
理解和解释人工智能, 机器学习和深度学习 急诊医学
理解和解释人工智能, 机器学习和深度学习 急诊医学
You might also like
- Artificial Intelligence in HealthcareDocument13 pagesArtificial Intelligence in HealthcareJenner FeijoóNo ratings yet
- Fanuc PMC - Ladder Language - Programming ManualDocument1,508 pagesFanuc PMC - Ladder Language - Programming Manualaxande85% (13)
- Artwork and Signature File For: MAN-00799, "Manual, Selenia AEC Calibration"Document12 pagesArtwork and Signature File For: MAN-00799, "Manual, Selenia AEC Calibration"Esmirna GrullonNo ratings yet
- Artificial Intelligence in Dentistry Current Applications and Future PerspectivesDocument10 pagesArtificial Intelligence in Dentistry Current Applications and Future PerspectivesSkAliHassanNo ratings yet
- SM EU109 WPiO12 Service Manual 2018 03Document92 pagesSM EU109 WPiO12 Service Manual 2018 03Jose PereiraNo ratings yet
- Transportation SystemsDocument32 pagesTransportation SystemsCollenne Kaye-Lie Garcia Uy75% (4)
- Bjro 20190037Document8 pagesBjro 20190037GPTV AdmissionsNo ratings yet
- Information Fusion As An Integrative Cross Cutting Enabler To - 2022 - InformatDocument16 pagesInformation Fusion As An Integrative Cross Cutting Enabler To - 2022 - InformatNguyễn VyNo ratings yet
- Survey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural NetworksDocument29 pagesSurvey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural Networkslenka14126No ratings yet
- Jurinter 1Document12 pagesJurinter 1alvin 08No ratings yet
- Explainable, Domain-Adaptive, and Federated Artificial Intelligence in MedicineDocument18 pagesExplainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine胡浩No ratings yet
- Artificial Intelligence and The Future of The DrugDocument7 pagesArtificial Intelligence and The Future of The DrugSutirtho MukherjiNo ratings yet
- Drug Classification Using Machine LearningDocument5 pagesDrug Classification Using Machine LearningIJRASETPublicationsNo ratings yet
- Explainability and AI in MedicineDocument2 pagesExplainability and AI in MedicineSANDEEP REDDYNo ratings yet
- Report - Artificial Intelligence Applications in MedicineDocument12 pagesReport - Artificial Intelligence Applications in Medicinekababey111No ratings yet
- Artificial Intelligence and Healthcare Regulatory and Legal ConcernsDocument5 pagesArtificial Intelligence and Healthcare Regulatory and Legal ConcernsLingha Dharshan AnparasuNo ratings yet
- MRP 18Document20 pagesMRP 184NM21CS114 PRATHAM S SHETTYNo ratings yet
- AIDocument3 pagesAICher Angel BihagNo ratings yet
- Governance of Automated Image Analysis and Arti Ficial Intelligence Analytics in HealthcareDocument9 pagesGovernance of Automated Image Analysis and Arti Ficial Intelligence Analytics in Healthcareyulita basirNo ratings yet
- Proteomics Clinical Apps - 2020 - Leite - Radiomics and Machine Learning in Oral HealthcareDocument11 pagesProteomics Clinical Apps - 2020 - Leite - Radiomics and Machine Learning in Oral HealthcareHarisankar BNo ratings yet
- SI, 5, Ward 2021Document10 pagesSI, 5, Ward 2021Anubhuti DhanukaNo ratings yet
- Ethical Framework For Harnessing The Power of AI IDocument32 pagesEthical Framework For Harnessing The Power of AI INaveen BhajantriNo ratings yet
- Privacy-Preserving and Verifiable Cloud-Aided Disease Diagnosis and Prediction With Hyperplane Decision-Based ClassifierDocument14 pagesPrivacy-Preserving and Verifiable Cloud-Aided Disease Diagnosis and Prediction With Hyperplane Decision-Based ClassifierBhuvana SenthilkumarNo ratings yet
- Cancer Science - 2020 - Shimizu - Artificial Intelligence in OncologyDocument9 pagesCancer Science - 2020 - Shimizu - Artificial Intelligence in OncologymkarthickcbiNo ratings yet
- Preprints202109 0034 v3Document35 pagesPreprints202109 0034 v3Marwa BayouNo ratings yet
- Smart Hospital-Room and Modern Photonics EmergingDocument15 pagesSmart Hospital-Room and Modern Photonics EmergingSupu VeeturiNo ratings yet
- Artificial Intelligence at Healthcare IndustryDocument6 pagesArtificial Intelligence at Healthcare IndustryIJRASETPublicationsNo ratings yet
- Diabetic Retinopathy Diagnosis Using Multichannel Generative Adversarial Network With SemisupervisionDocument12 pagesDiabetic Retinopathy Diagnosis Using Multichannel Generative Adversarial Network With SemisupervisionGuru VelmathiNo ratings yet
- Survey On Deep Learning For Medical Imaging: December 2018Document14 pagesSurvey On Deep Learning For Medical Imaging: December 2018Edward Ventura BarrientosNo ratings yet
- Futurehealth 9 1 75Document4 pagesFuturehealth 9 1 75christopher.lovejoy1No ratings yet
- 放射学中的持续学习人工智能:实施 原理和早期应用Document16 pages放射学中的持续学习人工智能:实施 原理和早期应用meiwanlanjunNo ratings yet
- Published PDF 6 ANND 119Document9 pagesPublished PDF 6 ANND 119Jikku KuriyanNo ratings yet
- Interpreting Cardiovascular Disease Using Random Forest and Explainable AIDocument12 pagesInterpreting Cardiovascular Disease Using Random Forest and Explainable AIIJRASETPublicationsNo ratings yet
- MET REV1 DOC st13Document9 pagesMET REV1 DOC st13Karnam SirishaNo ratings yet
- NIS MicroprojectDocument10 pagesNIS MicroprojectAmruta AvhaleNo ratings yet
- Artificial Intelligence in Emergency Medicine: Benefits, Risks and RecommendationsDocument8 pagesArtificial Intelligence in Emergency Medicine: Benefits, Risks and RecommendationsmjNo ratings yet
- Artificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaDocument9 pagesArtificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaNBME testNo ratings yet
- Artificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaDocument9 pagesArtificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaNBME testNo ratings yet
- Revista 1Document5 pagesRevista 1Fernando Anyosa TorresNo ratings yet
- KanchanDocument10 pagesKanchanAmruta AvhaleNo ratings yet
- The Potential For Artificial Intelligence in Healthcare PDFDocument5 pagesThe Potential For Artificial Intelligence in Healthcare PDFCleberson MouraNo ratings yet
- Expert Systems - 2023 - Gopalakrishnan - PriMed Private Federated Training and Encrypted Inference On Medical Images inDocument14 pagesExpert Systems - 2023 - Gopalakrishnan - PriMed Private Federated Training and Encrypted Inference On Medical Images inDr. V. Padmavathi Associate ProfessorNo ratings yet
- Heart Disease Prediction Using ML AlgorthimDocument7 pagesHeart Disease Prediction Using ML AlgorthimIJRASETPublicationsNo ratings yet
- Biology: Synsiggan: Generative Adversarial Networks For Synthetic Biomedical Signal GenerationDocument20 pagesBiology: Synsiggan: Generative Adversarial Networks For Synthetic Biomedical Signal GenerationSahil FarhanNo ratings yet
- Letter: Machine Learning and Artificial Intelligence in Neurosurgery: Status, Prospects, and ChallengesDocument2 pagesLetter: Machine Learning and Artificial Intelligence in Neurosurgery: Status, Prospects, and ChallengesJay CurranNo ratings yet
- An Overview of Deep Learning in Medical Imaging Focusing On MRIDocument26 pagesAn Overview of Deep Learning in Medical Imaging Focusing On MRIHammad SattiNo ratings yet
- BMS Cmim 2020 162Document19 pagesBMS Cmim 2020 162Khalid RazaNo ratings yet
- NTTTTTDocument5 pagesNTTTTTDippal IsraniNo ratings yet
- AI in Different FormsDocument2 pagesAI in Different FormsMyla TolentinoNo ratings yet
- 241410Document10 pages241410Aqsa AqqaNo ratings yet
- Multiple Disease Detection Using Machine Learning A SurveyDocument8 pagesMultiple Disease Detection Using Machine Learning A SurveyIJRASETPublicationsNo ratings yet
- Chen Decary 2019 Artificial Intelligence in Healthcare An Essential Guide For Health LeadersDocument9 pagesChen Decary 2019 Artificial Intelligence in Healthcare An Essential Guide For Health LeadersTheja ThushariNo ratings yet
- Computer Science & Engineering: Department ofDocument4 pagesComputer Science & Engineering: Department ofNaman DosiNo ratings yet
- Medical Image Dengan CNNDocument13 pagesMedical Image Dengan CNNarisNo ratings yet
- JPNR - 2022 - S08 - 17Document8 pagesJPNR - 2022 - S08 - 17gta game playNo ratings yet
- Etik 5Document14 pagesEtik 5Putri Hersya MauliaNo ratings yet
- 1 s2.0 S2468785522000271 MainDocument7 pages1 s2.0 S2468785522000271 MainCatalina Padilla TapiaNo ratings yet
- Blockchain-Based Secure Healthcare For Cardio Disease Prediction of ArrhythmiaDocument9 pagesBlockchain-Based Secure Healthcare For Cardio Disease Prediction of ArrhythmiaIJRASETPublicationsNo ratings yet
- Predictive Analytics Healthcare SurgeryDocument3 pagesPredictive Analytics Healthcare SurgerylauNo ratings yet
- 2021 Article 3612Document28 pages2021 Article 3612Elisa LeonteNo ratings yet
- The Significance of Machine Learning in Clinical Disease Diagnosis: A ReviewDocument8 pagesThe Significance of Machine Learning in Clinical Disease Diagnosis: A ReviewrectifiedNo ratings yet
- Machine Learning With Applications in Breast Cancer DetectionDocument10 pagesMachine Learning With Applications in Breast Cancer DetectionIJRASETPublicationsNo ratings yet
- Data Science Project Ideas, Methodology & Python Codes in Health CareFrom EverandData Science Project Ideas, Methodology & Python Codes in Health CareNo ratings yet
- Auto311 - A Confidence-Guided Automated System For Non-Emergency CallsDocument13 pagesAuto311 - A Confidence-Guided Automated System For Non-Emergency CallsmeiwanlanjunNo ratings yet
- AI Music Generation With Lyrical and Melodic CreationDocument2 pagesAI Music Generation With Lyrical and Melodic CreationmeiwanlanjunNo ratings yet
- 云计算和机器学习在精算行业中的应用Document9 pages云计算和机器学习在精算行业中的应用meiwanlanjunNo ratings yet
- 从实验室到病床:深度学习在医疗保健中的旅程Document11 pages从实验室到病床:深度学习在医疗保健中的旅程meiwanlanjunNo ratings yet
- 人工智能(Ai)和深度学习如何改变医疗行业Document11 pages人工智能(Ai)和深度学习如何改变医疗行业meiwanlanjunNo ratings yet
- 人工智能(Ai)与机器学习(Ml)与深度学习(Dl)Document7 pages人工智能(Ai)与机器学习(Ml)与深度学习(Dl)meiwanlanjunNo ratings yet
- 从深度学习到理性机器:哲学史对人工智能未来的启示Document69 pages从深度学习到理性机器:哲学史对人工智能未来的启示meiwanlanjunNo ratings yet
- 基于深度学习的人工智能模型来辅助 甲状腺结节的诊断和治疗:多中心 诊断研究Document13 pages基于深度学习的人工智能模型来辅助 甲状腺结节的诊断和治疗:多中心 诊断研究meiwanlanjunNo ratings yet
- 10个关于机器学习的误解Document8 pages10个关于机器学习的误解meiwanlanjunNo ratings yet
- 可解释的人工智能:理解、 可视化和解释深度学习模型Document11 pages可解释的人工智能:理解、 可视化和解释深度学习模型meiwanlanjunNo ratings yet
- 使用 Python 的语音助手调查Document5 pages使用 Python 的语音助手调查meiwanlanjunNo ratings yet
- 绿色人工智能:深度学习框架的成本是否不同?Document13 pages绿色人工智能:深度学习框架的成本是否不同?meiwanlanjunNo ratings yet
- 放射学中的持续学习人工智能:实施 原理和早期应用Document16 pages放射学中的持续学习人工智能:实施 原理和早期应用meiwanlanjunNo ratings yet
- 大学教学实践杂志 大学教学实践杂志Document26 pages大学教学实践杂志 大学教学实践杂志meiwanlanjunNo ratings yet
- 探索人工智能介导的非正式数字学习 英语(Ai Idle):混合方法调查 中国英语学习者人工智能的采用和体验Document30 pages探索人工智能介导的非正式数字学习 英语(Ai Idle):混合方法调查 中国英语学习者人工智能的采用和体验meiwanlanjunNo ratings yet
- 超越核心的分析:从Python到机器学习Document6 pages超越核心的分析:从Python到机器学习meiwanlanjunNo ratings yet
- Ricardo Vargas Practice-Guide Flow Color En-A0Document1 pageRicardo Vargas Practice-Guide Flow Color En-A0CICERO JOSÉ SANTANANo ratings yet
- Array-In-Java 11Document12 pagesArray-In-Java 11mohit chouhanNo ratings yet
- Notification 004Document2 pagesNotification 004cedcivilfdpcedNo ratings yet
- Office 3 - B - Sprinkler Manual PDFDocument59 pagesOffice 3 - B - Sprinkler Manual PDFabcNo ratings yet
- Textbook - Informatics With PythonDocument55 pagesTextbook - Informatics With PythonKOUSIK BISWASNo ratings yet
- Behaviour of 3D-Panels For Structural Applications Under General Loading: A State-Of-The-ArtDocument10 pagesBehaviour of 3D-Panels For Structural Applications Under General Loading: A State-Of-The-ArtVirat DesaiNo ratings yet
- Harn Frequently Asked Questions (HarnFAQ) (Archive, 19-Sep-2005)Document17 pagesHarn Frequently Asked Questions (HarnFAQ) (Archive, 19-Sep-2005)D.T. Wilson50% (2)
- DIGSI 5 Details - Control and Topology - V1.0 - en-USDocument23 pagesDIGSI 5 Details - Control and Topology - V1.0 - en-USKevin Luis Perez QuirozNo ratings yet
- Summary About NetworkingDocument7 pagesSummary About Networkingdon dali100% (1)
- Case No.3 Questions 1. in Which Ways Do Smart Phones Help These Companies Be More Profitable? To What ExtentDocument2 pagesCase No.3 Questions 1. in Which Ways Do Smart Phones Help These Companies Be More Profitable? To What ExtentGidey Yibeyin Gunner100% (1)
- Instrukciya Po Ekspluatacii Gusenichnogo Ekskavatora Liebherr R 944 C Litronic Operation InstructionDocument282 pagesInstrukciya Po Ekspluatacii Gusenichnogo Ekskavatora Liebherr R 944 C Litronic Operation InstructionВолодимир Кривко100% (1)
- Battery Tester Bt3554-50: Next Battery: No. 2 Pass! Next Battery: No. 3Document4 pagesBattery Tester Bt3554-50: Next Battery: No. 2 Pass! Next Battery: No. 3ppNo ratings yet
- Ba 3-4Document68 pagesBa 3-4Darlene Taniongon100% (2)
- Ashab Kahuf اصحاب کہفDocument21 pagesAshab Kahuf اصحاب کہفKashf e AreejNo ratings yet
- Feasibility Study ExampleDocument3 pagesFeasibility Study Examplewmarcia20050% (2)
- Cobetter Lab Catalog 2017 PDFDocument51 pagesCobetter Lab Catalog 2017 PDFYilun LiuNo ratings yet
- V and Inverted V Curves of Synchronous MotorDocument7 pagesV and Inverted V Curves of Synchronous Motorkarthikeyan249No ratings yet
- Motor Overhaul SOP-DRSSBDocument51 pagesMotor Overhaul SOP-DRSSBKholis JaimonNo ratings yet
- Basic Operations On Signals PDFDocument8 pagesBasic Operations On Signals PDFNaveen DuraNo ratings yet
- Pragnesh Black Book 18Document77 pagesPragnesh Black Book 18Pragnesh PawarNo ratings yet
- Learning Material For Week NumberDocument3 pagesLearning Material For Week NumberNovelyn Degones DuyoganNo ratings yet
- DBMS Ques 2Document11 pagesDBMS Ques 2Mo SaddNo ratings yet
- B550 Pro4Document91 pagesB550 Pro4이호원No ratings yet
- Arif Ihtisham CVDocument2 pagesArif Ihtisham CVIHTISHAM ARIFNo ratings yet
- Recruitment of Peon, Technician and Clerk in Various Disciplines Advertisement No. 88/2020/CHDocument6 pagesRecruitment of Peon, Technician and Clerk in Various Disciplines Advertisement No. 88/2020/CHvipinNo ratings yet
- Media and Information LiteracyDocument15 pagesMedia and Information Literacyنجشو گحوشNo ratings yet







































































































Practice
Understanding and interpreting artificial intelligence,
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
machine learning and deep learning in
Emergency Medicine
Shammi Ramlakhan ,1 Reza Saatchi,2 Lisa Sabir,1 Yardesh Singh,3
Ruby Hughes,4 Olamilekan Shobayo,2 Dale Ventour3
Handling editor Katie Walker
1
INTRODUCTION In addition, AI is facilitating the harnessing of
Emergency Department,
The field of artificial intelligence (AI) has been new technology suitable for ED applications and
Sheffield Children’s Hospital,
Sheffield, UK developing more prominently for over half a research, such as natural language processing,13
2
Electronics and Computer century. Innovations in computer processing power radiomics14 and machine vision.15 Large data repos-
Engineering Research Institute, and analytical capabilities coupled with the avail- itories are being curated and leveraged to explore
Sheffield Hallam University, ability of huge amounts of routinely collected data correlations between patient variables and urgent
Sheffield, UK
3 has meant that AI research and technology devel- care outcomes.10 16 17 Examples of recent studies
Department of Clinical Surgical
Sciences, Faculty of Medical opment has grown exponentially in recent years. with a reasonable rationale for using AI methods
Sciences, The University of The results of this growth can be seen in emer- are summarised in box 1.
the West Indies, St Augustine, gency medicine (EM)—with the Food and Drug However, the promise of AI must be tempered
Trinidad and Tobago Administration approving the first AI software as a with acknowledgement of its evolving nature. This
4
Simulation and Modelling Unit,
medical device for wrist fracture detection in 2018. must be coupled with a realistic assessment of the
Advanced Forming Research
Centre, University of Strathclyde, As of 2021, several more have been approved—for acceptability and quality of current EM applica-
Sheffield, UK triage, X-ray identification of pneumothorax and tions of the technology, especially compared with
notification and triage software for CT images.1 those which have been conventionally derived
Correspondence to Between 2015 and 2021, there were over 500 using traditional statistical methods. Certainly, in
Dr Shammi Ramlakhan, publications indexed in MEDLINE involving AI in other specialties, AI models have not been shown to
Emergency Department,
Sheffield Children’s Hospital, acute and emergency care, with more than half of be superior to those derived by traditional logistic
Sheffield, UK; these published within the last 2 years alone. There regression.18
sramlakhan@nhs.net is recognition that AI technology can potentially The vast majority of AI EM diagnostic and prog-
play an important role in ED decision making, nostic studies use retrospective data, that is, where
Received 3 October 2021
Accepted 29 January 2022 workflow and operations.2–4 However, concerns the data were not collected specifically for the AI
Published Online First with unstructured and often opaque reporting, application (which also raises questions about the
3 March 2022 inappropriate algorithm selection, proxy bias, data use of personal data without explicit consent).
privacy and safety have led to calls for better stan- Importantly, <20% are externally validated in a
dards for undertaking and reporting of research traditional manner,19 with less than half of those
involving AI.5–9 For practising ED clinicians, this externally validated according to AI standards.8 20 21
will facilitate interpretation and understanding Randomised trials are even rarer.
of AI research prior to model deployment or To compound matters, AI models can involve
generalisation. deep neural networks or similarly complex algo-
The aim of this paper is to serve as a primer rithms. The way that these models arrive at a deci-
for clinicians and researchers in understanding sion cannot be interrogated in the clinical setting,
common AI methods as they relate to EM, and to making transparency and acceptability challenging
provide a framework for interpreting AI research. A to clinicians, patients and regulators.22 23
companion paper provides a more detailed explo- Although most published research compares AI
ration of the AI model building pipeline in an EM with a clinician,19 24 this is arguably largely irrel-
context. evant. In EM practice, AI solutions have poten-
tial for secondary benefits by facilitating effective
► http://dx.doi.org/10.1136/ use of clinician time and reducing cognitive load.
emermed-2022-212379 WHAT IS THE PROMISE OF AI FOR EM? This can be through automating non-clinical tasks,
AI technology is seen in multiple aspects of day- allocating resources or prioritising workflows for
to-day living—from email spam filters, voice efficiency. Rather than replacing clinicians or clin-
acti- vated devices, suggestions from ical tasks, AI’s true promise lies in supplementing
© Author(s) (or their or improving on clinicians’ care by harnessing the
employer(s)) 2022. No entertainment streaming services and social media
commercial re-use. See rights to self-driving cars—all are powered by AI of most appropriate human and machine abilities.
and permissions. Published varying complexi- ties. The natural extension
by BMJ. into healthcare, and EM in particular, is expected ARTIFICIAL INTELLIGENCE, MACHINE LEARNING
given the generalist, public-facing nature of the AND DEEP NEURAL NETWORKS
To cite: Ramlakhan S,
Saatchi R, Sabir L,
specialty. Much of the terminology relating to AI can be
et al. Emerg Med J AI has the potential to influence and improve confusing as they are often used interchangeably—
2022;39:380–385. ED triage and outcome prediction,10 11 forecasting at least partly due to popular usage stemming from
and operations,3 diagnosis2 and assessment of
prognosis.12
Practice review
380 Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021-212068
Practice
Box 1 Emergency medicine-relevant studies using
Box 1 Continued
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
artificial intelligence (AI)/machine learning (ML)
algorithms can predict time-series events, and select important
Fracture recognition2 parameters/parameter combinations while handling class
Problem: misinterpretation of limb X-rays by less experienced imbalance. They can therefore predict an outcome at multiple
ED clinicians is not uncommon. Because contemporaneous given time points, making it particularly useful in the ED where
radiologist reporting is not widely available, a system which patients may present at different stages in disease progression.
automatically highlights abnormalities on an image may improve It also allows prediction, in this case, at up to 48 hours
fracture detection. before the onset of severe sepsis.
Why AI? Deep neural networks (DNN) can be trained to Issues: the model demonstrated impressively high area under
identify areas (pixels) on an image where a fracture is likely. A the receiver operating characteristics (AUROC), which was
DNN trained on a large number of images could improve the stable on external validation up to 6 hours before onset of
diagnostic accuracy of a clinician by providing a visual ‘opinion’ severe sepsis. However, performance at 48 hours deteriorated
of the presence of a fracture. This principle can be extended to markedly on external validation, suggesting overfitting
most imaging modalities. (overtraining so
Issues: although the reported DNN-aided accuracy was it fits too closely to training data and is unable to generalise
better than the clinician-only interpretation, this was well for new data). For imbalanced datasets, AUROC is not
assessed using images on which the DNN had been trained. an ideal metric for head-to-head comparison (given that the
The DNN would therefore have had an advantage, as it would false positive rate (FPR) changes minimally due to the high
have ‘seen’ the images before, and biasing direct comparison number of true negatives—see Fig 4). Whether predicting the
with human interpretation. In addition, the clinical significance of onset of severe sepsis translates into improved outcomes still
a missed or delayed fracture diagnoses must be considered— requires evaluation—with further external validation and/or a
with the actual patient benefit of any diagnostic improvement randomised trial.
from AI clearly shown.
Adverse outcomes from COVID-1932
Waiting time (WT) estimation17 Problem: the rapid spread and variable disease progression of
Problem: knowledge of expected WT are helpful for ED patients, SARS-CoV-2 infections have meant that clinicians are working
families and providers. Traditional triage or estimation based on with an unprecedented lack of data, knowledge base or decision
historical time/day WTs are considered crude, and often do not tools for predicting outcomes.
reflect actual time spent waiting. Why AI? The combination of individual patient variables
Why AI? Traditional statistical models derived from small which determine outcome are largely unknown. There is a
datasets/single sites may not capture important predictors and paucity of quality data which considers disease outcomes
are prone to overfitting. AI algorithms can look for important at variable time points and at different stages of illness. In
variables in large multicentre routine datasets and derive order to leverage available, good quality datasets to explore
predictive models which should theoretically give accurate multiple predictor variables and their relative importance, an
estimates of WTs across a network or at single sites. This interpretable ensemble algorithm (Random Forest) can be used.
approach would be more resource efficient than each site This allows various models to be constructed with iterations
developing their own model. of setting, clinical features, laboratory data and temporal
Issues: even within a geographically defined area using measures, thus allowing flexibility in deployment and
a large dataset, estimates of WT from AI models were only interpretability. In this case, the availability of a relatively
accurate within 30 min of the actual wait time between 40% small amount of good quality data to train and externally
and 63% of the time. This may not be sufficient for operational validate a model is preferable to larger poor-quality datasets from
benefit but may be for patient information purposes. External a single institution or region.
validation of models developed for one setting also appear to Issues: as with any AI model, deterministic capability
be less accurate at others, emphasising the importance of robust is lacking. This is compounded by similar lack of
external evaluation and the need for site-specific customisation. pathophysiological knowledge of poor outcomes in COVID-
19, for example, is obesity associated with poor outcomes
Predicting severe sepsis31
due to immunomodulation or simply reduced respiratory capacity
Problem: early recognition and treatment of sepsis
and is there therefore covariance and imputation issues which
improves outcomes. Several sepsis scoring systems are used
impacts on the model? A relatively small dataset makes the
to predict severe sepsis and outcomes. However, these
model potentially unstable, however external validation is
generally cannot leverage trends or correlate individual
reassuring other than for predicting intensive care unit admission
measures and have moderate predictive value. Automated
(likely due to the small numbers). As additional data become
electronic patient record (EPR) sepsis alerting systems using
available, the model performance and parameters may change,
these scores suffer from low specificity and false positives.
and validation in more diverse settings would be warranted.
Why AI? Large datasets with physiological and outcome
variables are available using EPR repositories. Conventional
regression methods may not capture the interdependencies
of individual parameters at specific times as well as relevant science fiction references. Even within the fields of computing
time-trends. The complexity of rationalising multiple variable and data science (not to mention philosophy!), there is no clear
combinations and the volume of data is challenging for human- definition of AI, and this is at least partly attributable to the
designed analysis; however, gradient boosted ensemble ML evolving nature of the technology. Box 2 contains a glossary to
aid in understanding AI terminology and descriptions uses in this
Continued
paper. From a clinician’s perspective, AI can be considered any
Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021- 3
Practice review
human-like intelligence displayed by a machine (computer).
This definition is valid insofar as humans demonstrate
intelligence by
3 Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021-
Practice
Box 2 Glossary of artificial intelligence/machine learning the use of algorithms which can identify patterns in data, learn
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
terms
Algorithm: programming code/pseudocode or formulae which
has been developed for a certain task or process.
Model: a representation of a trained algorithm, that is, an
algorithm which has learnt from data.
Ensemble: combinations of diverse simpler algorithms to
improve overall performance.
Data leakage: where data from outside the training set
manage to leak into the model building (training) process, hence
inappropriately influencing the model and its validation.
Feature: a measurable characteristic of the data or
population of interest (commonly a variable).
Training set: data used by an algorithm to create or fit a model.
Validation set: data used to evaluate the model fit while
tuning hyperparameters, or to select features.
Test set: data used to assess a model’s performance on
unseen data.
Ground truth: analogous to gold standard.
Underfitting: where the model does not learn adequately,
and performs poorly in training and testing. It has a high bias
and low variance.
Overfitting: where the model has learnt the training set too
well, and thus performs well in training but poorly in testing.
It has a low bias and high variance.
Bias: the difference between predicted and actual values.
Variance: how varied the predictions are between different
sets of input.
Parameter: a variable whose value is calculated from the
data and forms part of the model itself. It is independent of the
analyst and cannot be manually adjusted.
Hyperparameter: a setting or weight whose value cannot be
calculated from the data and is external to the model. It can be
tuned by the analyst.
Loss function: a measure of how the predicted output of
each training instance differs from the actual outcome.
Regularisation: modifications to a learning algorithm intended
to reduce its generalisation error but not its training error.33
This
is usually by penalising or limiting weights or early stopping of
training. This can be achieved by algorithms using least absolute
shrinkage and selection operator or Ridge regression.
Decision tree: a type of algorithm which splits data based on
probabilities or attributes in a branching pattern, until an output
is determined.
Support vector machine: a classification algorithm which
separates classes by finding a (hyper)plane of separability
between them.
Naïve Bayes: uses Bayes theorem, that is, how pre-event
variables influences postevent outcome probability. It is naïve as
it assumes all variables are independent.
K-nearest neighbours: an algorithm which predicts an
outcome by finding the k-nearest instances of the input variable
and averaging their outcomes.
Random Forest: a decision-tree-based bagging ensemble
model. It Randomly selects variables/data and builds a Forest of
multiple decision trees.
learning from experience or observations, then use this knowl-
edge to recognise, interpret and take autonomous actions when
faced with similar situations.
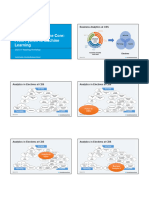
Machine learning (ML) is a subset of AI (figure 1), and involves
Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021- 3
Practice review
algorithms to leverage previously unrecognised variables (or
Figure 1 Relationship between artificial intelligence, machine
learning, artificial neural networks (ANN) and deep learning (deep
neural networks (DNN)).
from these patterns, improve with experience and come to
conclusions when faced with new data—all without being
explic- itly programmed.25 In EM, these data are generally from
images, electronic patient records and ED or population
databases, but can reasonably include any type of data which
can be interpreted by an algorithm. These algorithms usually
consist of program- ming code (written in programming
languages such as Python), mathematical formulae or
combinations of these represented as pseudocode. There are
several ML algorithm repositories/ libraries where researchers
can access ‘off-the-shelf ’ algorithms, which have functions
relevant to specific tasks. An AI algorithm which has ‘learnt’
from data is referred to as a model.
The term artificial neural network is used to describe an
algo- rithm which consists of an input, output and often
intermediate (hidden) layer(s). Data (input variables, also called
features) is fed into the algorithm, which then weighs various
combinations of these variables in the intermediate layer, and
feeds forward an output which is dependent on being activated
at set thresh- olds. As the number of hidden (intermediate)
layers increase, this layer becomes deeper—hence deep
learning (DL) or deep neural networks—and so does its ability
to undertake more complex learning tasks. Output is passed
from one layer to the next and is dependent on multiple inputs
into multiple layers. DL models can also correct their own
errors by backpropagation of data in order to refine and
improve on performance.
The fundamental principle of the subtypes of AI is the
require- ment for learning from data. In ML, this is generally
through either supervised or unsupervised learning. There
are other types such as semi-supervised or reinforcement
learning, which are less common in EM applications.
Supervised learning is used in most ML applications and
involves the use of labelled data (usually a type of variable as
well as outcome of interest) fed to the algorithm so that it can
learn the relationships and differences between the variables
and outcome(s). Conversely, in unsupervised learning,
unlabelled data are provided to the algo- rithm, and it is allowed
to determine patterns and features of the data on its own,
without human input. Unsupervised learning is used primarily
in exploratory (clustering) algorithms, and gener- ally requires
much more data to train than supervised models.
AI OR CONVENTIONAL METHODS?
ML/AI uses some biostatistical methods and measures that will
be familiar to emergency physicians (EP). Some algorithms use
methods based on linear regression, decision trees and Bayesian
reasoning, among others and these can usually be represented
mathematically. Significantly, AI/ML can go further, by using
3 Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021-
Practice
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
Figure 2 Steps in artificial intelligence (AI) model development. Square brackets denote steps which are sometimes described during data
management, model development or evaluation. Feedback and iterations of preceding steps are expected. ML, machine learning. PICO/PECO
- Population/ Intervention (Exposure)/Comparison/Outcome
features), which are different to the human-determined vari-
AI models learn from the data they are given—the algorithms
ables used in traditional statistics. In addition, models built on
can incorporate multiple data inputs and make predictions based
these algorithms can harness non-linear relationships between
on their analysis of the relationships between inputs and outputs.
variables and outcomes, which make them well suited to identi-
Just as an experienced EP who has looked at thousands of ECGs
fying complex or unapparent data inter-relationships. They are
can interpret an ECG at a glance by what would be considered
therefore better at exploratory predictive (regression or classi-
tacit knowledge, an AI/ML model should theoretically be able
fication) modelling with large or computationally heavy data-
to similarly interpret specific ECGs—provided that it has learnt
sets, whereas classic statistical approaches are arguably better
to do so by being trained on a sufficient number of similar
for confirmatory, hypotheses-light analyses with relatively
ECGs for it to discern the relationships between the labelled
smaller datasets. Of note, the process of evaluation and
ECG ‘variables’ and diagnosis. It can do this without explicitly
comparison of different models is almost always based on
learning—for example, it will not ‘learn’ the voltage criteria
conventional statis- tical methods. These methods can often be
for left bundle branch block (LBBB), the electro-pathological
adapted for ML models, commonly using programming code
reasons for the pattern or how it affects ST-elevation myocardial
written specifically to simplify some types of analysis.
infarction (STEMI) diagnosis. It may however, still be able to
Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021- 3
Practice review
Table 1 Key considerations when appraising an EM AI/ML paper
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
Key considerations
Internal Study question 1. Is the study question and aim clearly stated?
validity 2. Is a comparison with the current EM practice baseline and rationale for improvement explicitly stated?
3. Is the use of ML justifiable as opposed to traditional statistical methods?
4. Is the strategy for model development, validation and evaluation clearly described in a clinical EM context?
Baseline data 1. Is sufficient good quality data available? Has a sample size assessment been made?
2. Is data representative of the population and setting in which the model is being deployed?
3. Has data preprocessing been clearly described and handled in an EM applicable manner? Is this reproducible?
4. Have redundant (noisy or collinear) variables been identified and addressed?
5. Has any baseline class imbalance been addressed, and is the method appropriate to the intended EM task?
6. Is Ground Truth valid and reflects the EM ‘gold standard’.
Data split/ 1. Has the approach to data resampling been clearly described? (is a data flow diagram provided)
Resampling 2. Have internal and external validation test sets been clearly identified, and are they as independent as possible?
3. Is the data split clear, rationalised and stratified if appropriate?
4. Has data leakage been avoided?
Algorithm 1. Has the rationale for selecting candidate algorithms been explained in relation to the study aims? Has overfitting been explicitly addressed?
selection 2. Are candidate algorithms appropriate to EM and representative of a range of complexities?
3. Has a variable selection procedure been described? Are chosen variables plausible in the EM context?
4. Have the metrics for model evaluation been defined and rationalised?
Model validation 1. Are the model evaluation metrics appropriate to the task and clinical question? If not, has model performance been reported with a clinically
applicable (EM) metric?
2. Are estimates of model variance reported (from cross-validation/bootstrapping)?
3. Has tuning of model hyperparameters been undertaken, and have the settings been reported?
4. Have model calibration and discrimination been reported, and have these been tuned?
External Reproducibility 1. Has a statement regarding code (and data) availability been included?
validity 2. Are all steps in the model development described in sufficient detail to allow independent replication of the model pipeline?
3. Has interpretability been explicitly and reasonably addressed (eg, by model visualisations)?
Generalisability 1. Has external validation on a geographically (and temporally) independent test set been undertaken?
2. Are performance metrics consistent with the estimates of spread obtained during internal validation?
3. Have the reasons for good or poor performance on external validation been objectively explored?
4. Is the final model suitable for deployment in the ED? Does it have high computational or resource requirements?
5. Has an assessment been made of the potential for exacerbation of bias by the deployed model?
AI, artificial intelligence; EM, emergency medicine; ML, machine learning.
diagnose LBBB or a STEMI. This analogy highlights an often-
STAGES IN DEVELOPING AN AI (MACHINE LEARNING)
ignored aspect of AI—it has no deterministic capability and
MODEL
cannot discern physical, physiological or pathological determi- EM research in AI is almost entirely focused on ML models,
nants or constraints. It can therefore find spurious relationships and therefore the focus henceforth will be on ML, although
which may lead to inappropriate predictions. With large datasets the framework and principles will also apply to almost any
with multiple combinations of input variables, it is not difficult AI model. There is significant variability in the reporting and
to see how ‘statistically’ significant relationships can be derived conduct of ML research, which can make interpretation chal-
purely by chance—so-called ‘p-hacking’. lenging—particularly when some of the models used are by
Another driver for using AI/ML stems from the type of their nature ‘black boxes’.22 An ML model should be developed
data that is being made available. Besides large-scale routinely systematically, with the same structure and clinical focus as any
traditional EM clinical research. The steps in model develop-
collected data, other types of data which were previously rela-
ment from conception to deployment are outlined in figure 2.
tively untapped due to their complexity are well suited for AI
An understanding of model development is useful when inter-
algorithmic analysis. These include diagnostic imaging, labora- preting an AI research paper. More detail on this process is
tory or physiological data and free text from clinical notes. discussed in a linked companion paper26.
Understanding the differences between AI and traditional
statistical methods also comes from appreciating the focus of INTERPRETING AN AI/ML PAPER
the main proponents of AI development—usually in data-rich The ability to interpret and understand ML methodology is
technology and marketing industries—where the performance vitally important to EM clinicians. Key considerations when
of a model takes priority over describing how it works. ML/AI appraising an EM AI/ML paper are summarised in table 1.
is focused on real-life predictions or decisions based on new or There are concerns that AI in clinical medicine is overhyped
dynamic data, whereas traditional statistics is more focused on and suffers from poor methodology, reporting and transparency.9
understanding and articulating data relationships using estab- This is reflected in the findings of systematic reviews which
lished statistical theories and assumptions. This difference is have highlighted incomplete and non-standardised methods
critical—the point of creating an AI model is not to show how and reporting in ML studies.6 18 19 24 27 This has led to calls for
reporting standards to address these shortcomings, with exten-
it performs in vitro, but to deploy it in the real world (clinically
sions to current reporting guidelines 8 28 29 developed along with
or operationally). The ultimate goal therefore, is developing a suggested general20 30 and specialist21 frameworks and checklists
model which can be confidently generalised. being proposed.
3 Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021-
Practice
There are several ML repositories and libraries which allow
researchers to use ML techniques out-of-box using accessible 9 Chen JH, Asch SM. Machine learning and prediction in medicine - beyond the peak of
Emerg Med J: first published as 10.1136/emermed-2021-212068 on 3 March 2022. Downloaded from http://emj.bmj.com/ on May 27, 2022
inflated expectations. N Engl J Med 2017;376:2507–9.
platforms such as R(r-project.org). As with any novel tool, there 10 Kwon J-M, Lee Y, Lee Y, et al. Validation of deep-learning-based triage and acuity
is a risk of inappropriate or clinically disconnected use. In addi- score using a large national dataset. PLoS One 2018;13:e0205836.
tion, internal validation processes are heterogeneous with heuris- 11 Shung DL, Au B, Taylor RA, et al. Validation of a machine learning model
tics and analyst preference regarding algorithms, procedures, that outperforms clinical risk scoring systems for upper gastrointestinal
metrics and validation being common. Because of the interde- bleeding. Gastroenterology 2020;158:160–7.
12 D’Ascenzo F, De Filippo O, Gallone G, et al. Machine learning-based prediction
pendencies of various steps in model development, bias or poor of adverse events following an acute coronary syndrome (praise): a modelling study
choice of processes at any part of data selection, preparation of pooled datasets. Lancet 2021;397:199–207.
or model development will have a knock-on effect, and impact 13 López Pineda A, Ye Y, Visweswaran S, et al. Comparison of machine learning
negatively on the performance of the final model(s). This and classifiers for influenza detection from emergency department free-text reports. J
other model building considerations are explored and expanded Biomed Inform 2015;58:60–9.
14 Rizzo S, Botta F, Raimondi S, et al. Radiomics: the facts and the challenges of image
on in a linked paper, along with discussion of the pitfalls to be analysis. Eur Radiol Exp 2018;2:36.
aware of when interpreting AI model performance. 15 Haque A, Guo M, Alahi A. Towards vision-based smart hospitals: a system for tracking
This paper should provide the reader with conceptual insight and monitoring hand hygiene compliance 2018.
on how AI models are developed and a framework to interpret 16 Walker KJ, Jiarpakdee J, Loupis A, et al. Predicting ambulance patient wait times: a
AI applications as it relates to EM practice and research. There is multicenter derivation and validation study. Ann Emerg Med 2021;78:113–22.
17 Walker K, Jiarpakdee J, Loupis A, et al. Emergency medicine patient wait time
scope for synergism between AI and EM clinicians to maximise multivariable prediction models: a multicentre derivation and validation study. Emerg
efficiency within EDs by using these methods in workflow, Med J 2022;39:386–93.
triage processes, automating certain tasks and diagnostic 18 Christodoulou E, Ma J, Collins GS, et al. A systematic review shows no
applications. There is likely to be an ongoing increase in the performance benefit of machine learning over logistic regression for clinical
number of studies describing these methods. Therefore, the prediction models. J Clin Epidemiol 2019;110:12–22.
19 Kareemi H, Vaillancourt C, Rosenberg H, et al. Machine learning versus usual care
ability to critically appraise these papers and careful awareness for diagnostic and prognostic prediction in the emergency department: a systematic
that despite exciting promise, AI models still have to be review. Acad Emerg Med 2021;28:184–96.
methodologically sound and applicable to real-world practice. 20 Norgeot B, Quer G, Beaulieu-Jones BK, et al. Minimum information about
The true benefit of AI is likely in assisting clinicians rather than clinical artificial intelligence modeling: the MI-CLAIM checklist. Nat Med
replacing them. 2020;26:1320–4.
21 Sengupta PP, Shrestha S, Berthon B, et al. Proposed requirements for cardiovascular
Imaging-Related machine learning evaluation (prime): a checklist: reviewed by the
Twitter Shammi Ramlakhan @shammi_ram American College of cardiology healthcare innovation Council. JACC Cardiovasc
Contributors Conceptualisation, writing original draft: SLR. Writing—review and Imaging 2020;13:2017–35.
editing: all other authors. 22 Price WN. Big data and black-box medical algorithms. Sci Transl Med 2018;10.
doi:10.1126/scitranslmed.aao5333. [Epub ahead of print: 12 12 2018].
Funding The authors have not declared a specific grant for this research from any 23 European Parliament, European Parliamentary Research Service, Scientific Foresight
funding agency in the public, commercial or not-for-profit sectors. Unit. The impact of the General Data Protection Regulation (GDPR) on artificial
Competing interests SLR is a Decision Editor for the EMJ. intelligence: study [Internet], 2020. Available: http://www.europarl.europa.eu/
RegData/etudes/STUD/2020/641530/EPRS_STU(2020)641530_EN.pdf
Patient consent for publication Not applicable. 24 Liu X, Faes L, Kale AU, et al. A comparison of deep learning performance against
Ethics approval This study does not involve human participants. health-care professionals in detecting diseases from medical imaging: a systematic
review and meta-analysis. Lancet Digit Health 2019;1:e271–97.
Provenance and peer review Not commissioned; externally peer reviewed.
25 Koza JR, Bennett FH, Andre D. Automated design of both the topology and sizing
ORCID iDs of analog electrical circuits using genetic programming. In: Gero JS, Sudweeks
Shammi Ramlakhan http://orcid.org/0000-0003-1792-0842 F, eds. Artificial Intelligence in Design ’96. Dordrecht: Springer Netherlands,
Lisa Sabir http://orcid.org/0000-0001-6488-3314 1996: 151–70.
26 Ramlakhan SL, Saatchi R, Sabir L, et al. Building artificial intelligence and machine
learning models : a primer for emergency physicians. Emerg Med J 2022;39:e1
REFERENCES 27 Király FJ, Mateen B, Sonabend R. NIPS - Not Even Wrong? A Systematic Review of
1 Benjamens S, Dhunnoo P, Meskó B. The state of artificial intelligence-based FDA- Empirically Complete Demonstrations of Algorithmic Effectiveness in the Machine
approved medical devices and algorithms: an online database. NPJ Digit Med Learning and Artificial Intelligence Literature. ArXiv181207519 Cs Stat 2018 http://
2020;3:1–8. arxiv.org/abs/1812.07519
2 Lindsey R, Daluiski A, Chopra S, et al. Deep neural network improves fracture 28 Cruz Rivera S, Liu X, Chan A-W, et al. Guidelines for clinical trial protocols for
detection by clinicians. Proc Natl Acad Sci U S A 2018;115:11591–6. interventions involving artificial intelligence: the SPIRIT-AI extension. Nat Med
3 Nas S, Koyuncu M. Emergency department capacity planning: a recurrent neural 2020;26:1351–63.
network and simulation approach. In: Computational and mathematical methods in 29 Liu X, Cruz Rivera S, Moher D, et al. Reporting guidelines for clinical trial reports for
medicine. Hindawi, 2019: 2019. 1–13. interventions involving artificial intelligence: the CONSORT-AI extension. Nat Med
4 Shafaf N, Malek H. Applications of machine learning approaches in emergency 2020;26:1364–74.
medicine; a review article. Arch Acad Emerg Med 2019;7:34. 30 Luo W, Phung D, Tran T, et al. Guidelines for developing and reporting
5 Challen R, Denny J, Pitt M, et al. Artificial intelligence, bias and clinical safety. BMJ machine learning predictive models in biomedical research: a multidisciplinary
Qual Saf 2019;28:231–7. view. J Med Internet Res 2016;18:e323.
6 Yusuf M, Atal I, Li J, et al. Reporting quality of studies using machine learning models 31 Burdick H, Pino E, Gabel-Comeau D, et al. Validation of a machine learning algorithm
for medical diagnosis: a systematic review. BMJ Open 2020;10:e034568. for early severe sepsis prediction: a retrospective study predicting severe sepsis up
7 Vollmer S, Mateen BA, Bohner G, et al. Machine learning and artificial intelligence to 48 h in advance using a diverse dataset from 461 US hospitals. BMC Med Inform
research for patient benefit: 20 critical questions on transparency, replicability, ethics, Decis Mak 2020;20:276.
and effectiveness. BMJ 2020;368:l6927. 32 Jimenez-Solem E, Petersen TS, Hansen C, et al. Developing and validating COVID-19
8 Collins GS, Moons KGM. Reporting of artificial intelligence prediction models. Lancet adverse outcome risk prediction models from a bi-national European cohort of 5594
2019;393:1577–9. patients. Sci Rep 2021;11:3246.
33 Bishop CM. Pattern recognition and machine learning. New York: Springer, 2006: 738.
Ramlakhan S, et al. Emerg Med J 2022;39:380–385. doi:10.1136/emermed-2021- 3
You might also like
- Artificial Intelligence in HealthcareDocument13 pagesArtificial Intelligence in HealthcareJenner FeijoóNo ratings yet
- Fanuc PMC - Ladder Language - Programming ManualDocument1,508 pagesFanuc PMC - Ladder Language - Programming Manualaxande85% (13)
- Artwork and Signature File For: MAN-00799, "Manual, Selenia AEC Calibration"Document12 pagesArtwork and Signature File For: MAN-00799, "Manual, Selenia AEC Calibration"Esmirna GrullonNo ratings yet
- Artificial Intelligence in Dentistry Current Applications and Future PerspectivesDocument10 pagesArtificial Intelligence in Dentistry Current Applications and Future PerspectivesSkAliHassanNo ratings yet
- SM EU109 WPiO12 Service Manual 2018 03Document92 pagesSM EU109 WPiO12 Service Manual 2018 03Jose PereiraNo ratings yet
- Transportation SystemsDocument32 pagesTransportation SystemsCollenne Kaye-Lie Garcia Uy75% (4)
- Bjro 20190037Document8 pagesBjro 20190037GPTV AdmissionsNo ratings yet
- Information Fusion As An Integrative Cross Cutting Enabler To - 2022 - InformatDocument16 pagesInformation Fusion As An Integrative Cross Cutting Enabler To - 2022 - InformatNguyễn VyNo ratings yet
- Survey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural NetworksDocument29 pagesSurvey of Explainable Artificial Intelligence Techniques For Biomedical Imaging With Deep Neural Networkslenka14126No ratings yet
- Jurinter 1Document12 pagesJurinter 1alvin 08No ratings yet
- Explainable, Domain-Adaptive, and Federated Artificial Intelligence in MedicineDocument18 pagesExplainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine胡浩No ratings yet
- Artificial Intelligence and The Future of The DrugDocument7 pagesArtificial Intelligence and The Future of The DrugSutirtho MukherjiNo ratings yet
- Drug Classification Using Machine LearningDocument5 pagesDrug Classification Using Machine LearningIJRASETPublicationsNo ratings yet
- Explainability and AI in MedicineDocument2 pagesExplainability and AI in MedicineSANDEEP REDDYNo ratings yet
- Report - Artificial Intelligence Applications in MedicineDocument12 pagesReport - Artificial Intelligence Applications in Medicinekababey111No ratings yet
- Artificial Intelligence and Healthcare Regulatory and Legal ConcernsDocument5 pagesArtificial Intelligence and Healthcare Regulatory and Legal ConcernsLingha Dharshan AnparasuNo ratings yet
- MRP 18Document20 pagesMRP 184NM21CS114 PRATHAM S SHETTYNo ratings yet
- AIDocument3 pagesAICher Angel BihagNo ratings yet
- Governance of Automated Image Analysis and Arti Ficial Intelligence Analytics in HealthcareDocument9 pagesGovernance of Automated Image Analysis and Arti Ficial Intelligence Analytics in Healthcareyulita basirNo ratings yet
- Proteomics Clinical Apps - 2020 - Leite - Radiomics and Machine Learning in Oral HealthcareDocument11 pagesProteomics Clinical Apps - 2020 - Leite - Radiomics and Machine Learning in Oral HealthcareHarisankar BNo ratings yet
- SI, 5, Ward 2021Document10 pagesSI, 5, Ward 2021Anubhuti DhanukaNo ratings yet
- Ethical Framework For Harnessing The Power of AI IDocument32 pagesEthical Framework For Harnessing The Power of AI INaveen BhajantriNo ratings yet
- Privacy-Preserving and Verifiable Cloud-Aided Disease Diagnosis and Prediction With Hyperplane Decision-Based ClassifierDocument14 pagesPrivacy-Preserving and Verifiable Cloud-Aided Disease Diagnosis and Prediction With Hyperplane Decision-Based ClassifierBhuvana SenthilkumarNo ratings yet
- Cancer Science - 2020 - Shimizu - Artificial Intelligence in OncologyDocument9 pagesCancer Science - 2020 - Shimizu - Artificial Intelligence in OncologymkarthickcbiNo ratings yet
- Preprints202109 0034 v3Document35 pagesPreprints202109 0034 v3Marwa BayouNo ratings yet
- Smart Hospital-Room and Modern Photonics EmergingDocument15 pagesSmart Hospital-Room and Modern Photonics EmergingSupu VeeturiNo ratings yet
- Artificial Intelligence at Healthcare IndustryDocument6 pagesArtificial Intelligence at Healthcare IndustryIJRASETPublicationsNo ratings yet
- Diabetic Retinopathy Diagnosis Using Multichannel Generative Adversarial Network With SemisupervisionDocument12 pagesDiabetic Retinopathy Diagnosis Using Multichannel Generative Adversarial Network With SemisupervisionGuru VelmathiNo ratings yet
- Survey On Deep Learning For Medical Imaging: December 2018Document14 pagesSurvey On Deep Learning For Medical Imaging: December 2018Edward Ventura BarrientosNo ratings yet
- Futurehealth 9 1 75Document4 pagesFuturehealth 9 1 75christopher.lovejoy1No ratings yet
- 放射学中的持续学习人工智能:实施 原理和早期应用Document16 pages放射学中的持续学习人工智能:实施 原理和早期应用meiwanlanjunNo ratings yet
- Published PDF 6 ANND 119Document9 pagesPublished PDF 6 ANND 119Jikku KuriyanNo ratings yet
- Interpreting Cardiovascular Disease Using Random Forest and Explainable AIDocument12 pagesInterpreting Cardiovascular Disease Using Random Forest and Explainable AIIJRASETPublicationsNo ratings yet
- MET REV1 DOC st13Document9 pagesMET REV1 DOC st13Karnam SirishaNo ratings yet
- NIS MicroprojectDocument10 pagesNIS MicroprojectAmruta AvhaleNo ratings yet
- Artificial Intelligence in Emergency Medicine: Benefits, Risks and RecommendationsDocument8 pagesArtificial Intelligence in Emergency Medicine: Benefits, Risks and RecommendationsmjNo ratings yet
- Artificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaDocument9 pagesArtificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaNBME testNo ratings yet
- Artificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaDocument9 pagesArtificial Intelligence in Oncology: Hideyuki Shimizu - Keiichi I. NakayamaNBME testNo ratings yet
- Revista 1Document5 pagesRevista 1Fernando Anyosa TorresNo ratings yet
- KanchanDocument10 pagesKanchanAmruta AvhaleNo ratings yet
- The Potential For Artificial Intelligence in Healthcare PDFDocument5 pagesThe Potential For Artificial Intelligence in Healthcare PDFCleberson MouraNo ratings yet
- Expert Systems - 2023 - Gopalakrishnan - PriMed Private Federated Training and Encrypted Inference On Medical Images inDocument14 pagesExpert Systems - 2023 - Gopalakrishnan - PriMed Private Federated Training and Encrypted Inference On Medical Images inDr. V. Padmavathi Associate ProfessorNo ratings yet
- Heart Disease Prediction Using ML AlgorthimDocument7 pagesHeart Disease Prediction Using ML AlgorthimIJRASETPublicationsNo ratings yet
- Biology: Synsiggan: Generative Adversarial Networks For Synthetic Biomedical Signal GenerationDocument20 pagesBiology: Synsiggan: Generative Adversarial Networks For Synthetic Biomedical Signal GenerationSahil FarhanNo ratings yet
- Letter: Machine Learning and Artificial Intelligence in Neurosurgery: Status, Prospects, and ChallengesDocument2 pagesLetter: Machine Learning and Artificial Intelligence in Neurosurgery: Status, Prospects, and ChallengesJay CurranNo ratings yet
- An Overview of Deep Learning in Medical Imaging Focusing On MRIDocument26 pagesAn Overview of Deep Learning in Medical Imaging Focusing On MRIHammad SattiNo ratings yet
- BMS Cmim 2020 162Document19 pagesBMS Cmim 2020 162Khalid RazaNo ratings yet
- NTTTTTDocument5 pagesNTTTTTDippal IsraniNo ratings yet
- AI in Different FormsDocument2 pagesAI in Different FormsMyla TolentinoNo ratings yet
- 241410Document10 pages241410Aqsa AqqaNo ratings yet
- Multiple Disease Detection Using Machine Learning A SurveyDocument8 pagesMultiple Disease Detection Using Machine Learning A SurveyIJRASETPublicationsNo ratings yet
- Chen Decary 2019 Artificial Intelligence in Healthcare An Essential Guide For Health LeadersDocument9 pagesChen Decary 2019 Artificial Intelligence in Healthcare An Essential Guide For Health LeadersTheja ThushariNo ratings yet
- Computer Science & Engineering: Department ofDocument4 pagesComputer Science & Engineering: Department ofNaman DosiNo ratings yet
- Medical Image Dengan CNNDocument13 pagesMedical Image Dengan CNNarisNo ratings yet
- JPNR - 2022 - S08 - 17Document8 pagesJPNR - 2022 - S08 - 17gta game playNo ratings yet
- Etik 5Document14 pagesEtik 5Putri Hersya MauliaNo ratings yet
- 1 s2.0 S2468785522000271 MainDocument7 pages1 s2.0 S2468785522000271 MainCatalina Padilla TapiaNo ratings yet
- Blockchain-Based Secure Healthcare For Cardio Disease Prediction of ArrhythmiaDocument9 pagesBlockchain-Based Secure Healthcare For Cardio Disease Prediction of ArrhythmiaIJRASETPublicationsNo ratings yet
- Predictive Analytics Healthcare SurgeryDocument3 pagesPredictive Analytics Healthcare SurgerylauNo ratings yet
- 2021 Article 3612Document28 pages2021 Article 3612Elisa LeonteNo ratings yet
- The Significance of Machine Learning in Clinical Disease Diagnosis: A ReviewDocument8 pagesThe Significance of Machine Learning in Clinical Disease Diagnosis: A ReviewrectifiedNo ratings yet
- Machine Learning With Applications in Breast Cancer DetectionDocument10 pagesMachine Learning With Applications in Breast Cancer DetectionIJRASETPublicationsNo ratings yet
- Data Science Project Ideas, Methodology & Python Codes in Health CareFrom EverandData Science Project Ideas, Methodology & Python Codes in Health CareNo ratings yet
- Auto311 - A Confidence-Guided Automated System For Non-Emergency CallsDocument13 pagesAuto311 - A Confidence-Guided Automated System For Non-Emergency CallsmeiwanlanjunNo ratings yet
- AI Music Generation With Lyrical and Melodic CreationDocument2 pagesAI Music Generation With Lyrical and Melodic CreationmeiwanlanjunNo ratings yet
- 云计算和机器学习在精算行业中的应用Document9 pages云计算和机器学习在精算行业中的应用meiwanlanjunNo ratings yet
- 从实验室到病床:深度学习在医疗保健中的旅程Document11 pages从实验室到病床:深度学习在医疗保健中的旅程meiwanlanjunNo ratings yet
- 人工智能(Ai)和深度学习如何改变医疗行业Document11 pages人工智能(Ai)和深度学习如何改变医疗行业meiwanlanjunNo ratings yet
- 人工智能(Ai)与机器学习(Ml)与深度学习(Dl)Document7 pages人工智能(Ai)与机器学习(Ml)与深度学习(Dl)meiwanlanjunNo ratings yet
- 从深度学习到理性机器:哲学史对人工智能未来的启示Document69 pages从深度学习到理性机器:哲学史对人工智能未来的启示meiwanlanjunNo ratings yet
- 基于深度学习的人工智能模型来辅助 甲状腺结节的诊断和治疗:多中心 诊断研究Document13 pages基于深度学习的人工智能模型来辅助 甲状腺结节的诊断和治疗:多中心 诊断研究meiwanlanjunNo ratings yet
- 10个关于机器学习的误解Document8 pages10个关于机器学习的误解meiwanlanjunNo ratings yet
- 可解释的人工智能:理解、 可视化和解释深度学习模型Document11 pages可解释的人工智能:理解、 可视化和解释深度学习模型meiwanlanjunNo ratings yet
- 使用 Python 的语音助手调查Document5 pages使用 Python 的语音助手调查meiwanlanjunNo ratings yet
- 绿色人工智能:深度学习框架的成本是否不同?Document13 pages绿色人工智能:深度学习框架的成本是否不同?meiwanlanjunNo ratings yet
- 放射学中的持续学习人工智能:实施 原理和早期应用Document16 pages放射学中的持续学习人工智能:实施 原理和早期应用meiwanlanjunNo ratings yet
- 大学教学实践杂志 大学教学实践杂志Document26 pages大学教学实践杂志 大学教学实践杂志meiwanlanjunNo ratings yet
- 探索人工智能介导的非正式数字学习 英语(Ai Idle):混合方法调查 中国英语学习者人工智能的采用和体验Document30 pages探索人工智能介导的非正式数字学习 英语(Ai Idle):混合方法调查 中国英语学习者人工智能的采用和体验meiwanlanjunNo ratings yet
- 超越核心的分析:从Python到机器学习Document6 pages超越核心的分析:从Python到机器学习meiwanlanjunNo ratings yet
- Ricardo Vargas Practice-Guide Flow Color En-A0Document1 pageRicardo Vargas Practice-Guide Flow Color En-A0CICERO JOSÉ SANTANANo ratings yet
- Array-In-Java 11Document12 pagesArray-In-Java 11mohit chouhanNo ratings yet
- Notification 004Document2 pagesNotification 004cedcivilfdpcedNo ratings yet
- Office 3 - B - Sprinkler Manual PDFDocument59 pagesOffice 3 - B - Sprinkler Manual PDFabcNo ratings yet
- Textbook - Informatics With PythonDocument55 pagesTextbook - Informatics With PythonKOUSIK BISWASNo ratings yet
- Behaviour of 3D-Panels For Structural Applications Under General Loading: A State-Of-The-ArtDocument10 pagesBehaviour of 3D-Panels For Structural Applications Under General Loading: A State-Of-The-ArtVirat DesaiNo ratings yet
- Harn Frequently Asked Questions (HarnFAQ) (Archive, 19-Sep-2005)Document17 pagesHarn Frequently Asked Questions (HarnFAQ) (Archive, 19-Sep-2005)D.T. Wilson50% (2)
- DIGSI 5 Details - Control and Topology - V1.0 - en-USDocument23 pagesDIGSI 5 Details - Control and Topology - V1.0 - en-USKevin Luis Perez QuirozNo ratings yet
- Summary About NetworkingDocument7 pagesSummary About Networkingdon dali100% (1)
- Case No.3 Questions 1. in Which Ways Do Smart Phones Help These Companies Be More Profitable? To What ExtentDocument2 pagesCase No.3 Questions 1. in Which Ways Do Smart Phones Help These Companies Be More Profitable? To What ExtentGidey Yibeyin Gunner100% (1)
- Instrukciya Po Ekspluatacii Gusenichnogo Ekskavatora Liebherr R 944 C Litronic Operation InstructionDocument282 pagesInstrukciya Po Ekspluatacii Gusenichnogo Ekskavatora Liebherr R 944 C Litronic Operation InstructionВолодимир Кривко100% (1)
- Battery Tester Bt3554-50: Next Battery: No. 2 Pass! Next Battery: No. 3Document4 pagesBattery Tester Bt3554-50: Next Battery: No. 2 Pass! Next Battery: No. 3ppNo ratings yet
- Ba 3-4Document68 pagesBa 3-4Darlene Taniongon100% (2)
- Ashab Kahuf اصحاب کہفDocument21 pagesAshab Kahuf اصحاب کہفKashf e AreejNo ratings yet
- Feasibility Study ExampleDocument3 pagesFeasibility Study Examplewmarcia20050% (2)
- Cobetter Lab Catalog 2017 PDFDocument51 pagesCobetter Lab Catalog 2017 PDFYilun LiuNo ratings yet
- V and Inverted V Curves of Synchronous MotorDocument7 pagesV and Inverted V Curves of Synchronous Motorkarthikeyan249No ratings yet
- Motor Overhaul SOP-DRSSBDocument51 pagesMotor Overhaul SOP-DRSSBKholis JaimonNo ratings yet
- Basic Operations On Signals PDFDocument8 pagesBasic Operations On Signals PDFNaveen DuraNo ratings yet
- Pragnesh Black Book 18Document77 pagesPragnesh Black Book 18Pragnesh PawarNo ratings yet
- Learning Material For Week NumberDocument3 pagesLearning Material For Week NumberNovelyn Degones DuyoganNo ratings yet
- DBMS Ques 2Document11 pagesDBMS Ques 2Mo SaddNo ratings yet
- B550 Pro4Document91 pagesB550 Pro4이호원No ratings yet
- Arif Ihtisham CVDocument2 pagesArif Ihtisham CVIHTISHAM ARIFNo ratings yet
- Recruitment of Peon, Technician and Clerk in Various Disciplines Advertisement No. 88/2020/CHDocument6 pagesRecruitment of Peon, Technician and Clerk in Various Disciplines Advertisement No. 88/2020/CHvipinNo ratings yet
- Media and Information LiteracyDocument15 pagesMedia and Information Literacyنجشو گحوشNo ratings yet