Download as pdf or txt
You might also like
- FUNCTIONSDocument1 pageFUNCTIONSvarun08080808No ratings yet
- Lec 3 - Linear RegressionDocument9 pagesLec 3 - Linear Regression14 Asif AkhtarNo ratings yet
- Vector & 3DDocument35 pagesVector & 3DSubh SandeepNo ratings yet
- 633 Sep. 03Document19 pages633 Sep. 03Ebtihal ArabiNo ratings yet
- Morse HomologyDocument14 pagesMorse HomologyVVeraNo ratings yet
- Ptaltscias: - ZinscDocument5 pagesPtaltscias: - ZinscDancing Yu JinNo ratings yet
- MathsDocument3 pagesMathsKaushalya PeoplezzNo ratings yet
- The 2-D Rectangular ElementDocument4 pagesThe 2-D Rectangular ElementAshrf Omer ElmiladiNo ratings yet
- Unit 1 Activity AnswersDocument6 pagesUnit 1 Activity Answers1sonirudNo ratings yet
- Masterclass DSDocument11 pagesMasterclass DS71762202100No ratings yet
- Formula SheetsDocument5 pagesFormula SheetsAayesha NoorNo ratings yet
- QM Formula Sheets by JahanzaibDocument6 pagesQM Formula Sheets by JahanzaibBasit MehrNo ratings yet
- PZO2106 Character Sheet - UpdatedDocument2 pagesPZO2106 Character Sheet - UpdatedJhonnyNo ratings yet
- MATHS P2 (Main Stuff)Document108 pagesMATHS P2 (Main Stuff)hwarraich403rNo ratings yet
- AS TransformationsDocument4 pagesAS Transformationsalya farahiyahNo ratings yet
- Extrema of A FunctionDocument32 pagesExtrema of A FunctionEunice Kyla MapisaNo ratings yet
- Relation Funtions 2021100 601Document1 pageRelation Funtions 2021100 601Harsh JainNo ratings yet
- Bio StatisticsDocument26 pagesBio Statisticsnandhank2k3No ratings yet
- Math 341Document9 pagesMath 341Habil BüyükpınarNo ratings yet
- Tos 1Document1 pageTos 1Maevin WooNo ratings yet
- StrucTheor FormulasDocument3 pagesStrucTheor FormulasMJ Dela CruzNo ratings yet
- 07 Spatial Filtering - PDFDocument98 pages07 Spatial Filtering - PDFMuhammad Tehsin RashadNo ratings yet
- 4april GraceDocument3 pages4april GraceSUCI AMALIANo ratings yet
- LR 4Document15 pagesLR 4cherukurichaitanya99No ratings yet
- Machine LearningDocument79 pagesMachine LearningLOPASNo ratings yet
- Calc III Summary NotesDocument8 pagesCalc III Summary NotesVanessa RoseNo ratings yet
- Summary NotesDocument8 pagesSummary NotesVanessa RoseNo ratings yet
- Apuntes 1 ESTRUCTURASDocument7 pagesApuntes 1 ESTRUCTURASLeandro SotoNo ratings yet
- LR 3Document23 pagesLR 3cherukurichaitanya99No ratings yet
- UOM Electromagnetic Induction Notes 2Document5 pagesUOM Electromagnetic Induction Notes 2Arctic TurtleNo ratings yet
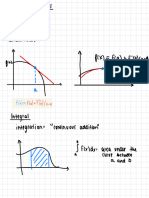
- IntegrationDocument7 pagesIntegrationapi-516387140No ratings yet
- Cost Functions: Machine Learning Course - CS-433Document8 pagesCost Functions: Machine Learning Course - CS-433Diego Iriarte SainzNo ratings yet
- Vector 1Document10 pagesVector 1editorNo ratings yet
- Finite Mathematics Review: ,!7IA3C1-dhedje!:t K K K KDocument2 pagesFinite Mathematics Review: ,!7IA3C1-dhedje!:t K K K Kkyte walkerNo ratings yet
- VectorDocument17 pagesVectorPrisha ShailyNo ratings yet
- อนุพันธ์Document10 pagesอนุพันธ์POPPYNo ratings yet
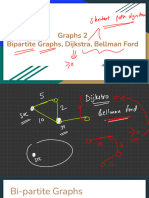
- Graphs 2 - GT Bootcamp 2Document39 pagesGraphs 2 - GT Bootcamp 2Akshat MauryaNo ratings yet
- Functions From A Calculus Perspective: Tie It TogetherDocument1 pageFunctions From A Calculus Perspective: Tie It TogetherChandra KantNo ratings yet
- Lecture12 RoutersDocument64 pagesLecture12 RoutersFuego McFuegoNo ratings yet
- Midterm 1 - MATH 222Document82 pagesMidterm 1 - MATH 222alexbstp10No ratings yet
- 2 MQPDocument1 page2 MQPpraveencybertronNo ratings yet
- Probability Class 3Document15 pagesProbability Class 3Boss of the worldNo ratings yet
- Fundamentals of NursingDocument8 pagesFundamentals of NursingFrancis Neil BacasnotNo ratings yet
- CALCULUSDocument5 pagesCALCULUS4gjhfv2yvfNo ratings yet
- Machine Learning Machine Learning: Learning Highly Non-Linear FunctionsDocument28 pagesMachine Learning Machine Learning: Learning Highly Non-Linear FunctionsAlejandro CelemínNo ratings yet
- 6 - Portfolio TheoryDocument5 pages6 - Portfolio TheoryAmit GuptaNo ratings yet
- 普物Document23 pages普物c44111081No ratings yet
- Redor ReactionDocument1 pageRedor ReactionHems MadaviNo ratings yet
- Conservative HD: Wax DLDocument5 pagesConservative HD: Wax DLArctic TurtleNo ratings yet
- MATLAB Information and Formulas: Operator Precedence Fprintf SPECIFIERDocument3 pagesMATLAB Information and Formulas: Operator Precedence Fprintf SPECIFIEROmar El MasryNo ratings yet
- Bach Optim 2020 Chap1Document8 pagesBach Optim 2020 Chap1AbiyNo ratings yet
- PCS Algebra I Quiz 4 Chapter Review KEYDocument1 pagePCS Algebra I Quiz 4 Chapter Review KEYTim Ricchuiti100% (1)
- UOM Electromagnetic Induction Notes 3Document7 pagesUOM Electromagnetic Induction Notes 3Arctic TurtleNo ratings yet
- MAE563 - 1D - Beam F2013Document26 pagesMAE563 - 1D - Beam F2013chesspalace2No ratings yet
- Tutorial 4Document3 pagesTutorial 4keungboy26No ratings yet
- Lecture 05 - Multivariate MethodsDocument6 pagesLecture 05 - Multivariate MethodsAtaNo ratings yet
- Relational CalculusDocument12 pagesRelational CalculuskasikanoNo ratings yet
- Chapter 4 Deep Neural NetsDocument75 pagesChapter 4 Deep Neural NetsPRATIK GANGAPURWALANo ratings yet
- Linear Algebra 1 - The ML ContextDocument2 pagesLinear Algebra 1 - The ML Contextcherukurichaitanya99No ratings yet
- Intro To ML RevisionNotesDocument24 pagesIntro To ML RevisionNotescherukurichaitanya99No ratings yet
- Logistic Regression-2Document3 pagesLogistic Regression-2cherukurichaitanya99No ratings yet
- Logistic Regression 1Document32 pagesLogistic Regression 1cherukurichaitanya99No ratings yet
- LR 1Document35 pagesLR 1cherukurichaitanya99No ratings yet
- Intro To ML NotesDocument37 pagesIntro To ML Notescherukurichaitanya99No ratings yet
- Vector Tensor CalculusDocument300 pagesVector Tensor CalculusDiogo Martins100% (3)
- Cost Accounting - Chapter 9Document2 pagesCost Accounting - Chapter 9JaceNo ratings yet
- CSCI 170 Homework #1Document2 pagesCSCI 170 Homework #1Kayla Green0% (1)
- A CROSS-CULTURAL STUDY ON WEATHER PROVERBS IN ENGLISH AND VIETNAMESE. Đỗ Thị Minh Ngọc. QHF.1.2006Document110 pagesA CROSS-CULTURAL STUDY ON WEATHER PROVERBS IN ENGLISH AND VIETNAMESE. Đỗ Thị Minh Ngọc. QHF.1.2006Kavic100% (4)
- Resources Policy: Md. Aminul Haque, Erkan Topal, Eric LilfordDocument9 pagesResources Policy: Md. Aminul Haque, Erkan Topal, Eric LilfordYhoan Miller Lujan GomezNo ratings yet
- Charlie MungerDocument19 pagesCharlie MungerTeddy RusliNo ratings yet
- Tutorial 1.0 - Construction Management and Management TechniquesDocument14 pagesTutorial 1.0 - Construction Management and Management TechniquesPatel MitulkumarNo ratings yet
- Mirrors and LensesDocument28 pagesMirrors and LensesRemi Eyonganyoh100% (1)
- Solving Linear Word Problems PracticeDocument2 pagesSolving Linear Word Problems Practiceapi-240157292No ratings yet
- Odeon Application Note - RestaurantsDocument8 pagesOdeon Application Note - RestaurantsSeddik MaarfiNo ratings yet
- Scaling and Content Analysis and Data ProcessingDocument22 pagesScaling and Content Analysis and Data ProcessingabhishekNo ratings yet
- Act 3Document3 pagesAct 3Charll Dezon Abcede AbaNo ratings yet
- Management Yesterday and TodayDocument25 pagesManagement Yesterday and TodayAbhishek Kumar SinghNo ratings yet
- Complex DifferentiationDocument32 pagesComplex DifferentiationrakshithNo ratings yet
- KULIAH 13 The RLC CircuitDocument141 pagesKULIAH 13 The RLC CircuitGara ilhamNo ratings yet
- Tutorial 4Document2 pagesTutorial 4Yuwi ShugumarNo ratings yet
- Factors Affecting Internal Audit Effectiveness: Evidence From Microfinance Institutions Operating in Hawassa, Sidama Region, EthiopiaDocument11 pagesFactors Affecting Internal Audit Effectiveness: Evidence From Microfinance Institutions Operating in Hawassa, Sidama Region, Ethiopiaelias getachewNo ratings yet
- HW 11 SolDocument14 pagesHW 11 SolPerpetual hubbyNo ratings yet
- Electrical Analogy of Physical SystemDocument7 pagesElectrical Analogy of Physical SystemAmitava BiswasNo ratings yet
- Pivot TablesDocument24 pagesPivot TablesOmprakash SharmaNo ratings yet
- Ls-Dyna Manual Vol II r7.0Document1,154 pagesLs-Dyna Manual Vol II r7.0Francisco Ribeiro FernandesNo ratings yet
- 04a Practice Tests Set 3 - Paper 1HDocument20 pages04a Practice Tests Set 3 - Paper 1HArchit GuptaNo ratings yet
- Electron Plasma Oscillation SDocument6 pagesElectron Plasma Oscillation SCésar AveleyraNo ratings yet
- Force Fields and Molecular Dynamics Simulations: M.A. GonzálezDocument32 pagesForce Fields and Molecular Dynamics Simulations: M.A. GonzálezSanjay singhNo ratings yet
- Homework12 SolutionsDocument5 pagesHomework12 SolutionsOscar Alarcon CelyNo ratings yet
- Principal Component AnalysisDocument17 pagesPrincipal Component AnalysisNovi NurcahyaningsihNo ratings yet
- 2020 Grade 12 Patterns and SequencesDocument25 pages2020 Grade 12 Patterns and SequencesMaria-Regina UkatuNo ratings yet
- Lie 2010Document150 pagesLie 2010Alejandro GastonNo ratings yet
- AOA Course ContentsDocument5 pagesAOA Course ContentsMarryam ZulfiqarNo ratings yet
- Z TestDocument3 pagesZ TestzedingelNo ratings yet