Download as pdf or txt
You might also like
- Grade 10 Terms and DefinitionsDocument11 pagesGrade 10 Terms and Definitionskhotso86% (7)
- Research PaperDocument7 pagesResearch PaperNeelam Kumari BNo ratings yet
- PSSR FormDocument16 pagesPSSR Formmythee100% (6)
- socialMedia_dataanalitic (1)Document12 pagessocialMedia_dataanalitic (1)bayuahmadnizarNo ratings yet
- Cyberbullying Detection On Twitter Using Machine Learning A ReviewDocument5 pagesCyberbullying Detection On Twitter Using Machine Learning A ReviewInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Machine Learning Approach To Classify Twitter Hate SpeechDocument5 pagesMachine Learning Approach To Classify Twitter Hate SpeechEditor IJTSRDNo ratings yet
- Down The Rabbit Hole Detecting Online Extremism, Radicalisation, and Politicised Hate SpeechDocument35 pagesDown The Rabbit Hole Detecting Online Extremism, Radicalisation, and Politicised Hate Speechellipsepurplish532No ratings yet
- Unsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaDocument11 pagesUnsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaJames WilsonNo ratings yet
- Sentiment Analysis of TwitterDocument9 pagesSentiment Analysis of TwitterIJRASETPublicationsNo ratings yet
- Information Fusion: Gema Bello-Orgaz, Jason J. Jung, David CamachoDocument15 pagesInformation Fusion: Gema Bello-Orgaz, Jason J. Jung, David CamachoNajd HemdanaNo ratings yet
- Big Data Analytics Meets Social Media, Systematic Review of TechniquesDocument39 pagesBig Data Analytics Meets Social Media, Systematic Review of TechniquesJAGA ADHINo ratings yet
- Combating Propaganda Texts Using Transfer LearningDocument10 pagesCombating Propaganda Texts Using Transfer LearningIAES IJAINo ratings yet
- A Social Network Analysis (SNA) Study On Data Breach Concerns Over Social Media (1) - DikonversiDocument10 pagesA Social Network Analysis (SNA) Study On Data Breach Concerns Over Social Media (1) - DikonversiNindi Nunha RoteNo ratings yet
- Big Data Analytics Meets Social Media A Systematic Review of Tech - CompressedDocument38 pagesBig Data Analytics Meets Social Media A Systematic Review of Tech - Compressedsaal wowNo ratings yet
- 3 Social Media AnalyticsDocument4 pages3 Social Media AnalyticsAnna JonesNo ratings yet
- Information: Online Multilingual Hate Speech Detection: Experimenting With Hindi and English Social MediaDocument16 pagesInformation: Online Multilingual Hate Speech Detection: Experimenting With Hindi and English Social Mediamehar bhatiaNo ratings yet
- Project WorkDocument36 pagesProject WorkOrah SeunNo ratings yet
- 20 On Scalable and Robust Truth Discovery in Big Data Social Media Sensing ApplicationsDocument3 pages20 On Scalable and Robust Truth Discovery in Big Data Social Media Sensing ApplicationsBaranishankarNo ratings yet
- Impact of Big Data and Social Media On Society: March 2016Document3 pagesImpact of Big Data and Social Media On Society: March 2016Robby Walsen PasaribuNo ratings yet
- Fake News Detection Using Supervised Learning MethDocument5 pagesFake News Detection Using Supervised Learning MethAmi. ESS.No ratings yet
- Survey On Data Analysis in Social Media A Practical Application AspectDocument21 pagesSurvey On Data Analysis in Social Media A Practical Application AspectmailNo ratings yet
- Ribes Et Al 2021 TrustindicatorsandexplainableAI Astudyonuserperceptions PreprintDocument11 pagesRibes Et Al 2021 TrustindicatorsandexplainableAI Astudyonuserperceptions Preprintksuhail44444No ratings yet
- Fake News Detection Using Machine Learning: A ReviewDocument6 pagesFake News Detection Using Machine Learning: A ReviewIjaems JournalNo ratings yet
- Detection of Cyber Bullying On Social Media Using Machine LearningDocument8 pagesDetection of Cyber Bullying On Social Media Using Machine LearningIJRASETPublicationsNo ratings yet
- M.Thasleemabanu DocumentDocument56 pagesM.Thasleemabanu DocumentAPCACNo ratings yet
- 2 Cesare-PromisesPitfallsUsing-2018Document22 pages2 Cesare-PromisesPitfallsUsing-2018Fahmi BurhanuddinNo ratings yet
- Natural Language Processing and Naive BaDocument10 pagesNatural Language Processing and Naive Bavits.20731a0433No ratings yet
- Natural Language Processing and Naïve Bayes Classifier Algorithm To Automate The Detection of CyberbullyingDocument10 pagesNatural Language Processing and Naïve Bayes Classifier Algorithm To Automate The Detection of CyberbullyingIJRASETPublicationsNo ratings yet
- A Big-Data Processing and Visualization PlatformDocument21 pagesA Big-Data Processing and Visualization Platformwingwingxd61No ratings yet
- Negative Sentiment Analysis Hate Speech Detection and Cyber BullyingDocument9 pagesNegative Sentiment Analysis Hate Speech Detection and Cyber BullyingIJRASETPublicationsNo ratings yet
- 2-Convolutional Neural Network With Margin Loss For Fake News DetectionDocument12 pages2-Convolutional Neural Network With Margin Loss For Fake News DetectionMr. Saqib UbaidNo ratings yet
- A Case Study For Intelligent Event Recommendation: ArticleDocument21 pagesA Case Study For Intelligent Event Recommendation: ArticleBogdan VladNo ratings yet
- Method For The Analysis of Sentiments in Social Networks With The Use of RDocument16 pagesMethod For The Analysis of Sentiments in Social Networks With The Use of RArthur AguilarNo ratings yet
- The Impact of Big Data On YourDocument13 pagesThe Impact of Big Data On YourGundeepNo ratings yet
- Reddy - 2022 - Toxic Comments Classification (2) - AnnotatedDocument17 pagesReddy - 2022 - Toxic Comments Classification (2) - AnnotatedMafer ReveloNo ratings yet
- SSRN Id4533642Document48 pagesSSRN Id4533642João Vitor Nunes de OliveiraNo ratings yet
- 1 Running Head: Research ProposalDocument16 pages1 Running Head: Research ProposalFrancisNo ratings yet
- Big Questions For Social Media Big Data RepresentaDocument11 pagesBig Questions For Social Media Big Data RepresentaBlessing OjoNo ratings yet
- Cyber Bullying Detection On Social Media NetworkDocument9 pagesCyber Bullying Detection On Social Media NetworkIJRASETPublicationsNo ratings yet
- Fighting Hate Speech, Silencing Drag Queens? Artificial Intelligence in Content Moderation and Risks To LGBTQ Voices OnlineDocument33 pagesFighting Hate Speech, Silencing Drag Queens? Artificial Intelligence in Content Moderation and Risks To LGBTQ Voices OnlineLuyi ZhangNo ratings yet
- IEEASMD00Document12 pagesIEEASMD00music2850No ratings yet
- 2021 Sexual Harassment With Chat Predators Detection and Classification Using Bidirectionally Long Short-Term Memory and Gated Recurrent UnitDocument15 pages2021 Sexual Harassment With Chat Predators Detection and Classification Using Bidirectionally Long Short-Term Memory and Gated Recurrent Unitgatekeeper.ai.bdNo ratings yet
- Irjet Fake News Prediction Using MachineDocument5 pagesIrjet Fake News Prediction Using Machinealperen.unal89No ratings yet
- Sources of Evidence of Learning Learning and Assessment in The Era of Big DataDocument25 pagesSources of Evidence of Learning Learning and Assessment in The Era of Big Datajudith patnaanNo ratings yet
- Some Antecedents and Effects of Trust in Virtual C PDFDocument26 pagesSome Antecedents and Effects of Trust in Virtual C PDFNUNQUAMSATISNo ratings yet
- Algorithmic Censorship by Social Platforms: Power and ResistanceDocument28 pagesAlgorithmic Censorship by Social Platforms: Power and Resistanceabycy2718No ratings yet
- 07516129Document6 pages07516129Govind UpadhyayNo ratings yet
- Cyberloafing Research 1997-2019: A Citation-Based Literature ReviewDocument14 pagesCyberloafing Research 1997-2019: A Citation-Based Literature ReviewsharventhiriNo ratings yet
- Privacy Issues On Social Networking Websites: January 2021Document11 pagesPrivacy Issues On Social Networking Websites: January 2021mohammpooyaNo ratings yet
- Final YearDocument25 pagesFinal YearHarry RoyNo ratings yet
- Fake News DetectionDocument6 pagesFake News DetectionOnsa piarusNo ratings yet
- Social Cybersecurity: An Emerging Science: Kathleen M. CarleyDocument17 pagesSocial Cybersecurity: An Emerging Science: Kathleen M. CarleyJuan Pablo Betancur CórdobaNo ratings yet
- Proceedings of The Association For Information Science and Technology - 2020 - Slota - Good Systems Bad DataDocument11 pagesProceedings of The Association For Information Science and Technology - 2020 - Slota - Good Systems Bad DataAbhishek SharmaNo ratings yet
- Content Analysis in An Era of Big DataDocument20 pagesContent Analysis in An Era of Big DataMina HalimNo ratings yet
- The Challenges of Social Media Research in Online Learning EnvironmentsDocument4 pagesThe Challenges of Social Media Research in Online Learning EnvironmentsIJAR JOURNALNo ratings yet
- 1 s2.0 S0378437119317546 MainDocument17 pages1 s2.0 S0378437119317546 MainDanteNo ratings yet
- Abusive Language Detection in Speech DatasetDocument6 pagesAbusive Language Detection in Speech DatasetIJRASETPublicationsNo ratings yet
- Electronics 11 01449 v2Document34 pagesElectronics 11 01449 v2أيه الحنفىNo ratings yet
- Backchanneling ConversationsDocument11 pagesBackchanneling ConversationsSahba SadeghianNo ratings yet
- Trends in Social Network Analysis: Rokia Missaoui Talel Abdessalem Matthieu Latapy EditorsDocument264 pagesTrends in Social Network Analysis: Rokia Missaoui Talel Abdessalem Matthieu Latapy EditorsTijanaNo ratings yet
- Open Source Intelligence and Cyber Crime: Social Media AnalyticsFrom EverandOpen Source Intelligence and Cyber Crime: Social Media AnalyticsRating: 4 out of 5 stars4/5 (1173)
- Open GLDocument161 pagesOpen GLRavi ParkheNo ratings yet
- Manual Sierra Biro 3334-4003Document47 pagesManual Sierra Biro 3334-4003SEBASTIAN PEREZNo ratings yet
- Questions and Answers - PMP Exam PrepDocument14 pagesQuestions and Answers - PMP Exam PrepPramod Gupta100% (2)
- Hydra Text BookDocument3 pagesHydra Text BookRinku kumar PatelNo ratings yet
- Anh 12-WORD FORM & WORD ORDER-HSDocument6 pagesAnh 12-WORD FORM & WORD ORDER-HSTuan Anh Nguyen100% (1)
- Mac ShiftDocument2 pagesMac ShiftanoopsreNo ratings yet
- Republic v. PLDT, 26 SCRA 620Document1 pageRepublic v. PLDT, 26 SCRA 620YANG FLNo ratings yet
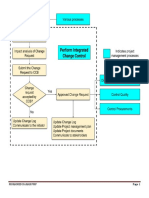
- Perform Integrated Change Control (Step-By-Step)Document4 pagesPerform Integrated Change Control (Step-By-Step)Justin M. FowlkesNo ratings yet
- 135G/245G LC Excavators: 13 900-25 500-kg (30,617-56,167 LB.) Operating WeightDocument9 pages135G/245G LC Excavators: 13 900-25 500-kg (30,617-56,167 LB.) Operating Weightapi-282795606No ratings yet
- MBA Assignments Guide: HandbookDocument60 pagesMBA Assignments Guide: Handbooksuad550No ratings yet
- Reflection Exercise 4 - Hackworth EllaryDocument13 pagesReflection Exercise 4 - Hackworth Ellaryapi-484215877No ratings yet
- SRDC Rman CDBinfoDocument4 pagesSRDC Rman CDBinfoarun kumarNo ratings yet
- ABB Transformer ManufacturingDocument2 pagesABB Transformer ManufacturinggrovisanNo ratings yet
- Asy13144Document87 pagesAsy13144Oz DemonNo ratings yet
- Serv1862 TXTDocument40 pagesServ1862 TXTlalo11715100% (1)
- Bolt FailuresDocument14 pagesBolt FailuressymkimonNo ratings yet
- Peritoneal Dialysis.Document2 pagesPeritoneal Dialysis.alex_cariñoNo ratings yet
- US ARMY - Inventory of Field Manuals As of January 23, 2002Document13 pagesUS ARMY - Inventory of Field Manuals As of January 23, 2002AKsentinelNo ratings yet
- Elforsk English 01Document58 pagesElforsk English 01ecatworldNo ratings yet
- Presentation Alfa Laval Corrosion Charts For Plate Heat ExchangersDocument5 pagesPresentation Alfa Laval Corrosion Charts For Plate Heat ExchangersNasrin AkhondiNo ratings yet
- WMO Guidelines On Surface Station Data Quality Assurance For Climate ApplicationsDocument74 pagesWMO Guidelines On Surface Station Data Quality Assurance For Climate ApplicationsGEMPFNo ratings yet
- Dc-Os ArchDocument14 pagesDc-Os ArchSandra MariaNo ratings yet
- 11-Igmp Principle Issue1.01Document32 pages11-Igmp Principle Issue1.01thato69100% (1)
- RefDocument11 pagesRefKailash KumarNo ratings yet
- Amazon Cognito PrinciplesDocument3 pagesAmazon Cognito PrinciplesHaider HadiNo ratings yet
- Blue Chips Bags 4 Gold, 15 Silver, 1 Bronze Medals in ArcheryDocument1 pageBlue Chips Bags 4 Gold, 15 Silver, 1 Bronze Medals in ArcheryRodel Novesteras ClausNo ratings yet
- Emile Agnel Trio Oboe Cello PianoDocument52 pagesEmile Agnel Trio Oboe Cello PianoVíctor Lazo100% (1)
- Patient Transfer Policy 3.0Document25 pagesPatient Transfer Policy 3.0Val SolidumNo ratings yet