Download as docx, pdf, or txt
You might also like
- Computer Vision With Python Cookbook PDFDocument208 pagesComputer Vision With Python Cookbook PDFNevin DeshpandeNo ratings yet
- Eye Safety of IREDsDocument17 pagesEye Safety of IREDsЕвгений МихайловNo ratings yet
- VOITH Variable Speed Fluid CouplingsDocument20 pagesVOITH Variable Speed Fluid CouplingsChristian AlmengorNo ratings yet
- Oral PresentationDocument9 pagesOral Presentationaryanrajesh6702No ratings yet
- CodingDocument7 pagesCodingbraisonwabwire2003No ratings yet
- House Price Prediction Using Linear Regression in MLDocument9 pagesHouse Price Prediction Using Linear Regression in MLVishnu BNo ratings yet
- Assignment 1 AIDocument6 pagesAssignment 1 AIRaj AryanNo ratings yet
- R D National College Mumbai University: On "House Price Prediction System"Document14 pagesR D National College Mumbai University: On "House Price Prediction System"Simran SolankiNo ratings yet
- Real Estate Project PDFDocument8 pagesReal Estate Project PDFRashmiNo ratings yet
- Data Science Assignment Chapter 1Document5 pagesData Science Assignment Chapter 1Gaming WorldNo ratings yet
- Dma 362Document7 pagesDma 362mithileshwarreddymithileshNo ratings yet
- Project CdacDocument4 pagesProject Cdacabhishekbayas103No ratings yet
- Dynamic Retail PricingDocument5 pagesDynamic Retail PricingOmkar A. PätìlNo ratings yet
- Title Predicting House Pricing Using AIML (KASHISH)Document2 pagesTitle Predicting House Pricing Using AIML (KASHISH)Jay VardhanNo ratings yet
- House Pricing Prediction SystemDocument36 pagesHouse Pricing Prediction SystemShivam PatelNo ratings yet
- An Introduction To Parametric EstimatingDocument7 pagesAn Introduction To Parametric EstimatinggenergiaNo ratings yet
- Type of Cost ModelDocument9 pagesType of Cost ModelBgee Lee100% (1)
- End To End Machine Learning Problem Problem Under DiscussionDocument12 pagesEnd To End Machine Learning Problem Problem Under DiscussionDONA A BNo ratings yet
- Notes - Sap BPC 340Document10 pagesNotes - Sap BPC 340anusssnair8808No ratings yet
- Real Estate Value Prediction Using Multivariate Regression ModelsDocument8 pagesReal Estate Value Prediction Using Multivariate Regression ModelsAimane CAFNo ratings yet
- Predicting Stock Values Using A Recurrent Neural NetworkDocument12 pagesPredicting Stock Values Using A Recurrent Neural NetworkMr SKammerNo ratings yet
- COMP1801 - Copy 1Document18 pagesCOMP1801 - Copy 1SujiKrishnanNo ratings yet
- SWE680 Midterm - 94929Document6 pagesSWE680 Midterm - 94929Jayanth JaidevNo ratings yet
- Machine Learning Assignment 1Document4 pagesMachine Learning Assignment 1Balaji DhanabalNo ratings yet
- Powerplay Cubes Modeling and Development Process: Main Powerplay Transformer FeaturesDocument16 pagesPowerplay Cubes Modeling and Development Process: Main Powerplay Transformer FeaturesjbprasadyadavNo ratings yet
- Unit 4Document5 pagesUnit 4Rohan pandeyNo ratings yet
- Module 2Document24 pagesModule 2anushajNo ratings yet
- QuizDocument5 pagesQuizFatma Zohra OUIRNo ratings yet
- MLDocument49 pagesMLgetap85298No ratings yet
- Quiz-1 NotesDocument4 pagesQuiz-1 NotesShruthi ShettyNo ratings yet
- TDT4240 Exam 2014 SolutionDocument7 pagesTDT4240 Exam 2014 SolutionWajih ul hassanNo ratings yet
- SRS WorddDocument5 pagesSRS Worddsairgvn47No ratings yet
- Steps of Implementation of A GLMDocument8 pagesSteps of Implementation of A GLMPaul WattellierNo ratings yet
- Loan Pricing SRSDocument10 pagesLoan Pricing SRSabhikore1432No ratings yet
- Case Study 219302405Document14 pagesCase Study 219302405nishantjain2k03No ratings yet
- 2 & 5 MarksDocument25 pages2 & 5 MarksSamarth PhutelaNo ratings yet
- Phase 5Document5 pagesPhase 5jeinjein864No ratings yet
- A Synopsys ReportDocument16 pagesA Synopsys ReportHasan KhanNo ratings yet
- Improving Preference Prediction Accuracy With Feature LearningDocument9 pagesImproving Preference Prediction Accuracy With Feature LearningKyle GibsonNo ratings yet
- Unit 5Document11 pagesUnit 5Md. SunmunNo ratings yet
- Punishment AssignmentDocument6 pagesPunishment Assignmentyashchheda2002No ratings yet
- PY016Document8 pagesPY016jekocew803No ratings yet
- Price Discrimination in Communication NetworksDocument7 pagesPrice Discrimination in Communication NetworksIJCERT PUBLICATIONSNo ratings yet
- CE802 ReportDocument7 pagesCE802 ReportprenithjohnsamuelNo ratings yet
- UnitDocument9 pagesUnitabhilang836No ratings yet
- 2nd UnitDocument10 pages2nd UnitParveen SwamiNo ratings yet
- Architecting Option Content: Kevin N. OttoDocument11 pagesArchitecting Option Content: Kevin N. OttoRoberto PanizzoloNo ratings yet
- CW1 PaperDocument4 pagesCW1 Paperrevaluate21No ratings yet
- SynopsisDocument7 pagesSynopsissuryalakshmi147No ratings yet
- Project Synopsis ShaibaDocument5 pagesProject Synopsis ShaibaArshad ZakariaNo ratings yet
- Parameterized Specification and Verification of The Chilean Electronic Invoices SystemDocument12 pagesParameterized Specification and Verification of The Chilean Electronic Invoices SystemMCINo ratings yet
- AIDSDocument15 pagesAIDSDhanraj DeoreNo ratings yet
- CAT-2 NotesDocument26 pagesCAT-2 NotesDhanushNo ratings yet
- R For Data Science Sample ChapterDocument39 pagesR For Data Science Sample ChapterPackt Publishing100% (1)
- Yug RemovedDocument29 pagesYug Removedsrishti porwalNo ratings yet
- Snow Q&aDocument11 pagesSnow Q&amysubscriptionyt1No ratings yet
- CSIC 6132 排版870 878Document9 pagesCSIC 6132 排版870 878Shashank ChowdaryNo ratings yet
- P-149 Final PPTDocument57 pagesP-149 Final PPTVijay rathodNo ratings yet
- Week2 Excel Problem Statement Real Estate-1Document2 pagesWeek2 Excel Problem Statement Real Estate-1Sandeep VishwakarmaNo ratings yet
- An Enterprise Continuous Monitoring Technical Reference Model Overview Peter Sell, National Security AgencyDocument31 pagesAn Enterprise Continuous Monitoring Technical Reference Model Overview Peter Sell, National Security Agencyapi-226867795No ratings yet
- Preparing The Systems Proposal: Steps in Acquiring Computer Hardware and SoftwareDocument29 pagesPreparing The Systems Proposal: Steps in Acquiring Computer Hardware and Softwareapi-19794302No ratings yet
- TIME SERIES FORECASTING. ARIMAX, ARCH AND GARCH MODELS FOR UNIVARIATE TIME SERIES ANALYSIS. Examples with MatlabFrom EverandTIME SERIES FORECASTING. ARIMAX, ARCH AND GARCH MODELS FOR UNIVARIATE TIME SERIES ANALYSIS. Examples with MatlabNo ratings yet
- Modern Data Mining Algorithms in C++ and CUDA C: Recent Developments in Feature Extraction and Selection Algorithms for Data ScienceFrom EverandModern Data Mining Algorithms in C++ and CUDA C: Recent Developments in Feature Extraction and Selection Algorithms for Data ScienceNo ratings yet
- Jntuh SCTDocument3 pagesJntuh SCTGowthamUcekNo ratings yet
- Air Conditioning SystemDocument45 pagesAir Conditioning SystemJose Carlos LeonorNo ratings yet
- ED3100 Series High Performance General Pupose Inverter Instruction Manual V1.11Document144 pagesED3100 Series High Performance General Pupose Inverter Instruction Manual V1.11marcial714No ratings yet
- The E-Primer: An Introduction To Creating Psychological Experiments in E-Prime (Preview)Document71 pagesThe E-Primer: An Introduction To Creating Psychological Experiments in E-Prime (Preview)testhvseprimeNo ratings yet
- Magic of Geometry.Document113 pagesMagic of Geometry.uthso roy100% (3)
- Information FusionDocument22 pagesInformation FusionJavi DoorsNo ratings yet
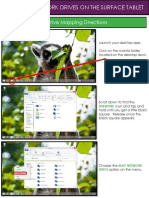
- MAPPING DRIVES PowerPoint PresentationDocument6 pagesMAPPING DRIVES PowerPoint PresentationDave MilnerNo ratings yet
- Chapter - 3 - EERDDocument67 pagesChapter - 3 - EERDbui datNo ratings yet
- Relational Database Operations Modeling With UMLDocument6 pagesRelational Database Operations Modeling With UMLMohammed AlramadiNo ratings yet
- Red Book Section 122Document18 pagesRed Book Section 122Alejandro ViscarraNo ratings yet
- InFix To PostFix ConversionDocument44 pagesInFix To PostFix ConversionAmany SalemNo ratings yet
- 7 - Schematic of A Thermal Power PlantDocument29 pages7 - Schematic of A Thermal Power PlantAnonymous 4SIk3AdnNo ratings yet
- Practical Model Paper Computer Science HSSC-PracticalDocument2 pagesPractical Model Paper Computer Science HSSC-PracticalAnas AliNo ratings yet
- SQL Server Interview Questions With Answers - Msbi GuideDocument16 pagesSQL Server Interview Questions With Answers - Msbi GuideKishore NaiduNo ratings yet
- Drill Nomenclature and Geometry: Submitted By:-Suhail Ali Sabri M.Tech, Production Engineering 2018PPE8010Document8 pagesDrill Nomenclature and Geometry: Submitted By:-Suhail Ali Sabri M.Tech, Production Engineering 2018PPE8010kumarNo ratings yet
- Arc Flash IE and Iarc Calculators User ManualDocument4 pagesArc Flash IE and Iarc Calculators User ManualMehrdad NiruiNo ratings yet
- DuplexerDocument7 pagesDuplexermanishbharti0786100% (2)
- Design & Development of Insertion Mechanism For Assemblage of Shell & Tube Heat ExchangerDocument8 pagesDesign & Development of Insertion Mechanism For Assemblage of Shell & Tube Heat ExchangerVaibhav DhandeNo ratings yet
- Control Keys in Computer A-Z - Control Key Shortcuts Keyboard Shortcut PDFDocument111 pagesControl Keys in Computer A-Z - Control Key Shortcuts Keyboard Shortcut PDFprodigious84No ratings yet
- P s l τ t s s τ s l P: Visit us at: www.nodia.co.inDocument1 pageP s l τ t s s τ s l P: Visit us at: www.nodia.co.inSameerChauhanNo ratings yet
- Differential Leveling PDF DocumentDocument4 pagesDifferential Leveling PDF DocumentKen Andrei CadungogNo ratings yet
- J Cos Lot QuadratoDocument10 pagesJ Cos Lot QuadratoMARLON ADOLFO CESPEDES ALCCANo ratings yet
- Class Xii Chemistry Students Support MaterialDocument95 pagesClass Xii Chemistry Students Support MaterialDivyam GargNo ratings yet
- Floor Plan Generation Using GANDocument144 pagesFloor Plan Generation Using GANBerfin YILDIZNo ratings yet
- Lesson 2 Parallel Lines and Transversals PDFDocument5 pagesLesson 2 Parallel Lines and Transversals PDFChebie CheChe OrdinaDoNo ratings yet
- Catalog Varvel RS RTDocument60 pagesCatalog Varvel RS RTNikola VojisavljevicNo ratings yet
- Mastering JMP Definitive Screening DesignsDocument39 pagesMastering JMP Definitive Screening DesignsBosco RajuNo ratings yet