
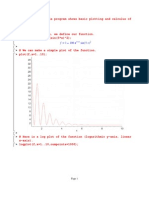
Code
Code
You might also like
- Python HandsOn-Function&OOPsDocument16 pagesPython HandsOn-Function&OOPsHap Py77% (93)
- Modules 1Document9 pagesModules 1karthiyayani umashankarNo ratings yet
- Python Hands OnDocument11 pagesPython Hands Onprashant pal100% (1)
- Hay System Job Evaluation Power PointDocument36 pagesHay System Job Evaluation Power PointOsayande Omo-osagie100% (2)
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- Code - Py: Import From Import Import As Import From Import Import AsDocument4 pagesCode - Py: Import From Import Import As Import From Import Import AsKUSHAL SARASWATNo ratings yet
- DWM Final ExpsDocument14 pagesDWM Final Expsmanujamanav01No ratings yet
- Python3 FrescoDocument8 pagesPython3 FrescoNaresh ReddyNo ratings yet
- ML Lab Manual PDFDocument9 pagesML Lab Manual PDFAnonymous KvIcYFNo ratings yet
- Program 1Document25 pagesProgram 1Asif BadegharNo ratings yet
- Max Sub Array:: Using Namespace Int Int Int Int Int Int Int IntDocument7 pagesMax Sub Array:: Using Namespace Int Int Int Int Int Int Int IntArth AgrawalNo ratings yet
- ML Lab....... 3-Converted NewDocument27 pagesML Lab....... 3-Converted NewHanisha BavanaNo ratings yet
- RNN - UrbanDocument4 pagesRNN - UrbanjuanNo ratings yet
- Data Science ManualDocument16 pagesData Science ManualKRISHNAVENI RNo ratings yet
- Ai Lab CodeDocument14 pagesAi Lab CodeAladin sabariNo ratings yet
- Code Question1-AdalineDocument29 pagesCode Question1-AdalineVoleti Sri Lakshmi Priyanka AP17110010124No ratings yet
- QLSTMvs LSTMDocument7 pagesQLSTMvs LSTMmohamedaligharbi20No ratings yet
- SodapdfDocument4 pagesSodapdfPerli Raj KumarNo ratings yet
- Hackerrank AnswersDocument8 pagesHackerrank AnswersMudadla.PoornimaNo ratings yet
- DAA LabDocument41 pagesDAA Labpalaniperumal041979No ratings yet
- JihznDocument3 pagesJihzndjihenebenbouhaNo ratings yet
- DCDR FULLDocument23 pagesDCDR FULLhet shah100% (1)
- Computer Ka ProjectDocument42 pagesComputer Ka ProjectTushar KandpalNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- 3 1,低阶API示范Document12 pages3 1,低阶API示范codetree0729No ratings yet
- CS Practical File 3Document18 pagesCS Practical File 3omNo ratings yet
- MLPrograma1-5 PyDocument17 pagesMLPrograma1-5 PybmbzogfxhbufiwsltuNo ratings yet
- CS Practical File 2Document9 pagesCS Practical File 2omNo ratings yet
- 4ann - 5Th ProgDocument15 pages4ann - 5Th Progshreyas .cNo ratings yet
- Machine FileDocument27 pagesMachine FileJyoti GodaraNo ratings yet
- ML LabDocument7 pagesML LabRishi TPNo ratings yet
- Ai Last 5Document4 pagesAi Last 5Bad BoyNo ratings yet
- Code:-: Compiler Construction (UCS802) Lab Assignment-2Document12 pagesCode:-: Compiler Construction (UCS802) Lab Assignment-2Devansh PahujaNo ratings yet
- ML RECORDDocument24 pagesML RECORDmkesav3070No ratings yet
- ML RecordDocument24 pagesML Recordmkesav3070No ratings yet
- DSL ProDocument41 pagesDSL ProSujit KhandareNo ratings yet
- Practical File Class 12Document6 pagesPractical File Class 12abhyudai.edwardsNo ratings yet
- AlexNet Transfer Learning - IpynbDocument5 pagesAlexNet Transfer Learning - IpynbPraveen J LNo ratings yet
- Yogen SMa 4Document10 pagesYogen SMa 4Yogen PS48No ratings yet
- Practical C++Document30 pagesPractical C++HarmanNo ratings yet
- EE 559 HW2Code PDFDocument7 pagesEE 559 HW2Code PDFAliNo ratings yet
- Litcoder Final Modules OnlyDocument9 pagesLitcoder Final Modules Onlynaveen kumarNo ratings yet
- Python LABDocument50 pagesPython LABToufik HossainNo ratings yet
- Worksheet FunctionsDocument12 pagesWorksheet Functionsabelosbert01No ratings yet
- A.) Input: Integer Real DimensionDocument28 pagesA.) Input: Integer Real DimensionSamar PratapNo ratings yet
- Apr 2023Document32 pagesApr 2023Abhilash JoseNo ratings yet
- Daa LabDocument22 pagesDaa Labvikas 5G9No ratings yet
- Ann Practical AllDocument23 pagesAnn Practical Allmst aheNo ratings yet
- 15CSL76 StudentsDocument18 pages15CSL76 StudentsYounus KhanNo ratings yet
- Miscellaneous Maple4llDocument4 pagesMiscellaneous Maple4llJean ReneNo ratings yet
- Python Class PRGDocument54 pagesPython Class PRGSyed SalmanNo ratings yet
- Aiml LabDocument13 pagesAiml LabAishwarya BiradarNo ratings yet
- ML Final-1Document7 pagesML Final-1shrinivaspawar350No ratings yet
- Python ExampleDocument43 pagesPython ExampleSri AshishNo ratings yet
- Project IpDocument51 pagesProject IpDwarkesh savaliaNo ratings yet
- AssDocument5 pagesAssTaqwa ElsayedNo ratings yet
- Exe 1Document13 pagesExe 1jaya pandiNo ratings yet
- 100 Python Examples.Document44 pages100 Python Examples.abhimanyu thakurNo ratings yet
- Scientific Calculator FinalllDocument10 pagesScientific Calculator Finalll2260 Shreya SonkusareAI&DSNo ratings yet
- Driver Packaging Utility User Guide MinoltaDocument54 pagesDriver Packaging Utility User Guide MinoltagedangboyNo ratings yet
- Business ProposalDocument5 pagesBusiness ProposalMary Grace Castañeda FloresNo ratings yet
- Plot Hooks: /U/Tundrawolfe /U/ZapzoroathDocument35 pagesPlot Hooks: /U/Tundrawolfe /U/ZapzoroathAdrian B.No ratings yet
- Property Notes A.Y. 2011-2012 Atty. Lopez-Rosario LecturesDocument7 pagesProperty Notes A.Y. 2011-2012 Atty. Lopez-Rosario LecturesAlit Dela CruzNo ratings yet
- Did The Berlin Blockade Bring Europe Close To Nuclear WarDocument2 pagesDid The Berlin Blockade Bring Europe Close To Nuclear WarJames HillNo ratings yet
- William Duarte - Delphi® para Android e iOS - Desenvolvendo Aplicativos MóveisDocument1 pageWilliam Duarte - Delphi® para Android e iOS - Desenvolvendo Aplicativos MóveisRonaldo NascimentoNo ratings yet
- 0000004232-Ashok Leyland LTD FullDocument5 pages0000004232-Ashok Leyland LTD FullVenkat Parthasarathy100% (1)
- Unnatural Nature of ScienceDocument5 pagesUnnatural Nature of ScienceXia AlliaNo ratings yet
- Apptitude 1Document11 pagesApptitude 1Javed IqbalNo ratings yet
- Pixel Tactics Rules Summary v1Document2 pagesPixel Tactics Rules Summary v1Vicente Martínez LópezNo ratings yet
- Critical Vices of PostmodernismDocument276 pagesCritical Vices of PostmodernismmytitaniciraqNo ratings yet
- Rahiotis2007 CPP Acp Dentin ReDocument4 pagesRahiotis2007 CPP Acp Dentin ReARUNA BharathiNo ratings yet
- 004 - Four Dimensions of Service ManagementDocument7 pages004 - Four Dimensions of Service ManagementAbdoo AbdooNo ratings yet
- Visual Design-Composition and Layout PrinciplesDocument5 pagesVisual Design-Composition and Layout PrinciplesRady100% (1)
- Interim Report EDUMENTORDocument17 pagesInterim Report EDUMENTORRajat Gaulkar100% (1)
- THE Strategic Mindset: Applying Strategic Thinking Skills For Organizational SuccessDocument10 pagesTHE Strategic Mindset: Applying Strategic Thinking Skills For Organizational SuccessDanielle GraceNo ratings yet
- Bray Series 35 36 Weights DimensionsDocument1 pageBray Series 35 36 Weights Dimensionsjacquesstrappe06No ratings yet
- Apple Iphone XR Price - Google SearchDocument1 pageApple Iphone XR Price - Google Searchkamarie DavisNo ratings yet
- The Works of Agatha Christie (v1.1)Document8 pagesThe Works of Agatha Christie (v1.1)Sam YeoNo ratings yet
- FprEN 1998-1-1 (2024)Document123 pagesFprEN 1998-1-1 (2024)MarcoNo ratings yet
- KUPWARADocument12 pagesKUPWARASbi reco north AnuragNo ratings yet
- EDFS - Request Memento For Reassigned Personnel of 205THWDocument1 pageEDFS - Request Memento For Reassigned Personnel of 205THWRomeo GarciaNo ratings yet
- Spirit NazarethDocument4 pagesSpirit NazarethPeter JackNo ratings yet
- UTH1. Bicycle Facilities Planning and Design by DR - RsiguaDocument52 pagesUTH1. Bicycle Facilities Planning and Design by DR - RsiguaGulienne Randee Mickhaela ZamoraNo ratings yet
- List of Red-Light Districts: Jump To Navigation Jump To SearchDocument32 pagesList of Red-Light Districts: Jump To Navigation Jump To SearchsudeepomNo ratings yet
- 2023 Career Roadmap Template (Editable)Document10 pages2023 Career Roadmap Template (Editable)Ebube IloNo ratings yet
- Michael King - PresentationDocument14 pagesMichael King - PresentationArk GroupNo ratings yet
- Business LetterDocument5 pagesBusiness LetterBeugh RiveraNo ratings yet
- J OperatorDocument6 pagesJ OperatorManikandan SundararajNo ratings yet

























































































Download as txt, pdf, or txt
You might also like
- Python HandsOn-Function&OOPsDocument16 pagesPython HandsOn-Function&OOPsHap Py77% (93)
- Modules 1Document9 pagesModules 1karthiyayani umashankarNo ratings yet
- Python Hands OnDocument11 pagesPython Hands Onprashant pal100% (1)
- Hay System Job Evaluation Power PointDocument36 pagesHay System Job Evaluation Power PointOsayande Omo-osagie100% (2)
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- Code - Py: Import From Import Import As Import From Import Import AsDocument4 pagesCode - Py: Import From Import Import As Import From Import Import AsKUSHAL SARASWATNo ratings yet
- DWM Final ExpsDocument14 pagesDWM Final Expsmanujamanav01No ratings yet
- Python3 FrescoDocument8 pagesPython3 FrescoNaresh ReddyNo ratings yet
- ML Lab Manual PDFDocument9 pagesML Lab Manual PDFAnonymous KvIcYFNo ratings yet
- Program 1Document25 pagesProgram 1Asif BadegharNo ratings yet
- Max Sub Array:: Using Namespace Int Int Int Int Int Int Int IntDocument7 pagesMax Sub Array:: Using Namespace Int Int Int Int Int Int Int IntArth AgrawalNo ratings yet
- ML Lab....... 3-Converted NewDocument27 pagesML Lab....... 3-Converted NewHanisha BavanaNo ratings yet
- RNN - UrbanDocument4 pagesRNN - UrbanjuanNo ratings yet
- Data Science ManualDocument16 pagesData Science ManualKRISHNAVENI RNo ratings yet
- Ai Lab CodeDocument14 pagesAi Lab CodeAladin sabariNo ratings yet
- Code Question1-AdalineDocument29 pagesCode Question1-AdalineVoleti Sri Lakshmi Priyanka AP17110010124No ratings yet
- QLSTMvs LSTMDocument7 pagesQLSTMvs LSTMmohamedaligharbi20No ratings yet
- SodapdfDocument4 pagesSodapdfPerli Raj KumarNo ratings yet
- Hackerrank AnswersDocument8 pagesHackerrank AnswersMudadla.PoornimaNo ratings yet
- DAA LabDocument41 pagesDAA Labpalaniperumal041979No ratings yet
- JihznDocument3 pagesJihzndjihenebenbouhaNo ratings yet
- DCDR FULLDocument23 pagesDCDR FULLhet shah100% (1)
- Computer Ka ProjectDocument42 pagesComputer Ka ProjectTushar KandpalNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- 3 1,低阶API示范Document12 pages3 1,低阶API示范codetree0729No ratings yet
- CS Practical File 3Document18 pagesCS Practical File 3omNo ratings yet
- MLPrograma1-5 PyDocument17 pagesMLPrograma1-5 PybmbzogfxhbufiwsltuNo ratings yet
- CS Practical File 2Document9 pagesCS Practical File 2omNo ratings yet
- 4ann - 5Th ProgDocument15 pages4ann - 5Th Progshreyas .cNo ratings yet
- Machine FileDocument27 pagesMachine FileJyoti GodaraNo ratings yet
- ML LabDocument7 pagesML LabRishi TPNo ratings yet
- Ai Last 5Document4 pagesAi Last 5Bad BoyNo ratings yet
- Code:-: Compiler Construction (UCS802) Lab Assignment-2Document12 pagesCode:-: Compiler Construction (UCS802) Lab Assignment-2Devansh PahujaNo ratings yet
- ML RECORDDocument24 pagesML RECORDmkesav3070No ratings yet
- ML RecordDocument24 pagesML Recordmkesav3070No ratings yet
- DSL ProDocument41 pagesDSL ProSujit KhandareNo ratings yet
- Practical File Class 12Document6 pagesPractical File Class 12abhyudai.edwardsNo ratings yet
- AlexNet Transfer Learning - IpynbDocument5 pagesAlexNet Transfer Learning - IpynbPraveen J LNo ratings yet
- Yogen SMa 4Document10 pagesYogen SMa 4Yogen PS48No ratings yet
- Practical C++Document30 pagesPractical C++HarmanNo ratings yet
- EE 559 HW2Code PDFDocument7 pagesEE 559 HW2Code PDFAliNo ratings yet
- Litcoder Final Modules OnlyDocument9 pagesLitcoder Final Modules Onlynaveen kumarNo ratings yet
- Python LABDocument50 pagesPython LABToufik HossainNo ratings yet
- Worksheet FunctionsDocument12 pagesWorksheet Functionsabelosbert01No ratings yet
- A.) Input: Integer Real DimensionDocument28 pagesA.) Input: Integer Real DimensionSamar PratapNo ratings yet
- Apr 2023Document32 pagesApr 2023Abhilash JoseNo ratings yet
- Daa LabDocument22 pagesDaa Labvikas 5G9No ratings yet
- Ann Practical AllDocument23 pagesAnn Practical Allmst aheNo ratings yet
- 15CSL76 StudentsDocument18 pages15CSL76 StudentsYounus KhanNo ratings yet
- Miscellaneous Maple4llDocument4 pagesMiscellaneous Maple4llJean ReneNo ratings yet
- Python Class PRGDocument54 pagesPython Class PRGSyed SalmanNo ratings yet
- Aiml LabDocument13 pagesAiml LabAishwarya BiradarNo ratings yet
- ML Final-1Document7 pagesML Final-1shrinivaspawar350No ratings yet
- Python ExampleDocument43 pagesPython ExampleSri AshishNo ratings yet
- Project IpDocument51 pagesProject IpDwarkesh savaliaNo ratings yet
- AssDocument5 pagesAssTaqwa ElsayedNo ratings yet
- Exe 1Document13 pagesExe 1jaya pandiNo ratings yet
- 100 Python Examples.Document44 pages100 Python Examples.abhimanyu thakurNo ratings yet
- Scientific Calculator FinalllDocument10 pagesScientific Calculator Finalll2260 Shreya SonkusareAI&DSNo ratings yet
- Driver Packaging Utility User Guide MinoltaDocument54 pagesDriver Packaging Utility User Guide MinoltagedangboyNo ratings yet
- Business ProposalDocument5 pagesBusiness ProposalMary Grace Castañeda FloresNo ratings yet
- Plot Hooks: /U/Tundrawolfe /U/ZapzoroathDocument35 pagesPlot Hooks: /U/Tundrawolfe /U/ZapzoroathAdrian B.No ratings yet
- Property Notes A.Y. 2011-2012 Atty. Lopez-Rosario LecturesDocument7 pagesProperty Notes A.Y. 2011-2012 Atty. Lopez-Rosario LecturesAlit Dela CruzNo ratings yet
- Did The Berlin Blockade Bring Europe Close To Nuclear WarDocument2 pagesDid The Berlin Blockade Bring Europe Close To Nuclear WarJames HillNo ratings yet
- William Duarte - Delphi® para Android e iOS - Desenvolvendo Aplicativos MóveisDocument1 pageWilliam Duarte - Delphi® para Android e iOS - Desenvolvendo Aplicativos MóveisRonaldo NascimentoNo ratings yet
- 0000004232-Ashok Leyland LTD FullDocument5 pages0000004232-Ashok Leyland LTD FullVenkat Parthasarathy100% (1)
- Unnatural Nature of ScienceDocument5 pagesUnnatural Nature of ScienceXia AlliaNo ratings yet
- Apptitude 1Document11 pagesApptitude 1Javed IqbalNo ratings yet
- Pixel Tactics Rules Summary v1Document2 pagesPixel Tactics Rules Summary v1Vicente Martínez LópezNo ratings yet
- Critical Vices of PostmodernismDocument276 pagesCritical Vices of PostmodernismmytitaniciraqNo ratings yet
- Rahiotis2007 CPP Acp Dentin ReDocument4 pagesRahiotis2007 CPP Acp Dentin ReARUNA BharathiNo ratings yet
- 004 - Four Dimensions of Service ManagementDocument7 pages004 - Four Dimensions of Service ManagementAbdoo AbdooNo ratings yet
- Visual Design-Composition and Layout PrinciplesDocument5 pagesVisual Design-Composition and Layout PrinciplesRady100% (1)
- Interim Report EDUMENTORDocument17 pagesInterim Report EDUMENTORRajat Gaulkar100% (1)
- THE Strategic Mindset: Applying Strategic Thinking Skills For Organizational SuccessDocument10 pagesTHE Strategic Mindset: Applying Strategic Thinking Skills For Organizational SuccessDanielle GraceNo ratings yet
- Bray Series 35 36 Weights DimensionsDocument1 pageBray Series 35 36 Weights Dimensionsjacquesstrappe06No ratings yet
- Apple Iphone XR Price - Google SearchDocument1 pageApple Iphone XR Price - Google Searchkamarie DavisNo ratings yet
- The Works of Agatha Christie (v1.1)Document8 pagesThe Works of Agatha Christie (v1.1)Sam YeoNo ratings yet
- FprEN 1998-1-1 (2024)Document123 pagesFprEN 1998-1-1 (2024)MarcoNo ratings yet
- KUPWARADocument12 pagesKUPWARASbi reco north AnuragNo ratings yet
- EDFS - Request Memento For Reassigned Personnel of 205THWDocument1 pageEDFS - Request Memento For Reassigned Personnel of 205THWRomeo GarciaNo ratings yet
- Spirit NazarethDocument4 pagesSpirit NazarethPeter JackNo ratings yet
- UTH1. Bicycle Facilities Planning and Design by DR - RsiguaDocument52 pagesUTH1. Bicycle Facilities Planning and Design by DR - RsiguaGulienne Randee Mickhaela ZamoraNo ratings yet
- List of Red-Light Districts: Jump To Navigation Jump To SearchDocument32 pagesList of Red-Light Districts: Jump To Navigation Jump To SearchsudeepomNo ratings yet
- 2023 Career Roadmap Template (Editable)Document10 pages2023 Career Roadmap Template (Editable)Ebube IloNo ratings yet
- Michael King - PresentationDocument14 pagesMichael King - PresentationArk GroupNo ratings yet
- Business LetterDocument5 pagesBusiness LetterBeugh RiveraNo ratings yet
- J OperatorDocument6 pagesJ OperatorManikandan SundararajNo ratings yet