Download as pdf or txt
You might also like
- This is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...From EverandThis is The Statistics Handbook your Professor Doesn't Want you to See. So Easy, it's Practically Cheating...Rating: 4.5 out of 5 stars4.5/5 (6)
- Detecting 0dayDocument8 pagesDetecting 0daycharly36No ratings yet
- L10 11 Hypothesis & ANOVADocument13 pagesL10 11 Hypothesis & ANOVAAlvi KabirNo ratings yet
- Week1 QuizDocument16 pagesWeek1 QuizAbhinav BhargavNo ratings yet
- Friedman Two Way Analysis of Variance by RanksDocument27 pagesFriedman Two Way Analysis of Variance by RanksRohaila Rohani100% (2)
- 5 LargesampletestDocument41 pages5 LargesampletestVenkat BalajiNo ratings yet
- Hypothesis Testing 1,2 PPT 1Document30 pagesHypothesis Testing 1,2 PPT 1Said VarshikNo ratings yet
- 3lesson 2 Tests Involving The Population Mean 1Document14 pages3lesson 2 Tests Involving The Population Mean 1AzodNo ratings yet
- BONGGA Statistics-and-Probability 4Q SLM6Document7 pagesBONGGA Statistics-and-Probability 4Q SLM6daniapslapulapuNo ratings yet
- Hypothesis Testing-1,2Document22 pagesHypothesis Testing-1,2Said VarshikNo ratings yet
- Module 5Document22 pagesModule 5Nithish kumar RajendranNo ratings yet
- PT Module5Document30 pagesPT Module5Venkat BalajiNo ratings yet
- Tests of Hypothesis Single MeanDocument5 pagesTests of Hypothesis Single MeanMhar G-i SalalilaNo ratings yet
- 2 Hypothesis Testing (Part 1)Document8 pages2 Hypothesis Testing (Part 1)Von Adrian Inociaan HernandezNo ratings yet
- Lecture 7-Statistics DecisionsDocument43 pagesLecture 7-Statistics DecisionsAshraf SeragNo ratings yet
- Chapters 10,11,12Document6 pagesChapters 10,11,12sarkarigamingytNo ratings yet
- Advanced Statistics Hypothesis TestingDocument42 pagesAdvanced Statistics Hypothesis TestingShermaine CachoNo ratings yet
- SSC 201Document14 pagesSSC 201Adebayo OmojuwaNo ratings yet
- Introduction To Hypothesis Testing: Print RoundDocument2 pagesIntroduction To Hypothesis Testing: Print RoundShubhashish PaulNo ratings yet
- Sampling TheoryDocument22 pagesSampling TheorySHAIK MAHAMMED RAFFINo ratings yet
- Hypothesis TestingDocument16 pagesHypothesis Testingbdsumaiya314No ratings yet
- Business Research Methods: Univariate StatisticsDocument55 pagesBusiness Research Methods: Univariate StatisticsRajashekhar B BeedimaniNo ratings yet
- Topic 7Document26 pagesTopic 7Zienab AhmedNo ratings yet
- Testing of HypothesisDocument9 pagesTesting of HypothesisAleenaNo ratings yet
- 5 Hypothesis TestsDocument14 pages5 Hypothesis TestsChooi Jia YueNo ratings yet
- Author: Dr. K. GURURAJAN: Class Notes of Engineering Mathematics Iv Subject Code: 06mat41Document122 pagesAuthor: Dr. K. GURURAJAN: Class Notes of Engineering Mathematics Iv Subject Code: 06mat41Rohit Patil0% (1)
- Z-Test For ProportionDocument13 pagesZ-Test For ProportionAysha KhanNo ratings yet
- Section V Notes With Answers - PDF BDocument8 pagesSection V Notes With Answers - PDF BDeivid William TorresNo ratings yet
- Testing of HypothesisDocument15 pagesTesting of HypothesisALLADA JAYAVANTH KUMARNo ratings yet
- Testing of Hypothesis For Large SampleDocument11 pagesTesting of Hypothesis For Large Sample52 Shagun ChaudhariNo ratings yet
- Unit-5 BS& ADocument71 pagesUnit-5 BS& Aus825844No ratings yet
- SP Q4 Module 3 PPT 2Document25 pagesSP Q4 Module 3 PPT 2Shanne RachoNo ratings yet
- T TestDocument20 pagesT Testlhara vilarNo ratings yet
- Hypothesis Testing: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument23 pagesHypothesis Testing: Prepared By: Mr. Ian Anthony M. Torrente, LPTAldrich MartirezNo ratings yet
- HYPOTHESIS TESTING, Z-Test, and T-TestDocument3 pagesHYPOTHESIS TESTING, Z-Test, and T-TestAnanda Del CastilloNo ratings yet
- AS STAT-11 Q4 Wk3-4Document19 pagesAS STAT-11 Q4 Wk3-4Fabriculous NikkiNo ratings yet
- Sampling Theory NotesDocument8 pagesSampling Theory NotesChandan RaiNo ratings yet
- Ed Inference1Document20 pagesEd Inference1shoaib625No ratings yet
- ) and Variance, So The Hypothesis, H: andDocument4 pages) and Variance, So The Hypothesis, H: andPi YaNo ratings yet
- W7 Lecture7Document19 pagesW7 Lecture7Thi Nam PhạmNo ratings yet
- Statistics Probability: Quarter 4Document8 pagesStatistics Probability: Quarter 4Rizwan OrduñaNo ratings yet
- Hypotheses TestingiDocument36 pagesHypotheses TestingiAhmed EssamNo ratings yet
- SLG 28.2 - Procedure in Doing A Test For A MeanDocument7 pagesSLG 28.2 - Procedure in Doing A Test For A Meanrex pangetNo ratings yet
- Unit-4 Applied StatisticsDocument23 pagesUnit-4 Applied StatisticsRidham chitreNo ratings yet
- Hypothesis+tests+involving+a+sample+mean+or+proportionDocument45 pagesHypothesis+tests+involving+a+sample+mean+or+proportionJerome Badillo100% (1)
- HypothesisDocument14 pagesHypothesisMarkNo ratings yet
- Statistics & Probability: Hypothesis Testing Z-TestDocument63 pagesStatistics & Probability: Hypothesis Testing Z-TestKyla Aragon BersalonaNo ratings yet
- Population Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTDocument11 pagesPopulation Proportion: Prepared By: Mr. Ian Anthony M. Torrente, LPTRamona BaculinaoNo ratings yet
- Testing of Hypothesis Unit-IDocument16 pagesTesting of Hypothesis Unit-IanohanabrotherhoodcaveNo ratings yet
- HypothesisDocument29 pagesHypothesisdionvenus100% (1)
- Statistics For Management Decisions MG913: Sampling Distributions and Confidence IntervalsDocument31 pagesStatistics For Management Decisions MG913: Sampling Distributions and Confidence IntervalsAshraf SeragNo ratings yet
- The Hypothesis Testing On One-Sample ProportionDocument18 pagesThe Hypothesis Testing On One-Sample ProportionChecken Joy100% (1)
- Math 8aDocument6 pagesMath 8arodel totzNo ratings yet
- Probability Distribution: - Discrete - ContinuousDocument5 pagesProbability Distribution: - Discrete - ContinuousEavie OngNo ratings yet
- WK 10-Session 10 Notes-Hypothesis Testing (One Sample) - Upload-UpdatedDocument24 pagesWK 10-Session 10 Notes-Hypothesis Testing (One Sample) - Upload-UpdatedLIAW ANN YINo ratings yet
- Inferential Statistic IDocument83 pagesInferential Statistic IThiviyashiniNo ratings yet
- Binomial Test For Non Parametric StatisticsDocument5 pagesBinomial Test For Non Parametric StatisticsJay SantosNo ratings yet
- Final Term Biostatistics PDFDocument7 pagesFinal Term Biostatistics PDFSarmad HussainNo ratings yet
- Week 6 Class 2Document23 pagesWeek 6 Class 2anon_711312801No ratings yet
- Learning Unit 8Document20 pagesLearning Unit 8Nubaila EssopNo ratings yet
- Steps in Testing A HypothesisDocument2 pagesSteps in Testing A HypothesisJoanne SazonNo ratings yet
- Schaum's Easy Outline of Probability and Statistics, Revised EditionFrom EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionNo ratings yet
- DL Mid 2Document1 pageDL Mid 2Vadlamudi DhyanamalikaNo ratings yet
- Project On Plant Leaf Disease DetectionDocument10 pagesProject On Plant Leaf Disease DetectionVadlamudi DhyanamalikaNo ratings yet
- Tips Reference 7Document38 pagesTips Reference 7Vadlamudi DhyanamalikaNo ratings yet
- LLDDDocument18 pagesLLDDVadlamudi DhyanamalikaNo ratings yet
- Wepik Unleashing The Zesty Potential Deep Learning For Lemon Leaf Disease Detection 202402041503523FxBDocument12 pagesWepik Unleashing The Zesty Potential Deep Learning For Lemon Leaf Disease Detection 202402041503523FxBVadlamudi DhyanamalikaNo ratings yet
- NTC Power Point TemplateDocument13 pagesNTC Power Point TemplateKevin EspirituNo ratings yet
- Rel CodeDocument148 pagesRel CodeJorge FracaroNo ratings yet
- Word of MouthDocument5 pagesWord of MouthSasiNo ratings yet
- Navigating Brand Evolution: The Strategic Impact of Logo Redesign On Consumer Perceptions and BehavioursDocument63 pagesNavigating Brand Evolution: The Strategic Impact of Logo Redesign On Consumer Perceptions and Behavioursdhruv.kataria24No ratings yet
- Paul Lambe, Catherine Waters & David BristowDocument10 pagesPaul Lambe, Catherine Waters & David BristowAdam LevineNo ratings yet
- ExerciseDocument10 pagesExercisea192452No ratings yet
- Perception of Investors in Stock Market: A Case Study of Bhopal RegionDocument24 pagesPerception of Investors in Stock Market: A Case Study of Bhopal RegionVISHAL PANDYANo ratings yet
- University of Wyoming College of Business Department of Economics ECON 4230/5230 Intermediate Econometric Theory Spring 2019Document2 pagesUniversity of Wyoming College of Business Department of Economics ECON 4230/5230 Intermediate Econometric Theory Spring 2019Juan Tomas SayagoNo ratings yet
- Statistical Learning in RDocument31 pagesStatistical Learning in RAngela IvanovaNo ratings yet
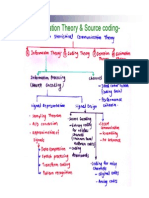
- Unit I Information Theory & Coding Techniques P IDocument48 pagesUnit I Information Theory & Coding Techniques P IShanmugapriyaVinodkumarNo ratings yet
- Linear Latent Variable Models in R: Odel Building ON Linear ConstraintsDocument2 pagesLinear Latent Variable Models in R: Odel Building ON Linear ConstraintsPascal GrangeonNo ratings yet
- Advanced Statistics Using RDocument127 pagesAdvanced Statistics Using RFrederick Bugay Cabactulan100% (2)
- Barnes, Tiffany D., and Erin C. Cassese. 2017. American Party Women - A Look at The Gender Gap Within PartiesDocument15 pagesBarnes, Tiffany D., and Erin C. Cassese. 2017. American Party Women - A Look at The Gender Gap Within PartiesMack EncheeseNo ratings yet
- Scoreplus E-BrochureDocument14 pagesScoreplus E-BrochureAlexander KilfordNo ratings yet
- Chapter 4Document26 pagesChapter 4Eebbisaa CharuuNo ratings yet
- Probability: (EAMCET 2009)Document11 pagesProbability: (EAMCET 2009)eamcetmaterials100% (1)
- Notre Dame University and Its Impact On Their Monetary DecisionsDocument5 pagesNotre Dame University and Its Impact On Their Monetary DecisionsRaenessa FranciscoNo ratings yet
- Lecture On Bootstrap - Lecture NotesDocument29 pagesLecture On Bootstrap - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- UntitledDocument177 pagesUntitledAlipsa Samal B (221210096)No ratings yet
- Data ManagementDocument62 pagesData ManagementMilk BrotherNo ratings yet
- Em 602Document23 pagesEm 602Vaibhav DafaleNo ratings yet
- Final Report - Predicting Traffic Accident SeverityDocument11 pagesFinal Report - Predicting Traffic Accident SeverityShivangi100% (1)
- SPC MinitaDocument1 pageSPC MinitatryNo ratings yet
- Cohort Life Table - Ana - K Marta - Mba LiaDocument14 pagesCohort Life Table - Ana - K Marta - Mba LiarahimulyNo ratings yet
- DETERMINISTICDocument3 pagesDETERMINISTICShimikuWongNo ratings yet
- 2964 CONSORT+2010+ChecklistDocument3 pages2964 CONSORT+2010+ChecklistNur UlayatilmiladiyyahNo ratings yet
- GEC 4 Revised AY 2019-2020Document23 pagesGEC 4 Revised AY 2019-2020Rommel Samonte Alonzagay100% (1)