Download as pdf or txt
You might also like
- Time Series Analysis by State Space MethodsDocument369 pagesTime Series Analysis by State Space Methodsumarsabo100% (6)
- Data Mini ProjDocument44 pagesData Mini ProjZohaib Imam100% (2)
- Dca6105 - Computer ArchitectureDocument6 pagesDca6105 - Computer Architectureanshika mahajanNo ratings yet
- CA Unit IV Notes Part 1 PDFDocument17 pagesCA Unit IV Notes Part 1 PDFaarockiaabins AP - II - CSENo ratings yet
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Cloud ComputingDocument27 pagesCloud ComputingmanojNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- Chapter 3-Processes: Mulugeta ADocument34 pagesChapter 3-Processes: Mulugeta Amerhatsidik melkeNo ratings yet
- Lecture 10Document34 pagesLecture 10MAIMONA KHALIDNo ratings yet
- OS NotesDocument10 pagesOS NotesKundan KumarNo ratings yet
- Windows Operating SystemDocument9 pagesWindows Operating Systemthesingh_0No ratings yet
- Computer ArchitectureDocument29 pagesComputer ArchitectureKaushik CNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument47 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Unit 9: Fundamentals of Parallel ProcessingDocument16 pagesUnit 9: Fundamentals of Parallel ProcessingLoganathan RmNo ratings yet
- Parallelism in Computer ArchitectureDocument27 pagesParallelism in Computer ArchitectureKumarNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Chapter 1: Multi Threaded Programming: (Operating Systems-18Cs43)Document39 pagesChapter 1: Multi Threaded Programming: (Operating Systems-18Cs43)Vaishak kamathNo ratings yet
- Week1 - Parallel and Distributed ComputingDocument46 pagesWeek1 - Parallel and Distributed ComputingA NNo ratings yet
- Cloud Computing - Lecture 3Document22 pagesCloud Computing - Lecture 3Muhammad FahadNo ratings yet
- Hardware MultithreadingDocument10 pagesHardware MultithreadingFarin KhanNo ratings yet
- Parallel Processing in LINUX (PareshDocument13 pagesParallel Processing in LINUX (PareshDIPAK VINAYAK SHIRBHATENo ratings yet
- Parallel Final ExamDocument9 pagesParallel Final ExamjhoshepsmithNo ratings yet
- 5 Marks Q. Describe Array Processor ArchitectureDocument11 pages5 Marks Q. Describe Array Processor ArchitectureGaurav BiswasNo ratings yet
- Lecture 10 Parallel Computing - by FQDocument29 pagesLecture 10 Parallel Computing - by FQaina syafNo ratings yet
- Operating SystemDocument16 pagesOperating SystemGadgetNo ratings yet
- Parallel Computing Seminar ReportDocument35 pagesParallel Computing Seminar ReportAmeya Waghmare100% (3)
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- OS MOD - 2 NotesDocument44 pagesOS MOD - 2 NotesSHALINI KGNo ratings yet
- Parallel Processing ReportDocument9 pagesParallel Processing ReportZaidBNo ratings yet
- Chapter 4: Threads & Concurrency: Difference Between Multiprocessing and MultithreadingDocument20 pagesChapter 4: Threads & Concurrency: Difference Between Multiprocessing and MultithreadingJamal alomNo ratings yet
- CC UNIT-1 MaterialDocument26 pagesCC UNIT-1 Materialarvindreddy013No ratings yet
- Lecture-13-14 Parallel and Distributed Systems Programming Models-JameelDocument70 pagesLecture-13-14 Parallel and Distributed Systems Programming Models-JameelAbdul BariiNo ratings yet
- Provi MiDocument6 pagesProvi MialbjoridollaniNo ratings yet
- Mohsin 019 Quiz 1 OSDocument5 pagesMohsin 019 Quiz 1 OSMohsin MajeedNo ratings yet
- Computer Architecture Unit V - Advanced Architecture Part-ADocument4 pagesComputer Architecture Unit V - Advanced Architecture Part-AJennifer PeterNo ratings yet
- Chapter 6 Advanced TopicsDocument14 pagesChapter 6 Advanced TopicsRoshanNo ratings yet
- What Are Batch Processing System and Real Time Processing System and The Difference Between ThemDocument6 pagesWhat Are Batch Processing System and Real Time Processing System and The Difference Between ThemfikaduNo ratings yet
- CH 4 (Threads)Document8 pagesCH 4 (Threads)Muhammad ImranNo ratings yet
- High Performance Computing-1 PDFDocument15 pagesHigh Performance Computing-1 PDFPriyanka JadhavNo ratings yet
- Watercolor Organic Shapes SlidesManiaDocument23 pagesWatercolor Organic Shapes SlidesManiaAyush kumarNo ratings yet
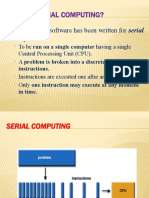
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Unit 5 (Coa) NotesDocument35 pagesUnit 5 (Coa) NotesmudiyalaruchithaNo ratings yet
- Introduction To Parallel and Distributed ComputingDocument29 pagesIntroduction To Parallel and Distributed ComputingBerto ZerimarNo ratings yet
- Advanced Computer ArchitectureDocument28 pagesAdvanced Computer ArchitectureSameer KhudeNo ratings yet
- CS0051 - Module 01Document52 pagesCS0051 - Module 01Ron BayaniNo ratings yet
- Multi-Core Processors: Page 1 of 25Document25 pagesMulti-Core Processors: Page 1 of 25nnNo ratings yet
- Parallel Systems AssignmentDocument11 pagesParallel Systems AssignmentmahaNo ratings yet
- Activity 1: - Jobs: 1. ComparisonDocument15 pagesActivity 1: - Jobs: 1. Comparisoni180538 Vi ShalNo ratings yet
- Assignment Os: Saqib Javed 11912Document8 pagesAssignment Os: Saqib Javed 11912Saqib JavedNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- CS0051 - Module 01 - Subtopic 1Document27 pagesCS0051 - Module 01 - Subtopic 1ronbayani2000No ratings yet
- Chapter 3 ProcessesDocument42 pagesChapter 3 ProcessesLusi ሉሲNo ratings yet
- Arkom 13-40275Document32 pagesArkom 13-40275Harier Hard RierNo ratings yet
- Operating SystemDocument14 pagesOperating SystemNishant MishraNo ratings yet
- Operating System 2Document29 pagesOperating System 2nazim khanNo ratings yet
- Institution of Technology School of Computing Department of Information TechnologyDocument42 pagesInstitution of Technology School of Computing Department of Information TechnologysemagnNo ratings yet
- Notes Xii Dec 2020Document82 pagesNotes Xii Dec 2020Liza MalikNo ratings yet
- Parallel Processors From Client To Cloud: Omputer Rganization and EsignDocument43 pagesParallel Processors From Client To Cloud: Omputer Rganization and EsignPavithra JanarthananNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Computer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignFrom EverandComputer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignNo ratings yet
- Partial Solutions To Exercises 2.2Document4 pagesPartial Solutions To Exercises 2.2Luhan ZhaoNo ratings yet
- M16 Petrophysical Modeling 2007Document11 pagesM16 Petrophysical Modeling 2007msfz751No ratings yet
- Statistical Intervals For A Single SampleDocument31 pagesStatistical Intervals For A Single SampleBui Tien DatNo ratings yet
- A Review of Industrial MIMO Decoupling ControlDocument9 pagesA Review of Industrial MIMO Decoupling ControlpraveenmandeNo ratings yet
- Vision Based Autonomous Landing of UAVDocument12 pagesVision Based Autonomous Landing of UAVAnurag PandeyNo ratings yet
- Objectives:: The General Form of The Yokogawa Cs3000 and Centumvp Pid ControllersDocument2 pagesObjectives:: The General Form of The Yokogawa Cs3000 and Centumvp Pid ControllersSudeep MukherjeeNo ratings yet
- Essentials of Digital Signal Processing (2014)Document763 pagesEssentials of Digital Signal Processing (2014)Jeremy Wishner100% (7)
- Fermi Dirac Distribution Function PDFDocument2 pagesFermi Dirac Distribution Function PDFScott50% (2)
- Digital Signal Processing First Global Edition Full ChapterDocument41 pagesDigital Signal Processing First Global Edition Full Chaptertommy.kondracki100100% (27)
- Bab IvDocument18 pagesBab IvAgung MaulanaNo ratings yet
- Efficient Designs Lecture 3 (SEN1221 - Part II) : Eric Molin - TU DelftDocument68 pagesEfficient Designs Lecture 3 (SEN1221 - Part II) : Eric Molin - TU DelftBerkan CeylanNo ratings yet
- Lasso and Group Lasso: Peter B Uhlmann ETH Z UrichDocument101 pagesLasso and Group Lasso: Peter B Uhlmann ETH Z UrichPraveenNo ratings yet
- Predicting Project Delivery Rates Using The Naive-Bayes ClassifierDocument20 pagesPredicting Project Delivery Rates Using The Naive-Bayes ClassifierAnita GutierrezNo ratings yet
- Assignments-Discrete MathsDocument8 pagesAssignments-Discrete MathsSundeep ChopraNo ratings yet
- NR-311102 - Digital Signal ProcessingDocument8 pagesNR-311102 - Digital Signal ProcessingSrinivasa Rao GNo ratings yet
- Mte 10Document10 pagesMte 10VipinNo ratings yet
- RC4 and WEP: By: Anthony Gervasi & Adam DickinsonDocument18 pagesRC4 and WEP: By: Anthony Gervasi & Adam DickinsonNeha VermaNo ratings yet
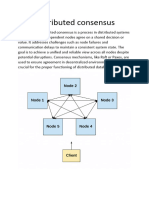
- Distributed ConsensusDocument6 pagesDistributed Consensusfellahmusstapha2002No ratings yet
- Review Question Econometrics - 2Document3 pagesReview Question Econometrics - 2OLIVA MACHUMUNo ratings yet
- Improving Performance of Spatio-Temporal Machine Learning Models Using Forward Feature Selection and Target-Oriented ValidationDocument9 pagesImproving Performance of Spatio-Temporal Machine Learning Models Using Forward Feature Selection and Target-Oriented Validations8nd11d UNINo ratings yet
- CS6711 Security Lab Manual PDFDocument82 pagesCS6711 Security Lab Manual PDFAathi LinNo ratings yet
- Paper Survey On Performance Metrics For Object Detection AlgorithmsDocument6 pagesPaper Survey On Performance Metrics For Object Detection Algorithmstest ptNo ratings yet
- DL Notes 1 5 Deep LearningDocument189 pagesDL Notes 1 5 Deep Learningsugumar100% (1)
- Solutions: 10-601 Machine Learning, Midterm Exam: Spring 2008 SolutionsDocument8 pagesSolutions: 10-601 Machine Learning, Midterm Exam: Spring 2008 Solutionsreshma khemchandaniNo ratings yet
- Mixed Exam-Style Questions On DifferentiationDocument2 pagesMixed Exam-Style Questions On Differentiationsamsweet96No ratings yet
- Sesi 5a - Ukuran Asosiasi 2011Document50 pagesSesi 5a - Ukuran Asosiasi 2011Tyra Septi DianaNo ratings yet
- Advanced Structural Analysis - SyllabusDocument2 pagesAdvanced Structural Analysis - SyllabusMubasheerNo ratings yet
- Create Properties BMIDEDocument2 pagesCreate Properties BMIDEcad cadNo ratings yet