
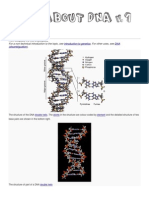
Structure of Nucleic Acids
Structure of Nucleic Acids
You might also like
- Nucleic Acid ProjectDocument18 pagesNucleic Acid ProjectPramod Etarvi90% (10)
- DNA Rep and RNA StructureDocument30 pagesDNA Rep and RNA Structurekoromamoses235No ratings yet
- DNA in Cells: Molecular BiologyDocument10 pagesDNA in Cells: Molecular BiologyDe Los Santos AinjelNo ratings yet
- 6nucleic Acids - Boundless BiologyDocument15 pages6nucleic Acids - Boundless BiologyAmy SuarezNo ratings yet
- Nucleic Acids Store, Transmit and Help Express Hereditary InformationDocument6 pagesNucleic Acids Store, Transmit and Help Express Hereditary InformationDanielle GuerraNo ratings yet
- Nucleic Acid: 1. Nitrogenous BasesDocument3 pagesNucleic Acid: 1. Nitrogenous BasesMarie WrightNo ratings yet
- Research in Lecture "All About Nucleic Acid": Bicol University College of Nursing Legazpi City 2015-2016Document27 pagesResearch in Lecture "All About Nucleic Acid": Bicol University College of Nursing Legazpi City 2015-2016Kim GoNo ratings yet
- CHBH13 - Laboratory Manual 5Document11 pagesCHBH13 - Laboratory Manual 5Ysa DienteNo ratings yet
- Nucleic Acids - Structure and Function 2013Document51 pagesNucleic Acids - Structure and Function 2013ender arslanNo ratings yet
- Assignment No. 2Document2 pagesAssignment No. 2Jane Valine BalinoNo ratings yet
- 02-Nucleic Acids - Structure and FunctionDocument70 pages02-Nucleic Acids - Structure and FunctionBerru VardarNo ratings yet
- Nucleic Acid MetabolismDocument41 pagesNucleic Acid MetabolismPavani AkkalaNo ratings yet
- Nucleic Acids.Document7 pagesNucleic Acids.Mujthaba AdmaniNo ratings yet
- Written: in Biology Group 1Document5 pagesWritten: in Biology Group 1Joel EvangelistaNo ratings yet
- Lecture Nucleic AcidsDocument4 pagesLecture Nucleic Acidsj9694052No ratings yet
- BIO 001 5th LectureDocument24 pagesBIO 001 5th LectureBenjaminNo ratings yet
- Karthikeya XII-A Chemistry Project PDFDocument45 pagesKarthikeya XII-A Chemistry Project PDFkarthikeya kakarlapudiNo ratings yet
- Nucleic AcidsDocument4 pagesNucleic AcidsAshley Margareth BonifacioNo ratings yet
- Dna & RnaDocument11 pagesDna & Rnabelal.hassan3No ratings yet
- Basic Principles: Organisms Are Made of CellsDocument10 pagesBasic Principles: Organisms Are Made of CellsEllu SeethaNo ratings yet
- Structure and Function of Nucleic AcidDocument33 pagesStructure and Function of Nucleic AcidLaiba FarooqNo ratings yet
- Chromosomes, Genes and Nucleic AcidsDocument23 pagesChromosomes, Genes and Nucleic AcidsDANIELLA LOMA CAPONPONNo ratings yet
- Structure of Nucleic AcidsDocument3 pagesStructure of Nucleic AcidsHanz Glitzer MosquedaNo ratings yet
- 3.5. Nucleic Acids 22-23Document3 pages3.5. Nucleic Acids 22-23SiNo ratings yet
- 471 - BCH 201-Lecture Note On WebDocument10 pages471 - BCH 201-Lecture Note On WebShaikh SalmanNo ratings yet
- Chemistry of The Cell: Dr. Ayhan R. MahmoodDocument17 pagesChemistry of The Cell: Dr. Ayhan R. MahmoodSane IvNo ratings yet
- Nucleic Acids Rna World Biotech ProjectDocument18 pagesNucleic Acids Rna World Biotech ProjectSakshi SinghNo ratings yet
- HDTD-B-9 - Molecular Genetics IDocument25 pagesHDTD-B-9 - Molecular Genetics IMariam QaisNo ratings yet
- Structure and Function of Dna and Rna: Jon Paul M. Reyes, RMT, MBA, MSMLS Program Chair College of Medical TechnologyDocument21 pagesStructure and Function of Dna and Rna: Jon Paul M. Reyes, RMT, MBA, MSMLS Program Chair College of Medical TechnologyRich Darlene Dela CruzNo ratings yet
- Structure and Function of DNADocument27 pagesStructure and Function of DNAHaniya RijaNo ratings yet
- BiomoleculesDocument7 pagesBiomoleculesrajan.11proNo ratings yet
- Paper - IV Molecular BiologyDocument236 pagesPaper - IV Molecular BiologyNaruto UzumakiNo ratings yet
- BIOLOGY Chapter 4 - DNA, RNA and Protein SynthesisDocument6 pagesBIOLOGY Chapter 4 - DNA, RNA and Protein Synthesischelsea AlexandriaNo ratings yet
- Nucleic Acids and NucleotidesDocument4 pagesNucleic Acids and NucleotidesWolverineInZenNo ratings yet
- Nucleic AcidDocument3 pagesNucleic AcidSamraNo ratings yet
- Nucleic AcidsDocument42 pagesNucleic AcidsJulianne AnikaNo ratings yet
- Dna Dna DnaDocument67 pagesDna Dna DnaAlyasin FrougaNo ratings yet
- Differences Between DNA and RNADocument6 pagesDifferences Between DNA and RNAGevo GegantoNo ratings yet
- Chap. 8A Nucleotides and Nucleic Acids: - Some Basics - Nucleic Acid StructureDocument30 pagesChap. 8A Nucleotides and Nucleic Acids: - Some Basics - Nucleic Acid StructureAbrar Mohi-ud-DinNo ratings yet
- Genetic MaterialDocument31 pagesGenetic MaterialANBC- 24- Safa AfreenNo ratings yet
- MDocument9 pagesMNafeesa KousarNo ratings yet
- Dna 1Document31 pagesDna 1Dr-Dalya ShakirNo ratings yet
- Nucleic Acid and Protein Synthesis 2017-18Document18 pagesNucleic Acid and Protein Synthesis 2017-18ADEEL AHMADNo ratings yet
- Chemistry of Nucleic Acids..slideDocument19 pagesChemistry of Nucleic Acids..slideezebelluciNo ratings yet
- Linkages Form The Sugar-Phosphate Backbone of Both DNA and RNADocument3 pagesLinkages Form The Sugar-Phosphate Backbone of Both DNA and RNAed modoNo ratings yet
- Linkages Form The Sugar-Phosphate Backbone of Both DNA and RNADocument3 pagesLinkages Form The Sugar-Phosphate Backbone of Both DNA and RNAed modoNo ratings yet
- 1 The Central Dogma of Molecular BiologyDocument6 pages1 The Central Dogma of Molecular Biologydeladestianiaji2490100% (1)
- Nucleic Acid: Suzette B. DoctoleroDocument67 pagesNucleic Acid: Suzette B. DoctoleroPojangNo ratings yet
- 1 Nucleic AcidsDocument11 pages1 Nucleic AcidsSafiya JamesNo ratings yet
- Types of Nucleic AcidsDocument7 pagesTypes of Nucleic AcidsJomari Alipante100% (1)
- Nucleic AcidsDocument32 pagesNucleic AcidsAlexander DacumosNo ratings yet
- Structure and Function of DNADocument29 pagesStructure and Function of DNAMatthew Justin Villanueva GozoNo ratings yet
- Nucleic Acids RevisionDocument15 pagesNucleic Acids RevisionGilbert ossullivanNo ratings yet
- Basics of Molecular BiologyDocument10 pagesBasics of Molecular BiologyOday MadiNo ratings yet
- Nucleic-AcidDocument28 pagesNucleic-AcidIvan Jhon AnamNo ratings yet
- All About DnaDocument65 pagesAll About DnaPeopwdNo ratings yet
- 1.5 Nucleic AcidsDocument23 pages1.5 Nucleic AcidsMûhd AïZām ÄhmâdNo ratings yet
- Nucleotides and Nucleic Acids: Nucleotides Are Phosphorylated Nucleosides. A Nucleoside Is ADocument4 pagesNucleotides and Nucleic Acids: Nucleotides Are Phosphorylated Nucleosides. A Nucleoside Is AJuan sebastianNo ratings yet
- BCH 305 (Chemistry & Metabolism of Nucleic Acids)Document30 pagesBCH 305 (Chemistry & Metabolism of Nucleic Acids)ihebunnaogochukwu24No ratings yet
- Anatomy and Physiology for Students: A College Level Study Guide for Life Science and Allied Health MajorsFrom EverandAnatomy and Physiology for Students: A College Level Study Guide for Life Science and Allied Health MajorsNo ratings yet
- Exploring Ensembl: Exercise 1 - PandaDocument4 pagesExploring Ensembl: Exercise 1 - Pandaquique ddmNo ratings yet
- Variant ClassificationDocument5 pagesVariant ClassificationPeter OlejuaNo ratings yet
- MSC Ag GPBDocument26 pagesMSC Ag GPBnnazmul8052No ratings yet
- Scientists Prove DNA Can Be Reprogrammed by Our Own WordsDocument15 pagesScientists Prove DNA Can Be Reprogrammed by Our Own WordsqwertyjinNo ratings yet
- Paraphrasing Techniques-1Document21 pagesParaphrasing Techniques-1James CostelloeNo ratings yet
- M.Sc.-Microbiology Syllabus HNBDocument58 pagesM.Sc.-Microbiology Syllabus HNBBiology Made EasyNo ratings yet
- Lab 3 Evolutionary ProcessDocument3 pagesLab 3 Evolutionary ProcessRizkyDirectioners'ZaynsterNo ratings yet
- Syllabus 2022-2023 Class: XII Biology (Code No. 044) Course Structure Total Times: 3 Hrs Total Marks: 70Document5 pagesSyllabus 2022-2023 Class: XII Biology (Code No. 044) Course Structure Total Times: 3 Hrs Total Marks: 70Debalina NagNo ratings yet
- Biology Science For Life 4th Edition Belk Test BankDocument38 pagesBiology Science For Life 4th Edition Belk Test Bankapodaawlwortn3ae100% (14)
- Oligo Analyzer SEC PRIMER 2Document1 pageOligo Analyzer SEC PRIMER 2divillamarinNo ratings yet
- Term Exam: NEET - 2020Document15 pagesTerm Exam: NEET - 2020Adarsh SinghalNo ratings yet
- Nutrition in Metabolic Disorder PDFDocument363 pagesNutrition in Metabolic Disorder PDFJasmineSinghNo ratings yet
- An Assignment On Gene Transfer MechanismDocument4 pagesAn Assignment On Gene Transfer MechanismPraveen SapkotaNo ratings yet
- 233 Ia 2 2026Document15 pages233 Ia 2 2026PaapaErnestNo ratings yet
- MD AnatomyDocument16 pagesMD AnatomyJaydenNo ratings yet
- Csir Net Paper June 2008Document8 pagesCsir Net Paper June 2008Sajeer SayedaliNo ratings yet
- Protein Synthesis: It Is Expected That Students WillDocument32 pagesProtein Synthesis: It Is Expected That Students WillIMY PAMEROYANNo ratings yet
- AGR516 Chapter 2 Gene Recombination in Plant BreedingDocument59 pagesAGR516 Chapter 2 Gene Recombination in Plant BreedingXwag 12No ratings yet
- Quizzes For GeneticsDocument64 pagesQuizzes For Genetics2 Llamas ENTNo ratings yet
- Plants: Plant Breeding Is The Science of Changing The Traits ofDocument20 pagesPlants: Plant Breeding Is The Science of Changing The Traits ofBharat PatelNo ratings yet
- Classification and Identification of BacteriaDocument3 pagesClassification and Identification of BacteriaVenzNo ratings yet
- Seidman 2011Document9 pagesSeidman 2011Илија РадосављевићNo ratings yet
- James Perloff - Tornado in A Junkyard (Condensed)Document24 pagesJames Perloff - Tornado in A Junkyard (Condensed)mcdozer100% (1)
- Biological DatabasesDocument39 pagesBiological DatabasesKasun BandaraNo ratings yet
- Specification IGCSE Double Award Science SpecificationDocument62 pagesSpecification IGCSE Double Award Science Specificationjenny10040% (1)
- Cracking The Code of Life - AnswersDocument10 pagesCracking The Code of Life - AnswersmanessnatalyeeNo ratings yet
- Gene Therapy - STem Cell ResearchDocument35 pagesGene Therapy - STem Cell Researchqr codeNo ratings yet
- 2.1 Cell Structure QPDocument22 pages2.1 Cell Structure QPFatima NissaNo ratings yet
- Presentasi MutasiDocument33 pagesPresentasi MutasimilatiNo ratings yet
- Biology Model Examination For Grade 12 in The Year 2007 E.CDocument15 pagesBiology Model Examination For Grade 12 in The Year 2007 E.CDanielNo ratings yet

























































































Download as docx, pdf, or txt
You might also like
- Nucleic Acid ProjectDocument18 pagesNucleic Acid ProjectPramod Etarvi90% (10)
- DNA Rep and RNA StructureDocument30 pagesDNA Rep and RNA Structurekoromamoses235No ratings yet
- DNA in Cells: Molecular BiologyDocument10 pagesDNA in Cells: Molecular BiologyDe Los Santos AinjelNo ratings yet
- 6nucleic Acids - Boundless BiologyDocument15 pages6nucleic Acids - Boundless BiologyAmy SuarezNo ratings yet
- Nucleic Acids Store, Transmit and Help Express Hereditary InformationDocument6 pagesNucleic Acids Store, Transmit and Help Express Hereditary InformationDanielle GuerraNo ratings yet
- Nucleic Acid: 1. Nitrogenous BasesDocument3 pagesNucleic Acid: 1. Nitrogenous BasesMarie WrightNo ratings yet
- Research in Lecture "All About Nucleic Acid": Bicol University College of Nursing Legazpi City 2015-2016Document27 pagesResearch in Lecture "All About Nucleic Acid": Bicol University College of Nursing Legazpi City 2015-2016Kim GoNo ratings yet
- CHBH13 - Laboratory Manual 5Document11 pagesCHBH13 - Laboratory Manual 5Ysa DienteNo ratings yet
- Nucleic Acids - Structure and Function 2013Document51 pagesNucleic Acids - Structure and Function 2013ender arslanNo ratings yet
- Assignment No. 2Document2 pagesAssignment No. 2Jane Valine BalinoNo ratings yet
- 02-Nucleic Acids - Structure and FunctionDocument70 pages02-Nucleic Acids - Structure and FunctionBerru VardarNo ratings yet
- Nucleic Acid MetabolismDocument41 pagesNucleic Acid MetabolismPavani AkkalaNo ratings yet
- Nucleic Acids.Document7 pagesNucleic Acids.Mujthaba AdmaniNo ratings yet
- Written: in Biology Group 1Document5 pagesWritten: in Biology Group 1Joel EvangelistaNo ratings yet
- Lecture Nucleic AcidsDocument4 pagesLecture Nucleic Acidsj9694052No ratings yet
- BIO 001 5th LectureDocument24 pagesBIO 001 5th LectureBenjaminNo ratings yet
- Karthikeya XII-A Chemistry Project PDFDocument45 pagesKarthikeya XII-A Chemistry Project PDFkarthikeya kakarlapudiNo ratings yet
- Nucleic AcidsDocument4 pagesNucleic AcidsAshley Margareth BonifacioNo ratings yet
- Dna & RnaDocument11 pagesDna & Rnabelal.hassan3No ratings yet
- Basic Principles: Organisms Are Made of CellsDocument10 pagesBasic Principles: Organisms Are Made of CellsEllu SeethaNo ratings yet
- Structure and Function of Nucleic AcidDocument33 pagesStructure and Function of Nucleic AcidLaiba FarooqNo ratings yet
- Chromosomes, Genes and Nucleic AcidsDocument23 pagesChromosomes, Genes and Nucleic AcidsDANIELLA LOMA CAPONPONNo ratings yet
- Structure of Nucleic AcidsDocument3 pagesStructure of Nucleic AcidsHanz Glitzer MosquedaNo ratings yet
- 3.5. Nucleic Acids 22-23Document3 pages3.5. Nucleic Acids 22-23SiNo ratings yet
- 471 - BCH 201-Lecture Note On WebDocument10 pages471 - BCH 201-Lecture Note On WebShaikh SalmanNo ratings yet
- Chemistry of The Cell: Dr. Ayhan R. MahmoodDocument17 pagesChemistry of The Cell: Dr. Ayhan R. MahmoodSane IvNo ratings yet
- Nucleic Acids Rna World Biotech ProjectDocument18 pagesNucleic Acids Rna World Biotech ProjectSakshi SinghNo ratings yet
- HDTD-B-9 - Molecular Genetics IDocument25 pagesHDTD-B-9 - Molecular Genetics IMariam QaisNo ratings yet
- Structure and Function of Dna and Rna: Jon Paul M. Reyes, RMT, MBA, MSMLS Program Chair College of Medical TechnologyDocument21 pagesStructure and Function of Dna and Rna: Jon Paul M. Reyes, RMT, MBA, MSMLS Program Chair College of Medical TechnologyRich Darlene Dela CruzNo ratings yet
- Structure and Function of DNADocument27 pagesStructure and Function of DNAHaniya RijaNo ratings yet
- BiomoleculesDocument7 pagesBiomoleculesrajan.11proNo ratings yet
- Paper - IV Molecular BiologyDocument236 pagesPaper - IV Molecular BiologyNaruto UzumakiNo ratings yet
- BIOLOGY Chapter 4 - DNA, RNA and Protein SynthesisDocument6 pagesBIOLOGY Chapter 4 - DNA, RNA and Protein Synthesischelsea AlexandriaNo ratings yet
- Nucleic Acids and NucleotidesDocument4 pagesNucleic Acids and NucleotidesWolverineInZenNo ratings yet
- Nucleic AcidDocument3 pagesNucleic AcidSamraNo ratings yet
- Nucleic AcidsDocument42 pagesNucleic AcidsJulianne AnikaNo ratings yet
- Dna Dna DnaDocument67 pagesDna Dna DnaAlyasin FrougaNo ratings yet
- Differences Between DNA and RNADocument6 pagesDifferences Between DNA and RNAGevo GegantoNo ratings yet
- Chap. 8A Nucleotides and Nucleic Acids: - Some Basics - Nucleic Acid StructureDocument30 pagesChap. 8A Nucleotides and Nucleic Acids: - Some Basics - Nucleic Acid StructureAbrar Mohi-ud-DinNo ratings yet
- Genetic MaterialDocument31 pagesGenetic MaterialANBC- 24- Safa AfreenNo ratings yet
- MDocument9 pagesMNafeesa KousarNo ratings yet
- Dna 1Document31 pagesDna 1Dr-Dalya ShakirNo ratings yet
- Nucleic Acid and Protein Synthesis 2017-18Document18 pagesNucleic Acid and Protein Synthesis 2017-18ADEEL AHMADNo ratings yet
- Chemistry of Nucleic Acids..slideDocument19 pagesChemistry of Nucleic Acids..slideezebelluciNo ratings yet
- Linkages Form The Sugar-Phosphate Backbone of Both DNA and RNADocument3 pagesLinkages Form The Sugar-Phosphate Backbone of Both DNA and RNAed modoNo ratings yet
- Linkages Form The Sugar-Phosphate Backbone of Both DNA and RNADocument3 pagesLinkages Form The Sugar-Phosphate Backbone of Both DNA and RNAed modoNo ratings yet
- 1 The Central Dogma of Molecular BiologyDocument6 pages1 The Central Dogma of Molecular Biologydeladestianiaji2490100% (1)
- Nucleic Acid: Suzette B. DoctoleroDocument67 pagesNucleic Acid: Suzette B. DoctoleroPojangNo ratings yet
- 1 Nucleic AcidsDocument11 pages1 Nucleic AcidsSafiya JamesNo ratings yet
- Types of Nucleic AcidsDocument7 pagesTypes of Nucleic AcidsJomari Alipante100% (1)
- Nucleic AcidsDocument32 pagesNucleic AcidsAlexander DacumosNo ratings yet
- Structure and Function of DNADocument29 pagesStructure and Function of DNAMatthew Justin Villanueva GozoNo ratings yet
- Nucleic Acids RevisionDocument15 pagesNucleic Acids RevisionGilbert ossullivanNo ratings yet
- Basics of Molecular BiologyDocument10 pagesBasics of Molecular BiologyOday MadiNo ratings yet
- Nucleic-AcidDocument28 pagesNucleic-AcidIvan Jhon AnamNo ratings yet
- All About DnaDocument65 pagesAll About DnaPeopwdNo ratings yet
- 1.5 Nucleic AcidsDocument23 pages1.5 Nucleic AcidsMûhd AïZām ÄhmâdNo ratings yet
- Nucleotides and Nucleic Acids: Nucleotides Are Phosphorylated Nucleosides. A Nucleoside Is ADocument4 pagesNucleotides and Nucleic Acids: Nucleotides Are Phosphorylated Nucleosides. A Nucleoside Is AJuan sebastianNo ratings yet
- BCH 305 (Chemistry & Metabolism of Nucleic Acids)Document30 pagesBCH 305 (Chemistry & Metabolism of Nucleic Acids)ihebunnaogochukwu24No ratings yet
- Anatomy and Physiology for Students: A College Level Study Guide for Life Science and Allied Health MajorsFrom EverandAnatomy and Physiology for Students: A College Level Study Guide for Life Science and Allied Health MajorsNo ratings yet
- Exploring Ensembl: Exercise 1 - PandaDocument4 pagesExploring Ensembl: Exercise 1 - Pandaquique ddmNo ratings yet
- Variant ClassificationDocument5 pagesVariant ClassificationPeter OlejuaNo ratings yet
- MSC Ag GPBDocument26 pagesMSC Ag GPBnnazmul8052No ratings yet
- Scientists Prove DNA Can Be Reprogrammed by Our Own WordsDocument15 pagesScientists Prove DNA Can Be Reprogrammed by Our Own WordsqwertyjinNo ratings yet
- Paraphrasing Techniques-1Document21 pagesParaphrasing Techniques-1James CostelloeNo ratings yet
- M.Sc.-Microbiology Syllabus HNBDocument58 pagesM.Sc.-Microbiology Syllabus HNBBiology Made EasyNo ratings yet
- Lab 3 Evolutionary ProcessDocument3 pagesLab 3 Evolutionary ProcessRizkyDirectioners'ZaynsterNo ratings yet
- Syllabus 2022-2023 Class: XII Biology (Code No. 044) Course Structure Total Times: 3 Hrs Total Marks: 70Document5 pagesSyllabus 2022-2023 Class: XII Biology (Code No. 044) Course Structure Total Times: 3 Hrs Total Marks: 70Debalina NagNo ratings yet
- Biology Science For Life 4th Edition Belk Test BankDocument38 pagesBiology Science For Life 4th Edition Belk Test Bankapodaawlwortn3ae100% (14)
- Oligo Analyzer SEC PRIMER 2Document1 pageOligo Analyzer SEC PRIMER 2divillamarinNo ratings yet
- Term Exam: NEET - 2020Document15 pagesTerm Exam: NEET - 2020Adarsh SinghalNo ratings yet
- Nutrition in Metabolic Disorder PDFDocument363 pagesNutrition in Metabolic Disorder PDFJasmineSinghNo ratings yet
- An Assignment On Gene Transfer MechanismDocument4 pagesAn Assignment On Gene Transfer MechanismPraveen SapkotaNo ratings yet
- 233 Ia 2 2026Document15 pages233 Ia 2 2026PaapaErnestNo ratings yet
- MD AnatomyDocument16 pagesMD AnatomyJaydenNo ratings yet
- Csir Net Paper June 2008Document8 pagesCsir Net Paper June 2008Sajeer SayedaliNo ratings yet
- Protein Synthesis: It Is Expected That Students WillDocument32 pagesProtein Synthesis: It Is Expected That Students WillIMY PAMEROYANNo ratings yet
- AGR516 Chapter 2 Gene Recombination in Plant BreedingDocument59 pagesAGR516 Chapter 2 Gene Recombination in Plant BreedingXwag 12No ratings yet
- Quizzes For GeneticsDocument64 pagesQuizzes For Genetics2 Llamas ENTNo ratings yet
- Plants: Plant Breeding Is The Science of Changing The Traits ofDocument20 pagesPlants: Plant Breeding Is The Science of Changing The Traits ofBharat PatelNo ratings yet
- Classification and Identification of BacteriaDocument3 pagesClassification and Identification of BacteriaVenzNo ratings yet
- Seidman 2011Document9 pagesSeidman 2011Илија РадосављевићNo ratings yet
- James Perloff - Tornado in A Junkyard (Condensed)Document24 pagesJames Perloff - Tornado in A Junkyard (Condensed)mcdozer100% (1)
- Biological DatabasesDocument39 pagesBiological DatabasesKasun BandaraNo ratings yet
- Specification IGCSE Double Award Science SpecificationDocument62 pagesSpecification IGCSE Double Award Science Specificationjenny10040% (1)
- Cracking The Code of Life - AnswersDocument10 pagesCracking The Code of Life - AnswersmanessnatalyeeNo ratings yet
- Gene Therapy - STem Cell ResearchDocument35 pagesGene Therapy - STem Cell Researchqr codeNo ratings yet
- 2.1 Cell Structure QPDocument22 pages2.1 Cell Structure QPFatima NissaNo ratings yet
- Presentasi MutasiDocument33 pagesPresentasi MutasimilatiNo ratings yet
- Biology Model Examination For Grade 12 in The Year 2007 E.CDocument15 pagesBiology Model Examination For Grade 12 in The Year 2007 E.CDanielNo ratings yet