Download as pdf or txt
You might also like
- Statistics For Management McqsDocument29 pagesStatistics For Management McqsNIRALI86% (29)
- SMAI Question PapersDocument13 pagesSMAI Question PapersSangam PatilNo ratings yet
- The Application of Machine Learning and Deep LearnDocument20 pagesThe Application of Machine Learning and Deep LearnFran MoralesNo ratings yet
- Constantinou 2018 ML PDFDocument27 pagesConstantinou 2018 ML PDFParaschiv DariusNo ratings yet
- Notes For E-Sports InteractiveDocument17 pagesNotes For E-Sports Interactivejinhyeok0628No ratings yet
- Entropy 23 00090 v3Document12 pagesEntropy 23 00090 v3Christy BinuNo ratings yet
- Application of Artificial Intelligence in Basketball Sport. Journal of Education, Health and Sport. 2021Document14 pagesApplication of Artificial Intelligence in Basketball Sport. Journal of Education, Health and Sport. 2021Łukasz Wiesław StrzałkowskiNo ratings yet
- Psicología Del Deporte en E-SportsDocument10 pagesPsicología Del Deporte en E-Sportsjuan alejandro perez quinteroNo ratings yet
- Fuzzy-Based Model For Predicting Football Match Results: February 2020Document12 pagesFuzzy-Based Model For Predicting Football Match Results: February 2020Sarah HassanNo ratings yet
- PA in Fuzzy Based Model (Intro 2)Document12 pagesPA in Fuzzy Based Model (Intro 2)shankar.isaac1013No ratings yet
- 12 JST-1649-2019Document16 pages12 JST-1649-2019Chung Tiến PhátNo ratings yet
- What Contributes To Success in MOBA Games? An Empirical Study of Defense of The Ancients 2Document25 pagesWhat Contributes To Success in MOBA Games? An Empirical Study of Defense of The Ancients 2Gonzalo RamírezNo ratings yet
- Ipl 4Document8 pagesIpl 4soyff7spxfNo ratings yet
- The Effects of Artificial Intelligence On Competitive SportsDocument35 pagesThe Effects of Artificial Intelligence On Competitive SportsTest ChiNo ratings yet
- Analysing Long Short Term Memory Models For Cricket Match Outcome PredictionDocument10 pagesAnalysing Long Short Term Memory Models For Cricket Match Outcome PredictionIJRASETPublicationsNo ratings yet
- Performance Analysis of A Cricketer by Data VisualizationDocument10 pagesPerformance Analysis of A Cricketer by Data VisualizationIJRASETPublicationsNo ratings yet
- Introduction NewDocument3 pagesIntroduction Newshankar.isaac1013No ratings yet
- Descriptive and Predictive Analysis of Euroleague PDFDocument25 pagesDescriptive and Predictive Analysis of Euroleague PDFCoach-NeilKhayechNo ratings yet
- Descriptive and Predictive Analysis of EuroleagueDocument25 pagesDescriptive and Predictive Analysis of EuroleagueCoach-NeilKhayechNo ratings yet
- Descriptive and Predictive Analysis of Euroleague PDFDocument25 pagesDescriptive and Predictive Analysis of Euroleague PDFCoach-NeilKhayechNo ratings yet
- Esports As A Career in The Indian Context: Akhilesh Swaroop Joshi, Amritashish BagchiDocument9 pagesEsports As A Career in The Indian Context: Akhilesh Swaroop Joshi, Amritashish BagchiAmit DashNo ratings yet
- E Sports PDFDocument12 pagesE Sports PDFMonthatiNo ratings yet
- Eda of IplDocument62 pagesEda of IplLoki LaufeysonNo ratings yet
- A Novel Approach For Predicting Football Match Results: An Evaluation of Classification AlgorithmsDocument8 pagesA Novel Approach For Predicting Football Match Results: An Evaluation of Classification AlgorithmsIJAR JOURNALNo ratings yet
- Sports Analyticsfor Football League Tableand Player Performance Prediction CRDocument9 pagesSports Analyticsfor Football League Tableand Player Performance Prediction CRrautpranay111No ratings yet
- 1 s2.0 S2666827022001104 MainDocument9 pages1 s2.0 S2666827022001104 MainKushal MudaliyarNo ratings yet
- Orientation and Decision-Making For Soccer Based On Sports Analytics and AI: A Systematic ReviewDocument21 pagesOrientation and Decision-Making For Soccer Based On Sports Analytics and AI: A Systematic Reviewjulia.sousaNo ratings yet
- 181 Dec2019Document8 pages181 Dec2019MuhammadSaadKhanNo ratings yet
- Thesis Video Game IndustryDocument5 pagesThesis Video Game Industryzidhelvcf100% (2)
- Data Analytics in SportsDocument22 pagesData Analytics in Sportspauld100% (3)
- Machine Learning With ApplicationsDocument9 pagesMachine Learning With ApplicationsSyed M FarjadNo ratings yet
- Assignment AI Society E18CSE173Document4 pagesAssignment AI Society E18CSE173Raghav RNo ratings yet
- Deep Learning FootballDocument8 pagesDeep Learning Footballhamzedd77tankiNo ratings yet
- Application of Artificial Intelligence TechnologyDocument9 pagesApplication of Artificial Intelligence TechnologyCoach-NeilKhayechNo ratings yet
- Doyen - Live Project Details PDFDocument2 pagesDoyen - Live Project Details PDFSudha MadhuriNo ratings yet
- 17 - Best Strategy To Win A Match An Analytical Approach Using Hybrid MachineDocument43 pages17 - Best Strategy To Win A Match An Analytical Approach Using Hybrid MachineKnowledge FactoryNo ratings yet
- Lukowicz Mmi 2020 4Document15 pagesLukowicz Mmi 2020 4jaydeepsharma95.jsNo ratings yet
- Comprehensive Data Analysis and Prediction On IPL Using Machine Learning Algorithms Valarmathi B 2113j1Document11 pagesComprehensive Data Analysis and Prediction On IPL Using Machine Learning Algorithms Valarmathi B 2113j1aishwarya kulkarniNo ratings yet
- Towards Smart-Data - Improving Predictive Accuracy in Long-Term Football Team Performance - 2Document28 pagesTowards Smart-Data - Improving Predictive Accuracy in Long-Term Football Team Performance - 2Kevin ShiNo ratings yet
- Super Predictor of Indian Premier League (IPL) Using Various ML Techniques With Help of IBM CloudDocument17 pagesSuper Predictor of Indian Premier League (IPL) Using Various ML Techniques With Help of IBM CloudIJRASETPublicationsNo ratings yet
- paper-5Document23 pagespaper-5Srinu .MNo ratings yet
- BM2302 001Document5 pagesBM2302 001seley94024No ratings yet
- sminton,+13509-Article+(PDF)-30287-1-11-20220414Document38 pagessminton,+13509-Article+(PDF)-30287-1-11-20220414moajlan2No ratings yet
- The Development of Theoretical Framework For In-App Purchasing For The Gaming IndustryDocument9 pagesThe Development of Theoretical Framework For In-App Purchasing For The Gaming IndustrydanicalalalaNo ratings yet
- Ii. Literture ReviewDocument3 pagesIi. Literture Reviewnhan leNo ratings yet
- Application of Machine Learning in Cricket and Predictive Analytics of IPL 2020Document26 pagesApplication of Machine Learning in Cricket and Predictive Analytics of IPL 2020JehanNo ratings yet
- Football Data Analysis Using Machine Learning TechniquesDocument3 pagesFootball Data Analysis Using Machine Learning TechniquesskulspidyyyNo ratings yet
- Managing EDocument5 pagesManaging Eclocktowerkings72No ratings yet
- An Analysis of Batting Performance of The Cricket PlayersDocument6 pagesAn Analysis of Batting Performance of The Cricket PlayersFaiz ur RehmanNo ratings yet
- CKKK AI Go Research PaperDocument52 pagesCKKK AI Go Research Paperbasib76893No ratings yet
- IplDocument13 pagesIplintisarNo ratings yet
- Tictactoe AI DocumentationDocument16 pagesTictactoe AI DocumentationKou CatarajaNo ratings yet
- K SunilDocument21 pagesK Sunilnitheeshchowdary2007No ratings yet
- Is Esport A Real Sport Reflections On The Spread of Virtual CompetitionsDocument6 pagesIs Esport A Real Sport Reflections On The Spread of Virtual CompetitionsJay Tabar BenaojanNo ratings yet
- PresentationDocument16 pagesPresentationbryan ongwinardyNo ratings yet
- Artificial Intelligence and Machine Learning in SPDocument8 pagesArtificial Intelligence and Machine Learning in SPMirela OlteanuNo ratings yet
- 1809 09813 PDFDocument13 pages1809 09813 PDFgaur1234No ratings yet
- Predicting Outcome of Indian Premier League (IPL) Matches Using Machine LearningDocument12 pagesPredicting Outcome of Indian Premier League (IPL) Matches Using Machine LearningRaj R. PawarNo ratings yet
- Akhil JosephDocument6 pagesAkhil JosephJosephNo ratings yet
- FULLTEXT02Document97 pagesFULLTEXT02venki08No ratings yet
- Data Science Essentials: Machine Learning and Natural Language ProcessingFrom EverandData Science Essentials: Machine Learning and Natural Language ProcessingNo ratings yet
- Data and Analytics in Action: Project Ideas and Basic Code Skeleton in PythonFrom EverandData and Analytics in Action: Project Ideas and Basic Code Skeleton in PythonNo ratings yet
- Testing For Normality Using SPSSDocument12 pagesTesting For Normality Using SPSSGazal GuptaNo ratings yet
- T TestDocument12 pagesT TestNantiwa NaulsreeNo ratings yet
- Statistics Practice SetDocument6 pagesStatistics Practice SetPrasun NaskarNo ratings yet
- Vina Rosta-Econometrics 4 SummaryDocument5 pagesVina Rosta-Econometrics 4 SummaryTommy LesmanaNo ratings yet
- Unit 4 Research MethodologyDocument23 pagesUnit 4 Research MethodologyLords PorseenaNo ratings yet
- Part Three ms-95Document53 pagesPart Three ms-95Sanjaya kumar SwainNo ratings yet
- STAT2080 Ass1 2022Document3 pagesSTAT2080 Ass1 20221780178025No ratings yet
- Sesi 5 TWO SAMPLE TEST Levine - Smume7 - ch10Document44 pagesSesi 5 TWO SAMPLE TEST Levine - Smume7 - ch10Kevin Aditya100% (1)
- LGT2425 Lecture 3 Part II (Notes)Document55 pagesLGT2425 Lecture 3 Part II (Notes)Jackie ChouNo ratings yet
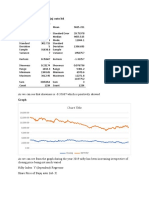
- Summary Statistics of Bajaj Auto LTD: Chart TitleDocument5 pagesSummary Statistics of Bajaj Auto LTD: Chart TitleAkshay UdayNo ratings yet
- Independent Sample T TestDocument17 pagesIndependent Sample T TestDream HighNo ratings yet
- L 11, One Sample TestDocument10 pagesL 11, One Sample TestShan AliNo ratings yet
- CQE Academy Equation Cheat Sheet - DDocument15 pagesCQE Academy Equation Cheat Sheet - DAmr AlShenawyNo ratings yet
- Case Study 1: Southwestern University (Topic: Forecasting)Document10 pagesCase Study 1: Southwestern University (Topic: Forecasting)sonhera sheikhNo ratings yet
- Employee's Retention and Job Satisfaction: Mediating Role of Career Development ProgramsDocument12 pagesEmployee's Retention and Job Satisfaction: Mediating Role of Career Development ProgramsArham KhawajaNo ratings yet
- Assignment - Exercise 6.1 .AnovaDocument13 pagesAssignment - Exercise 6.1 .Anovamhartin liragNo ratings yet
- Standard DeviationDocument3 pagesStandard DeviationmirelaasmanNo ratings yet
- Review MidtermII Summer09Document51 pagesReview MidtermII Summer09Deepak RanaNo ratings yet
- Pratima Education® 9898168041: D. RatioDocument68 pagesPratima Education® 9898168041: D. RatioChinmay Sirasiya (che3kuu)No ratings yet
- Asgnmnt 1 - Q PAPER1Document11 pagesAsgnmnt 1 - Q PAPER1Freddy Savio D'souzaNo ratings yet
- MCQ 12765 KDocument21 pagesMCQ 12765 Kcool_spNo ratings yet
- Faktor Determinan Balita Stunting Pada DDocument14 pagesFaktor Determinan Balita Stunting Pada DVIRGINA PUTRINo ratings yet
- Measures of Central Tendency-ADYDocument12 pagesMeasures of Central Tendency-ADYmukesh_kumar_47100% (1)
- (1st Ed.) Tenko Raykov, - George A. Marcoulides - Introduction To Psychometric Theory-Routledge-115-136Document22 pages(1st Ed.) Tenko Raykov, - George A. Marcoulides - Introduction To Psychometric Theory-Routledge-115-136Gabriella charityNo ratings yet
- Comparison of Goodness of Fit Tests For PDFDocument32 pagesComparison of Goodness of Fit Tests For PDFCavid HacızadəNo ratings yet
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (4)
- Wisner - Supply Chain - 6e - Ch05 - PowerPoint - CeDocument37 pagesWisner - Supply Chain - 6e - Ch05 - PowerPoint - CeMarie-ange Serrão100% (1)