Download as docx, pdf, or txt
You might also like
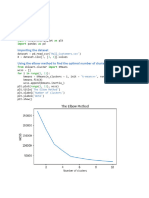
- Subject: ML Name: Priyanshu Gandhi Date: 10/4/21 Expt. No.: 9 Roll No.: C008 Title: Clustering Implementation in PythonDocument7 pagesSubject: ML Name: Priyanshu Gandhi Date: 10/4/21 Expt. No.: 9 Roll No.: C008 Title: Clustering Implementation in PythonKartik KatekarNo ratings yet
- Week 8. GMMDocument11 pagesWeek 8. GMMrevaldianggaraNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- 21BEC505 Exp2Document7 pages21BEC505 Exp2jayNo ratings yet
- Experiment No 7Document4 pagesExperiment No 7Mayur PawadeNo ratings yet
- DocumentDocument4 pagesDocumentkedaw93371No ratings yet
- K Means ClusteringDocument11 pagesK Means ClusteringShobha Kumari ChoudharyNo ratings yet
- Ml-A2 CodeDocument5 pagesMl-A2 CodeBECOC362Atharva UtekarNo ratings yet
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- ML0101EN Clus K Means Customer Seg Py v1Document8 pagesML0101EN Clus K Means Customer Seg Py v1Rajat Solanki100% (1)
- ML2 Practical ListDocument80 pagesML2 Practical ListYash AminNo ratings yet
- 2.3 Aiml RishitDocument7 pages2.3 Aiml Rishitheex.prosNo ratings yet
- Week 8. K-MeansDocument7 pagesWeek 8. K-MeansrevaldianggaraNo ratings yet
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Implementing Custom Randomsearchcv: 'Red' 'Blue'Document1 pageImplementing Custom Randomsearchcv: 'Red' 'Blue'Tayub khan.ANo ratings yet
- K-Means in Python - SolutionDocument6 pagesK-Means in Python - SolutionRodrigo ViolanteNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- Bigdata External Programs 181801120034Document4 pagesBigdata External Programs 181801120034agoyal5145No ratings yet
- DS - ML - 7 - 60019210046 1Document6 pagesDS - ML - 7 - 60019210046 1Deep PrajapatiNo ratings yet
- Untitled59: 1 Decision TreeDocument2 pagesUntitled59: 1 Decision TreeDEV RISHI 20BCE0965No ratings yet
- ML Minors Exp7Document6 pagesML Minors Exp7Deep PrajapatiNo ratings yet
- K MeansDocument3 pagesK Meanslyna mebarka BENYAKOUBNo ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- Tutorial 6Document8 pagesTutorial 6POEASONo ratings yet
- Classification Algorithm Python Code 1567761638Document4 pagesClassification Algorithm Python Code 1567761638Awanit KumarNo ratings yet
- Intro Cluster Problem PythonDocument13 pagesIntro Cluster Problem Pythongabrielrichter2021No ratings yet
- Exp 4Document10 pagesExp 4jayNo ratings yet
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- Tugas 3 672020133Document3 pagesTugas 3 672020133HrCreative YopiNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- Lab Experiment No. 4 Name: Dhruv Jain SAP ID: 60004190030 Div/Batch: A/A2 AimDocument9 pagesLab Experiment No. 4 Name: Dhruv Jain SAP ID: 60004190030 Div/Batch: A/A2 AimDhruv jainNo ratings yet
- Iris ClaasificationDocument1 pageIris ClaasificationMohammad Faysal KhanNo ratings yet
- sectionSVM PDFDocument10 pagessectionSVM PDFArif Rahman HakimNo ratings yet
- Solution First Point ML-HW4Document6 pagesSolution First Point ML-HW4Juan Sebastian Otálora Montenegro100% (1)
- 05 Logistic - RegressionDocument7 pages05 Logistic - RegressionadalinaNo ratings yet
- Assignment 4 On Clustering TechniquesDocument2 pagesAssignment 4 On Clustering Techniques06–Yash BhusalNo ratings yet
- Task 6Document8 pagesTask 6gauravpatel5436No ratings yet
- Kabir Khan 1147 - 4Document4 pagesKabir Khan 1147 - 4mohammed.ibrahimdurrani.bscs-2020bNo ratings yet
- Computational Techniques in Statistics: Exercise 1Document5 pagesComputational Techniques in Statistics: Exercise 1وجدان الشداديNo ratings yet
- DM Slip SolutionsDocument24 pagesDM Slip Solutions09.Khadija Gharatkar100% (1)
- Assignment 2Document1 pageAssignment 2estebandgonoNo ratings yet
- LAB-4 ReportDocument21 pagesLAB-4 Reportjithentar.cs21No ratings yet
- Seminar 10Document3 pagesSeminar 10Nishad AhamedNo ratings yet
- NguyenTrungThinh BT3.3Document5 pagesNguyenTrungThinh BT3.3Nguyen Trung ThinhNo ratings yet
- ML Lab6Document4 pagesML Lab6Pankaj MandloiNo ratings yet
- 8 NaiveBayesDocument2 pages8 NaiveBayesvoxorit295No ratings yet
- K Means ClusteringDocument2 pagesK Means Clusteringmmmoneyyyy2No ratings yet
- Exp 4 and 6Document7 pagesExp 4 and 6user NewNo ratings yet
- Unit2 ML ProgramsDocument7 pagesUnit2 ML Programsdiroja5648No ratings yet
- AI42001 Practice 2Document4 pagesAI42001 Practice 2rohan kalidindiNo ratings yet
- K - NN Learning-30 AprilDocument2 pagesK - NN Learning-30 Aprilanimehv5500No ratings yet
- Raj Practical File (ML)Document16 pagesRaj Practical File (ML)RajNo ratings yet
- 09.unsupervised LearningDocument50 pages09.unsupervised LearningJuan Zamora IbacacheNo ratings yet
- K Means AlgorithmDocument6 pagesK Means AlgorithmAsir Mosaddek SakibNo ratings yet
- SL Classification For Data Science..Document4 pagesSL Classification For Data Science..shivaybhargava33No ratings yet
- JAVIER KMeans Clustering Jupyter NotebookDocument7 pagesJAVIER KMeans Clustering Jupyter NotebookAlleah LayloNo ratings yet
- Unit 3Document28 pagesUnit 3Arslan MansooriNo ratings yet
- Eswd AssignmentDocument10 pagesEswd AssignmentArslan MansooriNo ratings yet
- PyCaret RegressionDocument13 pagesPyCaret RegressionArslan MansooriNo ratings yet
- Motion DetectionDocument5 pagesMotion DetectionArslan MansooriNo ratings yet
- De Lab WorksheetDocument5 pagesDe Lab WorksheetArslan MansooriNo ratings yet
- Design Automatic Street Light Using LDRDocument4 pagesDesign Automatic Street Light Using LDRArslan MansooriNo ratings yet
- Experiment Title: 3.2Document4 pagesExperiment Title: 3.2Arslan MansooriNo ratings yet
- Experiment Title: 3.1Document4 pagesExperiment Title: 3.1Arslan MansooriNo ratings yet
- Anand Kumar SN S Complete Notes On Signals and SystemsDocument64 pagesAnand Kumar SN S Complete Notes On Signals and Systemsgokunair103No ratings yet
- DCS 1Document17 pagesDCS 1Anna BrookeNo ratings yet
- Linear ProgrammingDocument70 pagesLinear ProgrammingAditya Risqi PratamaNo ratings yet
- Perceptron - WikipediaDocument9 pagesPerceptron - WikipediaNoles PandeNo ratings yet
- Phasor EstimationDocument77 pagesPhasor Estimationajmeriyash.13No ratings yet
- Iterative Reweighted Least Squares 12 PDFDocument14 pagesIterative Reweighted Least Squares 12 PDFVanidevi ManiNo ratings yet
- Topic: Dimension Reduction With PCA: InstructionsDocument8 pagesTopic: Dimension Reduction With PCA: InstructionsAlesya alesyaNo ratings yet
- Solutions - Chap10Document22 pagesSolutions - Chap10julianaNo ratings yet
- 06 Elements of DP Fibonacci NumbersDocument14 pages06 Elements of DP Fibonacci NumbersassdNo ratings yet
- DSP Question BankDocument5 pagesDSP Question BankhksaifeeNo ratings yet
- Fast Radix-2 Algorithm For The Discrete Hartley Transform of Type IIDocument3 pagesFast Radix-2 Algorithm For The Discrete Hartley Transform of Type IIManish BansalNo ratings yet
- Ada Lab Manual: Design and Analysis of Algorithms LaboratoryDocument48 pagesAda Lab Manual: Design and Analysis of Algorithms LaboratoryMunavalli Matt K SNo ratings yet
- Ultrasound Image Segmentation by Using Wavelet Transform and Self-Organizing Neural NetworkDocument9 pagesUltrasound Image Segmentation by Using Wavelet Transform and Self-Organizing Neural Networkyogesh_gaidhane3743No ratings yet
- Extra Tut 5 SolsDocument4 pagesExtra Tut 5 SolsNOMPUMELELO MTHETHWANo ratings yet
- Volume 2Document696 pagesVolume 2Kirti Mittal100% (1)
- Application of Greedy MethodDocument26 pagesApplication of Greedy MethodTech_MXNo ratings yet
- Assignment 3 Warehouse Saturdays ClassDocument3 pagesAssignment 3 Warehouse Saturdays ClassNguyễn QuỳnhNo ratings yet
- CH 6 - Application of InteroplationsDocument19 pagesCH 6 - Application of InteroplationsLëmä FeyTitaNo ratings yet
- CH332 L3 Emin PDFDocument17 pagesCH332 L3 Emin PDFkdsarodeNo ratings yet
- Ep-8 (B) Binomial Theorem QuestionsDocument46 pagesEp-8 (B) Binomial Theorem QuestionsDHANESHWAR MAHATONo ratings yet
- Laplace Transform For Systems of ODE PDFDocument317 pagesLaplace Transform For Systems of ODE PDFrandoNo ratings yet
- P.E.S. College of Engineering, Mandya - 571 401Document2 pagesP.E.S. College of Engineering, Mandya - 571 401Sohan G NaikNo ratings yet
- Artificial Intelligence QuestionsDocument15 pagesArtificial Intelligence QuestionsvigneshNo ratings yet
- UnSupervised LearningDocument40 pagesUnSupervised LearningPandu KNo ratings yet
- Breadth First Search: BFS PseudocodeDocument9 pagesBreadth First Search: BFS PseudocodeAchmad Hadzami SetiawanNo ratings yet
- Module 3 - Polynomial Functions PDFDocument26 pagesModule 3 - Polynomial Functions PDFanamarietuvNo ratings yet
- Chapter10 (Error Detection and Correction)Document48 pagesChapter10 (Error Detection and Correction)Rahil HussainNo ratings yet
- Ch01 SolutionsDocument7 pagesCh01 SolutionsАлекс БогдановNo ratings yet
- 10 GaDocument20 pages10 GaNoor WaleedNo ratings yet
- CSCI 3110 Assignment 6 Solutions: n ≈ n nlogn=O n n − ϵ where ϵ = (log − logDocument4 pagesCSCI 3110 Assignment 6 Solutions: n ≈ n nlogn=O n n − ϵ where ϵ = (log − logRicardo BrunoNo ratings yet