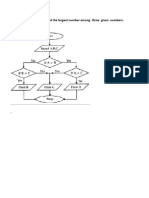
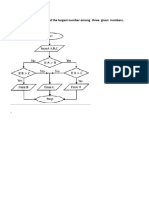
Download as docx, pdf, or txt
You might also like
- Becca Fitzpatrick Crescendo PDF in EnglishDocument4 pagesBecca Fitzpatrick Crescendo PDF in EnglishDiana CristinaNo ratings yet
- New Python Basics AssignmentDocument5 pagesNew Python Basics AssignmentRAHUL SONI0% (1)
- Full Serial Keys of Windows XP All VersionDocument26 pagesFull Serial Keys of Windows XP All VersionArthur MalanovNo ratings yet
- PrograProgramming Manual v6.Xx OP2002 CD2005 GB X41063B Mming Manual v6.Xx OP2002 CD2005 GB X41063B (Jun-2006)Document136 pagesPrograProgramming Manual v6.Xx OP2002 CD2005 GB X41063B Mming Manual v6.Xx OP2002 CD2005 GB X41063B (Jun-2006)ΕΛΙΣΣΑΙΟΣ ΑΝΕΝΟΓΛΟΥ100% (1)
- Cs50 Harvard Edu Extension 2019 Spring Weeks 1-8 Compiled NotesDocument121 pagesCs50 Harvard Edu Extension 2019 Spring Weeks 1-8 Compiled NotesAngad PablayNo ratings yet
- Lecture 3 - CS50x 2024Document16 pagesLecture 3 - CS50x 2024qj4xt8h9pbNo ratings yet
- Itc Lab Report 12: OjectiveDocument5 pagesItc Lab Report 12: OjectiveMuhammad Moaz Awan FastNU0% (1)
- Lecture 3 - CSLDocument12 pagesLecture 3 - CSLAkhil Preetham SNo ratings yet
- MIPS Programming ExamplesDocument7 pagesMIPS Programming ExamplesMichaelJeffNo ratings yet
- This Is CS50x: Last WeekDocument10 pagesThis Is CS50x: Last WeekOmaru NimagaNo ratings yet
- Pps Solved 2019 NovemberDocument16 pagesPps Solved 2019 NovemberH CUBENo ratings yet
- C Assignments 1 of Date 8th October)Document7 pagesC Assignments 1 of Date 8th October)Pratik RathodNo ratings yet
- Strlen - : "Hello World!"Document32 pagesStrlen - : "Hello World!"bhandaviNo ratings yet
- Lecture 1 - CS50x PDFDocument12 pagesLecture 1 - CS50x PDFTahseenNo ratings yet
- Question Solution of CIT-111Document42 pagesQuestion Solution of CIT-111Sadia Islam ShefaNo ratings yet
- STA1007S Lab 3: Plots (II) and Sub-Setting: "Sample"Document10 pagesSTA1007S Lab 3: Plots (II) and Sub-Setting: "Sample"mlunguNo ratings yet
- Robotics Review NotesDocument27 pagesRobotics Review NotesAchionta NandyNo ratings yet
- Lecture 3 - CS50x PDFDocument14 pagesLecture 3 - CS50x PDFEmily SiaNo ratings yet
- PHP Interview Questions and AnswersDocument4 pagesPHP Interview Questions and AnswershirenloveuNo ratings yet
- Answers Final - MergedDocument34 pagesAnswers Final - MergedNEW PREMIUMNo ratings yet
- Python Notes by Jobhunter TeamDocument255 pagesPython Notes by Jobhunter TeamChinamayi ChinmayiNo ratings yet
- WK 4 (1) - 02032024 - 120151Document7 pagesWK 4 (1) - 02032024 - 120151suchinanand07No ratings yet
- Introduction To JavaScriptDocument9 pagesIntroduction To JavaScriptjajajajajaNo ratings yet
- C CodingDocument24 pagesC Codinganurag_gduNo ratings yet
- SoncavabDocument9 pagesSoncavabNigar QurbanovaNo ratings yet
- Exp7 RojidDocument5 pagesExp7 Rojidbhalaninaman7No ratings yet
- Write A C Program To (I.e, Free Up Its Nodes)Document23 pagesWrite A C Program To (I.e, Free Up Its Nodes)Umesh NarayananNo ratings yet
- Laboratory Exercise No9 String FunctionDocument34 pagesLaboratory Exercise No9 String Functionmin minNo ratings yet
- John Llyod EDocument5 pagesJohn Llyod Eetackenneth961No ratings yet
- CF ChetasDocument2 pagesCF Chetasa KhanNo ratings yet
- Chapter7 ArraysDocument26 pagesChapter7 Arrayshisham_eyesNo ratings yet
- Foc and C AssingmentDocument23 pagesFoc and C Assingmentaaryanbhatnagar04No ratings yet
- FunctionsDocument43 pagesFunctionsSimrat MathurNo ratings yet
- C Lab Worksheet 9 C & C++ Array Data Type Part 1Document4 pagesC Lab Worksheet 9 C & C++ Array Data Type Part 1Wil-Ly de la CernaNo ratings yet
- ComputerDocument2 pagesComputerrupaNo ratings yet
- Computer Programming (Unit III & IV) Program For Matrix MultiplicationDocument17 pagesComputer Programming (Unit III & IV) Program For Matrix MultiplicationVasantha KumariNo ratings yet
- Assignment IV - Recursion: Question 2 and 4, You Can Assume The Input Is Always Correct (You Are Not Required To Test It)Document7 pagesAssignment IV - Recursion: Question 2 and 4, You Can Assume The Input Is Always Correct (You Are Not Required To Test It)S.k. HussainNo ratings yet
- Lecture 4Document30 pagesLecture 4sitisusanti31No ratings yet
- Programming Abstractions: Cynthia LeeDocument21 pagesProgramming Abstractions: Cynthia LeeRashul ChutaniNo ratings yet
- 11.intermediate Code Generation Quadruple, Triple, Indirect TripleDocument27 pages11.intermediate Code Generation Quadruple, Triple, Indirect TripleApoorv DiwanNo ratings yet
- Q & A From C, C++, Linux, VxWorksDocument38 pagesQ & A From C, C++, Linux, VxWorksmukeshNo ratings yet
- McqsDocument125 pagesMcqsAbanishAmpNo ratings yet
- Practical 1: TheoryDocument72 pagesPractical 1: TheoryprogrammerNo ratings yet
- Lecture 5 ArraysDocument13 pagesLecture 5 ArraysShahib SkNo ratings yet
- 1.? Smart Keypad - AdvancedDocument2 pages1.? Smart Keypad - Advancedpiyush.vermacs22No ratings yet
- C ModuleDocument12 pagesC Moduleram anjiNo ratings yet
- INFO3063 Assignment #3 Winter 2007: Getting The ParametersDocument17 pagesINFO3063 Assignment #3 Winter 2007: Getting The Parametersapi-3761843No ratings yet
- Assignment 3 Burhanuddin Sikandar Roll No:-1511Document7 pagesAssignment 3 Burhanuddin Sikandar Roll No:-1511Barry AllenNo ratings yet
- Course Notes For Unit 1 of The Udacity Course CS262 Programming LanguagesDocument32 pagesCourse Notes For Unit 1 of The Udacity Course CS262 Programming LanguagesIain McCullochNo ratings yet
- NS 2,3,4 AnsDocument11 pagesNS 2,3,4 AnsShana KaurNo ratings yet
- Foc and C Assingment of RajatDocument32 pagesFoc and C Assingment of Rajataaryanbhatnagar04No ratings yet
- Bba SolutionDocument15 pagesBba Solutiondevi420No ratings yet
- WT Sem 3-2Document64 pagesWT Sem 3-2Navilash RedsNo ratings yet
- Turbo C Interiew Questions With Answers..Document6 pagesTurbo C Interiew Questions With Answers..Priyank PanchalNo ratings yet
- CH-1 AssignmentDocument4 pagesCH-1 AssignmentSimrat MathurNo ratings yet
- Sample Paper 2 2023-24Document7 pagesSample Paper 2 2023-24lucifergamer996No ratings yet
- CryptographyDocument74 pagesCryptographyprogrammerNo ratings yet
- Wta Module 3Document10 pagesWta Module 3sanjaysgryffindorNo ratings yet
- Workshop 1Document5 pagesWorkshop 1Tanminder MaanNo ratings yet
- UntitledDocument51 pagesUntitledAbhishek PatelNo ratings yet
- Array of StringDocument6 pagesArray of StringPrerak KhuntetaNo ratings yet
- C TutorialDocument10 pagesC TutorialhpmaxNo ratings yet
- Concrete SPPPDocument8 pagesConcrete SPPPaliNo ratings yet
- Civil EngineerDocument15 pagesCivil EngineeraliNo ratings yet
- CPN SppsdsDocument10 pagesCPN SppsdsaliNo ratings yet
- LectureDocument5 pagesLecturealiNo ratings yet
- LectureDocument17 pagesLecturealiNo ratings yet
- 003 3.vam-Btc-H1Document1 page003 3.vam-Btc-H1aliNo ratings yet
- 002 2.EnDe-BTC-M15Document1 page002 2.EnDe-BTC-M15aliNo ratings yet
- AQuilDocument9 pagesAQuilaliNo ratings yet
- 4 MEP ClearanceDocument1 page4 MEP ClearancealiNo ratings yet
- 004 4.candle Color BTC H1Document1 page004 4.candle Color BTC H1aliNo ratings yet
- DEsign of Water TankkksaDocument10 pagesDEsign of Water TankkksaaliNo ratings yet
- Construction Project Strategic Risk Management PlanDocument10 pagesConstruction Project Strategic Risk Management PlanaliNo ratings yet
- Masterglenium Sky 504 TdsDocument2 pagesMasterglenium Sky 504 TdsaliNo ratings yet
- Liquid Containing Rectangular Concrete Tank Design ACI 318 14 v10Document39 pagesLiquid Containing Rectangular Concrete Tank Design ACI 318 14 v10aliNo ratings yet
- AttendanceDocument1 pageAttendancealiNo ratings yet
- 4 DesignDocument20 pages4 DesignaliNo ratings yet
- Word FileDocument1 pageWord FilealiNo ratings yet
- Attendance Sheet 18 Oct 23Document1 pageAttendance Sheet 18 Oct 23aliNo ratings yet
- Sika Bonding AgentDocument2 pagesSika Bonding AgentaliNo ratings yet
- ATeco Invoice 2Document18 pagesATeco Invoice 2aliNo ratings yet
- Panametrics 25HP Ultrasonic Precision Thickness Gage 2004Document2 pagesPanametrics 25HP Ultrasonic Precision Thickness Gage 2004Laurence BeasleyNo ratings yet
- CL01, CL02 and CL03 - Class Maintenance - Product Lifecycle Management - SCN WikiDocument4 pagesCL01, CL02 and CL03 - Class Maintenance - Product Lifecycle Management - SCN WikisampathNo ratings yet
- Exception HandlingDocument54 pagesException HandlingSyed SalmanNo ratings yet
- 1991-09 The Computer Paper - BC EditionDocument104 pages1991-09 The Computer Paper - BC EditionthecomputerpaperNo ratings yet
- Linking Notes To Document PropertiesDocument11 pagesLinking Notes To Document Properties816623No ratings yet
- Tutorial 5Document5 pagesTutorial 5sajan gcNo ratings yet
- Hotel-Man Agement Sytem ProjectDocument18 pagesHotel-Man Agement Sytem ProjectgriideoNo ratings yet
- AMIBIOS 3.31aDocument2 pagesAMIBIOS 3.31aBoki1978SrNo ratings yet
- WoodwardDocument4 pagesWoodwarddatastageNo ratings yet
- C++ Programming Lab Manual R18 JNTUHDocument25 pagesC++ Programming Lab Manual R18 JNTUHAEMN M24No ratings yet
- Supply Chain Management: EC-CouncilDocument7 pagesSupply Chain Management: EC-CouncilabhiaryanmibNo ratings yet
- Professional Experience: Authentication SpecialistDocument4 pagesProfessional Experience: Authentication SpecialistTech VisionNo ratings yet
- Chapter 3 - Synchronizing Pthreads: Synchronization in The ATM ServerDocument5 pagesChapter 3 - Synchronizing Pthreads: Synchronization in The ATM Serversavio77No ratings yet
- CRUD Application Using PHP and MysqlDocument11 pagesCRUD Application Using PHP and Mysqlparasmet685No ratings yet
- Assignment 5 AiDocument3 pagesAssignment 5 AiPiyush BhandariNo ratings yet
- Anubhav JainDocument2 pagesAnubhav JainAnubhav JainNo ratings yet
- How To Apply Cell Variant For Columns of ALV in Web Dynpro For ABAPDocument7 pagesHow To Apply Cell Variant For Columns of ALV in Web Dynpro For ABAPingerr_ashNo ratings yet
- Unity - InputDocument5 pagesUnity - InputVictor Monteiro de OliveiraNo ratings yet
- S4H - 1615 Design and Configuration Documentation TemplateDocument5 pagesS4H - 1615 Design and Configuration Documentation TemplateCleber CardosoNo ratings yet
- Trends in Atomistic SimulationsDocument11 pagesTrends in Atomistic SimulationsKol kingNo ratings yet
- Tutorial IITBDocument9 pagesTutorial IITBpiyush_rawat_5No ratings yet
- B&R AutomationDocument236 pagesB&R AutomationrudiharahapNo ratings yet
- Employment Application Form Guide: Accenture Operations Recruitment TeamDocument57 pagesEmployment Application Form Guide: Accenture Operations Recruitment Teamjeevan manjunathNo ratings yet
- Stability in Control SystemsDocument20 pagesStability in Control Systemssamir100% (1)
- Distributed Databases: Solutions To Practice ExercisesDocument4 pagesDistributed Databases: Solutions To Practice ExercisesNUBG GamerNo ratings yet
- An Industrial Training ReportDocument43 pagesAn Industrial Training ReportRutuja PoteNo ratings yet
- Linphone CallDocument3 pagesLinphone CallvitryNo ratings yet