Download as pdf or txt
You might also like
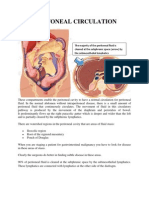
- Peritoneal CirculationDocument2 pagesPeritoneal CirculationM Rizal Isburhan0% (1)
- 1.017/1.010 Class 19 Analysis of Variance: Concepts and DefinitionsDocument5 pages1.017/1.010 Class 19 Analysis of Variance: Concepts and DefinitionsDr. Ir. R. Didin Kusdian, MT.No ratings yet
- Ghitany, Karlis, Mutairi, Dan Al-Awadhi (2012) - EM AlgorithmDocument14 pagesGhitany, Karlis, Mutairi, Dan Al-Awadhi (2012) - EM AlgorithmyusriantihanikeNo ratings yet
- Lec11 Introduction2BayesianStatisticsDocument48 pagesLec11 Introduction2BayesianStatisticshu jackNo ratings yet
- Examples Comparing Importance Sampling and The MetDocument26 pagesExamples Comparing Importance Sampling and The MetRafalel JupioNo ratings yet
- The Logic of ANOVADocument4 pagesThe Logic of ANOVAAlp Eren AKYUZNo ratings yet
- Week 9 Lecture NotesDocument7 pagesWeek 9 Lecture NotesIlhan YunusNo ratings yet
- Chap 2Document9 pagesChap 2MingdreamerNo ratings yet
- Parameter Estimation of Switching SystemsDocument11 pagesParameter Estimation of Switching SystemsJosé RagotNo ratings yet
- Aos 2067Document23 pagesAos 2067Karen PessoaNo ratings yet
- On Moments of Sample Mean and VarianceDocument21 pagesOn Moments of Sample Mean and VarianceSandra Montes FaustorNo ratings yet
- Fuzzy Algo UpdatedDocument8 pagesFuzzy Algo Updatednirmala periasamyNo ratings yet
- STA 303 Lec 1Document5 pagesSTA 303 Lec 1kuriajames147No ratings yet
- Structural Element Stiffness Matrices and Mass Matrices: 1 PreliminariesDocument28 pagesStructural Element Stiffness Matrices and Mass Matrices: 1 PreliminariesZahid RahmanNo ratings yet
- Chap2 Multivariate Normal and Related DistributionsDocument18 pagesChap2 Multivariate Normal and Related DistributionschanpeinNo ratings yet
- ANOVA With Summary Statistics A STATA MaDocument6 pagesANOVA With Summary Statistics A STATA MaRock Hall Primary SchoolNo ratings yet
- Chapter 7Document30 pagesChapter 7Umer SharazNo ratings yet
- HASTS215 - HSTS215 NOTES Chapter3Document7 pagesHASTS215 - HSTS215 NOTES Chapter3Carl UsheNo ratings yet
- Assignment 1 - SolutionDocument9 pagesAssignment 1 - SolutionscribdllNo ratings yet
- Alternating Direction Implicit Osc Scheme For The Two-Dimensional Fractional Evolution Equation With A Weakly Singular KernelDocument23 pagesAlternating Direction Implicit Osc Scheme For The Two-Dimensional Fractional Evolution Equation With A Weakly Singular KernelNo FaceNo ratings yet
- Journal of Statistical SoftwareDocument14 pagesJournal of Statistical SoftwaresoniaNo ratings yet
- DeLeon Etal ChileJStat2013Document17 pagesDeLeon Etal ChileJStat2013sam.gotcha2018No ratings yet
- An Application of The Minkowski Inequality: International Journal of Pure and Applied Mathematics January 2004Document4 pagesAn Application of The Minkowski Inequality: International Journal of Pure and Applied Mathematics January 2004Alfira Amalia AmaliaNo ratings yet
- Multivariate NormalDocument4 pagesMultivariate NormalKumar PriyanshuNo ratings yet
- Ben-Hamou Et Al - Concentration Inequalities in The Infinite UrnDocument39 pagesBen-Hamou Et Al - Concentration Inequalities in The Infinite UrnJoey CarterNo ratings yet
- 5 BSM214 Lecture5 Fall2023Document25 pages5 BSM214 Lecture5 Fall2023mf7059708No ratings yet
- Anomaly DetectionDocument7 pagesAnomaly DetectionRutvikNo ratings yet
- Multiple Regression Analyisis ClearDocument27 pagesMultiple Regression Analyisis ClearArbi ChaimaNo ratings yet
- Variance EstimationDocument2 pagesVariance EstimationMalkin DivyaNo ratings yet
- EC221 Principles of Econometrics Solutions PSDocument6 pagesEC221 Principles of Econometrics Solutions PSslyk1993No ratings yet
- Oneway 01Document1 pageOneway 01Agung No LimitNo ratings yet
- 1 Preliminaries: 1.1 MotivationDocument7 pages1 Preliminaries: 1.1 Motivationecd4282003No ratings yet
- 8170 FNLDocument13 pages8170 FNLfillali23No ratings yet
- One-Way ANOVADocument18 pagesOne-Way ANOVATADIWANASHE TINONETSANANo ratings yet
- Gram Charlier and Edgeworth Expansion For Sample VarianceDocument14 pagesGram Charlier and Edgeworth Expansion For Sample VarianceEric BenhamouNo ratings yet
- EXAM1 Practise MTH2222Document4 pagesEXAM1 Practise MTH2222rachelstirlingNo ratings yet
- Multivariate AnalysisDocument25 pagesMultivariate AnalysisPaul EthamNo ratings yet
- Sampling DistributionsDocument9 pagesSampling DistributionsjayNo ratings yet
- Applied Mathematics and Computation: Alper Korkmaz, Idris Da GDocument12 pagesApplied Mathematics and Computation: Alper Korkmaz, Idris Da GLaila FouadNo ratings yet
- Lar Math So15 MLDocument11 pagesLar Math So15 MLbenjamin AidooNo ratings yet
- 3 The Rao-Blackwell Theorem: 3.1 Mean Squared ErrorDocument2 pages3 The Rao-Blackwell Theorem: 3.1 Mean Squared ErrorBakari HamisiNo ratings yet
- Large-Time Asymptotics For Solutions of A Generalized Burgers Equation With Variable ViscosityDocument23 pagesLarge-Time Asymptotics For Solutions of A Generalized Burgers Equation With Variable ViscositychandruNo ratings yet
- (Springer Texts in Statistics) Jonathan D. Cryer, Kung-Sik Chan - Time Series Analysis - With Applications in R-Springer (2008) - 40-63Document24 pages(Springer Texts in Statistics) Jonathan D. Cryer, Kung-Sik Chan - Time Series Analysis - With Applications in R-Springer (2008) - 40-63MICHAEL MEDINA FLORESNo ratings yet
- Properties of Self Similar Solutions of Reaction-Diffusion Systems of Quasilinear EquationsDocument12 pagesProperties of Self Similar Solutions of Reaction-Diffusion Systems of Quasilinear EquationsTJPRC PublicationsNo ratings yet
- Chapter 7 - Sum of Independent Random - 2016 - Introduction To Statistical MachiDocument8 pagesChapter 7 - Sum of Independent Random - 2016 - Introduction To Statistical MachiRobinsonNo ratings yet
- 5 Discrete Processing of Analog SignalsDocument21 pages5 Discrete Processing of Analog SignalsCHARLES MATHEWNo ratings yet
- Mixed Correlation Functions of The Two-Matrix Model: M. Bertola B. EynardDocument18 pagesMixed Correlation Functions of The Two-Matrix Model: M. Bertola B. EynardSîImoHäāķīīmNo ratings yet
- STAT2372 Topic5 2020Document27 pagesSTAT2372 Topic5 2020Simthande SokeNo ratings yet
- Logarithmic Mean For Several Arguments:, X 0, X 0 Is Defined by L (X, X X /X, XDocument12 pagesLogarithmic Mean For Several Arguments:, X 0, X 0 Is Defined by L (X, X X /X, XΓιάννης ΣτεργίουNo ratings yet
- Department of Mathematics and Statistics, University of Maine, Orono, ME 04469-5752, U.S.ADocument20 pagesDepartment of Mathematics and Statistics, University of Maine, Orono, ME 04469-5752, U.S.AENOCK NIGHTWALKERNo ratings yet
- Econometric Toolkit For Studying Dynamic Models in Economics and FinanceDocument39 pagesEconometric Toolkit For Studying Dynamic Models in Economics and FinancerrrrrrrrNo ratings yet
- 18 The Exponential Family and Statistical ApplicationsDocument24 pages18 The Exponential Family and Statistical ApplicationsHira NaeemNo ratings yet
- Almost Unbiased Exponential Estimator For The Finite Population MeanDocument14 pagesAlmost Unbiased Exponential Estimator For The Finite Population MeanScience DirectNo ratings yet
- Chapter 9 Sample Estimation Problems: Classical Methods of Estimation Point EstimationDocument8 pagesChapter 9 Sample Estimation Problems: Classical Methods of Estimation Point EstimationSantos PavaNo ratings yet
- Statistical Inference: Dr. Venkataramana BDocument38 pagesStatistical Inference: Dr. Venkataramana BSRIDHAR RAMESHNo ratings yet
- PBM NotesDocument130 pagesPBM NotesSurya IyerNo ratings yet
- Chapter 3 BDocument10 pagesChapter 3 BemilyNo ratings yet
- Stats Formulas &tablesDocument21 pagesStats Formulas &tablesChandra ReddyNo ratings yet
- احصاء د.رياض بابل (1) 1Document128 pagesاحصاء د.رياض بابل (1) 1brhmNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- P2NP To Amine With NaBH4-CopperDocument281 pagesP2NP To Amine With NaBH4-CopperIo TatNo ratings yet
- OB Case Study-1Document4 pagesOB Case Study-1melat bizu0% (1)
- Xtensa Lx7 Data BookDocument755 pagesXtensa Lx7 Data Booklucian.ungureanNo ratings yet
- 6 Rock-CycleDocument13 pages6 Rock-CycleSakshi BhalewadikarNo ratings yet
- Financial Performance Analysis of Nepal Doorsanchar Comapany LimitedDocument23 pagesFinancial Performance Analysis of Nepal Doorsanchar Comapany LimitedLarisha PandeyNo ratings yet
- Dark Sun Grand Compendium - Volume 3 - Society PDFDocument288 pagesDark Sun Grand Compendium - Volume 3 - Society PDFKenny LindenNo ratings yet
- Historia The FelidsDocument5 pagesHistoria The Felidsbalim01100% (1)
- Earth & Life Science Day 1Document8 pagesEarth & Life Science Day 1Maria Theresa Deluna Macairan100% (1)
- MIUX529C: Military SpecificationDocument17 pagesMIUX529C: Military SpecificationJhan Carlos RamosNo ratings yet
- 2012 Paper 21Document12 pages2012 Paper 21rajdeepghai5607No ratings yet
- Marketing Moguls Gartons IIM Kashipur FinalsDocument22 pagesMarketing Moguls Gartons IIM Kashipur FinalsTarun SinghNo ratings yet
- Mathematics 8-Marigold/ Sampaguita MULTIPLE CHOCE: Choose The Letter of The Correct Answer and Write It On The SpaceDocument4 pagesMathematics 8-Marigold/ Sampaguita MULTIPLE CHOCE: Choose The Letter of The Correct Answer and Write It On The SpaceIvy Jane MalacastaNo ratings yet
- Cheeke 1971 CJAS Saponin-RevDocument14 pagesCheeke 1971 CJAS Saponin-RevRinaERpienaNo ratings yet
- GTB Jeremiah DownloadDocument87 pagesGTB Jeremiah DownloadEdwin PitangaNo ratings yet
- Miley Ped - RadiologyDocument52 pagesMiley Ped - RadiologyLukasNo ratings yet
- Fossil Fuels Oil and GasDocument12 pagesFossil Fuels Oil and GasCrystian Kobee EmpeynadoNo ratings yet
- TCS 3050 50 1019 2Document17 pagesTCS 3050 50 1019 2Samari LarryNo ratings yet
- Letter of Reference Angela Mathew 1Document3 pagesLetter of Reference Angela Mathew 1api-490106269No ratings yet
- Chocolate Chip Banana BreadDocument8 pagesChocolate Chip Banana BreadouruleNo ratings yet
- AP Bio Cram Chart 2021Document1 pageAP Bio Cram Chart 2021Evangeline YaoNo ratings yet
- Deepfake Is The Future of Content Creation'Document9 pagesDeepfake Is The Future of Content Creation'I IvaNo ratings yet
- Unnat - Bharat - Abhiyan TPPDocument9 pagesUnnat - Bharat - Abhiyan TPPashishmodak2222No ratings yet
- People v. RiveraDocument36 pagesPeople v. RiveraAemel de LeonNo ratings yet
- Biopolitics and The Spectacle in Classic Hollywood CinemaDocument19 pagesBiopolitics and The Spectacle in Classic Hollywood CinemaAnastasiia SoloveiNo ratings yet
- Nursing Science and Profession: As An ArtDocument45 pagesNursing Science and Profession: As An ArtHans TrishaNo ratings yet
- Sep 15 Final Cpsa LetterDocument19 pagesSep 15 Final Cpsa LetterFatima Berriah CamposNo ratings yet
- Right and Wrong in Writing Test Cases.v4 PublicDocument64 pagesRight and Wrong in Writing Test Cases.v4 PublicAnil KanchiNo ratings yet
- ICT in Teaching LearningDocument3 pagesICT in Teaching LearningElizalde PiolNo ratings yet
- Tickler Final PDFDocument29 pagesTickler Final PDFSerious LeoNo ratings yet