Download as pdf or txt
You might also like
- Instructional Strategies and Practices Towards The Enhancement of Cookery-Related Skills of The Grade 7 and 9 Students of Titay National High SchoolDocument20 pagesInstructional Strategies and Practices Towards The Enhancement of Cookery-Related Skills of The Grade 7 and 9 Students of Titay National High SchoolPilar Galvano Ancheta80% (15)
- LorelDocument23 pagesLorelRabindra KarkiNo ratings yet
- Astm A500Document6 pagesAstm A500notsofar100% (4)
- Simple Linear Regression: Y ($) X ($) Y ($) X ($)Document5 pagesSimple Linear Regression: Y ($) X ($) Y ($) X ($)Nguyễn Tuấn AnhNo ratings yet
- HW Multiple Regression AnalysisDocument5 pagesHW Multiple Regression AnalysisChristine NgNo ratings yet
- Engineering ManagementDocument4 pagesEngineering ManagementPHILIPANTHONY MASILANGNo ratings yet
- F1G113078 UasDocument11 pagesF1G113078 UasSabanNo ratings yet
- Tugas Metode Kuantitatif - Dicky WahyudiDocument9 pagesTugas Metode Kuantitatif - Dicky WahyudiDicky WahyudiNo ratings yet
- Chanels Tapered Flange Metric and Universal Beams and Columns Imperial Units and UPNDocument3 pagesChanels Tapered Flange Metric and Universal Beams and Columns Imperial Units and UPNPratama YogaNo ratings yet
- Feliciani, Bryan, M Midterm ExamDocument10 pagesFeliciani, Bryan, M Midterm ExamBryan FelicianoNo ratings yet
- Intervale de Variatie Ponderea Cumulata A Debitorilor N X XNDocument4 pagesIntervale de Variatie Ponderea Cumulata A Debitorilor N X XNLena IlicishinaNo ratings yet
- Variable ChartsDocument18 pagesVariable Chartsyuanita_mayasariNo ratings yet
- Student Name: Zain Asim: Question 1 (Correlation Coefficient and Population Analysis)Document7 pagesStudent Name: Zain Asim: Question 1 (Correlation Coefficient and Population Analysis)Abass GblaNo ratings yet
- Taller 11Document2 pagesTaller 11angie_varela8511No ratings yet
- Linear Regression2Document8 pagesLinear Regression2Bulelwa HarrisNo ratings yet
- ExerciseDocument6 pagesExerciseihab awwadNo ratings yet
- Chart Title: Periode 1 2 3 4 5 6 7 8 9 10 11 12 Qté 150 162 170 175 180 191 185 196 213 223 212 225Document14 pagesChart Title: Periode 1 2 3 4 5 6 7 8 9 10 11 12 Qté 150 162 170 175 180 191 185 196 213 223 212 225Shop InNo ratings yet
- Simple Linear RegressionDocument11 pagesSimple Linear RegressionmaneeshmogallpuNo ratings yet
- 58 GF 1958.333 78 GP 750 GW 1208.333 Hỗn hợp năng suất aF aP aW Acetone-B 47 0.38 0.96 0.02 xF 0.45 MF 68.96341 xP 0.97 MP 58.60104 xW 0.03 MW 77.46575 F 28.3967 P 12.7984 W 12.7984 M MDocument55 pages58 GF 1958.333 78 GP 750 GW 1208.333 Hỗn hợp năng suất aF aP aW Acetone-B 47 0.38 0.96 0.02 xF 0.45 MF 68.96341 xP 0.97 MP 58.60104 xW 0.03 MW 77.46575 F 28.3967 P 12.7984 W 12.7984 M MTình NợNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- Frasco Vazio: Número de Vezes)Document8 pagesFrasco Vazio: Número de Vezes)Rafael Campos MaiaNo ratings yet
- Z Scores 02042021 104523pmDocument9 pagesZ Scores 02042021 104523pmAbduiNo ratings yet
- Diagrama de Dispercion: Semana Ventas PrecioDocument18 pagesDiagrama de Dispercion: Semana Ventas PrecioJuanCarlos MendozaNo ratings yet
- Axis Title: 1200 1400 F (X) 84.7484629538x - 70.7707669524 R 0.989570487 V Linear (V)Document10 pagesAxis Title: 1200 1400 F (X) 84.7484629538x - 70.7707669524 R 0.989570487 V Linear (V)rahmatNo ratings yet
- Chart Title: Tablet Computer Sales Week Units SoldDocument4 pagesChart Title: Tablet Computer Sales Week Units SoldAshir khanNo ratings yet
- ABCT1001 Tut 6 Question SetDocument3 pagesABCT1001 Tut 6 Question Setzhouwenjin1916No ratings yet
- Universal Beams and Columns Imperial UnitsDocument1 pageUniversal Beams and Columns Imperial UnitsPratama YogaNo ratings yet
- Intervalo de Clase (M) Marca de Clase Frec. Absoluta (X) Frec. Relativa (%) Frec. Relativa AcumuladaDocument5 pagesIntervalo de Clase (M) Marca de Clase Frec. Absoluta (X) Frec. Relativa (%) Frec. Relativa AcumuladaBrayanNo ratings yet
- Simple Linear Regression EquationDocument7 pagesSimple Linear Regression Equationsuboor ahmedNo ratings yet
- Regression Illustrations PDFDocument5 pagesRegression Illustrations PDFMarrick MbuiNo ratings yet
- SPC Calculator 1Document15 pagesSPC Calculator 1NarasimharaghavanPuliyurKrishnaswamyNo ratings yet
- STA101 Assignment 5 SolutionDocument7 pagesSTA101 Assignment 5 SolutionJUNAYED AHMED RAFINNo ratings yet
- Lampiran SPSS: StatisticsDocument2 pagesLampiran SPSS: StatisticsWida SukmawatiNo ratings yet
- Analysis and Interpretation of Data Regression Analysis: Table 5.1. Nike's Actual Shares in August 2020Document11 pagesAnalysis and Interpretation of Data Regression Analysis: Table 5.1. Nike's Actual Shares in August 2020Zamantha TiangcoNo ratings yet
- Decision Science Assignment 2Document6 pagesDecision Science Assignment 2Vishnu TiwariNo ratings yet
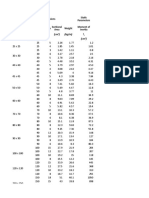
- (MM X MM) (CM) (CM) : Size Dimensions Depth Thickness Weight H S Static Parameters Sectional Area Moment of Inertia IDocument2 pages(MM X MM) (CM) (CM) : Size Dimensions Depth Thickness Weight H S Static Parameters Sectional Area Moment of Inertia IKakoy Lagusan EcobenNo ratings yet
- Frequency Distribution - Qualitative: Tipo de CreditoDocument4 pagesFrequency Distribution - Qualitative: Tipo de CreditoJosue Huaman CiezaNo ratings yet
- Σy Ȳ Ȳ Ȳ Ȳ Ȳ Desviacion Estándar Ȳ Ȳ Ȳ Aσy-Bσxy Ȳ N- 2 ΣyDocument8 pagesΣy Ȳ Ȳ Ȳ Ȳ Ȳ Desviacion Estándar Ȳ Ȳ Ȳ Aσy-Bσxy Ȳ N- 2 Σyandrea delgadoNo ratings yet
- Problema Resuelto GranulometriaDocument2 pagesProblema Resuelto GranulometriaJ Quispe MontañezNo ratings yet
- Notes Chap 2 OrganizeDocument9 pagesNotes Chap 2 OrganizeAbtehal AlfahaidNo ratings yet
- Assignment 3 Case Study 1. 16th August 2020Document9 pagesAssignment 3 Case Study 1. 16th August 2020Shivam AgarwalNo ratings yet
- Exe ExcelDocument9 pagesExe ExcelAnh PhongNo ratings yet
- Rachit. AssignmentDocument25 pagesRachit. Assignmentkracc0744No ratings yet
- I-MR Exercises and Problem SituationDocument5 pagesI-MR Exercises and Problem Situationa01634109No ratings yet
- Hydrology Assignment No. 2 Double Mass AnalysisDocument5 pagesHydrology Assignment No. 2 Double Mass AnalysisFrank PingolNo ratings yet
- MM4 ฟิว (Version 1)Document15 pagesMM4 ฟิว (Version 1)Pattanapol KraisookNo ratings yet
- Book 1Document4 pagesBook 1PalakNo ratings yet
- Estadistica GraficosDocument6 pagesEstadistica Graficosalejandra prieto corderoNo ratings yet
- Optimized Conversions Using RSMDocument3 pagesOptimized Conversions Using RSMSudarshan GopalNo ratings yet
- Latihan AndataDocument12 pagesLatihan AndataPSKM STIKES HI JAMBINo ratings yet
- LC Praktikum 2 (Konstanta Radiasi)Document3 pagesLC Praktikum 2 (Konstanta Radiasi)annesa hanabilaNo ratings yet
- Multiple Regression and Correlation Analysis: BX A YDocument35 pagesMultiple Regression and Correlation Analysis: BX A YMd. Rafiul Islam 2016326660No ratings yet
- REGRESIONDocument7 pagesREGRESIONAlejandro RojasNo ratings yet
- Quadratic Curve BaiDocument6 pagesQuadratic Curve Bai2022697858No ratings yet
- Time (HR)Document11 pagesTime (HR)Miko AbiNo ratings yet
- Polim-D Chabb 103 en 31.03.2010Document6 pagesPolim-D Chabb 103 en 31.03.2010anksyeteNo ratings yet
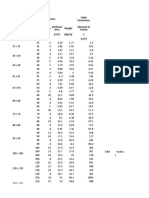
- (MM X MM) (CM) (CM) : Size Dimensions Depth Thickness Weight H S Static Parameters Sectional Area Moment of Inertia IDocument2 pages(MM X MM) (CM) (CM) : Size Dimensions Depth Thickness Weight H S Static Parameters Sectional Area Moment of Inertia IKakoy Lagusan EcobenNo ratings yet
- STPM Physic Experiment 2 (Term 1, 2016) .Document2 pagesSTPM Physic Experiment 2 (Term 1, 2016) .Oh Yee YinNo ratings yet
- AsdDocument16 pagesAsdjossNo ratings yet
- Decision Science AssignmentDocument13 pagesDecision Science AssignmentPooja GoyalNo ratings yet
- LGT2425 Lecture 3 Part II (Notes)Document55 pagesLGT2425 Lecture 3 Part II (Notes)Jackie ChouNo ratings yet
- Year Annual Precipitation Year Annual PrecipitationDocument10 pagesYear Annual Precipitation Year Annual PrecipitationRowena PandanNo ratings yet
- Technical Specification For Ground Wire OPGWDocument28 pagesTechnical Specification For Ground Wire OPGWtanujaayer100% (1)
- Sencha Advance CheatSheetDocument43 pagesSencha Advance CheatSheetkokareom2977No ratings yet
- Problems of Education in The 21st Century, Vol. 27, 2011Document125 pagesProblems of Education in The 21st Century, Vol. 27, 2011Scientia Socialis, Ltd.No ratings yet
- George Hang - Finding The Energy Spectrum of The Quantum Hindered Rotor by The Lanczos MethodDocument119 pagesGeorge Hang - Finding The Energy Spectrum of The Quantum Hindered Rotor by The Lanczos MethodYidel4313No ratings yet
- SynonymsDocument3 pagesSynonymsMary Fe Sarate Navarro IINo ratings yet
- Depth InterviewDocument23 pagesDepth InterviewRevs MenonNo ratings yet
- Technologies Design and Technologies Year 5 Teaching and Learning ExemplarDocument94 pagesTechnologies Design and Technologies Year 5 Teaching and Learning ExemplarFabiana VasquesNo ratings yet
- Getting Started With MDM: 9 Steps ToDocument16 pagesGetting Started With MDM: 9 Steps ToSantiago GivNo ratings yet
- Ucdb Ref v1.0Document102 pagesUcdb Ref v1.0SWAPNIL DWIVEDINo ratings yet
- Rotary Polishing Tool 2Document14 pagesRotary Polishing Tool 2bcairns12No ratings yet
- Ilide - Info Details of Mobile Repairing Course PRDocument5 pagesIlide - Info Details of Mobile Repairing Course PRLoki VistNo ratings yet
- Sociotropy, Autonomy, and Self-CriticismDocument10 pagesSociotropy, Autonomy, and Self-Criticismowilm892973100% (1)
- OCBC Customer Service CharterDocument14 pagesOCBC Customer Service CharterSivanathan AnbuNo ratings yet
- Mill Behaviour of Rubber On Two Roll Mill With Temperature: Nippon Gomu Kyokaishi, 88, No. 4, 2015, Pp. 130-135Document6 pagesMill Behaviour of Rubber On Two Roll Mill With Temperature: Nippon Gomu Kyokaishi, 88, No. 4, 2015, Pp. 130-135Prashantha NandavarNo ratings yet
- SPD Compatible Pedals: SM-SH51 SM-SH55Document1 pageSPD Compatible Pedals: SM-SH51 SM-SH55Bernardo LizardiNo ratings yet
- 305-Understanding The Operation of Pumps Missing Pages 139-140Document162 pages305-Understanding The Operation of Pumps Missing Pages 139-140ataguca100% (1)
- Unit 14 Opinion Full EssayDocument1 pageUnit 14 Opinion Full EssayQuân Lê ĐàoNo ratings yet
- Honda Motorcycle & Scooter India Pvt. LTD.: MH010402PA001:10-Mar-2022 04:46:20 PMDocument128 pagesHonda Motorcycle & Scooter India Pvt. LTD.: MH010402PA001:10-Mar-2022 04:46:20 PMpzy84628870No ratings yet
- Appunti Nothing Ever DiesDocument10 pagesAppunti Nothing Ever DiesfedericaNo ratings yet
- White Paper Dissolved Gas Analysis: © 2014 Schneider Electric All Rights ReservedDocument4 pagesWhite Paper Dissolved Gas Analysis: © 2014 Schneider Electric All Rights ReservedtusarNo ratings yet
- False Friends: A Historical Perspective Aild Present Iinplications For Lexical AcqttisitioilDocument13 pagesFalse Friends: A Historical Perspective Aild Present Iinplications For Lexical AcqttisitioilKory VegaNo ratings yet
- HP 15-CS 1016ur Quanta G7BD DAG7BDMB8F0 Rev 1ADocument49 pagesHP 15-CS 1016ur Quanta G7BD DAG7BDMB8F0 Rev 1AJuan Carlos Huaman HuertaNo ratings yet
- DatabaseDocument326 pagesDatabaseFurukawa SaiNo ratings yet
- Gec105 Chapter1 3 Compilation PDFDocument6 pagesGec105 Chapter1 3 Compilation PDFGail AgadNo ratings yet
- Concrete Placement Inspection ChecklistDocument21 pagesConcrete Placement Inspection ChecklistVasa50% (2)
- Ch-03 Vectors: Lect-01Document20 pagesCh-03 Vectors: Lect-01Mohit TewatiaNo ratings yet
- Amnex Corporate Presentation PDFDocument28 pagesAmnex Corporate Presentation PDFShweta SharmaNo ratings yet