
Li 2016
Li 2016
You might also like
- TX150+ TX300+ V2.1 ManualDocument46 pagesTX150+ TX300+ V2.1 ManualVincent MNo ratings yet
- HW 02Document8 pagesHW 02Sarah Santiago100% (1)
- Synchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasDocument5 pagesSynchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasSatya NagendraNo ratings yet
- Expander CodesDocument13 pagesExpander CodesAmir Hesam SalavatiNo ratings yet
- Realization of Preconditioned Lanczos AnDocument7 pagesRealization of Preconditioned Lanczos AnHenrikas KurylaNo ratings yet
- Performance Analysis of ConcatenatedDocument4 pagesPerformance Analysis of ConcatenatedNawrasNo ratings yet
- Montepython: Implementing Quantum Monte Carlo Using PythonDocument17 pagesMontepython: Implementing Quantum Monte Carlo Using PythonJuan Bernardo Delgadillo GallardoNo ratings yet
- Analog Modeling Using Event-Driven HDLsDocument4 pagesAnalog Modeling Using Event-Driven HDLsGuru VelmathiNo ratings yet
- Esac2022 167 171Document5 pagesEsac2022 167 171Ricky TerryNo ratings yet
- Design and Implementation of A Configurable Real-Time FPGA-Based Geometric Symmetry-CFAR Processer For Radar Target DetectionDocument14 pagesDesign and Implementation of A Configurable Real-Time FPGA-Based Geometric Symmetry-CFAR Processer For Radar Target DetectionReda BekhakhechaNo ratings yet
- Performance Analysis For Multipliers Based Correlator: Trupti Menghare, Sudesh GuptaDocument5 pagesPerformance Analysis For Multipliers Based Correlator: Trupti Menghare, Sudesh Guptapramod_scribdNo ratings yet
- Upsampling and DownsamplingDocument8 pagesUpsampling and DownsamplingAmit PrajapatiNo ratings yet
- Fractional Order Sliding Mode Control Based Chaos Synchronization and Secure CommunicationDocument6 pagesFractional Order Sliding Mode Control Based Chaos Synchronization and Secure CommunicationPRITAM PARALNo ratings yet
- A Robust Frequency Offset Estimation Scheme For OFDM SystemsDocument6 pagesA Robust Frequency Offset Estimation Scheme For OFDM SystemsSoumitra BhowmickNo ratings yet
- Multi Iteration RegistrationDocument6 pagesMulti Iteration RegistrationSimone FontanaNo ratings yet
- Observer Based Adaptive Output Feedback Tracking Control of Robot ManipulatorsDocument6 pagesObserver Based Adaptive Output Feedback Tracking Control of Robot ManipulatorsberkeogulcanparlakNo ratings yet
- Spectral Efficiency of Uplink SCMA System With CSI EstimationDocument7 pagesSpectral Efficiency of Uplink SCMA System With CSI EstimationMoayad MkhlefNo ratings yet
- Comparison Between LDPC Codes and QC-LDPCDocument4 pagesComparison Between LDPC Codes and QC-LDPCzelalemaschaleyNo ratings yet
- FuzzyVC Anil 1Document11 pagesFuzzyVC Anil 1ranga247No ratings yet
- FarrowDocument4 pagesFarrowamith nayakNo ratings yet
- A BPSK QPSK Timing Error Detector For SampledDocument7 pagesA BPSK QPSK Timing Error Detector For SampledFahmi MuradNo ratings yet
- Design of Parallel Concatenated Convolution Turbo Code Using Harmony Search AlgorithmDocument6 pagesDesign of Parallel Concatenated Convolution Turbo Code Using Harmony Search AlgorithmSubhabrata BanerjeeNo ratings yet
- Efficient Model For OFDM Based IEEE 802.11 Receiver With Autocorrelation Technique and CORDIC AlgorithmDocument8 pagesEfficient Model For OFDM Based IEEE 802.11 Receiver With Autocorrelation Technique and CORDIC AlgorithmInternational Journal of computational Engineering research (IJCER)No ratings yet
- Performance Analysis of Incremental Redundancy Hybrid ARQ Schemes With Parallel Concatenated LDPC CodesDocument3 pagesPerformance Analysis of Incremental Redundancy Hybrid ARQ Schemes With Parallel Concatenated LDPC Codesawais04No ratings yet
- Analysis of Timing Synchronization Techniques in OFDM For SDR Waveform Performance ComparisonDocument6 pagesAnalysis of Timing Synchronization Techniques in OFDM For SDR Waveform Performance ComparisonÖzkan SezerNo ratings yet
- Very High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic DevicesDocument5 pagesVery High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic Devices8148593856No ratings yet
- An Analog Decoder For Concatenated Magnetic Recording SchemesDocument6 pagesAn Analog Decoder For Concatenated Magnetic Recording SchemescaduzinhoxNo ratings yet
- Power Law Filters A New Class of Fractional - 2021 - AEU - International JournDocument13 pagesPower Law Filters A New Class of Fractional - 2021 - AEU - International JournDr. D. V. KamathNo ratings yet
- 50ICRASE130513Document4 pages50ICRASE130513Kanaga VaratharajanNo ratings yet
- Image Encryption With Fusion of Two Maps: Yannick Abanda, Alain Tiedeu, Guillaume KomDocument28 pagesImage Encryption With Fusion of Two Maps: Yannick Abanda, Alain Tiedeu, Guillaume KomYannick AbandaNo ratings yet
- Performance Review of Serially Concatenated RSC-RSC Codes Using Non-Iterative Viterbi Decoding TechniqueDocument6 pagesPerformance Review of Serially Concatenated RSC-RSC Codes Using Non-Iterative Viterbi Decoding TechniqueJacob BauerNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationMatthew CarterNo ratings yet
- Synchronization in IEEE 802.15.4 Zigbee Transceiver Using Matlab SimulinkDocument5 pagesSynchronization in IEEE 802.15.4 Zigbee Transceiver Using Matlab SimulinktesteNo ratings yet
- System Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsDocument8 pagesSystem Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsanchisanNo ratings yet
- Control Systems - PART - ADocument12 pagesControl Systems - PART - Aaarthir88100% (1)
- BER Comparison Between Turbo, LDPC, and Polar CodesDocument7 pagesBER Comparison Between Turbo, LDPC, and Polar CodesGkhn MnrsNo ratings yet
- Simulink Library Development and Implementation For VLSI Testing in MatlabDocument8 pagesSimulink Library Development and Implementation For VLSI Testing in MatlabM Chandan ShankarNo ratings yet
- Formal Verification of Logical Link Control and Adaptation ProtocolDocument4 pagesFormal Verification of Logical Link Control and Adaptation ProtocolBuss BussNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationdabajiNo ratings yet
- Turbo-Like Processing For Scalable Interleaving Pattern Generation Application To 60 GHZ UWB-OFDM SystemsDocument6 pagesTurbo-Like Processing For Scalable Interleaving Pattern Generation Application To 60 GHZ UWB-OFDM SystemsPraveen GanigerNo ratings yet
- Observer Based Output Feedback Tracking Control of Robot ManipulatorsDocument6 pagesObserver Based Output Feedback Tracking Control of Robot ManipulatorsberkeogulcanparlakNo ratings yet
- Sampled-Data Regulation of A Class of Time Varying Systems Based On A Realizable Reconstruction FilterDocument6 pagesSampled-Data Regulation of A Class of Time Varying Systems Based On A Realizable Reconstruction FilterIbraheem ZebNo ratings yet
- SRT Division Architectures and ImplementationsDocument8 pagesSRT Division Architectures and ImplementationsAsif KhanNo ratings yet
- Carrier Recovery and Automatic Gain Control On FPGA's Based Platform (IEEE 802.15.3c Mm-Wave PHY Application)Document5 pagesCarrier Recovery and Automatic Gain Control On FPGA's Based Platform (IEEE 802.15.3c Mm-Wave PHY Application)skalyd100% (1)
- Parallel CRC RealizationDocument20 pagesParallel CRC RealizationgoutambiswaNo ratings yet
- #Parallel CRC RealizationDocument8 pages#Parallel CRC RealizationBainan ChenNo ratings yet
- Analyzing Logistic Map Pseudorandom Number Generators ForDocument8 pagesAnalyzing Logistic Map Pseudorandom Number Generators Foransam.moh2016No ratings yet
- dSPACE Implementation of Fuzzy Logic Based Vector Control of Induction MotorDocument6 pagesdSPACE Implementation of Fuzzy Logic Based Vector Control of Induction MotorAshwani RanaNo ratings yet
- Citation Linear Parameter-Varying System Identification of An Industrial Ball Screw SetupDocument7 pagesCitation Linear Parameter-Varying System Identification of An Industrial Ball Screw SetupJessica JaraNo ratings yet
- High-Speed and Hardware-Efficient Successive Cancellation Polar-DecoderDocument5 pagesHigh-Speed and Hardware-Efficient Successive Cancellation Polar-Decodersameer nigamNo ratings yet
- FPAA-based Implementation of Fractional-Order Chaotic Oscillators Using First-Order Active Filter BlocksDocument19 pagesFPAA-based Implementation of Fractional-Order Chaotic Oscillators Using First-Order Active Filter BlockspunithNo ratings yet
- Content PDFDocument14 pagesContent PDFrobbyyuNo ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document11 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850ashishNo ratings yet
- A Robust Baud Rate Estimator For Noncooperative Demodulation PDFDocument5 pagesA Robust Baud Rate Estimator For Noncooperative Demodulation PDFSorin GoldenbergNo ratings yet
- Hardware Implementation BackpropagationDocument14 pagesHardware Implementation BackpropagationDavidThânNo ratings yet
- Randomized AlgorithmDocument6 pagesRandomized AlgorithmPrateek BhatnagarNo ratings yet
- Spline Path Following For Redundant Mechanical SystemsDocument15 pagesSpline Path Following For Redundant Mechanical SystemsMohammedNo ratings yet
- Multi Objective ACODocument6 pagesMulti Objective ACOlahlouhNo ratings yet
- Analysis Simulation of Ds-Cdma Mobile System in Non-Linear, Frequency Selective Slow ChannelDocument5 pagesAnalysis Simulation of Ds-Cdma Mobile System in Non-Linear, Frequency Selective Slow ChannelAnonymous JPbUTto8tqNo ratings yet
- Parallel CRC GeneratorDocument20 pagesParallel CRC GeneratorEvgeni StavinovNo ratings yet
- Evaluate Error Correction Performance of Binary Repeat Accumulate Code and Quasi Cyclic Low-Density Parity-Check Code in 5G New-RadioDocument10 pagesEvaluate Error Correction Performance of Binary Repeat Accumulate Code and Quasi Cyclic Low-Density Parity-Check Code in 5G New-Radioah1929No ratings yet
- Spline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsFrom EverandSpline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsNo ratings yet
- Afifi When Color Constancy Goes Wrong1Document10 pagesAfifi When Color Constancy Goes Wrong1hung kungNo ratings yet
- Carrier Frequency OffsetDocument2 pagesCarrier Frequency Offsethung kungNo ratings yet
- ELECH409 Th03Document61 pagesELECH409 Th03hung kungNo ratings yet
- Sensors 22 00554 v2Document12 pagesSensors 22 00554 v2hung kungNo ratings yet
- Note 1Document25 pagesNote 1hung kungNo ratings yet
- Atmospheric Influences On Satellite CommunicationsDocument5 pagesAtmospheric Influences On Satellite Communicationshung kungNo ratings yet
- Xiao 2018Document11 pagesXiao 2018hung kungNo ratings yet
- A Ka-Band Receiver Front-End With Noise InjectionDocument15 pagesA Ka-Band Receiver Front-End With Noise Injectionhung kungNo ratings yet
- PIERS2013 Taipei Proceedings 04Document314 pagesPIERS2013 Taipei Proceedings 04hung kungNo ratings yet
- ELECH409 Th04Document51 pagesELECH409 Th04hung kungNo ratings yet
- W HKT Yly EHgyk DM VNDocument6 pagesW HKT Yly EHgyk DM VNhung kungNo ratings yet
- 409 New Lab 2 CorrDocument9 pages409 New Lab 2 Corrhung kungNo ratings yet
- Session 3Document10 pagesSession 3hung kungNo ratings yet
- Lab VPNDocument9 pagesLab VPNhung kungNo ratings yet
- CSD 2023Document34 pagesCSD 2023hung kungNo ratings yet
- Report - Sergi GallardoDocument74 pagesReport - Sergi Gallardohung kungNo ratings yet
- Design of Polyrod Antenna Having Iso Ux Radiation Characteristic For Satellite Communication SystemsDocument8 pagesDesign of Polyrod Antenna Having Iso Ux Radiation Characteristic For Satellite Communication Systemshung kungNo ratings yet
- Installation GNS3Document6 pagesInstallation GNS3hung kungNo ratings yet
- Isolated SCM5B Analog Signal Conditioning ProductsDocument4 pagesIsolated SCM5B Analog Signal Conditioning ProductsvelmuruganNo ratings yet
- Amplitude Modulat ION: Communications Lab (EE351)Document5 pagesAmplitude Modulat ION: Communications Lab (EE351)Priyesh PandeyNo ratings yet
- Feedback OscillatorsDocument27 pagesFeedback OscillatorsAlex William JohnNo ratings yet
- 12 - JIP Huawei - Small Cell Trial PDFDocument46 pages12 - JIP Huawei - Small Cell Trial PDFMahamad BarznjiNo ratings yet
- CMU200 User Manual R&S EnglishDocument644 pagesCMU200 User Manual R&S EnglishGuo ZhiwenNo ratings yet
- Acoustic Noise Cancellation: From Matlab and Simulink To Real Time With Ti DspsDocument26 pagesAcoustic Noise Cancellation: From Matlab and Simulink To Real Time With Ti DspsSapantan MariaNo ratings yet
- Expt No: 1 Mode Characteristics of Reflex Klystron 1.1 ObjectiveDocument6 pagesExpt No: 1 Mode Characteristics of Reflex Klystron 1.1 ObjectivePriya DarshuNo ratings yet
- The Path To 5G in Australia 03 August 2018 2Document28 pagesThe Path To 5G in Australia 03 August 2018 2a_sahai100% (2)
- VX602,1502,2002,3002,4002,6002,2004,3004,4004,6005Document14 pagesVX602,1502,2002,3002,4002,6002,2004,3004,4004,6005Alex GeleverNo ratings yet
- 2.4 GHZ LNA Filter DesingDocument4 pages2.4 GHZ LNA Filter DesingNikhilAKothariNo ratings yet
- Decimation Filtering For Complex Sigma Delta Analog To Digital Conversion in A Low-IF ReceiverDocument48 pagesDecimation Filtering For Complex Sigma Delta Analog To Digital Conversion in A Low-IF ReceiverSimyon PinskyNo ratings yet
- 2200 Chapter - 6 - Addendum (Ebook) Actualizacion y Mejoras Fisica Orban 2200Document87 pages2200 Chapter - 6 - Addendum (Ebook) Actualizacion y Mejoras Fisica Orban 2200Gustavo RamirezNo ratings yet
- SLR350Ni Receiver PDFDocument19 pagesSLR350Ni Receiver PDFVictor RamirezNo ratings yet
- FinalDocument19 pagesFinalkluNo ratings yet
- A Patch Antenna Design With Boosted Bandwidth For Ism Band ApplicationsDocument9 pagesA Patch Antenna Design With Boosted Bandwidth For Ism Band ApplicationsijansjournalNo ratings yet
- Cpre 281: Digital Logic: Instructor: Alexander StoytchevDocument108 pagesCpre 281: Digital Logic: Instructor: Alexander StoytchevHarsh WadhwaNo ratings yet
- Module 2 - Gain, Attenuation, and DecibelsDocument12 pagesModule 2 - Gain, Attenuation, and DecibelsMiscrits TRENo ratings yet
- Scorpion System Four: SEG Y FormatDocument25 pagesScorpion System Four: SEG Y FormatTanaskumarKanesanNo ratings yet
- 80010456V02Document2 pages80010456V02mau_mmx5738100% (2)
- Comba Odp-065r18bv (Single)Document1 pageComba Odp-065r18bv (Single)DAVROJNo ratings yet
- RF Plan Release 3.0 Release NotesDocument6 pagesRF Plan Release 3.0 Release NotesMichele PastoreNo ratings yet
- Xbee S6 PDFDocument86 pagesXbee S6 PDFRodrigo Missagia HulleNo ratings yet
- Combiner Box InBuilding DASDocument29 pagesCombiner Box InBuilding DASAnonymous pkbJNqN2No ratings yet
- Ch03-2-Examples OnGOSDocument55 pagesCh03-2-Examples OnGOSLeviOsaNo ratings yet
- APFM SeriesDocument3 pagesAPFM SeriessibashisdharNo ratings yet
- Victor's Video Scaler Cook BookDocument30 pagesVictor's Video Scaler Cook BookgursimranjitsinghNo ratings yet
- LECTURE 4-Direct Link Networks Part IDocument12 pagesLECTURE 4-Direct Link Networks Part IyesmuraliNo ratings yet
- Practical 6 Aim - : Create A Basic MANET Implementation Simulation For Packet Animation and Packet TraceDocument3 pagesPractical 6 Aim - : Create A Basic MANET Implementation Simulation For Packet Animation and Packet TracePraveen MishraNo ratings yet











































































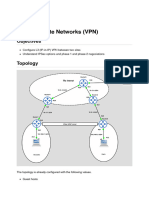































Download as pdf or txt
You might also like
- TX150+ TX300+ V2.1 ManualDocument46 pagesTX150+ TX300+ V2.1 ManualVincent MNo ratings yet
- HW 02Document8 pagesHW 02Sarah Santiago100% (1)
- Synchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasDocument5 pagesSynchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasSatya NagendraNo ratings yet
- Expander CodesDocument13 pagesExpander CodesAmir Hesam SalavatiNo ratings yet
- Realization of Preconditioned Lanczos AnDocument7 pagesRealization of Preconditioned Lanczos AnHenrikas KurylaNo ratings yet
- Performance Analysis of ConcatenatedDocument4 pagesPerformance Analysis of ConcatenatedNawrasNo ratings yet
- Montepython: Implementing Quantum Monte Carlo Using PythonDocument17 pagesMontepython: Implementing Quantum Monte Carlo Using PythonJuan Bernardo Delgadillo GallardoNo ratings yet
- Analog Modeling Using Event-Driven HDLsDocument4 pagesAnalog Modeling Using Event-Driven HDLsGuru VelmathiNo ratings yet
- Esac2022 167 171Document5 pagesEsac2022 167 171Ricky TerryNo ratings yet
- Design and Implementation of A Configurable Real-Time FPGA-Based Geometric Symmetry-CFAR Processer For Radar Target DetectionDocument14 pagesDesign and Implementation of A Configurable Real-Time FPGA-Based Geometric Symmetry-CFAR Processer For Radar Target DetectionReda BekhakhechaNo ratings yet
- Performance Analysis For Multipliers Based Correlator: Trupti Menghare, Sudesh GuptaDocument5 pagesPerformance Analysis For Multipliers Based Correlator: Trupti Menghare, Sudesh Guptapramod_scribdNo ratings yet
- Upsampling and DownsamplingDocument8 pagesUpsampling and DownsamplingAmit PrajapatiNo ratings yet
- Fractional Order Sliding Mode Control Based Chaos Synchronization and Secure CommunicationDocument6 pagesFractional Order Sliding Mode Control Based Chaos Synchronization and Secure CommunicationPRITAM PARALNo ratings yet
- A Robust Frequency Offset Estimation Scheme For OFDM SystemsDocument6 pagesA Robust Frequency Offset Estimation Scheme For OFDM SystemsSoumitra BhowmickNo ratings yet
- Multi Iteration RegistrationDocument6 pagesMulti Iteration RegistrationSimone FontanaNo ratings yet
- Observer Based Adaptive Output Feedback Tracking Control of Robot ManipulatorsDocument6 pagesObserver Based Adaptive Output Feedback Tracking Control of Robot ManipulatorsberkeogulcanparlakNo ratings yet
- Spectral Efficiency of Uplink SCMA System With CSI EstimationDocument7 pagesSpectral Efficiency of Uplink SCMA System With CSI EstimationMoayad MkhlefNo ratings yet
- Comparison Between LDPC Codes and QC-LDPCDocument4 pagesComparison Between LDPC Codes and QC-LDPCzelalemaschaleyNo ratings yet
- FuzzyVC Anil 1Document11 pagesFuzzyVC Anil 1ranga247No ratings yet
- FarrowDocument4 pagesFarrowamith nayakNo ratings yet
- A BPSK QPSK Timing Error Detector For SampledDocument7 pagesA BPSK QPSK Timing Error Detector For SampledFahmi MuradNo ratings yet
- Design of Parallel Concatenated Convolution Turbo Code Using Harmony Search AlgorithmDocument6 pagesDesign of Parallel Concatenated Convolution Turbo Code Using Harmony Search AlgorithmSubhabrata BanerjeeNo ratings yet
- Efficient Model For OFDM Based IEEE 802.11 Receiver With Autocorrelation Technique and CORDIC AlgorithmDocument8 pagesEfficient Model For OFDM Based IEEE 802.11 Receiver With Autocorrelation Technique and CORDIC AlgorithmInternational Journal of computational Engineering research (IJCER)No ratings yet
- Performance Analysis of Incremental Redundancy Hybrid ARQ Schemes With Parallel Concatenated LDPC CodesDocument3 pagesPerformance Analysis of Incremental Redundancy Hybrid ARQ Schemes With Parallel Concatenated LDPC Codesawais04No ratings yet
- Analysis of Timing Synchronization Techniques in OFDM For SDR Waveform Performance ComparisonDocument6 pagesAnalysis of Timing Synchronization Techniques in OFDM For SDR Waveform Performance ComparisonÖzkan SezerNo ratings yet
- Very High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic DevicesDocument5 pagesVery High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic Devices8148593856No ratings yet
- An Analog Decoder For Concatenated Magnetic Recording SchemesDocument6 pagesAn Analog Decoder For Concatenated Magnetic Recording SchemescaduzinhoxNo ratings yet
- Power Law Filters A New Class of Fractional - 2021 - AEU - International JournDocument13 pagesPower Law Filters A New Class of Fractional - 2021 - AEU - International JournDr. D. V. KamathNo ratings yet
- 50ICRASE130513Document4 pages50ICRASE130513Kanaga VaratharajanNo ratings yet
- Image Encryption With Fusion of Two Maps: Yannick Abanda, Alain Tiedeu, Guillaume KomDocument28 pagesImage Encryption With Fusion of Two Maps: Yannick Abanda, Alain Tiedeu, Guillaume KomYannick AbandaNo ratings yet
- Performance Review of Serially Concatenated RSC-RSC Codes Using Non-Iterative Viterbi Decoding TechniqueDocument6 pagesPerformance Review of Serially Concatenated RSC-RSC Codes Using Non-Iterative Viterbi Decoding TechniqueJacob BauerNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationMatthew CarterNo ratings yet
- Synchronization in IEEE 802.15.4 Zigbee Transceiver Using Matlab SimulinkDocument5 pagesSynchronization in IEEE 802.15.4 Zigbee Transceiver Using Matlab SimulinktesteNo ratings yet
- System Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsDocument8 pagesSystem Design Considerations For The Use Turbo Codes in Aeronautical Satellite CommuncationsanchisanNo ratings yet
- Control Systems - PART - ADocument12 pagesControl Systems - PART - Aaarthir88100% (1)
- BER Comparison Between Turbo, LDPC, and Polar CodesDocument7 pagesBER Comparison Between Turbo, LDPC, and Polar CodesGkhn MnrsNo ratings yet
- Simulink Library Development and Implementation For VLSI Testing in MatlabDocument8 pagesSimulink Library Development and Implementation For VLSI Testing in MatlabM Chandan ShankarNo ratings yet
- Formal Verification of Logical Link Control and Adaptation ProtocolDocument4 pagesFormal Verification of Logical Link Control and Adaptation ProtocolBuss BussNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationdabajiNo ratings yet
- Turbo-Like Processing For Scalable Interleaving Pattern Generation Application To 60 GHZ UWB-OFDM SystemsDocument6 pagesTurbo-Like Processing For Scalable Interleaving Pattern Generation Application To 60 GHZ UWB-OFDM SystemsPraveen GanigerNo ratings yet
- Observer Based Output Feedback Tracking Control of Robot ManipulatorsDocument6 pagesObserver Based Output Feedback Tracking Control of Robot ManipulatorsberkeogulcanparlakNo ratings yet
- Sampled-Data Regulation of A Class of Time Varying Systems Based On A Realizable Reconstruction FilterDocument6 pagesSampled-Data Regulation of A Class of Time Varying Systems Based On A Realizable Reconstruction FilterIbraheem ZebNo ratings yet
- SRT Division Architectures and ImplementationsDocument8 pagesSRT Division Architectures and ImplementationsAsif KhanNo ratings yet
- Carrier Recovery and Automatic Gain Control On FPGA's Based Platform (IEEE 802.15.3c Mm-Wave PHY Application)Document5 pagesCarrier Recovery and Automatic Gain Control On FPGA's Based Platform (IEEE 802.15.3c Mm-Wave PHY Application)skalyd100% (1)
- Parallel CRC RealizationDocument20 pagesParallel CRC RealizationgoutambiswaNo ratings yet
- #Parallel CRC RealizationDocument8 pages#Parallel CRC RealizationBainan ChenNo ratings yet
- Analyzing Logistic Map Pseudorandom Number Generators ForDocument8 pagesAnalyzing Logistic Map Pseudorandom Number Generators Foransam.moh2016No ratings yet
- dSPACE Implementation of Fuzzy Logic Based Vector Control of Induction MotorDocument6 pagesdSPACE Implementation of Fuzzy Logic Based Vector Control of Induction MotorAshwani RanaNo ratings yet
- Citation Linear Parameter-Varying System Identification of An Industrial Ball Screw SetupDocument7 pagesCitation Linear Parameter-Varying System Identification of An Industrial Ball Screw SetupJessica JaraNo ratings yet
- High-Speed and Hardware-Efficient Successive Cancellation Polar-DecoderDocument5 pagesHigh-Speed and Hardware-Efficient Successive Cancellation Polar-Decodersameer nigamNo ratings yet
- FPAA-based Implementation of Fractional-Order Chaotic Oscillators Using First-Order Active Filter BlocksDocument19 pagesFPAA-based Implementation of Fractional-Order Chaotic Oscillators Using First-Order Active Filter BlockspunithNo ratings yet
- Content PDFDocument14 pagesContent PDFrobbyyuNo ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document11 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850ashishNo ratings yet
- A Robust Baud Rate Estimator For Noncooperative Demodulation PDFDocument5 pagesA Robust Baud Rate Estimator For Noncooperative Demodulation PDFSorin GoldenbergNo ratings yet
- Hardware Implementation BackpropagationDocument14 pagesHardware Implementation BackpropagationDavidThânNo ratings yet
- Randomized AlgorithmDocument6 pagesRandomized AlgorithmPrateek BhatnagarNo ratings yet
- Spline Path Following For Redundant Mechanical SystemsDocument15 pagesSpline Path Following For Redundant Mechanical SystemsMohammedNo ratings yet
- Multi Objective ACODocument6 pagesMulti Objective ACOlahlouhNo ratings yet
- Analysis Simulation of Ds-Cdma Mobile System in Non-Linear, Frequency Selective Slow ChannelDocument5 pagesAnalysis Simulation of Ds-Cdma Mobile System in Non-Linear, Frequency Selective Slow ChannelAnonymous JPbUTto8tqNo ratings yet
- Parallel CRC GeneratorDocument20 pagesParallel CRC GeneratorEvgeni StavinovNo ratings yet
- Evaluate Error Correction Performance of Binary Repeat Accumulate Code and Quasi Cyclic Low-Density Parity-Check Code in 5G New-RadioDocument10 pagesEvaluate Error Correction Performance of Binary Repeat Accumulate Code and Quasi Cyclic Low-Density Parity-Check Code in 5G New-Radioah1929No ratings yet
- Spline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsFrom EverandSpline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsNo ratings yet
- Afifi When Color Constancy Goes Wrong1Document10 pagesAfifi When Color Constancy Goes Wrong1hung kungNo ratings yet
- Carrier Frequency OffsetDocument2 pagesCarrier Frequency Offsethung kungNo ratings yet
- ELECH409 Th03Document61 pagesELECH409 Th03hung kungNo ratings yet
- Sensors 22 00554 v2Document12 pagesSensors 22 00554 v2hung kungNo ratings yet
- Note 1Document25 pagesNote 1hung kungNo ratings yet
- Atmospheric Influences On Satellite CommunicationsDocument5 pagesAtmospheric Influences On Satellite Communicationshung kungNo ratings yet
- Xiao 2018Document11 pagesXiao 2018hung kungNo ratings yet
- A Ka-Band Receiver Front-End With Noise InjectionDocument15 pagesA Ka-Band Receiver Front-End With Noise Injectionhung kungNo ratings yet
- PIERS2013 Taipei Proceedings 04Document314 pagesPIERS2013 Taipei Proceedings 04hung kungNo ratings yet
- ELECH409 Th04Document51 pagesELECH409 Th04hung kungNo ratings yet
- W HKT Yly EHgyk DM VNDocument6 pagesW HKT Yly EHgyk DM VNhung kungNo ratings yet
- 409 New Lab 2 CorrDocument9 pages409 New Lab 2 Corrhung kungNo ratings yet
- Session 3Document10 pagesSession 3hung kungNo ratings yet
- Lab VPNDocument9 pagesLab VPNhung kungNo ratings yet
- CSD 2023Document34 pagesCSD 2023hung kungNo ratings yet
- Report - Sergi GallardoDocument74 pagesReport - Sergi Gallardohung kungNo ratings yet
- Design of Polyrod Antenna Having Iso Ux Radiation Characteristic For Satellite Communication SystemsDocument8 pagesDesign of Polyrod Antenna Having Iso Ux Radiation Characteristic For Satellite Communication Systemshung kungNo ratings yet
- Installation GNS3Document6 pagesInstallation GNS3hung kungNo ratings yet
- Isolated SCM5B Analog Signal Conditioning ProductsDocument4 pagesIsolated SCM5B Analog Signal Conditioning ProductsvelmuruganNo ratings yet
- Amplitude Modulat ION: Communications Lab (EE351)Document5 pagesAmplitude Modulat ION: Communications Lab (EE351)Priyesh PandeyNo ratings yet
- Feedback OscillatorsDocument27 pagesFeedback OscillatorsAlex William JohnNo ratings yet
- 12 - JIP Huawei - Small Cell Trial PDFDocument46 pages12 - JIP Huawei - Small Cell Trial PDFMahamad BarznjiNo ratings yet
- CMU200 User Manual R&S EnglishDocument644 pagesCMU200 User Manual R&S EnglishGuo ZhiwenNo ratings yet
- Acoustic Noise Cancellation: From Matlab and Simulink To Real Time With Ti DspsDocument26 pagesAcoustic Noise Cancellation: From Matlab and Simulink To Real Time With Ti DspsSapantan MariaNo ratings yet
- Expt No: 1 Mode Characteristics of Reflex Klystron 1.1 ObjectiveDocument6 pagesExpt No: 1 Mode Characteristics of Reflex Klystron 1.1 ObjectivePriya DarshuNo ratings yet
- The Path To 5G in Australia 03 August 2018 2Document28 pagesThe Path To 5G in Australia 03 August 2018 2a_sahai100% (2)
- VX602,1502,2002,3002,4002,6002,2004,3004,4004,6005Document14 pagesVX602,1502,2002,3002,4002,6002,2004,3004,4004,6005Alex GeleverNo ratings yet
- 2.4 GHZ LNA Filter DesingDocument4 pages2.4 GHZ LNA Filter DesingNikhilAKothariNo ratings yet
- Decimation Filtering For Complex Sigma Delta Analog To Digital Conversion in A Low-IF ReceiverDocument48 pagesDecimation Filtering For Complex Sigma Delta Analog To Digital Conversion in A Low-IF ReceiverSimyon PinskyNo ratings yet
- 2200 Chapter - 6 - Addendum (Ebook) Actualizacion y Mejoras Fisica Orban 2200Document87 pages2200 Chapter - 6 - Addendum (Ebook) Actualizacion y Mejoras Fisica Orban 2200Gustavo RamirezNo ratings yet
- SLR350Ni Receiver PDFDocument19 pagesSLR350Ni Receiver PDFVictor RamirezNo ratings yet
- FinalDocument19 pagesFinalkluNo ratings yet
- A Patch Antenna Design With Boosted Bandwidth For Ism Band ApplicationsDocument9 pagesA Patch Antenna Design With Boosted Bandwidth For Ism Band ApplicationsijansjournalNo ratings yet
- Cpre 281: Digital Logic: Instructor: Alexander StoytchevDocument108 pagesCpre 281: Digital Logic: Instructor: Alexander StoytchevHarsh WadhwaNo ratings yet
- Module 2 - Gain, Attenuation, and DecibelsDocument12 pagesModule 2 - Gain, Attenuation, and DecibelsMiscrits TRENo ratings yet
- Scorpion System Four: SEG Y FormatDocument25 pagesScorpion System Four: SEG Y FormatTanaskumarKanesanNo ratings yet
- 80010456V02Document2 pages80010456V02mau_mmx5738100% (2)
- Comba Odp-065r18bv (Single)Document1 pageComba Odp-065r18bv (Single)DAVROJNo ratings yet
- RF Plan Release 3.0 Release NotesDocument6 pagesRF Plan Release 3.0 Release NotesMichele PastoreNo ratings yet
- Xbee S6 PDFDocument86 pagesXbee S6 PDFRodrigo Missagia HulleNo ratings yet
- Combiner Box InBuilding DASDocument29 pagesCombiner Box InBuilding DASAnonymous pkbJNqN2No ratings yet
- Ch03-2-Examples OnGOSDocument55 pagesCh03-2-Examples OnGOSLeviOsaNo ratings yet
- APFM SeriesDocument3 pagesAPFM SeriessibashisdharNo ratings yet
- Victor's Video Scaler Cook BookDocument30 pagesVictor's Video Scaler Cook BookgursimranjitsinghNo ratings yet
- LECTURE 4-Direct Link Networks Part IDocument12 pagesLECTURE 4-Direct Link Networks Part IyesmuraliNo ratings yet
- Practical 6 Aim - : Create A Basic MANET Implementation Simulation For Packet Animation and Packet TraceDocument3 pagesPractical 6 Aim - : Create A Basic MANET Implementation Simulation For Packet Animation and Packet TracePraveen MishraNo ratings yet