
Presentation (Created From Your
Presentation (Created From Your
You might also like
- Google Ads Measurement Certification AnswersDocument33 pagesGoogle Ads Measurement Certification AnswersScribdTranslations100% (1)
- Machine Learning AssignmentDocument55 pagesMachine Learning AssignmentAkashNo ratings yet
- Siebel Communications 8.1Document258 pagesSiebel Communications 8.1Oscar Garcia80% (5)
- Deep Learning Coffee Deasses AbstractDocument4 pagesDeep Learning Coffee Deasses Abstractsamueltamiru2008No ratings yet
- YasarDocument10 pagesYasarMuhammad IbrahimNo ratings yet
- Phase 2Document3 pagesPhase 24074- RashmiNo ratings yet
- Fruit Quality Classifier - Group 1Document12 pagesFruit Quality Classifier - Group 1Bruno TelesNo ratings yet
- Skin Cancer PredictionDocument29 pagesSkin Cancer PredictionfoodloverdjdeepakNo ratings yet
- Research Proposal On Deep Learning For Early Cancer Diagnosis and Prediction.Document2 pagesResearch Proposal On Deep Learning For Early Cancer Diagnosis and Prediction.Ali Abu melhemNo ratings yet
- Review ArticleDocument30 pagesReview Articlemohsinramzan999No ratings yet
- Crop Disease Detection Using Image Processing and Machine LearningDocument7 pagesCrop Disease Detection Using Image Processing and Machine LearningHardik kapoorNo ratings yet
- IEEE Conference Template 1Document4 pagesIEEE Conference Template 1NNM22MC020 DEVIKA UDUPA VNo ratings yet
- Google Research Advances Medical ImagingDocument3 pagesGoogle Research Advances Medical ImagingBhavya SehgalNo ratings yet
- STW7088CEMDocument4 pagesSTW7088CEMManish049No ratings yet
- Enabling Data Diversity - Efficient Automatic Augmentation Via Regularized Adversarial Training PDFDocument12 pagesEnabling Data Diversity - Efficient Automatic Augmentation Via Regularized Adversarial Training PDFdaisyNo ratings yet
- A Transfer Learning Approach To Breast CancerDocument11 pagesA Transfer Learning Approach To Breast CancerNexgen TechnologyNo ratings yet
- Vishal Minor Project 2Document16 pagesVishal Minor Project 2Krishna MalviyaNo ratings yet
- Predicting Diabetes in Medical Datasets Using Machine Learning TechniquesDocument14 pagesPredicting Diabetes in Medical Datasets Using Machine Learning TechniquesSardar Manikanta YadavNo ratings yet
- Electronics 11 00477 v2Document15 pagesElectronics 11 00477 v2Pablo OrricoNo ratings yet
- Report - Nutrition Analysis Using Image ClassificationDocument10 pagesReport - Nutrition Analysis Using Image Classificationpoi poiNo ratings yet
- A Skin Disease Classification Model Based On DenseNet and ConvNeXt FusionDocument19 pagesA Skin Disease Classification Model Based On DenseNet and ConvNeXt FusionRana AtharNo ratings yet
- Technical ReportDocument4 pagesTechnical Reportvjp01122000No ratings yet
- 50 Advanced Machine Learning Questions - ChatGPTDocument18 pages50 Advanced Machine Learning Questions - ChatGPTLily Lauren100% (1)
- Food ApplicationDocument22 pagesFood Applicationsoufiane.bassaNo ratings yet
- COntentDocument43 pagesCOntentprabu sekarNo ratings yet
- (IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanDocument9 pages(IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanEighthSenseGroupNo ratings yet
- INTRODUCTIONDocument25 pagesINTRODUCTIONshashankpatel1430No ratings yet
- Food Recognition Using Extreme Learning MachinesDocument8 pagesFood Recognition Using Extreme Learning MachinesIJRASETPublicationsNo ratings yet
- Fine-Grained Food Classification Methods On TheDocument5 pagesFine-Grained Food Classification Methods On ThePavan KumarNo ratings yet
- I Eee Crop AnalyzerDocument9 pagesI Eee Crop Analyzerwekawi2113No ratings yet
- PaperDocument6 pagesPapertaranesvar.cs21No ratings yet
- Implementasi CNN Dan VGG-16 Untuk Mendeteksi GenderDocument10 pagesImplementasi CNN Dan VGG-16 Untuk Mendeteksi GenderAji PurwinarkoNo ratings yet
- Orange and Cream Playful and Illustrative Portrait University Research PosterDocument1 pageOrange and Cream Playful and Illustrative Portrait University Research PosterTrần Chí ThànhNo ratings yet
- Feature EngineeringDocument2 pagesFeature EngineeringEVERYMOMENT ONLENSNo ratings yet
- Ai ML Exp4Document7 pagesAi ML Exp4Kamat HrishikeshNo ratings yet
- DSF Unit 4Document12 pagesDSF Unit 4Hitarth ChughNo ratings yet
- Samatrix Assignment3Document4 pagesSamatrix Assignment3Yash KumarNo ratings yet
- Comparing Data Augmentation Strategies For Deep Image ClassificatDocument9 pagesComparing Data Augmentation Strategies For Deep Image ClassificatARIEL YONATAN ALIN 21.51.2106No ratings yet
- AlbumentationDocument20 pagesAlbumentationChristian Carlos Quispe Bonilla - NEURAL XNo ratings yet
- NTTTTTDocument5 pagesNTTTTTDippal IsraniNo ratings yet
- ProposalDocument12 pagesProposalusama.matin1998No ratings yet
- FRTemplate SoftwareDocument50 pagesFRTemplate SoftwaremohsinNo ratings yet
- WSCG 19Document8 pagesWSCG 19Danilo AntonioNo ratings yet
- 1012 HCI SeminarDocument9 pages1012 HCI Seminarjoelalex528491No ratings yet
- Batch 13ADocument17 pagesBatch 13ADevika gurreNo ratings yet
- DiabetesDocument2 pagesDiabetesLiahNo ratings yet
- Y20cs027 InternshipDocument18 pagesY20cs027 InternshipSARATH CHANDRANo ratings yet
- Updated Research Paper - 295Document19 pagesUpdated Research Paper - 295Pratik NagareNo ratings yet
- My WorkDocument2 pagesMy WorkPritish SinglaNo ratings yet
- Effect of CLAHE-based Enhancement On Bean Leaf Disease Classification Through Explainable AIDocument2 pagesEffect of CLAHE-based Enhancement On Bean Leaf Disease Classification Through Explainable AIVanko SmyrnovNo ratings yet
- Performance and Analysis of Skin Cancer Detection Using Deep LearningDocument6 pagesPerformance and Analysis of Skin Cancer Detection Using Deep LearningjosephineNo ratings yet
- Biomedical Visual Instruction Tuning With Clinician Preference AlignmentDocument18 pagesBiomedical Visual Instruction Tuning With Clinician Preference AlignmentNicola NatalettiNo ratings yet
- Muti-Class Image Classification Using Transfer LearningDocument7 pagesMuti-Class Image Classification Using Transfer LearningIJRASETPublicationsNo ratings yet
- Health Dataset Synopsis NewDocument9 pagesHealth Dataset Synopsis Newnavneet chauhanNo ratings yet
- Diabetes Prediction Using Machine LearningDocument6 pagesDiabetes Prediction Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Reaction Paper 1Document2 pagesReaction Paper 1ron861336No ratings yet
- An Efficient Convolutional Neural Network-Based Classifier For An Imbalanced Oral Squamous Carcinoma Cell DatasetDocument13 pagesAn Efficient Convolutional Neural Network-Based Classifier For An Imbalanced Oral Squamous Carcinoma Cell DatasetIAES IJAINo ratings yet
- A Survey On Image Data Augmentation For Deep LearnDocument49 pagesA Survey On Image Data Augmentation For Deep LearnGabriele CastaldiNo ratings yet
- Kleppe 2021Document13 pagesKleppe 2021SAYAN SARKARNo ratings yet
- Data Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4From EverandData Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4No ratings yet
- Mini Sem6 1Document17 pagesMini Sem6 1shaikhnida381No ratings yet
- BFR92/BFR92R: Silicon NPN Planar RF TransistorDocument6 pagesBFR92/BFR92R: Silicon NPN Planar RF TransistornudufoqiNo ratings yet
- END SEMESTER EXAMINATION SCHEDULE OF AUTUMN SEMESTER 2023-24, B. Tech. (Hons.)Document5 pagesEND SEMESTER EXAMINATION SCHEDULE OF AUTUMN SEMESTER 2023-24, B. Tech. (Hons.)Pallav SumanNo ratings yet
- Iso 22301 - BC PPT V2Document53 pagesIso 22301 - BC PPT V2ForbetNo ratings yet
- Servlets and JDBCDocument12 pagesServlets and JDBChima bindhuNo ratings yet
- Book of Ideas A Journal of Creative Direction and Graphic DesignDocument283 pagesBook of Ideas A Journal of Creative Direction and Graphic DesigndizainmdgNo ratings yet
- Phil Collins PresentationDocument12 pagesPhil Collins Presentationapi-315724509No ratings yet
- Department of Civil EngineeringDocument2 pagesDepartment of Civil EngineeringArnold ApostolNo ratings yet
- Hhtfa8e ch01 SMDocument83 pagesHhtfa8e ch01 SMkbrooks323No ratings yet
- Qatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesDocument16 pagesQatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesShashank Hanuman JainNo ratings yet
- Erekle Gozalishvili - Review - Opinion - Brexit and The Continued Troubles in Northern IrelandDocument1 pageErekle Gozalishvili - Review - Opinion - Brexit and The Continued Troubles in Northern IrelandErekle GozalishviliNo ratings yet
- Week 5 - TBM ExcavationDocument16 pagesWeek 5 - TBM ExcavationNilakshiManawaduNo ratings yet
- Business Analysis Fundamentals PDFDocument22 pagesBusiness Analysis Fundamentals PDFsaravanan_mcNo ratings yet
- Depreciation Mar 2020Document20 pagesDepreciation Mar 2020JDE AdminNo ratings yet
- Mazen Salem Baabdullah: Sales Director - Business Development ManagementDocument2 pagesMazen Salem Baabdullah: Sales Director - Business Development ManagementmazNo ratings yet
- Keshab Chandra Panda Vs StateDocument5 pagesKeshab Chandra Panda Vs StateShivangiNo ratings yet
- Drummond Special Master R&R On Crime Fraud in Camera Review Exhibit B R 633-2Document17 pagesDrummond Special Master R&R On Crime Fraud in Camera Review Exhibit B R 633-2PaulWolfNo ratings yet
- Card Level Laptop DesktopDocument2 pagesCard Level Laptop DesktopJawad Anwar100% (1)
- Buyer Agent AgreementDocument2 pagesBuyer Agent AgreementIndia PropertiesNo ratings yet
- Pile RockDocument31 pagesPile RockpandianNo ratings yet
- Contempt of CourtDocument5 pagesContempt of Courtumesh kumarNo ratings yet
- Settlement Deed A Case Study Study of LaDocument3 pagesSettlement Deed A Case Study Study of Lavaidehipragna pragnaNo ratings yet
- Study of Different Cropping Pattern Followed by The Farmers of PunjabDocument8 pagesStudy of Different Cropping Pattern Followed by The Farmers of PunjabGurloveleen KaurNo ratings yet
- Technology NCC 2022Document19 pagesTechnology NCC 2022maganolefikaNo ratings yet
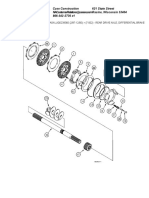
- 621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1Document3 pages621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1JESUSNo ratings yet
- Letter of AcceptanceDocument3 pagesLetter of AcceptanceAbhinay KumarNo ratings yet
- Influence Lines For Indeterminate StructureDocument9 pagesInfluence Lines For Indeterminate StructureveerusiteNo ratings yet
- UG SPOT Business PlanDocument13 pagesUG SPOT Business Plankolawole olajideNo ratings yet
























































































Download as pdf or txt
You might also like
- Google Ads Measurement Certification AnswersDocument33 pagesGoogle Ads Measurement Certification AnswersScribdTranslations100% (1)
- Machine Learning AssignmentDocument55 pagesMachine Learning AssignmentAkashNo ratings yet
- Siebel Communications 8.1Document258 pagesSiebel Communications 8.1Oscar Garcia80% (5)
- Deep Learning Coffee Deasses AbstractDocument4 pagesDeep Learning Coffee Deasses Abstractsamueltamiru2008No ratings yet
- YasarDocument10 pagesYasarMuhammad IbrahimNo ratings yet
- Phase 2Document3 pagesPhase 24074- RashmiNo ratings yet
- Fruit Quality Classifier - Group 1Document12 pagesFruit Quality Classifier - Group 1Bruno TelesNo ratings yet
- Skin Cancer PredictionDocument29 pagesSkin Cancer PredictionfoodloverdjdeepakNo ratings yet
- Research Proposal On Deep Learning For Early Cancer Diagnosis and Prediction.Document2 pagesResearch Proposal On Deep Learning For Early Cancer Diagnosis and Prediction.Ali Abu melhemNo ratings yet
- Review ArticleDocument30 pagesReview Articlemohsinramzan999No ratings yet
- Crop Disease Detection Using Image Processing and Machine LearningDocument7 pagesCrop Disease Detection Using Image Processing and Machine LearningHardik kapoorNo ratings yet
- IEEE Conference Template 1Document4 pagesIEEE Conference Template 1NNM22MC020 DEVIKA UDUPA VNo ratings yet
- Google Research Advances Medical ImagingDocument3 pagesGoogle Research Advances Medical ImagingBhavya SehgalNo ratings yet
- STW7088CEMDocument4 pagesSTW7088CEMManish049No ratings yet
- Enabling Data Diversity - Efficient Automatic Augmentation Via Regularized Adversarial Training PDFDocument12 pagesEnabling Data Diversity - Efficient Automatic Augmentation Via Regularized Adversarial Training PDFdaisyNo ratings yet
- A Transfer Learning Approach To Breast CancerDocument11 pagesA Transfer Learning Approach To Breast CancerNexgen TechnologyNo ratings yet
- Vishal Minor Project 2Document16 pagesVishal Minor Project 2Krishna MalviyaNo ratings yet
- Predicting Diabetes in Medical Datasets Using Machine Learning TechniquesDocument14 pagesPredicting Diabetes in Medical Datasets Using Machine Learning TechniquesSardar Manikanta YadavNo ratings yet
- Electronics 11 00477 v2Document15 pagesElectronics 11 00477 v2Pablo OrricoNo ratings yet
- Report - Nutrition Analysis Using Image ClassificationDocument10 pagesReport - Nutrition Analysis Using Image Classificationpoi poiNo ratings yet
- A Skin Disease Classification Model Based On DenseNet and ConvNeXt FusionDocument19 pagesA Skin Disease Classification Model Based On DenseNet and ConvNeXt FusionRana AtharNo ratings yet
- Technical ReportDocument4 pagesTechnical Reportvjp01122000No ratings yet
- 50 Advanced Machine Learning Questions - ChatGPTDocument18 pages50 Advanced Machine Learning Questions - ChatGPTLily Lauren100% (1)
- Food ApplicationDocument22 pagesFood Applicationsoufiane.bassaNo ratings yet
- COntentDocument43 pagesCOntentprabu sekarNo ratings yet
- (IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanDocument9 pages(IJCST-V12I1P4) :M. Sharmila, Dr. M. NatarajanEighthSenseGroupNo ratings yet
- INTRODUCTIONDocument25 pagesINTRODUCTIONshashankpatel1430No ratings yet
- Food Recognition Using Extreme Learning MachinesDocument8 pagesFood Recognition Using Extreme Learning MachinesIJRASETPublicationsNo ratings yet
- Fine-Grained Food Classification Methods On TheDocument5 pagesFine-Grained Food Classification Methods On ThePavan KumarNo ratings yet
- I Eee Crop AnalyzerDocument9 pagesI Eee Crop Analyzerwekawi2113No ratings yet
- PaperDocument6 pagesPapertaranesvar.cs21No ratings yet
- Implementasi CNN Dan VGG-16 Untuk Mendeteksi GenderDocument10 pagesImplementasi CNN Dan VGG-16 Untuk Mendeteksi GenderAji PurwinarkoNo ratings yet
- Orange and Cream Playful and Illustrative Portrait University Research PosterDocument1 pageOrange and Cream Playful and Illustrative Portrait University Research PosterTrần Chí ThànhNo ratings yet
- Feature EngineeringDocument2 pagesFeature EngineeringEVERYMOMENT ONLENSNo ratings yet
- Ai ML Exp4Document7 pagesAi ML Exp4Kamat HrishikeshNo ratings yet
- DSF Unit 4Document12 pagesDSF Unit 4Hitarth ChughNo ratings yet
- Samatrix Assignment3Document4 pagesSamatrix Assignment3Yash KumarNo ratings yet
- Comparing Data Augmentation Strategies For Deep Image ClassificatDocument9 pagesComparing Data Augmentation Strategies For Deep Image ClassificatARIEL YONATAN ALIN 21.51.2106No ratings yet
- AlbumentationDocument20 pagesAlbumentationChristian Carlos Quispe Bonilla - NEURAL XNo ratings yet
- NTTTTTDocument5 pagesNTTTTTDippal IsraniNo ratings yet
- ProposalDocument12 pagesProposalusama.matin1998No ratings yet
- FRTemplate SoftwareDocument50 pagesFRTemplate SoftwaremohsinNo ratings yet
- WSCG 19Document8 pagesWSCG 19Danilo AntonioNo ratings yet
- 1012 HCI SeminarDocument9 pages1012 HCI Seminarjoelalex528491No ratings yet
- Batch 13ADocument17 pagesBatch 13ADevika gurreNo ratings yet
- DiabetesDocument2 pagesDiabetesLiahNo ratings yet
- Y20cs027 InternshipDocument18 pagesY20cs027 InternshipSARATH CHANDRANo ratings yet
- Updated Research Paper - 295Document19 pagesUpdated Research Paper - 295Pratik NagareNo ratings yet
- My WorkDocument2 pagesMy WorkPritish SinglaNo ratings yet
- Effect of CLAHE-based Enhancement On Bean Leaf Disease Classification Through Explainable AIDocument2 pagesEffect of CLAHE-based Enhancement On Bean Leaf Disease Classification Through Explainable AIVanko SmyrnovNo ratings yet
- Performance and Analysis of Skin Cancer Detection Using Deep LearningDocument6 pagesPerformance and Analysis of Skin Cancer Detection Using Deep LearningjosephineNo ratings yet
- Biomedical Visual Instruction Tuning With Clinician Preference AlignmentDocument18 pagesBiomedical Visual Instruction Tuning With Clinician Preference AlignmentNicola NatalettiNo ratings yet
- Muti-Class Image Classification Using Transfer LearningDocument7 pagesMuti-Class Image Classification Using Transfer LearningIJRASETPublicationsNo ratings yet
- Health Dataset Synopsis NewDocument9 pagesHealth Dataset Synopsis Newnavneet chauhanNo ratings yet
- Diabetes Prediction Using Machine LearningDocument6 pagesDiabetes Prediction Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Reaction Paper 1Document2 pagesReaction Paper 1ron861336No ratings yet
- An Efficient Convolutional Neural Network-Based Classifier For An Imbalanced Oral Squamous Carcinoma Cell DatasetDocument13 pagesAn Efficient Convolutional Neural Network-Based Classifier For An Imbalanced Oral Squamous Carcinoma Cell DatasetIAES IJAINo ratings yet
- A Survey On Image Data Augmentation For Deep LearnDocument49 pagesA Survey On Image Data Augmentation For Deep LearnGabriele CastaldiNo ratings yet
- Kleppe 2021Document13 pagesKleppe 2021SAYAN SARKARNo ratings yet
- Data Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4From EverandData Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4No ratings yet
- Mini Sem6 1Document17 pagesMini Sem6 1shaikhnida381No ratings yet
- BFR92/BFR92R: Silicon NPN Planar RF TransistorDocument6 pagesBFR92/BFR92R: Silicon NPN Planar RF TransistornudufoqiNo ratings yet
- END SEMESTER EXAMINATION SCHEDULE OF AUTUMN SEMESTER 2023-24, B. Tech. (Hons.)Document5 pagesEND SEMESTER EXAMINATION SCHEDULE OF AUTUMN SEMESTER 2023-24, B. Tech. (Hons.)Pallav SumanNo ratings yet
- Iso 22301 - BC PPT V2Document53 pagesIso 22301 - BC PPT V2ForbetNo ratings yet
- Servlets and JDBCDocument12 pagesServlets and JDBChima bindhuNo ratings yet
- Book of Ideas A Journal of Creative Direction and Graphic DesignDocument283 pagesBook of Ideas A Journal of Creative Direction and Graphic DesigndizainmdgNo ratings yet
- Phil Collins PresentationDocument12 pagesPhil Collins Presentationapi-315724509No ratings yet
- Department of Civil EngineeringDocument2 pagesDepartment of Civil EngineeringArnold ApostolNo ratings yet
- Hhtfa8e ch01 SMDocument83 pagesHhtfa8e ch01 SMkbrooks323No ratings yet
- Qatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesDocument16 pagesQatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesShashank Hanuman JainNo ratings yet
- Erekle Gozalishvili - Review - Opinion - Brexit and The Continued Troubles in Northern IrelandDocument1 pageErekle Gozalishvili - Review - Opinion - Brexit and The Continued Troubles in Northern IrelandErekle GozalishviliNo ratings yet
- Week 5 - TBM ExcavationDocument16 pagesWeek 5 - TBM ExcavationNilakshiManawaduNo ratings yet
- Business Analysis Fundamentals PDFDocument22 pagesBusiness Analysis Fundamentals PDFsaravanan_mcNo ratings yet
- Depreciation Mar 2020Document20 pagesDepreciation Mar 2020JDE AdminNo ratings yet
- Mazen Salem Baabdullah: Sales Director - Business Development ManagementDocument2 pagesMazen Salem Baabdullah: Sales Director - Business Development ManagementmazNo ratings yet
- Keshab Chandra Panda Vs StateDocument5 pagesKeshab Chandra Panda Vs StateShivangiNo ratings yet
- Drummond Special Master R&R On Crime Fraud in Camera Review Exhibit B R 633-2Document17 pagesDrummond Special Master R&R On Crime Fraud in Camera Review Exhibit B R 633-2PaulWolfNo ratings yet
- Card Level Laptop DesktopDocument2 pagesCard Level Laptop DesktopJawad Anwar100% (1)
- Buyer Agent AgreementDocument2 pagesBuyer Agent AgreementIndia PropertiesNo ratings yet
- Pile RockDocument31 pagesPile RockpandianNo ratings yet
- Contempt of CourtDocument5 pagesContempt of Courtumesh kumarNo ratings yet
- Settlement Deed A Case Study Study of LaDocument3 pagesSettlement Deed A Case Study Study of Lavaidehipragna pragnaNo ratings yet
- Study of Different Cropping Pattern Followed by The Farmers of PunjabDocument8 pagesStudy of Different Cropping Pattern Followed by The Farmers of PunjabGurloveleen KaurNo ratings yet
- Technology NCC 2022Document19 pagesTechnology NCC 2022maganolefikaNo ratings yet
- 621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1Document3 pages621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1JESUSNo ratings yet
- Letter of AcceptanceDocument3 pagesLetter of AcceptanceAbhinay KumarNo ratings yet
- Influence Lines For Indeterminate StructureDocument9 pagesInfluence Lines For Indeterminate StructureveerusiteNo ratings yet
- UG SPOT Business PlanDocument13 pagesUG SPOT Business Plankolawole olajideNo ratings yet