratings yet
- The Concept of Jurisdiction Under The Indian Penal Code 1860Document9 pagesThe Concept of Jurisdiction Under The Indian Penal Code 1860Rahul JaiswarNo ratings yet
- Vibrant PU CollegeDocument10 pagesVibrant PU CollegemeghaonecityvibrantNo ratings yet
- 81221H Pressure ENGDocument11 pages81221H Pressure ENGGopal HegdeNo ratings yet
- Miller Proheat 35 CE ManualDocument1 pageMiller Proheat 35 CE ManualcarlosNo ratings yet
- 5 Combined Tension and Shear Loads (EN 1992-4, Section 7.2.3)Document1 page5 Combined Tension and Shear Loads (EN 1992-4, Section 7.2.3)Shashank PatoleNo ratings yet