
ML PDF1
ML PDF1
You might also like
- Principles of TurbomachineryDocument276 pagesPrinciples of TurbomachineryNavneet PAndeNo ratings yet
- 14M B9J Electric Schematic - B9J1-1272Document34 pages14M B9J Electric Schematic - B9J1-1272Muhammad IbrahimNo ratings yet
- ML PDFDocument7 pagesML PDFmanchal2204No ratings yet
- DMT BATCH-4 (Project Report)Document9 pagesDMT BATCH-4 (Project Report)Jaswanth PrabhasNo ratings yet
- A Hybrid Recommender System For Recommending Smartphones ToDocument24 pagesA Hybrid Recommender System For Recommending Smartphones ToSabri GOCERNo ratings yet
- Recommendation Model Using User Reviews and Deep Learning ApproachDocument5 pagesRecommendation Model Using User Reviews and Deep Learning ApproachANIMIXNo ratings yet
- Background InformationDocument9 pagesBackground InformationMwanthi kimuyuNo ratings yet
- 4704-Article Text-9006-1-10-20201231Document13 pages4704-Article Text-9006-1-10-20201231cagan.ulNo ratings yet
- Movie Recommendation System: Synopsis For Project (KCA 353)Document17 pagesMovie Recommendation System: Synopsis For Project (KCA 353)Rishabh MishraNo ratings yet
- Research Article: A Sentiment-Enhanced Hybrid Recommender System For Movie Recommendation: A Big Data Analytics FrameworkDocument10 pagesResearch Article: A Sentiment-Enhanced Hybrid Recommender System For Movie Recommendation: A Big Data Analytics Frameworkviju001No ratings yet
- Sensors 22 04904Document22 pagesSensors 22 04904Miza RaiNo ratings yet
- IJIRMPS Satish SirDocument8 pagesIJIRMPS Satish SirHatim HusainNo ratings yet
- ReportDocument20 pagesReports8240644No ratings yet
- Symmetry: Design of An Unsupervised Machine Learning-Based Movie Recommender SystemDocument27 pagesSymmetry: Design of An Unsupervised Machine Learning-Based Movie Recommender SystemMIGUEL ANGEL PICO LEALNo ratings yet
- MultiAttributed Hybrid IISC Banglore CBP RBW Jan 2014Document6 pagesMultiAttributed Hybrid IISC Banglore CBP RBW Jan 2014R.B.WaghNo ratings yet
- ITE2013 Big Data AnalyticsDocument13 pagesITE2013 Big Data AnalyticsSUKANT JHA 19BIT0359No ratings yet
- FINAL Document KalyaniDocument80 pagesFINAL Document KalyaniDNR PROJECTSNo ratings yet
- ReportDocument16 pagesReportUddesh BhagatNo ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208STRANGER MANNo ratings yet
- 10 1016@j Simpat 2020 102198Document17 pages10 1016@j Simpat 2020 102198Shrijan SinghNo ratings yet
- AakarshDocument10 pagesAakarshSam boiNo ratings yet
- Recommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyDocument10 pagesRecommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyIJRASETPublicationsNo ratings yet
- CBP RBW Ieee Conecct2014 1569825549Document6 pagesCBP RBW Ieee Conecct2014 1569825549R.B.WaghNo ratings yet
- Implementing A Movie Recommendation System in Machine Learning Using Hybrid ApproachDocument5 pagesImplementing A Movie Recommendation System in Machine Learning Using Hybrid ApproachIJRASETPublicationsNo ratings yet
- Query Extraction Using Filtering Technique Over The Stored Data in The DatabaseDocument5 pagesQuery Extraction Using Filtering Technique Over The Stored Data in The DatabaseRahul SharmaNo ratings yet
- Report Movie RecommendationDocument49 pagesReport Movie RecommendationChris Sosa JacobNo ratings yet
- Comp Sci - IJCSE - A Hybrid Recommender - AkshitaDocument8 pagesComp Sci - IJCSE - A Hybrid Recommender - Akshitaiaset123No ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208Vaibhav PatilNo ratings yet
- Building A Movie Recommendation System Using Collaborative Filtering With TF-IDF-IJRASETDocument13 pagesBuilding A Movie Recommendation System Using Collaborative Filtering With TF-IDF-IJRASETIJRASETPublicationsNo ratings yet
- Movie Recommendation Project ReportDocument9 pagesMovie Recommendation Project Reports8240644No ratings yet
- Survey On Kernel Optimization Based Enhanced Preference Learning For Online Movie RecommendationDocument8 pagesSurvey On Kernel Optimization Based Enhanced Preference Learning For Online Movie RecommendationEditor IJTSRDNo ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208bawec59510No ratings yet
- Moviegen: A Movie Recommendation System: Eyrun A. Eyjolfsdottir, Gaurangi Tilak, Nan LiDocument10 pagesMoviegen: A Movie Recommendation System: Eyrun A. Eyjolfsdottir, Gaurangi Tilak, Nan LiMul AdiNo ratings yet
- MediaRec A Hybrid Media Recommender SystemDocument8 pagesMediaRec A Hybrid Media Recommender SystemIJRASETPublicationsNo ratings yet
- Movie Recommdation ReportDocument10 pagesMovie Recommdation ReportPRATEEKNo ratings yet
- An Efficient Movie Recommendation Algorithm Based On Improved K CliqueDocument15 pagesAn Efficient Movie Recommendation Algorithm Based On Improved K CliquekarandhanodiyaNo ratings yet
- A Comprehensive Review On Non-Neural Networks Collaborative Filtering Recommendation SystemsDocument29 pagesA Comprehensive Review On Non-Neural Networks Collaborative Filtering Recommendation Systemsjayanthi jaiNo ratings yet
- Mean-Reversion Based Hybrid Movie Recommender System Using Collaborative and Content-Based Filtering MethodsDocument18 pagesMean-Reversion Based Hybrid Movie Recommender System Using Collaborative and Content-Based Filtering MethodsAmaan NasserNo ratings yet
- Movie Recommendation System Using TF-IDF Vectorization and Cosine SimilarityDocument9 pagesMovie Recommendation System Using TF-IDF Vectorization and Cosine SimilarityIJRASETPublicationsNo ratings yet
- A Systematic Literature Survey On Recommendation SystemDocument15 pagesA Systematic Literature Survey On Recommendation SystemIJRASETPublicationsNo ratings yet
- Personality-Based Active Learning For Collaborative Filtering Recommender SystemsDocument12 pagesPersonality-Based Active Learning For Collaborative Filtering Recommender Systemsmonamona69No ratings yet
- A Literature Review and Classification of Recommender Systems Research PDFDocument7 pagesA Literature Review and Classification of Recommender Systems Research PDFea6qsxqdNo ratings yet
- AMORE: Design and Implementation of A Commercial-Strength Parallel Hybrid Movie Recommendation EngineDocument26 pagesAMORE: Design and Implementation of A Commercial-Strength Parallel Hybrid Movie Recommendation EngineLaique SantanaNo ratings yet
- A Hybrid Approach For Personalized Recommender System Using Weighted TFIDF On RSS ContentsDocument11 pagesA Hybrid Approach For Personalized Recommender System Using Weighted TFIDF On RSS ContentsATSNo ratings yet
- Build A Recommendation System For Movies or BooksDocument6 pagesBuild A Recommendation System For Movies or BooksIJRASETPublicationsNo ratings yet
- Evaluating-ToIS-20041Document49 pagesEvaluating-ToIS-20041multe123No ratings yet
- Movie Recommendation System Using Content-Based Filtering With Heroku DeploymentDocument8 pagesMovie Recommendation System Using Content-Based Filtering With Heroku DeploymentIJRASETPublicationsNo ratings yet
- Recommender System Based On Customer Behaviour For Retail StoresDocument12 pagesRecommender System Based On Customer Behaviour For Retail StoresPriscila GuayasamínNo ratings yet
- Movie Recommendation SystemDocument24 pagesMovie Recommendation Systemcyclop910No ratings yet
- Using Feature Selection Methods To Discover Common Users' Preferences For Online Recommender SystemsDocument9 pagesUsing Feature Selection Methods To Discover Common Users' Preferences For Online Recommender SystemsHendra StoryNo ratings yet
- EAI Endorsed TransactionsDocument9 pagesEAI Endorsed TransactionsVALENTIN BELMUT ANTUNEZ GONZALESNo ratings yet
- A Survey of Web Service Recommendation Methods-28660Document5 pagesA Survey of Web Service Recommendation Methods-28660Editor IJAERDNo ratings yet
- A Survey For Personalized Item Based Recommendation SystemDocument3 pagesA Survey For Personalized Item Based Recommendation SystemInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Recommender System Using Collaborative Filtering and Demographic Characteristics of UsersDocument7 pagesRecommender System Using Collaborative Filtering and Demographic Characteristics of UsersEditor IJRITCCNo ratings yet
- MdocDocument32 pagesMdocjyothi bhavaniNo ratings yet
- Technical PaperDocument6 pagesTechnical PaperKunal salunkheNo ratings yet
- Movie Recommendation System Using Machine LearningDocument6 pagesMovie Recommendation System Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Deep Autoencoder For Recommender Systems: Parameter Influence AnalysisDocument11 pagesDeep Autoencoder For Recommender Systems: Parameter Influence AnalysisĐứcĐiệuNo ratings yet
- Item-Based Collaborative Filtering Recommendation Algorithms - Highlighted PaperDocument11 pagesItem-Based Collaborative Filtering Recommendation Algorithms - Highlighted PaperShubham ChaudharyNo ratings yet
- Minor ProjectDocument15 pagesMinor Projectharmeetpics1607No ratings yet
- Efficient Scalable Job RecoDocument16 pagesEfficient Scalable Job RecoLuckygirl JyothiNo ratings yet
- Applied Predictive Modeling: An Overview of Applied Predictive ModelingFrom EverandApplied Predictive Modeling: An Overview of Applied Predictive ModelingNo ratings yet
- The Impact of Sugar On Setting - Time of Ordinary Portland Cement (OPC) Paste and Compressive Strength of ConcreteDocument8 pagesThe Impact of Sugar On Setting - Time of Ordinary Portland Cement (OPC) Paste and Compressive Strength of ConcreteJarek PlaszczycaNo ratings yet
- Answers To Option A Exam-Style Questions: ReactantsDocument3 pagesAnswers To Option A Exam-Style Questions: ReactantsSwati NigaamNo ratings yet
- Cable SNR - Ubiquiti CommunityDocument3 pagesCable SNR - Ubiquiti CommunityETONSHOP EmprendeNo ratings yet
- R-12-090 - Pressure Meter Test ReportDocument30 pagesR-12-090 - Pressure Meter Test ReportRaghu Prakash ANo ratings yet
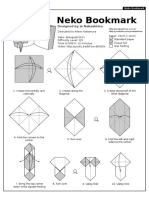
- Neko Bookmark: Designed by Jo NakashimaDocument4 pagesNeko Bookmark: Designed by Jo NakashimaEzra BlatzNo ratings yet
- KG2 Weekly Plan 4th WDocument2 pagesKG2 Weekly Plan 4th WAvik KunduNo ratings yet
- Economic SectionsDocument13 pagesEconomic SectionsArvin NaborNo ratings yet
- BS 7671-2001 - 16th Edition IEE Wiring Regulations - Design & VerificationsDocument8 pagesBS 7671-2001 - 16th Edition IEE Wiring Regulations - Design & VerificationsAshwin DuhonarrainNo ratings yet
- AE Smart Geared Prewired System Installation Manual v1 0Document20 pagesAE Smart Geared Prewired System Installation Manual v1 0ben omar HmidouNo ratings yet
- Area and Power Efficient Ecc For Multiple Adjacent Bit Errors in SramsDocument4 pagesArea and Power Efficient Ecc For Multiple Adjacent Bit Errors in Sramssri deviNo ratings yet
- BD 535Document5 pagesBD 535cagliaripescaNo ratings yet
- Turbo CodesDocument28 pagesTurbo CodesSharad KaushikNo ratings yet
- IBM 6m1 Maintenance GuideDocument567 pagesIBM 6m1 Maintenance GuidebryceNo ratings yet
- DCL Commands (Oracle)Document14 pagesDCL Commands (Oracle)Prasanthi KolliNo ratings yet
- Collabland: Software For Digitization and Mosaicing of Land Survey MapsDocument58 pagesCollabland: Software For Digitization and Mosaicing of Land Survey MapsMehaboob TeachesNo ratings yet
- Ye Tu19 Turning IDocument36 pagesYe Tu19 Turning IferNo ratings yet
- PJC H2 PHY 9646 Mid-Year Paper 2012Document22 pagesPJC H2 PHY 9646 Mid-Year Paper 2012Ng Jia ChengNo ratings yet
- EPEVER-Datasheet ItracerDocument2 pagesEPEVER-Datasheet ItracerM Khalif WinaryaNo ratings yet
- Tara Balam... : How To Caluculate Tarabalam?Document6 pagesTara Balam... : How To Caluculate Tarabalam?krishnaNo ratings yet
- Waves: Laq'S (8 Marks)Document9 pagesWaves: Laq'S (8 Marks)Mohd ShahbazNo ratings yet
- 1 - Matrix Method of Structural AnalysisDocument5 pages1 - Matrix Method of Structural AnalysistrixiaNo ratings yet
- Problem Solving PDFDocument24 pagesProblem Solving PDFDanny ReyesNo ratings yet
- 3 Mundlak Cavallo y Domenech 1990Document25 pages3 Mundlak Cavallo y Domenech 1990Candela Vazquez FernándezNo ratings yet
- Reading Raphael Lataster, A Review From A Bayesian PerspectiveDocument38 pagesReading Raphael Lataster, A Review From A Bayesian PerspectiveTim HendrixNo ratings yet
- 1 MC Culloh Pitts Neuron Model 22 Jul 2019material I 22 Jul 2019 Intro NewDocument58 pages1 MC Culloh Pitts Neuron Model 22 Jul 2019material I 22 Jul 2019 Intro NewBarry AllenNo ratings yet
- P and Q System@Sudip BakshiDocument15 pagesP and Q System@Sudip BakshiSudip BakshiNo ratings yet
- 3D SEARCHING IntroductionDocument3 pages3D SEARCHING IntroductionGitanjaliNo ratings yet
- CE023 LABORATORY MANUAL 2nd RevisionDocument72 pagesCE023 LABORATORY MANUAL 2nd RevisionernestNo ratings yet

























































































Download as pdf or txt
You might also like
- Principles of TurbomachineryDocument276 pagesPrinciples of TurbomachineryNavneet PAndeNo ratings yet
- 14M B9J Electric Schematic - B9J1-1272Document34 pages14M B9J Electric Schematic - B9J1-1272Muhammad IbrahimNo ratings yet
- ML PDFDocument7 pagesML PDFmanchal2204No ratings yet
- DMT BATCH-4 (Project Report)Document9 pagesDMT BATCH-4 (Project Report)Jaswanth PrabhasNo ratings yet
- A Hybrid Recommender System For Recommending Smartphones ToDocument24 pagesA Hybrid Recommender System For Recommending Smartphones ToSabri GOCERNo ratings yet
- Recommendation Model Using User Reviews and Deep Learning ApproachDocument5 pagesRecommendation Model Using User Reviews and Deep Learning ApproachANIMIXNo ratings yet
- Background InformationDocument9 pagesBackground InformationMwanthi kimuyuNo ratings yet
- 4704-Article Text-9006-1-10-20201231Document13 pages4704-Article Text-9006-1-10-20201231cagan.ulNo ratings yet
- Movie Recommendation System: Synopsis For Project (KCA 353)Document17 pagesMovie Recommendation System: Synopsis For Project (KCA 353)Rishabh MishraNo ratings yet
- Research Article: A Sentiment-Enhanced Hybrid Recommender System For Movie Recommendation: A Big Data Analytics FrameworkDocument10 pagesResearch Article: A Sentiment-Enhanced Hybrid Recommender System For Movie Recommendation: A Big Data Analytics Frameworkviju001No ratings yet
- Sensors 22 04904Document22 pagesSensors 22 04904Miza RaiNo ratings yet
- IJIRMPS Satish SirDocument8 pagesIJIRMPS Satish SirHatim HusainNo ratings yet
- ReportDocument20 pagesReports8240644No ratings yet
- Symmetry: Design of An Unsupervised Machine Learning-Based Movie Recommender SystemDocument27 pagesSymmetry: Design of An Unsupervised Machine Learning-Based Movie Recommender SystemMIGUEL ANGEL PICO LEALNo ratings yet
- MultiAttributed Hybrid IISC Banglore CBP RBW Jan 2014Document6 pagesMultiAttributed Hybrid IISC Banglore CBP RBW Jan 2014R.B.WaghNo ratings yet
- ITE2013 Big Data AnalyticsDocument13 pagesITE2013 Big Data AnalyticsSUKANT JHA 19BIT0359No ratings yet
- FINAL Document KalyaniDocument80 pagesFINAL Document KalyaniDNR PROJECTSNo ratings yet
- ReportDocument16 pagesReportUddesh BhagatNo ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208STRANGER MANNo ratings yet
- 10 1016@j Simpat 2020 102198Document17 pages10 1016@j Simpat 2020 102198Shrijan SinghNo ratings yet
- AakarshDocument10 pagesAakarshSam boiNo ratings yet
- Recommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyDocument10 pagesRecommendation System On Cloud Environment A Descriptive Study On This Marketing StrategyIJRASETPublicationsNo ratings yet
- CBP RBW Ieee Conecct2014 1569825549Document6 pagesCBP RBW Ieee Conecct2014 1569825549R.B.WaghNo ratings yet
- Implementing A Movie Recommendation System in Machine Learning Using Hybrid ApproachDocument5 pagesImplementing A Movie Recommendation System in Machine Learning Using Hybrid ApproachIJRASETPublicationsNo ratings yet
- Query Extraction Using Filtering Technique Over The Stored Data in The DatabaseDocument5 pagesQuery Extraction Using Filtering Technique Over The Stored Data in The DatabaseRahul SharmaNo ratings yet
- Report Movie RecommendationDocument49 pagesReport Movie RecommendationChris Sosa JacobNo ratings yet
- Comp Sci - IJCSE - A Hybrid Recommender - AkshitaDocument8 pagesComp Sci - IJCSE - A Hybrid Recommender - Akshitaiaset123No ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208Vaibhav PatilNo ratings yet
- Building A Movie Recommendation System Using Collaborative Filtering With TF-IDF-IJRASETDocument13 pagesBuilding A Movie Recommendation System Using Collaborative Filtering With TF-IDF-IJRASETIJRASETPublicationsNo ratings yet
- Movie Recommendation Project ReportDocument9 pagesMovie Recommendation Project Reports8240644No ratings yet
- Survey On Kernel Optimization Based Enhanced Preference Learning For Online Movie RecommendationDocument8 pagesSurvey On Kernel Optimization Based Enhanced Preference Learning For Online Movie RecommendationEditor IJTSRDNo ratings yet
- 98 Jicr September 3208Document6 pages98 Jicr September 3208bawec59510No ratings yet
- Moviegen: A Movie Recommendation System: Eyrun A. Eyjolfsdottir, Gaurangi Tilak, Nan LiDocument10 pagesMoviegen: A Movie Recommendation System: Eyrun A. Eyjolfsdottir, Gaurangi Tilak, Nan LiMul AdiNo ratings yet
- MediaRec A Hybrid Media Recommender SystemDocument8 pagesMediaRec A Hybrid Media Recommender SystemIJRASETPublicationsNo ratings yet
- Movie Recommdation ReportDocument10 pagesMovie Recommdation ReportPRATEEKNo ratings yet
- An Efficient Movie Recommendation Algorithm Based On Improved K CliqueDocument15 pagesAn Efficient Movie Recommendation Algorithm Based On Improved K CliquekarandhanodiyaNo ratings yet
- A Comprehensive Review On Non-Neural Networks Collaborative Filtering Recommendation SystemsDocument29 pagesA Comprehensive Review On Non-Neural Networks Collaborative Filtering Recommendation Systemsjayanthi jaiNo ratings yet
- Mean-Reversion Based Hybrid Movie Recommender System Using Collaborative and Content-Based Filtering MethodsDocument18 pagesMean-Reversion Based Hybrid Movie Recommender System Using Collaborative and Content-Based Filtering MethodsAmaan NasserNo ratings yet
- Movie Recommendation System Using TF-IDF Vectorization and Cosine SimilarityDocument9 pagesMovie Recommendation System Using TF-IDF Vectorization and Cosine SimilarityIJRASETPublicationsNo ratings yet
- A Systematic Literature Survey On Recommendation SystemDocument15 pagesA Systematic Literature Survey On Recommendation SystemIJRASETPublicationsNo ratings yet
- Personality-Based Active Learning For Collaborative Filtering Recommender SystemsDocument12 pagesPersonality-Based Active Learning For Collaborative Filtering Recommender Systemsmonamona69No ratings yet
- A Literature Review and Classification of Recommender Systems Research PDFDocument7 pagesA Literature Review and Classification of Recommender Systems Research PDFea6qsxqdNo ratings yet
- AMORE: Design and Implementation of A Commercial-Strength Parallel Hybrid Movie Recommendation EngineDocument26 pagesAMORE: Design and Implementation of A Commercial-Strength Parallel Hybrid Movie Recommendation EngineLaique SantanaNo ratings yet
- A Hybrid Approach For Personalized Recommender System Using Weighted TFIDF On RSS ContentsDocument11 pagesA Hybrid Approach For Personalized Recommender System Using Weighted TFIDF On RSS ContentsATSNo ratings yet
- Build A Recommendation System For Movies or BooksDocument6 pagesBuild A Recommendation System For Movies or BooksIJRASETPublicationsNo ratings yet
- Evaluating-ToIS-20041Document49 pagesEvaluating-ToIS-20041multe123No ratings yet
- Movie Recommendation System Using Content-Based Filtering With Heroku DeploymentDocument8 pagesMovie Recommendation System Using Content-Based Filtering With Heroku DeploymentIJRASETPublicationsNo ratings yet
- Recommender System Based On Customer Behaviour For Retail StoresDocument12 pagesRecommender System Based On Customer Behaviour For Retail StoresPriscila GuayasamínNo ratings yet
- Movie Recommendation SystemDocument24 pagesMovie Recommendation Systemcyclop910No ratings yet
- Using Feature Selection Methods To Discover Common Users' Preferences For Online Recommender SystemsDocument9 pagesUsing Feature Selection Methods To Discover Common Users' Preferences For Online Recommender SystemsHendra StoryNo ratings yet
- EAI Endorsed TransactionsDocument9 pagesEAI Endorsed TransactionsVALENTIN BELMUT ANTUNEZ GONZALESNo ratings yet
- A Survey of Web Service Recommendation Methods-28660Document5 pagesA Survey of Web Service Recommendation Methods-28660Editor IJAERDNo ratings yet
- A Survey For Personalized Item Based Recommendation SystemDocument3 pagesA Survey For Personalized Item Based Recommendation SystemInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Recommender System Using Collaborative Filtering and Demographic Characteristics of UsersDocument7 pagesRecommender System Using Collaborative Filtering and Demographic Characteristics of UsersEditor IJRITCCNo ratings yet
- MdocDocument32 pagesMdocjyothi bhavaniNo ratings yet
- Technical PaperDocument6 pagesTechnical PaperKunal salunkheNo ratings yet
- Movie Recommendation System Using Machine LearningDocument6 pagesMovie Recommendation System Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Deep Autoencoder For Recommender Systems: Parameter Influence AnalysisDocument11 pagesDeep Autoencoder For Recommender Systems: Parameter Influence AnalysisĐứcĐiệuNo ratings yet
- Item-Based Collaborative Filtering Recommendation Algorithms - Highlighted PaperDocument11 pagesItem-Based Collaborative Filtering Recommendation Algorithms - Highlighted PaperShubham ChaudharyNo ratings yet
- Minor ProjectDocument15 pagesMinor Projectharmeetpics1607No ratings yet
- Efficient Scalable Job RecoDocument16 pagesEfficient Scalable Job RecoLuckygirl JyothiNo ratings yet
- Applied Predictive Modeling: An Overview of Applied Predictive ModelingFrom EverandApplied Predictive Modeling: An Overview of Applied Predictive ModelingNo ratings yet
- The Impact of Sugar On Setting - Time of Ordinary Portland Cement (OPC) Paste and Compressive Strength of ConcreteDocument8 pagesThe Impact of Sugar On Setting - Time of Ordinary Portland Cement (OPC) Paste and Compressive Strength of ConcreteJarek PlaszczycaNo ratings yet
- Answers To Option A Exam-Style Questions: ReactantsDocument3 pagesAnswers To Option A Exam-Style Questions: ReactantsSwati NigaamNo ratings yet
- Cable SNR - Ubiquiti CommunityDocument3 pagesCable SNR - Ubiquiti CommunityETONSHOP EmprendeNo ratings yet
- R-12-090 - Pressure Meter Test ReportDocument30 pagesR-12-090 - Pressure Meter Test ReportRaghu Prakash ANo ratings yet
- Neko Bookmark: Designed by Jo NakashimaDocument4 pagesNeko Bookmark: Designed by Jo NakashimaEzra BlatzNo ratings yet
- KG2 Weekly Plan 4th WDocument2 pagesKG2 Weekly Plan 4th WAvik KunduNo ratings yet
- Economic SectionsDocument13 pagesEconomic SectionsArvin NaborNo ratings yet
- BS 7671-2001 - 16th Edition IEE Wiring Regulations - Design & VerificationsDocument8 pagesBS 7671-2001 - 16th Edition IEE Wiring Regulations - Design & VerificationsAshwin DuhonarrainNo ratings yet
- AE Smart Geared Prewired System Installation Manual v1 0Document20 pagesAE Smart Geared Prewired System Installation Manual v1 0ben omar HmidouNo ratings yet
- Area and Power Efficient Ecc For Multiple Adjacent Bit Errors in SramsDocument4 pagesArea and Power Efficient Ecc For Multiple Adjacent Bit Errors in Sramssri deviNo ratings yet
- BD 535Document5 pagesBD 535cagliaripescaNo ratings yet
- Turbo CodesDocument28 pagesTurbo CodesSharad KaushikNo ratings yet
- IBM 6m1 Maintenance GuideDocument567 pagesIBM 6m1 Maintenance GuidebryceNo ratings yet
- DCL Commands (Oracle)Document14 pagesDCL Commands (Oracle)Prasanthi KolliNo ratings yet
- Collabland: Software For Digitization and Mosaicing of Land Survey MapsDocument58 pagesCollabland: Software For Digitization and Mosaicing of Land Survey MapsMehaboob TeachesNo ratings yet
- Ye Tu19 Turning IDocument36 pagesYe Tu19 Turning IferNo ratings yet
- PJC H2 PHY 9646 Mid-Year Paper 2012Document22 pagesPJC H2 PHY 9646 Mid-Year Paper 2012Ng Jia ChengNo ratings yet
- EPEVER-Datasheet ItracerDocument2 pagesEPEVER-Datasheet ItracerM Khalif WinaryaNo ratings yet
- Tara Balam... : How To Caluculate Tarabalam?Document6 pagesTara Balam... : How To Caluculate Tarabalam?krishnaNo ratings yet
- Waves: Laq'S (8 Marks)Document9 pagesWaves: Laq'S (8 Marks)Mohd ShahbazNo ratings yet
- 1 - Matrix Method of Structural AnalysisDocument5 pages1 - Matrix Method of Structural AnalysistrixiaNo ratings yet
- Problem Solving PDFDocument24 pagesProblem Solving PDFDanny ReyesNo ratings yet
- 3 Mundlak Cavallo y Domenech 1990Document25 pages3 Mundlak Cavallo y Domenech 1990Candela Vazquez FernándezNo ratings yet
- Reading Raphael Lataster, A Review From A Bayesian PerspectiveDocument38 pagesReading Raphael Lataster, A Review From A Bayesian PerspectiveTim HendrixNo ratings yet
- 1 MC Culloh Pitts Neuron Model 22 Jul 2019material I 22 Jul 2019 Intro NewDocument58 pages1 MC Culloh Pitts Neuron Model 22 Jul 2019material I 22 Jul 2019 Intro NewBarry AllenNo ratings yet
- P and Q System@Sudip BakshiDocument15 pagesP and Q System@Sudip BakshiSudip BakshiNo ratings yet
- 3D SEARCHING IntroductionDocument3 pages3D SEARCHING IntroductionGitanjaliNo ratings yet
- CE023 LABORATORY MANUAL 2nd RevisionDocument72 pagesCE023 LABORATORY MANUAL 2nd RevisionernestNo ratings yet