Download as pdf or txt
You might also like
- 在线评价电影Document7 pages在线评价电影g68y8bgq100% (1)
- 欢迎来到Document6 pages欢迎来到afmohuode100% (1)
- 个人陈述:商业研究Document7 pages个人陈述:商业研究h6822n0s100% (1)
- Free Help With Homework QuestionsDocument7 pagesFree Help With Homework Questionsafocbgzdiaavbt100% (1)
- Mind Movies ReviewDocument7 pagesMind Movies Reviewplmgidwlf100% (1)
- Utexas Online HomeworkDocument5 pagesUtexas Online Homeworkewbgfjzh100% (1)
- Si Ganara La Lotería - EnsayoDocument4 pagesSi Ganara La Lotería - Ensayorredknlpd100% (1)
- Homework For Ks1 StudentsDocument4 pagesHomework For Ks1 Studentsafocbgzdiaavbt100% (1)
- Homeworks PRDocument5 pagesHomeworks PRlayfyrfng100% (1)
- 双倍行距参考文献Document12 pages双倍行距参考文献h66h4hd7100% (1)
- Stretch AssignmentDocument12 pagesStretch Assignmenth67qpj8p100% (1)
- 提高作业水平Document13 pages提高作业水平qewqtxfng100% (1)
- 推荐使用helpwriting net进行作业指派Document8 pages推荐使用helpwriting net进行作业指派afmojmkqc100% (1)
- 欢迎来到pretzi!Document6 pages欢迎来到pretzi!t1fif0won1w2100% (1)
- Do My CourseworkDocument10 pagesDo My Courseworkoqmycumpd100% (1)
- 最新电影评论和评分 - 帮助写作网Document5 pages最新电影评论和评分 - 帮助写作网h67qpj8p100% (1)
- Safe Assign是什么?Document9 pagesSafe Assign是什么?g6a9h8wa100% (1)
- Elementary Statistics Homework SolutionsDocument6 pagesElementary Statistics Homework Solutionsafoddlkrjjapgw100% (1)
- Show My Homework Rydon Community CollegeDocument6 pagesShow My Homework Rydon Community Collegeg69pvgv3100% (1)
- We Hate HomeworkDocument5 pagesWe Hate Homeworkh6822n0s100% (1)
- 什么是研究案例?Document6 pages什么是研究案例?g663q32m100% (1)
- 提供专业的论文帮助Document8 pages提供专业的论文帮助afodfebdabeabo100% (1)
- Ensayo Sobre Las Cualidades de Un Buen AmigoDocument7 pagesEnsayo Sobre Las Cualidades de Un Buen Amigoh6822n0s100% (1)
- 研究方法Document5 pages研究方法oqmycumpd100% (1)
- Budget AssignmentDocument8 pagesBudget Assignmentotpkyphjf100% (1)
- How To Get Child To Do His HomeworkDocument8 pagesHow To Get Child To Do His Homeworkiuoqhmwlf100% (1)
- Homework Film OnlineDocument6 pagesHomework Film Onlineafodcgksefjeif100% (1)
- Homework Hotline McpsDocument5 pagesHomework Hotline Mcpsjewypiv0gid3100% (1)
- 在helpwriting net上下订单,轻松完成在线作业!Document4 pages在helpwriting net上下订单,轻松完成在线作业!ctvypwfng100% (1)
- Meiosis Homework WorksheetDocument5 pagesMeiosis Homework Worksheetzoldoiwlf100% (1)
- 极点分配Document8 pages极点分配g69vq34n100% (1)
- Homework Advantages EssayDocument4 pagesHomework Advantages Essaykmkqtohjf100% (1)
- 家庭作业记录Document5 pages家庭作业记录g69x8qp6100% (1)
- Wallpaper HomeworkDocument6 pagesWallpaper Homeworkh66f9hzb100% (1)
- 医学院文书网站Document8 pages医学院文书网站afmadhdar100% (1)
- Wolfram Alpha Math HomeworkDocument7 pagesWolfram Alpha Math Homeworkg69pvgv3100% (1)
- Assign Homework To StudentsDocument4 pagesAssign Homework To Studentsglptgrfng100% (1)
- 欢迎来到assignments discoveryed com!Document7 pages欢迎来到assignments discoveryed com!afoddlkrjjapgw100% (1)
- Historia de Los Ensayos de MuestraDocument5 pagesHistoria de Los Ensayos de Muestraafodfgqbcvkhdo100% (1)
- Free Help With My Math HomeworkDocument5 pagesFree Help With My Math Homeworkh66h4hd7100% (1)
- 电影评论写作Document7 pages电影评论写作g663q32m100% (1)
- Esl Homework IdeasDocument6 pagesEsl Homework Ideascjc3rw4h100% (1)
- 体育作业帮助Document7 pages体育作业帮助ztcjajlpd100% (1)
- Homework Oh Homework Jack Prelutsky PoemDocument6 pagesHomework Oh Homework Jack Prelutsky Poemsnbxduhjf100% (1)
- Order Your English Paper OnDocument69 pagesOrder Your English Paper Ong68qm7t0100% (1)
- 投稿期刊的求职信Document5 pages投稿期刊的求职信afodefcwbtuyfw100% (1)
- I Need Help With My Algebra 1 HomeworkDocument8 pagesI Need Help With My Algebra 1 Homeworkafodfplgrodfca100% (1)
- 数据库作业帮助Document5 pages数据库作业帮助idtmiwmpd100% (1)
- Cómo Escribir Un Ensayo Sobre El Ciclo de NegociosDocument4 pagesCómo Escribir Un Ensayo Sobre El Ciclo de Negociosgycgvjwlf100% (1)
- 幼儿园作业文件夹Document6 pages幼儿园作业文件夹zqzhophjf100% (1)
- Introducing PresentationDocument15 pagesIntroducing Presentationafmoczaee100% (1)
- Experian Credit Report Customer ServiceDocument9 pagesExperian Credit Report Customer Serviceewbs1766100% (1)
- Ask Jeeves Homework HelpDocument8 pagesAsk Jeeves Homework Helphmnqguhjf100% (1)
- Homework and Practice Workbook Holt Algebra 2 AnswersDocument5 pagesHomework and Practice Workbook Holt Algebra 2 Answersafoddlkrjjapgw100% (1)
- 论文结果部分Document5 pages论文结果部分afefhtdof100% (1)
- 网上电影评论Document8 pages网上电影评论afefkkgot100% (1)
- Website That Does Your Homework For YouDocument8 pagesWebsite That Does Your Homework For Youlayfyrfng100% (1)
- 让helpwriting net帮助您完成作业Document6 pages让helpwriting net帮助您完成作业t0pisejag1z3100% (1)
- Higher Physics Homework BookletDocument6 pagesHigher Physics Homework Bookletmfnbqmwlf100% (1)
- 电影评分网站Document6 pages电影评分网站mivbciwlf100% (1)
- 为什么批判性思维很重要Document9 pages为什么批判性思维很重要h6822n0s100% (1)
- 提高批判性思维的另一个词Document7 pages提高批判性思维的另一个词h6822n0s100% (1)
- Ensayos de Matthew ArnoldDocument6 pagesEnsayos de Matthew Arnoldh6822n0s100% (1)
- 关于关键论文的重要性Document6 pages关于关键论文的重要性h6822n0s100% (1)
- 语言个人陈述Document15 pages语言个人陈述h6822n0s100% (1)
- 个人陈述:商业研究Document7 pages个人陈述:商业研究h6822n0s100% (1)
- 打印作业Document6 pages打印作业h6822n0sNo ratings yet
- 解决作业问题的最佳方案Document8 pages解决作业问题的最佳方案h6822n0sNo ratings yet
- Term Paper ThesisDocument52 pagesTerm Paper Thesish6822n0s100% (1)
- Formato de Conclusión para Ensayos PersuasivosDocument5 pagesFormato de Conclusión para Ensayos Persuasivosh6822n0s100% (1)
- Cómo Escribir Un Ensayo Sobre ArmasDocument7 pagesCómo Escribir Un Ensayo Sobre Armash6822n0s100% (1)
- Ensayo Sobre Las Cualidades de Un Buen AmigoDocument7 pagesEnsayo Sobre Las Cualidades de Un Buen Amigoh6822n0s100% (1)
- Cómo Escribir Un Ensayo para La Aplicación UcDocument8 pagesCómo Escribir Un Ensayo para La Aplicación Uch6822n0s100% (2)
- Chemistry Assessed Homework 2.1Document7 pagesChemistry Assessed Homework 2.1h6822n0s100% (1)
- Ensayo de AmistadDocument5 pagesEnsayo de Amistadh6822n0s100% (1)
- Engineering Homework Help FreeDocument6 pagesEngineering Homework Help Freeh6822n0s100% (1)
- Who Can Do My Math Homework For MeDocument7 pagesWho Can Do My Math Homework For Meh6822n0s100% (1)
- Comprar Ensayo Personalizado en LíneaDocument5 pagesComprar Ensayo Personalizado en Líneah6822n0s100% (1)
- Homework Help RatiosDocument9 pagesHomework Help Ratiosh6822n0s100% (1)
- Roman Homework Ideas Ks2Document6 pagesRoman Homework Ideas Ks2h6822n0s100% (1)
- Temas para El Ensayo de LysistrataDocument5 pagesTemas para El Ensayo de Lysistratah6822n0s100% (1)
- Cómo Escribir Un Ensayo Sobre Malcolm XDocument5 pagesCómo Escribir Un Ensayo Sobre Malcolm Xh6822n0s100% (1)
- Pre K Homework CalendarDocument8 pagesPre K Homework Calendarh6822n0s100% (1)
- Math 1za3 HomeworkDocument7 pagesMath 1za3 Homeworkh6822n0s100% (1)
- We Hate HomeworkDocument5 pagesWe Hate Homeworkh6822n0s100% (1)
- Homework Sheets For Year 1Document4 pagesHomework Sheets For Year 1h6822n0s100% (1)
- Ghs Summer HomeworkDocument4 pagesGhs Summer Homeworkh6822n0s100% (1)
- Homework Salesman WikiDocument7 pagesHomework Salesman Wikih6822n0s100% (1)
- Why We Should Have Homework Every NightDocument6 pagesWhy We Should Have Homework Every Nighth6822n0s100% (1)
- Text Homework To StudentsDocument5 pagesText Homework To Studentsh6822n0s100% (1)
- User Manual: DRC8030NDocument19 pagesUser Manual: DRC8030NGerardo LopezNo ratings yet
- Glossary of Terms in Greek Architecture HandoutDocument9 pagesGlossary of Terms in Greek Architecture HandoutJungNo ratings yet
- Mehanics - Statics and DynamicsDocument4 pagesMehanics - Statics and DynamicsVictor John PingkianNo ratings yet
- PSC Funded q2 Fy18 - q1 Fy21Document513 pagesPSC Funded q2 Fy18 - q1 Fy21Salwa KelontongNo ratings yet
- Chef CV TemplateDocument2 pagesChef CV Templatereaz4550No ratings yet
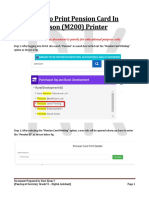
- How To Print Pension CardDocument5 pagesHow To Print Pension Cardm_pa1No ratings yet
- Sports Organization and Managemen1Document8 pagesSports Organization and Managemen1rhiza_babesNo ratings yet
- Effects of Music On The Mind and BrainDocument12 pagesEffects of Music On The Mind and BraininiahmadfahmiNo ratings yet
- Air Supply - All Out of LoveDocument10 pagesAir Supply - All Out of LovepiterNo ratings yet
- Connecting Esp8266-01 To Arduino Uno/ Mega and Blynk: Amith MP CircuitsarduinoDocument17 pagesConnecting Esp8266-01 To Arduino Uno/ Mega and Blynk: Amith MP CircuitsarduinoJulpan Ongly PangaribuanNo ratings yet
- Computer Basics For SeniorsDocument26 pagesComputer Basics For SeniorsMs. 37o?sANo ratings yet
- Permutation & Combination Part 3 of 4Document4 pagesPermutation & Combination Part 3 of 4majji satishNo ratings yet
- Demographic SegmentsDocument5 pagesDemographic SegmentsqueenNo ratings yet
- Adjectives Ed ing-ACTIVITYDocument1 pageAdjectives Ed ing-ACTIVITYCristina Fernández DíazNo ratings yet
- AT10II+User+Manual 2021.8.4 PDFDocument88 pagesAT10II+User+Manual 2021.8.4 PDFMitchell SchnyderNo ratings yet
- 1001 Check MateDocument250 pages1001 Check MateRitvik KrishnanNo ratings yet
- Diagnostic Examination: A. B. C. DDocument6 pagesDiagnostic Examination: A. B. C. DJahred ParasNo ratings yet
- Art ofDocument14 pagesArt ofMegan RobsonNo ratings yet
- 02 Homework 1Document2 pages02 Homework 1Stella LouiseNo ratings yet
- Pivot TableDocument23 pagesPivot TableReyna TamondongNo ratings yet
- 1700 - Phrasal Verbs Test 17 PDFDocument3 pages1700 - Phrasal Verbs Test 17 PDFPhuong Nghi NguyenNo ratings yet
- Star Citizen Helpdesk Project: 3.x InfoDocument46 pagesStar Citizen Helpdesk Project: 3.x Infoegil PettersenNo ratings yet
- Larvicidal Activity of Eichhornia Crassipes Solution Against Aedes Aegypti LarvaeDocument36 pagesLarvicidal Activity of Eichhornia Crassipes Solution Against Aedes Aegypti LarvaeLouise IgnacioNo ratings yet
- Zoom TrainingDocument39 pagesZoom TrainingLobo Solitario100% (3)
- Evermotion Archinteriors PDF Vol 21Document2 pagesEvermotion Archinteriors PDF Vol 21DannyNo ratings yet
- Vogue Korea Media Kit 2022 enDocument6 pagesVogue Korea Media Kit 2022 enFABIOLA VANESSA CARRERA CORT�SNo ratings yet
- Barcoo Independent 290509Document8 pagesBarcoo Independent 290509barcooindependentNo ratings yet
- Apple Inc SWOT AnalysisDocument9 pagesApple Inc SWOT AnalysisRITIKANo ratings yet
- High QB PDFDocument22 pagesHigh QB PDFShikhin GargNo ratings yet
- Unit 4 Test A Grupa 2Document4 pagesUnit 4 Test A Grupa 2Karolina ŚlakNo ratings yet