
Module 2
Module 2
You might also like
- individual scores final grade 1 2 3 4 5 6 7 8 Σ: Final Exam DSP May 24, 2018Document45 pagesindividual scores final grade 1 2 3 4 5 6 7 8 Σ: Final Exam DSP May 24, 2018Muhammad Khubaib AtharNo ratings yet
- A Crash Course in Data Science ReviewDocument11 pagesA Crash Course in Data Science ReviewhukaNo ratings yet
- Lecture4 - Convnets For CV SlideDocument65 pagesLecture4 - Convnets For CV SlidemohdharislcpNo ratings yet
- Lec9 - Logic SynthesisDocument26 pagesLec9 - Logic SynthesisPrabhavathi PNo ratings yet
- Visible SurfaceDocument23 pagesVisible SurfacePrachiNo ratings yet
- DL6 - Convnets 4Document57 pagesDL6 - Convnets 4razifa0No ratings yet
- CVlecture 6Document33 pagesCVlecture 6David BNo ratings yet
- Recurrent Neural NetworksDocument25 pagesRecurrent Neural NetworksMehak SmaghNo ratings yet
- Lect5 UWADocument93 pagesLect5 UWAanant_nimkar9243No ratings yet
- High-Performance Hardware For Machine Learning - 0916Document68 pagesHigh-Performance Hardware For Machine Learning - 0916Bill PetrieNo ratings yet
- 3.4 Feature and Distance Standardisation: 66 Chapter 3. Content-Based Retrieval in DepthDocument18 pages3.4 Feature and Distance Standardisation: 66 Chapter 3. Content-Based Retrieval in DepthAnnisa SafitriNo ratings yet
- L7 DetectionDocument54 pagesL7 DetectionAgha KazimNo ratings yet
- The JPEG2000 Image Compression Standard: © V. Sanchez & A. Basu, University of AlbertaDocument30 pagesThe JPEG2000 Image Compression Standard: © V. Sanchez & A. Basu, University of AlbertaAnonymous bIzjNHZeeBNo ratings yet
- Lovato 2013Document5 pagesLovato 2013AjaNo ratings yet
- Global Reg AllocationDocument76 pagesGlobal Reg Allocationjasonjunior390No ratings yet
- FTML - Learning Deep Architectures For AI - Slidesbengio - 2009 PDFDocument87 pagesFTML - Learning Deep Architectures For AI - Slidesbengio - 2009 PDFajgallegoNo ratings yet
- Module 6Document83 pagesModule 6saisivani.ashok2021No ratings yet
- A Novel Ku/Ka Dual-Band Reflectarray Antenna With Arbitrary PolarizationDocument2 pagesA Novel Ku/Ka Dual-Band Reflectarray Antenna With Arbitrary Polarizationpavithra paviNo ratings yet
- Today's Lecture: Repetition and Refinement of Image BasicsDocument36 pagesToday's Lecture: Repetition and Refinement of Image BasicsAli KassabNo ratings yet
- Congestion Driven PlacementDocument25 pagesCongestion Driven PlacementJayanth bemesettyNo ratings yet
- The Transfer Function of The Nth-Order Digital Butterworth Low Pass FilterDocument5 pagesThe Transfer Function of The Nth-Order Digital Butterworth Low Pass FilterNguyen Si PhuocNo ratings yet
- Back Prop in Cortex 2007Document16 pagesBack Prop in Cortex 2007danielNo ratings yet
- Distrebuted: CommunicationDocument8 pagesDistrebuted: Communicationjane turkNo ratings yet
- Heterogeneous Wireless Sensor Networks: ContentDocument6 pagesHeterogeneous Wireless Sensor Networks: ContentSumit KushwahaNo ratings yet
- 03 Convolutional Neural NetworksDocument83 pages03 Convolutional Neural NetworksManish kumawatNo ratings yet
- Class14 - Handout MTSE 3010 2013 PDFDocument14 pagesClass14 - Handout MTSE 3010 2013 PDFManprit SinghNo ratings yet
- Hall ICTPDocument40 pagesHall ICTPapi-3819873100% (1)
- CS60010: Deep Learning: Recurrent Neural NetworkDocument44 pagesCS60010: Deep Learning: Recurrent Neural Networkparantap dansanaNo ratings yet
- Wavelets and Multiresolution: by Dr. Mahua BhattacharyaDocument39 pagesWavelets and Multiresolution: by Dr. Mahua BhattacharyashubhamNo ratings yet
- R-FCN: Object Detection Via Region-Based Fully Convolutional NetworksDocument11 pagesR-FCN: Object Detection Via Region-Based Fully Convolutional NetworksujnzaqNo ratings yet
- Image and Video Super-ResolutionDocument62 pagesImage and Video Super-ResolutionjebemnatoNo ratings yet
- Bandwidth in Octaves Vs Q in Bandpass Filters PDFDocument3 pagesBandwidth in Octaves Vs Q in Bandpass Filters PDFManu GaunaNo ratings yet
- Minsky y PapertDocument77 pagesMinsky y PapertHenrry CastilloNo ratings yet
- Manipulator KinematicsDocument61 pagesManipulator KinematicsHoang Minh ThangNo ratings yet
- Basics of Neural Network and Deep Learning: Presented By: - Subhodeep Seal - 162116559 - CSE 'B' - 3 - 6 - 4/5/2019Document12 pagesBasics of Neural Network and Deep Learning: Presented By: - Subhodeep Seal - 162116559 - CSE 'B' - 3 - 6 - 4/5/2019Animesh PrasadNo ratings yet
- Computer Assisted Image Analysis Lecture 3 - Local OperatorsDocument47 pagesComputer Assisted Image Analysis Lecture 3 - Local OperatorsSome UserNo ratings yet
- Chenming Hu Ch4 SlidesDocument79 pagesChenming Hu Ch4 SlidesNikhil HosurNo ratings yet
- CNN IitkgpDocument112 pagesCNN Iitkgpamrutamhetre9No ratings yet
- Unit 4a - Convolutional Neural NetworksDocument107 pagesUnit 4a - Convolutional Neural NetworksEsha Thaniya MallaNo ratings yet
- Multichannel Variable-Size Convolution For Sentence ClassificationDocument13 pagesMultichannel Variable-Size Convolution For Sentence Classificationakg299No ratings yet
- Convolutional Neural Networks (1) : Geena KimDocument28 pagesConvolutional Neural Networks (1) : Geena KimHuston LAMNo ratings yet
- All Are Worth Words: A Vit Backbone For Diffusion Models: Long Skip ConnectionDocument21 pagesAll Are Worth Words: A Vit Backbone For Diffusion Models: Long Skip Connectionpjnbe6No ratings yet
- LECTURE 11,12 Camera Models: CSE 320 Graphics ProgrammingDocument71 pagesLECTURE 11,12 Camera Models: CSE 320 Graphics ProgrammingIsaac Joel RajNo ratings yet
- Class14 Handout Mtse 3010 2018Document14 pagesClass14 Handout Mtse 3010 2018Pragati GuptaNo ratings yet
- Ch. 10: Introduction To Convolution Neural Networks CNN and SystemsDocument69 pagesCh. 10: Introduction To Convolution Neural Networks CNN and SystemsfaisalNo ratings yet
- Convolutional Neural Network: Pham The BaoDocument34 pagesConvolutional Neural Network: Pham The BaoXuân XuânnNo ratings yet
- 8-Image Detection and Segmentation.pptxDocument73 pages8-Image Detection and Segmentation.pptxbiware8359No ratings yet
- Constraint Satisfaction Problems: Basic AlgorithmsDocument57 pagesConstraint Satisfaction Problems: Basic Algorithmssimionesei.loredanaNo ratings yet
- By: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)Document69 pagesBy: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)Sri KrishnaNo ratings yet
- Robotics: Dr. Omar Salah Eldin MahmoudDocument33 pagesRobotics: Dr. Omar Salah Eldin Mahmouddarthvader909No ratings yet
- Dlcvd3l4objects 160803161336Document31 pagesDlcvd3l4objects 160803161336SriramGudimellaNo ratings yet
- Module 3Document26 pagesModule 3PALLAVI RNo ratings yet
- Power Efficient Special Processor Design For Burrows-Wheeler-Transform-Based Short Read Sequence AlignmentDocument4 pagesPower Efficient Special Processor Design For Burrows-Wheeler-Transform-Based Short Read Sequence AlignmentHasif AimanNo ratings yet
- 9.5 Variants of The Basic Convolution Function Function of CNNDocument7 pages9.5 Variants of The Basic Convolution Function Function of CNNsavitaannu07No ratings yet
- Frequency-Selective Signal Sensing With Sub-Nyquist Uniform Sampling SchemeDocument3 pagesFrequency-Selective Signal Sensing With Sub-Nyquist Uniform Sampling SchemeRavi MuthamalaNo ratings yet
- Small Rectangular Patch Antenna: Chair and K.FDocument2 pagesSmall Rectangular Patch Antenna: Chair and K.FOmer KhalidNo ratings yet
- PN and Metal-Semiconductor Junctions: 4.1 Building Blocks of The PN Junction TheoryDocument79 pagesPN and Metal-Semiconductor Junctions: 4.1 Building Blocks of The PN Junction TheoryHayden FongerNo ratings yet
- Lecture 1 Part 2 Channel ModelDocument101 pagesLecture 1 Part 2 Channel Model87krishna331No ratings yet
- Lecture Paola Object DetectionDocument29 pagesLecture Paola Object DetectionMilad24No ratings yet
- Discrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)From EverandDiscrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)No ratings yet
- Improving Efficiency of Self-Care Classification Using PCA and Decision Tree AlgorithmDocument4 pagesImproving Efficiency of Self-Care Classification Using PCA and Decision Tree AlgorithmAllan MoreiraNo ratings yet
- The Implications, Applications, and Benefits of Emerging Technologies in AuditDocument10 pagesThe Implications, Applications, and Benefits of Emerging Technologies in AuditNur Aina Farisha Anuar AliNo ratings yet
- Deeplearning - Ai Deeplearning - AiDocument40 pagesDeeplearning - Ai Deeplearning - AiGeorge HamiltonNo ratings yet
- Machine Learning Tutorial For BeginnersDocument15 pagesMachine Learning Tutorial For BeginnersmanoranjanchoudhuryNo ratings yet
- MTPW DSM-410Document3 pagesMTPW DSM-410goutam1235No ratings yet
- Aarthi - K - Resume - 12 06 2023 15 37 13Document1 pageAarthi - K - Resume - 12 06 2023 15 37 13Aarthi.kNo ratings yet
- Topic: Dimension Reduction With PCA: InstructionsDocument8 pagesTopic: Dimension Reduction With PCA: InstructionsAlesya alesyaNo ratings yet
- QuizDocument5 pagesQuizFatma Zohra OUIRNo ratings yet
- Embedded SystemsDocument34 pagesEmbedded Systems402 ABHINAYA KEERTHINo ratings yet
- Jeppiaar Institute of Technology: Department OF Computer Science and EngineeringDocument24 pagesJeppiaar Institute of Technology: Department OF Computer Science and EngineeringProject 21-22No ratings yet
- 4307-Article Text-8218-1-10-20201228Document16 pages4307-Article Text-8218-1-10-20201228knxticsNo ratings yet
- Driver DrowinessDocument20 pagesDriver DrowinessSruthi ReddyNo ratings yet
- Module 2 NotesDocument24 pagesModule 2 NotesKeshav MishraNo ratings yet
- No - Ntnu Inspera 106583545 37535543Document85 pagesNo - Ntnu Inspera 106583545 37535543Ahmet Sacit SümerNo ratings yet
- DeepFood Food Image Analysis and Dietary Assessment Via Deep ModelDocument13 pagesDeepFood Food Image Analysis and Dietary Assessment Via Deep ModelChâu Huỳnh MinhNo ratings yet
- Thom Ives, PH.DDocument2 pagesThom Ives, PH.DPradeepNo ratings yet
- Hedlin Novian Napitupulu Tugas3Document7 pagesHedlin Novian Napitupulu Tugas3hedlinbarcelona10 hedlinNo ratings yet
- Data Mining P9-SVMDocument30 pagesData Mining P9-SVMHarry SimamoraNo ratings yet
- Classification: Rule Based Classification 0R Holte 1R Holte Decision TreeDocument24 pagesClassification: Rule Based Classification 0R Holte 1R Holte Decision TreeRicky ChandraNo ratings yet
- MathWorks News & NotesDocument21 pagesMathWorks News & Notesfrancisco_gil_51No ratings yet
- Neural NetworksDocument116 pagesNeural NetworksAbhishek NandaNo ratings yet
- Gacovski Z Ed Soft Computing and Machine Learning With PythoDocument380 pagesGacovski Z Ed Soft Computing and Machine Learning With PythoMaxi LunaNo ratings yet
- Master Thesis Topics Behavioral FinanceDocument7 pagesMaster Thesis Topics Behavioral Financecjzarbkef100% (2)
- Tire A PartDocument20 pagesTire A PartKumar HarishNo ratings yet
- Increase Conversions With Performance PlannerDocument8 pagesIncrease Conversions With Performance PlannerMujNo ratings yet
- Brief History of Generative AI - Pre Quiz - Attempt ReviewDocument4 pagesBrief History of Generative AI - Pre Quiz - Attempt Reviewvinay Murakambattu100% (1)
- Donkal, Gita Verma, Gyanendra K. (2018)Document12 pagesDonkal, Gita Verma, Gyanendra K. (2018)soutien104No ratings yet
- Soil Classification and Crop Suggestion Using Machine LearningDocument6 pagesSoil Classification and Crop Suggestion Using Machine LearningIJRASETPublicationsNo ratings yet
- Project - PPT - Design - Phase (2) (1) FinalDocument15 pagesProject - PPT - Design - Phase (2) (1) FinalRaghavendra KusoorNo ratings yet























































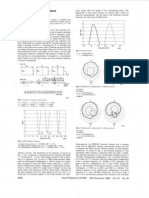
































Download as pdf or txt
You might also like
- individual scores final grade 1 2 3 4 5 6 7 8 Σ: Final Exam DSP May 24, 2018Document45 pagesindividual scores final grade 1 2 3 4 5 6 7 8 Σ: Final Exam DSP May 24, 2018Muhammad Khubaib AtharNo ratings yet
- A Crash Course in Data Science ReviewDocument11 pagesA Crash Course in Data Science ReviewhukaNo ratings yet
- Lecture4 - Convnets For CV SlideDocument65 pagesLecture4 - Convnets For CV SlidemohdharislcpNo ratings yet
- Lec9 - Logic SynthesisDocument26 pagesLec9 - Logic SynthesisPrabhavathi PNo ratings yet
- Visible SurfaceDocument23 pagesVisible SurfacePrachiNo ratings yet
- DL6 - Convnets 4Document57 pagesDL6 - Convnets 4razifa0No ratings yet
- CVlecture 6Document33 pagesCVlecture 6David BNo ratings yet
- Recurrent Neural NetworksDocument25 pagesRecurrent Neural NetworksMehak SmaghNo ratings yet
- Lect5 UWADocument93 pagesLect5 UWAanant_nimkar9243No ratings yet
- High-Performance Hardware For Machine Learning - 0916Document68 pagesHigh-Performance Hardware For Machine Learning - 0916Bill PetrieNo ratings yet
- 3.4 Feature and Distance Standardisation: 66 Chapter 3. Content-Based Retrieval in DepthDocument18 pages3.4 Feature and Distance Standardisation: 66 Chapter 3. Content-Based Retrieval in DepthAnnisa SafitriNo ratings yet
- L7 DetectionDocument54 pagesL7 DetectionAgha KazimNo ratings yet
- The JPEG2000 Image Compression Standard: © V. Sanchez & A. Basu, University of AlbertaDocument30 pagesThe JPEG2000 Image Compression Standard: © V. Sanchez & A. Basu, University of AlbertaAnonymous bIzjNHZeeBNo ratings yet
- Lovato 2013Document5 pagesLovato 2013AjaNo ratings yet
- Global Reg AllocationDocument76 pagesGlobal Reg Allocationjasonjunior390No ratings yet
- FTML - Learning Deep Architectures For AI - Slidesbengio - 2009 PDFDocument87 pagesFTML - Learning Deep Architectures For AI - Slidesbengio - 2009 PDFajgallegoNo ratings yet
- Module 6Document83 pagesModule 6saisivani.ashok2021No ratings yet
- A Novel Ku/Ka Dual-Band Reflectarray Antenna With Arbitrary PolarizationDocument2 pagesA Novel Ku/Ka Dual-Band Reflectarray Antenna With Arbitrary Polarizationpavithra paviNo ratings yet
- Today's Lecture: Repetition and Refinement of Image BasicsDocument36 pagesToday's Lecture: Repetition and Refinement of Image BasicsAli KassabNo ratings yet
- Congestion Driven PlacementDocument25 pagesCongestion Driven PlacementJayanth bemesettyNo ratings yet
- The Transfer Function of The Nth-Order Digital Butterworth Low Pass FilterDocument5 pagesThe Transfer Function of The Nth-Order Digital Butterworth Low Pass FilterNguyen Si PhuocNo ratings yet
- Back Prop in Cortex 2007Document16 pagesBack Prop in Cortex 2007danielNo ratings yet
- Distrebuted: CommunicationDocument8 pagesDistrebuted: Communicationjane turkNo ratings yet
- Heterogeneous Wireless Sensor Networks: ContentDocument6 pagesHeterogeneous Wireless Sensor Networks: ContentSumit KushwahaNo ratings yet
- 03 Convolutional Neural NetworksDocument83 pages03 Convolutional Neural NetworksManish kumawatNo ratings yet
- Class14 - Handout MTSE 3010 2013 PDFDocument14 pagesClass14 - Handout MTSE 3010 2013 PDFManprit SinghNo ratings yet
- Hall ICTPDocument40 pagesHall ICTPapi-3819873100% (1)
- CS60010: Deep Learning: Recurrent Neural NetworkDocument44 pagesCS60010: Deep Learning: Recurrent Neural Networkparantap dansanaNo ratings yet
- Wavelets and Multiresolution: by Dr. Mahua BhattacharyaDocument39 pagesWavelets and Multiresolution: by Dr. Mahua BhattacharyashubhamNo ratings yet
- R-FCN: Object Detection Via Region-Based Fully Convolutional NetworksDocument11 pagesR-FCN: Object Detection Via Region-Based Fully Convolutional NetworksujnzaqNo ratings yet
- Image and Video Super-ResolutionDocument62 pagesImage and Video Super-ResolutionjebemnatoNo ratings yet
- Bandwidth in Octaves Vs Q in Bandpass Filters PDFDocument3 pagesBandwidth in Octaves Vs Q in Bandpass Filters PDFManu GaunaNo ratings yet
- Minsky y PapertDocument77 pagesMinsky y PapertHenrry CastilloNo ratings yet
- Manipulator KinematicsDocument61 pagesManipulator KinematicsHoang Minh ThangNo ratings yet
- Basics of Neural Network and Deep Learning: Presented By: - Subhodeep Seal - 162116559 - CSE 'B' - 3 - 6 - 4/5/2019Document12 pagesBasics of Neural Network and Deep Learning: Presented By: - Subhodeep Seal - 162116559 - CSE 'B' - 3 - 6 - 4/5/2019Animesh PrasadNo ratings yet
- Computer Assisted Image Analysis Lecture 3 - Local OperatorsDocument47 pagesComputer Assisted Image Analysis Lecture 3 - Local OperatorsSome UserNo ratings yet
- Chenming Hu Ch4 SlidesDocument79 pagesChenming Hu Ch4 SlidesNikhil HosurNo ratings yet
- CNN IitkgpDocument112 pagesCNN Iitkgpamrutamhetre9No ratings yet
- Unit 4a - Convolutional Neural NetworksDocument107 pagesUnit 4a - Convolutional Neural NetworksEsha Thaniya MallaNo ratings yet
- Multichannel Variable-Size Convolution For Sentence ClassificationDocument13 pagesMultichannel Variable-Size Convolution For Sentence Classificationakg299No ratings yet
- Convolutional Neural Networks (1) : Geena KimDocument28 pagesConvolutional Neural Networks (1) : Geena KimHuston LAMNo ratings yet
- All Are Worth Words: A Vit Backbone For Diffusion Models: Long Skip ConnectionDocument21 pagesAll Are Worth Words: A Vit Backbone For Diffusion Models: Long Skip Connectionpjnbe6No ratings yet
- LECTURE 11,12 Camera Models: CSE 320 Graphics ProgrammingDocument71 pagesLECTURE 11,12 Camera Models: CSE 320 Graphics ProgrammingIsaac Joel RajNo ratings yet
- Class14 Handout Mtse 3010 2018Document14 pagesClass14 Handout Mtse 3010 2018Pragati GuptaNo ratings yet
- Ch. 10: Introduction To Convolution Neural Networks CNN and SystemsDocument69 pagesCh. 10: Introduction To Convolution Neural Networks CNN and SystemsfaisalNo ratings yet
- Convolutional Neural Network: Pham The BaoDocument34 pagesConvolutional Neural Network: Pham The BaoXuân XuânnNo ratings yet
- 8-Image Detection and Segmentation.pptxDocument73 pages8-Image Detection and Segmentation.pptxbiware8359No ratings yet
- Constraint Satisfaction Problems: Basic AlgorithmsDocument57 pagesConstraint Satisfaction Problems: Basic Algorithmssimionesei.loredanaNo ratings yet
- By: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)Document69 pagesBy: Moataz Al-Haj: Vision Topics - Seminar (University of Haifa)Sri KrishnaNo ratings yet
- Robotics: Dr. Omar Salah Eldin MahmoudDocument33 pagesRobotics: Dr. Omar Salah Eldin Mahmouddarthvader909No ratings yet
- Dlcvd3l4objects 160803161336Document31 pagesDlcvd3l4objects 160803161336SriramGudimellaNo ratings yet
- Module 3Document26 pagesModule 3PALLAVI RNo ratings yet
- Power Efficient Special Processor Design For Burrows-Wheeler-Transform-Based Short Read Sequence AlignmentDocument4 pagesPower Efficient Special Processor Design For Burrows-Wheeler-Transform-Based Short Read Sequence AlignmentHasif AimanNo ratings yet
- 9.5 Variants of The Basic Convolution Function Function of CNNDocument7 pages9.5 Variants of The Basic Convolution Function Function of CNNsavitaannu07No ratings yet
- Frequency-Selective Signal Sensing With Sub-Nyquist Uniform Sampling SchemeDocument3 pagesFrequency-Selective Signal Sensing With Sub-Nyquist Uniform Sampling SchemeRavi MuthamalaNo ratings yet
- Small Rectangular Patch Antenna: Chair and K.FDocument2 pagesSmall Rectangular Patch Antenna: Chair and K.FOmer KhalidNo ratings yet
- PN and Metal-Semiconductor Junctions: 4.1 Building Blocks of The PN Junction TheoryDocument79 pagesPN and Metal-Semiconductor Junctions: 4.1 Building Blocks of The PN Junction TheoryHayden FongerNo ratings yet
- Lecture 1 Part 2 Channel ModelDocument101 pagesLecture 1 Part 2 Channel Model87krishna331No ratings yet
- Lecture Paola Object DetectionDocument29 pagesLecture Paola Object DetectionMilad24No ratings yet
- Discrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)From EverandDiscrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)No ratings yet
- Improving Efficiency of Self-Care Classification Using PCA and Decision Tree AlgorithmDocument4 pagesImproving Efficiency of Self-Care Classification Using PCA and Decision Tree AlgorithmAllan MoreiraNo ratings yet
- The Implications, Applications, and Benefits of Emerging Technologies in AuditDocument10 pagesThe Implications, Applications, and Benefits of Emerging Technologies in AuditNur Aina Farisha Anuar AliNo ratings yet
- Deeplearning - Ai Deeplearning - AiDocument40 pagesDeeplearning - Ai Deeplearning - AiGeorge HamiltonNo ratings yet
- Machine Learning Tutorial For BeginnersDocument15 pagesMachine Learning Tutorial For BeginnersmanoranjanchoudhuryNo ratings yet
- MTPW DSM-410Document3 pagesMTPW DSM-410goutam1235No ratings yet
- Aarthi - K - Resume - 12 06 2023 15 37 13Document1 pageAarthi - K - Resume - 12 06 2023 15 37 13Aarthi.kNo ratings yet
- Topic: Dimension Reduction With PCA: InstructionsDocument8 pagesTopic: Dimension Reduction With PCA: InstructionsAlesya alesyaNo ratings yet
- QuizDocument5 pagesQuizFatma Zohra OUIRNo ratings yet
- Embedded SystemsDocument34 pagesEmbedded Systems402 ABHINAYA KEERTHINo ratings yet
- Jeppiaar Institute of Technology: Department OF Computer Science and EngineeringDocument24 pagesJeppiaar Institute of Technology: Department OF Computer Science and EngineeringProject 21-22No ratings yet
- 4307-Article Text-8218-1-10-20201228Document16 pages4307-Article Text-8218-1-10-20201228knxticsNo ratings yet
- Driver DrowinessDocument20 pagesDriver DrowinessSruthi ReddyNo ratings yet
- Module 2 NotesDocument24 pagesModule 2 NotesKeshav MishraNo ratings yet
- No - Ntnu Inspera 106583545 37535543Document85 pagesNo - Ntnu Inspera 106583545 37535543Ahmet Sacit SümerNo ratings yet
- DeepFood Food Image Analysis and Dietary Assessment Via Deep ModelDocument13 pagesDeepFood Food Image Analysis and Dietary Assessment Via Deep ModelChâu Huỳnh MinhNo ratings yet
- Thom Ives, PH.DDocument2 pagesThom Ives, PH.DPradeepNo ratings yet
- Hedlin Novian Napitupulu Tugas3Document7 pagesHedlin Novian Napitupulu Tugas3hedlinbarcelona10 hedlinNo ratings yet
- Data Mining P9-SVMDocument30 pagesData Mining P9-SVMHarry SimamoraNo ratings yet
- Classification: Rule Based Classification 0R Holte 1R Holte Decision TreeDocument24 pagesClassification: Rule Based Classification 0R Holte 1R Holte Decision TreeRicky ChandraNo ratings yet
- MathWorks News & NotesDocument21 pagesMathWorks News & Notesfrancisco_gil_51No ratings yet
- Neural NetworksDocument116 pagesNeural NetworksAbhishek NandaNo ratings yet
- Gacovski Z Ed Soft Computing and Machine Learning With PythoDocument380 pagesGacovski Z Ed Soft Computing and Machine Learning With PythoMaxi LunaNo ratings yet
- Master Thesis Topics Behavioral FinanceDocument7 pagesMaster Thesis Topics Behavioral Financecjzarbkef100% (2)
- Tire A PartDocument20 pagesTire A PartKumar HarishNo ratings yet
- Increase Conversions With Performance PlannerDocument8 pagesIncrease Conversions With Performance PlannerMujNo ratings yet
- Brief History of Generative AI - Pre Quiz - Attempt ReviewDocument4 pagesBrief History of Generative AI - Pre Quiz - Attempt Reviewvinay Murakambattu100% (1)
- Donkal, Gita Verma, Gyanendra K. (2018)Document12 pagesDonkal, Gita Verma, Gyanendra K. (2018)soutien104No ratings yet
- Soil Classification and Crop Suggestion Using Machine LearningDocument6 pagesSoil Classification and Crop Suggestion Using Machine LearningIJRASETPublicationsNo ratings yet
- Project - PPT - Design - Phase (2) (1) FinalDocument15 pagesProject - PPT - Design - Phase (2) (1) FinalRaghavendra KusoorNo ratings yet