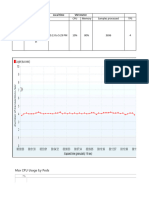
Download as docx, pdf, or txt
You might also like
- Solution Manual For Quantitative Analysis For Management, 12th EditionDocument8 pagesSolution Manual For Quantitative Analysis For Management, 12th EditionPeter Jackson64% (14)
- Mongo DBDocument13 pagesMongo DBMohit SainiNo ratings yet
- All in All QADocument125 pagesAll in All QAleworeNo ratings yet
- What Is Mongodb?: Unit-5Document14 pagesWhat Is Mongodb?: Unit-5mahesh babuNo ratings yet
- MongoDB BasicDocument9 pagesMongoDB BasicShaik ValiNo ratings yet
- Mongo DBDocument5 pagesMongo DBRonesh Kumar100% (1)
- Mongodb NotesDocument8 pagesMongodb NotesrehanNo ratings yet
- Mongo DBDocument21 pagesMongo DBAmrit RanabhatNo ratings yet
- Mongo DBDocument227 pagesMongo DBshivanjali.22210447No ratings yet
- DBMS NOSQLMongoDBMCQDocument9 pagesDBMS NOSQLMongoDBMCQsaumya tiwariNo ratings yet
- Presentation by Rajashekar G.SDocument79 pagesPresentation by Rajashekar G.SSuraj RajendraNo ratings yet
- NoSQL CIA EXAMS QUESTIONS WITH ANSWERSDocument32 pagesNoSQL CIA EXAMS QUESTIONS WITH ANSWERSshizuka shizukaNo ratings yet
- Commonly Asked MongoDB Interview Questions (2023) - InterviewbitDocument21 pagesCommonly Asked MongoDB Interview Questions (2023) - InterviewbitSagar ChaudhariNo ratings yet
- Mongodb Cheat SheetDocument10 pagesMongodb Cheat Sheetabhishekshaw122002No ratings yet
- Introductiont MongoDBDocument44 pagesIntroductiont MongoDBBASNILLO, DAVID JHONSONNo ratings yet
- Mongo DB Session 01 DocumentDocument10 pagesMongo DB Session 01 DocumentArun KumarNo ratings yet
- What Is MongoDB - Introduction, Architecture, Features & ExampleDocument8 pagesWhat Is MongoDB - Introduction, Architecture, Features & Examplejppn33No ratings yet
- MongoDB Quick GuideDocument61 pagesMongoDB Quick GuideDulari Bosamiya BhattNo ratings yet
- What Is Mongodb - Working and FeaturesDocument11 pagesWhat Is Mongodb - Working and FeaturesRaj PaliwalNo ratings yet
- MongoDB DocumentDocument3 pagesMongoDB Documentmevaibhav91No ratings yet
- Unit 5Document12 pagesUnit 5jokike8919No ratings yet
- Data Management in MongoDBDocument3 pagesData Management in MongoDBmyjansiraniselvamNo ratings yet
- Mongodb TutorialDocument15 pagesMongodb TutorialSrz CreationsNo ratings yet
- SQL Vs Mongo DBDocument40 pagesSQL Vs Mongo DBAMEYA ANAND JAMBHORKAR 21111408No ratings yet
- Mongodb Interview Q ADocument9 pagesMongodb Interview Q AechotrNo ratings yet
- UEU Course 9306 7 - 0154 PDFDocument68 pagesUEU Course 9306 7 - 0154 PDFAdhie_xNo ratings yet
- Basic Mongodb Interview QuestionsDocument7 pagesBasic Mongodb Interview QuestionsNirusha SNo ratings yet
- Performance Evaluation of Mysql and Mongodb DatabasesDocument8 pagesPerformance Evaluation of Mysql and Mongodb DatabasesJames MorenoNo ratings yet
- What Is Mongodb - Working and FeaturesDocument11 pagesWhat Is Mongodb - Working and FeaturesAbhishek Das100% (1)
- Mongodb TutorialDocument4 pagesMongodb TutorialVikram JhaNo ratings yet
- MEAN Ebook - CodeWithRandomDocument524 pagesMEAN Ebook - CodeWithRandomweshine.dataentry14No ratings yet
- MONGO Q&aDocument4 pagesMONGO Q&aMayur PanchalNo ratings yet
- Mongo Best PracticesDocument31 pagesMongo Best PracticesAbraham MartinezNo ratings yet
- MongoDB Atlas Best Practices White Paper PDFDocument21 pagesMongoDB Atlas Best Practices White Paper PDFErick Ricardo NarbonaNo ratings yet
- Experiment No 4Document9 pagesExperiment No 4Aman JainNo ratings yet
- Experiment No. 1 BDADocument8 pagesExperiment No. 1 BDAgowona4117No ratings yet
- Mongodb: Presented By: Josmi Agnes Jose Roll Number: 20bda27Document27 pagesMongodb: Presented By: Josmi Agnes Jose Roll Number: 20bda27josmiNo ratings yet
- DBMS Arman MONGODBDocument5 pagesDBMS Arman MONGODBheyimchad28No ratings yet
- Mongo DBDocument8 pagesMongo DBGauravNo ratings yet
- Mongo DBDocument8 pagesMongo DBGauravNo ratings yet
- Mongodb: by Shashank GuptaDocument20 pagesMongodb: by Shashank GuptaShashank GuptaNo ratings yet
- Mongodb: Developed by Mongodb IncDocument27 pagesMongodb: Developed by Mongodb IncHannah CaringalNo ratings yet
- Mongo DBDocument3 pagesMongo DBproundofyoubaoanhNo ratings yet
- How Does Mongodb Differ From Traditional Relational Databases?Document6 pagesHow Does Mongodb Differ From Traditional Relational Databases?annNo ratings yet
- Mongo DBDocument7 pagesMongo DBAMEYA ANAND JAMBHORKAR 21111408No ratings yet
- Mongodb Cheat Sheet: Click HereDocument17 pagesMongodb Cheat Sheet: Click Herearjun singhNo ratings yet
- 3.A Sample Case Study On MongoDBDocument9 pages3.A Sample Case Study On MongoDBkhanvilkarshruti6No ratings yet
- MongoDB Databases in Python With Advance IndexingDocument230 pagesMongoDB Databases in Python With Advance IndexingKaran Singh Bisht100% (1)
- Mongodb Homework 6.3 AnswerDocument5 pagesMongodb Homework 6.3 Answercfdw4djx100% (1)
- Mongo DBDocument33 pagesMongo DBVASALA AJAYKUMAR RGUKT BasarNo ratings yet
- 01 OverviewDocument49 pages01 OverviewHùng Anh NguyễnNo ratings yet
- RESERCHDocument15 pagesRESERCHAbo dahabNo ratings yet
- MongoDB LabDocument41 pagesMongoDB Lab218110141No ratings yet
- PPTDocument30 pagesPPTsaravananNo ratings yet
- 10gen-MongoDB Operations Best PracticesDocument26 pages10gen-MongoDB Operations Best PracticesRohit WaliNo ratings yet
- Document Oriented DatabaseDocument50 pagesDocument Oriented DatabaseKarthik AmarnathNo ratings yet
- Why Mongodb Is So Popular?Document3 pagesWhy Mongodb Is So Popular?prasannaNo ratings yet
- Mongodblabmanual1 240305075254 f531f8f5Document73 pagesMongodblabmanual1 240305075254 f531f8f5Hashim BilalNo ratings yet
- ChatgptDocument7 pagesChatgptannNo ratings yet
- MongoDB Architecture GuideDocument15 pagesMongoDB Architecture Guidemuthuarjunan100% (3)
- SQL TutorialDocument6 pagesSQL TutorialsubashreenataNo ratings yet
- UpdateDocument8 pagesUpdatesubashreenataNo ratings yet
- UpdateDocument8 pagesUpdatesubashreenataNo ratings yet
- User InputDocument5 pagesUser InputsubashreenataNo ratings yet
- C# Get StartedDocument9 pagesC# Get StartedsubashreenataNo ratings yet
- Sample Link Selenium Using C#Document1 pageSample Link Selenium Using C#subashreenataNo ratings yet
- Diff TetsingDocument2 pagesDiff TetsingsubashreenataNo ratings yet
- Conf JLRDocument2 pagesConf JLRsubashreenataNo ratings yet
- TrackerDocument90 pagesTrackersubashreenataNo ratings yet
- Steps To Publish An AppDocument6 pagesSteps To Publish An AppsubashreenataNo ratings yet
- ImpDocument2 pagesImpsubashreenataNo ratings yet
- Concurrent User TestDocument74 pagesConcurrent User TestsubashreenataNo ratings yet
- Agricultural ElectrificationDocument335 pagesAgricultural ElectrificationAbas S. AcmadNo ratings yet
- Terapi Seft Spiritual Emotional Freedom TechniqueDocument7 pagesTerapi Seft Spiritual Emotional Freedom TechniqueWiwik AristianiNo ratings yet
- Jurnal Literatur Review CTMDocument10 pagesJurnal Literatur Review CTMNafFadhillaNo ratings yet
- E CONNECT 12x18 Folded Instructions PRINT 011 JFDocument2 pagesE CONNECT 12x18 Folded Instructions PRINT 011 JFĐiền Huỳnh Đức TrọngNo ratings yet
- Autocad Basic Tutorial PDFDocument54 pagesAutocad Basic Tutorial PDFtheoNo ratings yet
- TextileDocument85 pagesTextileGihan Rangana100% (1)
- Science: Grade 6Document40 pagesScience: Grade 6LV BENDANA100% (1)
- List of Formula - Managerial StatisticsDocument6 pagesList of Formula - Managerial Statisticsmahendra pratap singhNo ratings yet
- How To Make A Simple DC MotorDocument1 pageHow To Make A Simple DC MotorQuen AñanaNo ratings yet
- Applying K-Nearest Neighbour in Diagnosing Heart Disease PatientDocument4 pagesApplying K-Nearest Neighbour in Diagnosing Heart Disease PatientHeshan RodrigoNo ratings yet
- Adenosine Triphosphate - WikipediaDocument65 pagesAdenosine Triphosphate - WikipediaBashiir NuurNo ratings yet
- Festo PLC Delta A. Hmi Factory Settings: Appendix B Communication - Scredit Software User ManualDocument2 pagesFesto PLC Delta A. Hmi Factory Settings: Appendix B Communication - Scredit Software User ManualryoNo ratings yet
- Comunications FundamentalsDocument271 pagesComunications FundamentalsDiego100% (1)
- Taller Fisicoquimica TermoDocument6 pagesTaller Fisicoquimica TermoWilo JaraNo ratings yet
- A7.5 Blood VesselsDocument5 pagesA7.5 Blood VesselsshannonNo ratings yet
- Session 7: Forecasting - IiiDocument14 pagesSession 7: Forecasting - IiiHeena AroraNo ratings yet
- Report - Welding and Types of WeldingDocument13 pagesReport - Welding and Types of WeldingИгорь ПетраковNo ratings yet
- Installation and Operating Manual: 6 - 10 kVA UPSDocument46 pagesInstallation and Operating Manual: 6 - 10 kVA UPSPE TruNo ratings yet
- Oran 2Document263 pagesOran 2KerimberdiNo ratings yet
- Measurement, Instrumentation and Control ME2400 Assignment 2Document13 pagesMeasurement, Instrumentation and Control ME2400 Assignment 2Chinmay TambatNo ratings yet
- 3 Ways To Uninstall Ubuntu Software - WikihowDocument6 pages3 Ways To Uninstall Ubuntu Software - Wikihowjppn33No ratings yet
- Latex Punctuation Cheet SheetDocument1 pageLatex Punctuation Cheet Sheethenrysting4366No ratings yet
- PDF Probability Theory and Examples Fifth Edition Durrett Ebook Full ChapterDocument53 pagesPDF Probability Theory and Examples Fifth Edition Durrett Ebook Full Chaptersusie.harris472100% (1)
- Chapter 1Document19 pagesChapter 1Kyrie IrvingNo ratings yet
- Quiz 002 - Attempt Review4 PDFDocument3 pagesQuiz 002 - Attempt Review4 PDFkatherine anne ortizNo ratings yet
- Thiết kế phần cứng xử lý giải thuật mãDocument6 pagesThiết kế phần cứng xử lý giải thuật mãThi PhamNo ratings yet
- Determinacion Por DerivatizaciónDocument6 pagesDeterminacion Por DerivatizaciónJuan SNo ratings yet
- Avogadro's Number and The Mole ConceptDocument24 pagesAvogadro's Number and The Mole ConceptMary Rose JasminNo ratings yet
- GEBCO 2023 Grid DocumentationDocument8 pagesGEBCO 2023 Grid Documentationym YMNo ratings yet