Download as pdf or txt
You might also like
- E20-393 Exam QuestionsDocument110 pagesE20-393 Exam QuestionssumirsainiNo ratings yet
- Apriori Principle Example Question and AnswerDocument11 pagesApriori Principle Example Question and AnswerUdara Seneviratne100% (11)
- Lecture 8-9 Association Rule MiningDocument21 pagesLecture 8-9 Association Rule MiningMuhammad UsmanNo ratings yet
- Module 5 - Frequent Pattern MiningDocument111 pagesModule 5 - Frequent Pattern MiningakaNo ratings yet
- CISA EXAM-Testing Concept-Knowledge of Compliance & Substantive Testing AspectsFrom EverandCISA EXAM-Testing Concept-Knowledge of Compliance & Substantive Testing AspectsRating: 3 out of 5 stars3/5 (4)
- DWDM Unit 3Document54 pagesDWDM Unit 3VvnaikcseVvnaikcseNo ratings yet
- DMDW Chapter 4Document29 pagesDMDW Chapter 4Samuel GeseseNo ratings yet
- Association Rule Mining: - Algorithms For Frequent Itemset Mining - Apriori - Elcat - FP-GrowthDocument45 pagesAssociation Rule Mining: - Algorithms For Frequent Itemset Mining - Apriori - Elcat - FP-Growthakshayhazari8281No ratings yet
- Part 2 Data MiningDocument78 pagesPart 2 Data MiningAditi Anand ShetkarNo ratings yet
- DMDW Chapter 4Document28 pagesDMDW Chapter 4DESSIE FIKIRNo ratings yet
- Association Rule Mining: Iyad BatalDocument37 pagesAssociation Rule Mining: Iyad BatalrajeswarikannanNo ratings yet
- Chap6 Basic Association Analysis-2016Document32 pagesChap6 Basic Association Analysis-2016Riskaa PriciliaNo ratings yet
- Association Analysis 1Document55 pagesAssociation Analysis 1Prateek BalchandaniNo ratings yet
- L5 - Association Rule MiningDocument17 pagesL5 - Association Rule MiningVeena TellaNo ratings yet
- DM Unit-IIDocument80 pagesDM Unit-IILaxmiNo ratings yet
- BIS 541 Ch05 20-21 SDocument91 pagesBIS 541 Ch05 20-21 SOmer TunogluNo ratings yet
- Data Mining-Knowledge Presentation 2: Prof. Sin-Min LeeDocument54 pagesData Mining-Knowledge Presentation 2: Prof. Sin-Min LeedilluNo ratings yet
- Data Mining Association RulesDocument54 pagesData Mining Association RulessuyashNo ratings yet
- CIS664-Knowledge Discovery and Data MiningDocument74 pagesCIS664-Knowledge Discovery and Data MininggNo ratings yet
- Apriori AlgorithmDocument23 pagesApriori AlgorithmArun MozhiNo ratings yet
- L6-7 - AprioriDocument22 pagesL6-7 - AprioriVeena TellaNo ratings yet
- CH - 5Document43 pagesCH - 5PIYUSH MANGILAL SONINo ratings yet
- Lecture Notes For Chapter 6: by Tan, Steinbach, KumarDocument65 pagesLecture Notes For Chapter 6: by Tan, Steinbach, KumarShweta SharmaNo ratings yet
- ATC - Lecture - Notes - Data Mining Techniques - 2021Document77 pagesATC - Lecture - Notes - Data Mining Techniques - 2021evarist madahaNo ratings yet
- From Introduction To Data Mining: Data Mining Association Analysis: Basic Concepts and AlgorithmsDocument37 pagesFrom Introduction To Data Mining: Data Mining Association Analysis: Basic Concepts and AlgorithmspriyaNo ratings yet
- AssociationDocument29 pagesAssociationAnonymous 1pDnp6XZNo ratings yet
- 11 Association Rules Mining NewDocument32 pages11 Association Rules Mining NewNilakhya ChawrokNo ratings yet
- Association Rule, Data Warehousing and Data MiningDocument81 pagesAssociation Rule, Data Warehousing and Data MiningRahul ChowdaryNo ratings yet
- Associationrule 1Document30 pagesAssociationrule 1bidafo2019No ratings yet
- CH 03 Frequent Pattern Mining 2021Document62 pagesCH 03 Frequent Pattern Mining 2021PRIYA RATHORENo ratings yet
- Association Analysis ModifiedDocument66 pagesAssociation Analysis ModifiedVijeth PoojaryNo ratings yet
- Unit 2Document14 pagesUnit 2Vasudevarao PeyyetiNo ratings yet
- Association Rule Mining ExampleDocument12 pagesAssociation Rule Mining ExamplesanjeewascribdNo ratings yet
- Association Rule Mining - Part IDocument21 pagesAssociation Rule Mining - Part IAlexCooksNo ratings yet
- Rule MiningDocument20 pagesRule MiningNeeta PatilNo ratings yet
- Mining Association Rules in Large DatabasesDocument40 pagesMining Association Rules in Large Databasessigma70egNo ratings yet
- Frequent Pattern Based Clustering MethodsDocument23 pagesFrequent Pattern Based Clustering Methodstanya.sharmaNo ratings yet
- Data Analytics Unit 4Document22 pagesData Analytics Unit 4Aditi JaiswalNo ratings yet
- DM Unit - 2Document14 pagesDM Unit - 2uzair farooqNo ratings yet
- AssocDocument166 pagesAssocTaj SapraNo ratings yet
- Bab 05 - Association MiningDocument58 pagesBab 05 - Association MiningMochammad Adji FirmansyahNo ratings yet
- Lecture Notes For Chapter 5 Dan 6: Data Mining Analisis Asosiasi: Konsep Dasar Dan AlgoritmaDocument28 pagesLecture Notes For Chapter 5 Dan 6: Data Mining Analisis Asosiasi: Konsep Dasar Dan AlgoritmaFierhan HasirNo ratings yet
- DM Lect7Document26 pagesDM Lect7هارون المقطريNo ratings yet
- Data Cube Computation and Data GenerationDocument54 pagesData Cube Computation and Data GenerationYiu Keung LiNo ratings yet
- 3-Associations and Corelations MTech-2016Document157 pages3-Associations and Corelations MTech-2016divyaNo ratings yet
- BusAn - Review - Lecture 5 Association RulesDocument22 pagesBusAn - Review - Lecture 5 Association RulesMecheal ThomasNo ratings yet
- Blatt03 SolDocument16 pagesBlatt03 SolWafa'a AbdoIslamNo ratings yet
- Data Mining: Concepts and Techniques: - Slides For Textbook - Chapter 6Document82 pagesData Mining: Concepts and Techniques: - Slides For Textbook - Chapter 6Harjas BakshiNo ratings yet
- Chapter 3Document27 pagesChapter 3Bikila SeketaNo ratings yet
- CIS664-Knowledge Discovery and Data MiningDocument74 pagesCIS664-Knowledge Discovery and Data MiningrbvgreNo ratings yet
- Association Rules PDFDocument35 pagesAssociation Rules PDFRenphilIanGapasBalantinNo ratings yet
- FP GrowthDocument21 pagesFP GrowthRa AbhishekNo ratings yet
- Unit 2 Question and Answers BdhdnsDocument15 pagesUnit 2 Question and Answers Bdhdnstagullajayanth72No ratings yet
- Concepts and Techniques: Data MiningDocument99 pagesConcepts and Techniques: Data MiningbhargaviNo ratings yet
- 9 - Association RulesDocument44 pages9 - Association RulesPutri AnisaNo ratings yet
- Business Plan IDocument56 pagesBusiness Plan ImehulNo ratings yet
- Data Mining: AssociationDocument41 pagesData Mining: AssociationParveen SwamiNo ratings yet
- Note 1455181909Document30 pagesNote 1455181909Ayman AymanNo ratings yet
- Concepts and Techniques: Data MiningDocument27 pagesConcepts and Techniques: Data MiningJarir AhmedNo ratings yet
- Association RulesDocument48 pagesAssociation RulesDev kartik AgarwalNo ratings yet
- Designing and Conducting Survey Research: A Comprehensive GuideFrom EverandDesigning and Conducting Survey Research: A Comprehensive GuideRating: 2 out of 5 stars2/5 (2)
- Unit IiiDocument73 pagesUnit IiiShashwat MishraNo ratings yet
- Discrete Maths Unit 5Document24 pagesDiscrete Maths Unit 5Shashwat MishraNo ratings yet
- Unit 5Document70 pagesUnit 5Shashwat MishraNo ratings yet
- Discrete Maths Unit 4 - 2Document28 pagesDiscrete Maths Unit 4 - 2Shashwat MishraNo ratings yet
- Ism 5Document40 pagesIsm 5Shashwat MishraNo ratings yet
- Ism 4Document63 pagesIsm 4Shashwat MishraNo ratings yet
- Discrete Maths Unit 1Document48 pagesDiscrete Maths Unit 1Shashwat MishraNo ratings yet
- 883x0b1 PDFDocument105 pages883x0b1 PDFAndreeNo ratings yet
- Change Log - Real Home - WP ThemesDocument30 pagesChange Log - Real Home - WP Themesakun bohonganNo ratings yet
- Net Neutrality Company Sign On LetterDocument3 pagesNet Neutrality Company Sign On LetterSam Gustin100% (2)
- Ravi S ChowdhuryDocument4 pagesRavi S ChowdhuryRavi Shankar ChowdhuryNo ratings yet
- Tle - Ict - CSS: Quarter 4 - Module 5-8: Install Network CablesDocument12 pagesTle - Ict - CSS: Quarter 4 - Module 5-8: Install Network CablesNhan RaquionNo ratings yet
- Ahmed Gomaa 2023Document6 pagesAhmed Gomaa 2023Ahmed GomaaNo ratings yet
- Autorun InfoDocument3 pagesAutorun InfoChaithanya BharadwajNo ratings yet
- Unit 3Document8 pagesUnit 3D Babu KosmicNo ratings yet
- Model 1200SE Series Dry Block Temperature Calibrators: Product DescriptionDocument4 pagesModel 1200SE Series Dry Block Temperature Calibrators: Product DescriptionMarco riveraNo ratings yet
- 2D Barcode Break DownDocument10 pages2D Barcode Break DownJorge Alberto Barrera AndrianoNo ratings yet
- Assignment Os: Saqib Javed 11912Document8 pagesAssignment Os: Saqib Javed 11912Saqib JavedNo ratings yet
- Avaya IP Office ContactCenter BrochureDocument87 pagesAvaya IP Office ContactCenter BrochureVicky NicNo ratings yet
- Sum of A Number Using SwingDocument8 pagesSum of A Number Using Swingrakhitha1083No ratings yet
- Week 4 - Networking ServicesDocument2 pagesWeek 4 - Networking ServicesJamesNo ratings yet
- Help Me Tuning This Wait Event - Log File SyncDocument12 pagesHelp Me Tuning This Wait Event - Log File SyncOsmanNo ratings yet
- Machine Learning Assignment 2Document1 pageMachine Learning Assignment 2Noah ByrneNo ratings yet
- Infinova V1421MN-Exproof HD Fixed Zoom Camera PDFDocument3 pagesInfinova V1421MN-Exproof HD Fixed Zoom Camera PDFnameshNo ratings yet
- Mos Excel 2016 Core Practice Exam 2Document8 pagesMos Excel 2016 Core Practice Exam 2Cẩm Tiên NguyễnNo ratings yet
- Big Data Analytics in Oil and Gas Industry - An Emerging TrendDocument8 pagesBig Data Analytics in Oil and Gas Industry - An Emerging Trendluli_kbrera100% (1)
- Kyocera TASKalfa 2554ci BrochureDocument9 pagesKyocera TASKalfa 2554ci BrochureULTIMA SERVICESNo ratings yet
- NetBackup AdminGuide OpsCenterDocument790 pagesNetBackup AdminGuide OpsCenterJuan AlanisNo ratings yet
- Cheryl Anderson CVDocument2 pagesCheryl Anderson CVapi-527318422No ratings yet
- PHP & Mysql: It84 - It Elective 1 (PHP Programming)Document17 pagesPHP & Mysql: It84 - It Elective 1 (PHP Programming)WearIt Co.No ratings yet
- Part 1 Programming Languages C, C++, PythonDocument31 pagesPart 1 Programming Languages C, C++, PythonRamya NarayananNo ratings yet
- Freeradius For Windows: Server EditionDocument13 pagesFreeradius For Windows: Server EditionHaris SpringNo ratings yet
- C Make ListsDocument8 pagesC Make ListsdaveyNo ratings yet
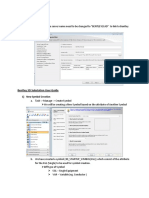
- SQL Installation: 1) New Symbol CreationDocument23 pagesSQL Installation: 1) New Symbol CreationKullu23No ratings yet
- Advanced Civil SoftwareDocument16 pagesAdvanced Civil SoftwaresithuNo ratings yet
- User's Manual User's ManualDocument52 pagesUser's Manual User's ManualalfalvaNo ratings yet