
Econ321 2017 Tutorial 2 Lab
Econ321 2017 Tutorial 2 Lab
You might also like
- FinalReport Life InsuranceDocument34 pagesFinalReport Life InsuranceShreyaPrakash75% (4)
- MATH 1281 Written Assignment Unit 6Document14 pagesMATH 1281 Written Assignment Unit 6Daniel GayNo ratings yet
- Lecture 11Document4 pagesLecture 11armailgmNo ratings yet
- Regression Analysis - VCE Further MathematicsDocument5 pagesRegression Analysis - VCE Further MathematicsPNo ratings yet
- Exa Eco II Reevaluacion 2013 Javi ENGLISH DEFINITIVO SOLUZIONIDocument3 pagesExa Eco II Reevaluacion 2013 Javi ENGLISH DEFINITIVO SOLUZIONIdamian camargoNo ratings yet
- Lecture 18. Serial Correlation: Testing and Estimation Testing For Serial CorrelationDocument21 pagesLecture 18. Serial Correlation: Testing and Estimation Testing For Serial CorrelationMilan DjordjevicNo ratings yet
- Formula SheetDocument7 pagesFormula SheetMohit RakyanNo ratings yet
- Autocorrelation - Computer LabDocument7 pagesAutocorrelation - Computer LabrajkumarbaimadNo ratings yet
- Notes On ARIMA Modelling: Brian Borchers November 22, 2002Document19 pagesNotes On ARIMA Modelling: Brian Borchers November 22, 2002Daryl ChinNo ratings yet
- Manual Eviews (Extracto)Document6 pagesManual Eviews (Extracto)Rafexo MamaniNo ratings yet
- STAT2201 - Ch. 14 Excel Files - UpdatedDocument41 pagesSTAT2201 - Ch. 14 Excel Files - UpdatedGurjot SinghNo ratings yet
- Spring07 OBrien TDocument40 pagesSpring07 OBrien Tsatztg6089No ratings yet
- Analyze The E-Views Report: R Var ( Y) Var (Y) Ess Tss Var (E) Var (Y) Rss Nvar (Y) R RDocument5 pagesAnalyze The E-Views Report: R Var ( Y) Var (Y) Ess Tss Var (E) Var (Y) Rss Nvar (Y) R REmiraslan MhrrovNo ratings yet
- Chapter 12 Homework Answer: T T+J TDocument3 pagesChapter 12 Homework Answer: T T+J TkNo ratings yet
- Autocorrelation: When Error Terms U and U, U,, U Are Correlated, We Call This The Serial Correlation orDocument27 pagesAutocorrelation: When Error Terms U and U, U,, U Are Correlated, We Call This The Serial Correlation orKathiravan GopalanNo ratings yet
- Chapter 13. Time Series Regression: Serial Correlation TheoryDocument26 pagesChapter 13. Time Series Regression: Serial Correlation TheorysubkmrNo ratings yet
- MFIN 514 Mod 3Document39 pagesMFIN 514 Mod 3Liam FraleighNo ratings yet
- Econometrics.: Home Assignment # 7Document5 pagesEconometrics.: Home Assignment # 7Гая ЗимрутянNo ratings yet
- Estimating A VAR - GretlDocument9 pagesEstimating A VAR - Gretlkaddour7108No ratings yet
- CRLB Vector ProofDocument24 pagesCRLB Vector Proofleena_shah25No ratings yet
- Final Exam SolutionsDocument7 pagesFinal Exam SolutionsMeliha PalošNo ratings yet
- EViewsDocument9 pagesEViewsroger02No ratings yet
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Simple Nonlinear Time Series Models For Returns: José Maria GasparDocument10 pagesSimple Nonlinear Time Series Models For Returns: José Maria GasparQueen RaniaNo ratings yet
- Mathematical StudiesDocument56 pagesMathematical StudiesOayes MiddaNo ratings yet
- 9bWJ4riXFBGGECh12 AutocorrelationDocument17 pages9bWJ4riXFBGGECh12 AutocorrelationRohan Deepika RawalNo ratings yet
- Chapter 12 Heteroskedasticity PDFDocument20 pagesChapter 12 Heteroskedasticity PDFVictor ManuelNo ratings yet
- Stata Lab4 2023Document36 pagesStata Lab4 2023Aadhav JayarajNo ratings yet
- SolutionDocument5 pagesSolutionMuhammad ArhamNo ratings yet
- Econometrics 2021Document9 pagesEconometrics 2021Yusuf ShotundeNo ratings yet
- Lab4 Orthogonal Contrasts and Multiple ComparisonsDocument14 pagesLab4 Orthogonal Contrasts and Multiple ComparisonsjorbelocoNo ratings yet
- CDS 110b Norms of Signals and SystemsDocument10 pagesCDS 110b Norms of Signals and SystemsSatyavir YadavNo ratings yet
- Estimating Demand: Using Regression MethodDocument17 pagesEstimating Demand: Using Regression MethodNabiha AzadNo ratings yet
- 04 BasicAnalysesDocument44 pages04 BasicAnalysesCotta LeeNo ratings yet
- AutocorrelationDocument38 pagesAutocorrelationHoàng TuấnNo ratings yet
- e y y ρ α n t e σ y y y α: Unit Roots and CointegrationDocument13 pagese y y ρ α n t e σ y y y α: Unit Roots and Cointegrationsmazadamha sulaimanNo ratings yet
- Gauss Markov TheoremDocument16 pagesGauss Markov TheoremNidhiNo ratings yet
- Session AutocorrelationDocument39 pagesSession Autocorrelationhilmiazis15No ratings yet
- Topic 11: Autocorrelation: ECO2009: Empirical Economic AnalysisDocument27 pagesTopic 11: Autocorrelation: ECO2009: Empirical Economic Analysissmurphy1234No ratings yet
- Circular Data AnalysisDocument29 pagesCircular Data AnalysisBenthosmanNo ratings yet
- Capitulo 3 (Ackermanf)Document20 pagesCapitulo 3 (Ackermanf)Gabyta XikitaaNo ratings yet
- Auto PartDocument21 pagesAuto Partaya.said2020No ratings yet
- Model Specification and Data Problems: 8.1 Functional Form MisspecificationDocument9 pagesModel Specification and Data Problems: 8.1 Functional Form MisspecificationajayikayodeNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Korelasi SeriDocument24 pagesKorelasi SeriBalai Rawa2020No ratings yet
- Economics 536 Introduction To Specification Testing in Dynamic Econometric ModelsDocument6 pagesEconomics 536 Introduction To Specification Testing in Dynamic Econometric ModelsMaria RoaNo ratings yet
- Critical Values For A Steady State IdentifierDocument4 pagesCritical Values For A Steady State IdentifierJuan OlivaresNo ratings yet
- Final Exam Solutions: N×N N×P M×NDocument37 pagesFinal Exam Solutions: N×N N×P M×NMorokot AngelaNo ratings yet
- Returns and Log-Returns: Quantitative Risk Management IndexDocument3 pagesReturns and Log-Returns: Quantitative Risk Management IndexMichele ValenariNo ratings yet
- Simple Linear Regression in RDocument17 pagesSimple Linear Regression in RGianni GorgoglioneNo ratings yet
- QuasilikelihoodDocument14 pagesQuasilikelihoodK6 LyonNo ratings yet
- 2.2.1 Example: Income and Money Supply Using SIMPLIS Syntax: Example 4: Non-Recursive SystemDocument24 pages2.2.1 Example: Income and Money Supply Using SIMPLIS Syntax: Example 4: Non-Recursive SystemcolegiulNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Econometrics CRT M2: Regression Model EvaluationDocument7 pagesEconometrics CRT M2: Regression Model EvaluationDickson phiriNo ratings yet
- Summary On Nonparametric Pricing of Interest Rate Derivative SecuritiesDocument36 pagesSummary On Nonparametric Pricing of Interest Rate Derivative SecuritiesWang Chun WeiNo ratings yet
- Practice 1 So LNDocument5 pagesPractice 1 So LNAdesh Nidhi TiwaryNo ratings yet
- Regression 2Document25 pagesRegression 2Henrique CalhauNo ratings yet
- Forecasting (Prediction) Limits: Example Linear Deterministic Trend Estimated by Least-SquaresDocument27 pagesForecasting (Prediction) Limits: Example Linear Deterministic Trend Estimated by Least-Squareszahid_rezaNo ratings yet
- CS6700 RL 2024 Wa1Document7 pagesCS6700 RL 2024 Wa1Rahul me20b145No ratings yet
- Remedial Measures Purdue - EduDocument28 pagesRemedial Measures Purdue - EduDash CorderoNo ratings yet
- Estimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseDocument17 pagesEstimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseScience DirectNo ratings yet
- Sales Force Modeling State of The Field and ResearDocument19 pagesSales Force Modeling State of The Field and Researsreenandan.kbNo ratings yet
- 4123-Article Text-15297-1-10-20211020Document16 pages4123-Article Text-15297-1-10-20211020Endi TiyasNo ratings yet
- Exact InferenceDocument18 pagesExact InferenceRoger Asencios NuñezNo ratings yet
- 2019-A New Two-Par (Exponentiated Shanker) Distr Properties and ApplicationsDocument14 pages2019-A New Two-Par (Exponentiated Shanker) Distr Properties and ApplicationsssssNo ratings yet
- Croon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsDocument23 pagesCroon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsPhuoc NguyenNo ratings yet
- 2 Simple Regression ModelDocument55 pages2 Simple Regression Modelfitra purnaNo ratings yet
- Noc20-Cs28 Week 06 Assignment 001 PDFDocument3 pagesNoc20-Cs28 Week 06 Assignment 001 PDFUKANI VEDANTNo ratings yet
- TutorialDocument42 pagesTutorialRevathi BelurNo ratings yet
- Regression Analysis With ScilabDocument57 pagesRegression Analysis With Scilabwakko29No ratings yet
- Lampiran Uji Regresi Linear BergandaDocument3 pagesLampiran Uji Regresi Linear Bergandakhrisna02No ratings yet
- University of Dhaka Department of Statistics Syllabus For 4-Year B.S. (Honors) Starting Sessions: 2017-2018Document45 pagesUniversity of Dhaka Department of Statistics Syllabus For 4-Year B.S. (Honors) Starting Sessions: 2017-2018Janus MalikNo ratings yet
- Jawa TengahDocument20 pagesJawa Tengahayu desiNo ratings yet
- Z Score TablesDocument5 pagesZ Score TablesErlangga SatryaNo ratings yet
- GMM With StataDocument53 pagesGMM With StataDevin-KonulRichmondNo ratings yet
- Chapter 2 SLRMDocument40 pagesChapter 2 SLRMmerondemekets12347No ratings yet
- 20 MASTER Exercise Answers MBADocument38 pages20 MASTER Exercise Answers MBASimbarashe Stewart KamwendoNo ratings yet
- Assignment 4Document3 pagesAssignment 4godlionwolfNo ratings yet
- Assignment 2 QTBDocument5 pagesAssignment 2 QTBTamanna KotnalaNo ratings yet
- Jackknife Bias Estimator, Standard Error and Pseudo-ValueDocument14 pagesJackknife Bias Estimator, Standard Error and Pseudo-ValueSherena KhatunNo ratings yet
- (Applied Optimization) Michael Doumpos, Constantin Zopounidis - Multicriteria Decision Aid Classification Methods - Springer (2002) PDFDocument263 pages(Applied Optimization) Michael Doumpos, Constantin Zopounidis - Multicriteria Decision Aid Classification Methods - Springer (2002) PDFothmanheathNo ratings yet
- Homework 1: Is Normally DistributedDocument2 pagesHomework 1: Is Normally DistributedAndres OrtizNo ratings yet
- Discrete Choice Models 2Document19 pagesDiscrete Choice Models 2Pebri HerryNo ratings yet
- Regression An OvaDocument24 pagesRegression An Ovaatul_sanchetiNo ratings yet
- Simultaneous Equations ModelsDocument30 pagesSimultaneous Equations ModelsNISHANTNo ratings yet
- Part 1: Simple Exponential Smoothing (α = 0.4) : t t t tDocument3 pagesPart 1: Simple Exponential Smoothing (α = 0.4) : t t t tTushNo ratings yet
- M.Sc. Statistics and ComputingDocument27 pagesM.Sc. Statistics and Computingsneha raoNo ratings yet
- Reliability Analysis For RepairableDocument261 pagesReliability Analysis For RepairableMuhammad GhufranNo ratings yet










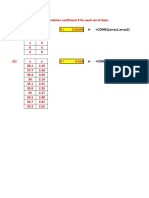





























































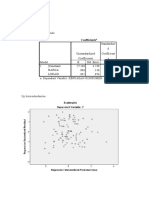

















Download as docx, pdf, or txt
You might also like
- FinalReport Life InsuranceDocument34 pagesFinalReport Life InsuranceShreyaPrakash75% (4)
- MATH 1281 Written Assignment Unit 6Document14 pagesMATH 1281 Written Assignment Unit 6Daniel GayNo ratings yet
- Lecture 11Document4 pagesLecture 11armailgmNo ratings yet
- Regression Analysis - VCE Further MathematicsDocument5 pagesRegression Analysis - VCE Further MathematicsPNo ratings yet
- Exa Eco II Reevaluacion 2013 Javi ENGLISH DEFINITIVO SOLUZIONIDocument3 pagesExa Eco II Reevaluacion 2013 Javi ENGLISH DEFINITIVO SOLUZIONIdamian camargoNo ratings yet
- Lecture 18. Serial Correlation: Testing and Estimation Testing For Serial CorrelationDocument21 pagesLecture 18. Serial Correlation: Testing and Estimation Testing For Serial CorrelationMilan DjordjevicNo ratings yet
- Formula SheetDocument7 pagesFormula SheetMohit RakyanNo ratings yet
- Autocorrelation - Computer LabDocument7 pagesAutocorrelation - Computer LabrajkumarbaimadNo ratings yet
- Notes On ARIMA Modelling: Brian Borchers November 22, 2002Document19 pagesNotes On ARIMA Modelling: Brian Borchers November 22, 2002Daryl ChinNo ratings yet
- Manual Eviews (Extracto)Document6 pagesManual Eviews (Extracto)Rafexo MamaniNo ratings yet
- STAT2201 - Ch. 14 Excel Files - UpdatedDocument41 pagesSTAT2201 - Ch. 14 Excel Files - UpdatedGurjot SinghNo ratings yet
- Spring07 OBrien TDocument40 pagesSpring07 OBrien Tsatztg6089No ratings yet
- Analyze The E-Views Report: R Var ( Y) Var (Y) Ess Tss Var (E) Var (Y) Rss Nvar (Y) R RDocument5 pagesAnalyze The E-Views Report: R Var ( Y) Var (Y) Ess Tss Var (E) Var (Y) Rss Nvar (Y) R REmiraslan MhrrovNo ratings yet
- Chapter 12 Homework Answer: T T+J TDocument3 pagesChapter 12 Homework Answer: T T+J TkNo ratings yet
- Autocorrelation: When Error Terms U and U, U,, U Are Correlated, We Call This The Serial Correlation orDocument27 pagesAutocorrelation: When Error Terms U and U, U,, U Are Correlated, We Call This The Serial Correlation orKathiravan GopalanNo ratings yet
- Chapter 13. Time Series Regression: Serial Correlation TheoryDocument26 pagesChapter 13. Time Series Regression: Serial Correlation TheorysubkmrNo ratings yet
- MFIN 514 Mod 3Document39 pagesMFIN 514 Mod 3Liam FraleighNo ratings yet
- Econometrics.: Home Assignment # 7Document5 pagesEconometrics.: Home Assignment # 7Гая ЗимрутянNo ratings yet
- Estimating A VAR - GretlDocument9 pagesEstimating A VAR - Gretlkaddour7108No ratings yet
- CRLB Vector ProofDocument24 pagesCRLB Vector Proofleena_shah25No ratings yet
- Final Exam SolutionsDocument7 pagesFinal Exam SolutionsMeliha PalošNo ratings yet
- EViewsDocument9 pagesEViewsroger02No ratings yet
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Simple Nonlinear Time Series Models For Returns: José Maria GasparDocument10 pagesSimple Nonlinear Time Series Models For Returns: José Maria GasparQueen RaniaNo ratings yet
- Mathematical StudiesDocument56 pagesMathematical StudiesOayes MiddaNo ratings yet
- 9bWJ4riXFBGGECh12 AutocorrelationDocument17 pages9bWJ4riXFBGGECh12 AutocorrelationRohan Deepika RawalNo ratings yet
- Chapter 12 Heteroskedasticity PDFDocument20 pagesChapter 12 Heteroskedasticity PDFVictor ManuelNo ratings yet
- Stata Lab4 2023Document36 pagesStata Lab4 2023Aadhav JayarajNo ratings yet
- SolutionDocument5 pagesSolutionMuhammad ArhamNo ratings yet
- Econometrics 2021Document9 pagesEconometrics 2021Yusuf ShotundeNo ratings yet
- Lab4 Orthogonal Contrasts and Multiple ComparisonsDocument14 pagesLab4 Orthogonal Contrasts and Multiple ComparisonsjorbelocoNo ratings yet
- CDS 110b Norms of Signals and SystemsDocument10 pagesCDS 110b Norms of Signals and SystemsSatyavir YadavNo ratings yet
- Estimating Demand: Using Regression MethodDocument17 pagesEstimating Demand: Using Regression MethodNabiha AzadNo ratings yet
- 04 BasicAnalysesDocument44 pages04 BasicAnalysesCotta LeeNo ratings yet
- AutocorrelationDocument38 pagesAutocorrelationHoàng TuấnNo ratings yet
- e y y ρ α n t e σ y y y α: Unit Roots and CointegrationDocument13 pagese y y ρ α n t e σ y y y α: Unit Roots and Cointegrationsmazadamha sulaimanNo ratings yet
- Gauss Markov TheoremDocument16 pagesGauss Markov TheoremNidhiNo ratings yet
- Session AutocorrelationDocument39 pagesSession Autocorrelationhilmiazis15No ratings yet
- Topic 11: Autocorrelation: ECO2009: Empirical Economic AnalysisDocument27 pagesTopic 11: Autocorrelation: ECO2009: Empirical Economic Analysissmurphy1234No ratings yet
- Circular Data AnalysisDocument29 pagesCircular Data AnalysisBenthosmanNo ratings yet
- Capitulo 3 (Ackermanf)Document20 pagesCapitulo 3 (Ackermanf)Gabyta XikitaaNo ratings yet
- Auto PartDocument21 pagesAuto Partaya.said2020No ratings yet
- Model Specification and Data Problems: 8.1 Functional Form MisspecificationDocument9 pagesModel Specification and Data Problems: 8.1 Functional Form MisspecificationajayikayodeNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Korelasi SeriDocument24 pagesKorelasi SeriBalai Rawa2020No ratings yet
- Economics 536 Introduction To Specification Testing in Dynamic Econometric ModelsDocument6 pagesEconomics 536 Introduction To Specification Testing in Dynamic Econometric ModelsMaria RoaNo ratings yet
- Critical Values For A Steady State IdentifierDocument4 pagesCritical Values For A Steady State IdentifierJuan OlivaresNo ratings yet
- Final Exam Solutions: N×N N×P M×NDocument37 pagesFinal Exam Solutions: N×N N×P M×NMorokot AngelaNo ratings yet
- Returns and Log-Returns: Quantitative Risk Management IndexDocument3 pagesReturns and Log-Returns: Quantitative Risk Management IndexMichele ValenariNo ratings yet
- Simple Linear Regression in RDocument17 pagesSimple Linear Regression in RGianni GorgoglioneNo ratings yet
- QuasilikelihoodDocument14 pagesQuasilikelihoodK6 LyonNo ratings yet
- 2.2.1 Example: Income and Money Supply Using SIMPLIS Syntax: Example 4: Non-Recursive SystemDocument24 pages2.2.1 Example: Income and Money Supply Using SIMPLIS Syntax: Example 4: Non-Recursive SystemcolegiulNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Econometrics CRT M2: Regression Model EvaluationDocument7 pagesEconometrics CRT M2: Regression Model EvaluationDickson phiriNo ratings yet
- Summary On Nonparametric Pricing of Interest Rate Derivative SecuritiesDocument36 pagesSummary On Nonparametric Pricing of Interest Rate Derivative SecuritiesWang Chun WeiNo ratings yet
- Practice 1 So LNDocument5 pagesPractice 1 So LNAdesh Nidhi TiwaryNo ratings yet
- Regression 2Document25 pagesRegression 2Henrique CalhauNo ratings yet
- Forecasting (Prediction) Limits: Example Linear Deterministic Trend Estimated by Least-SquaresDocument27 pagesForecasting (Prediction) Limits: Example Linear Deterministic Trend Estimated by Least-Squareszahid_rezaNo ratings yet
- CS6700 RL 2024 Wa1Document7 pagesCS6700 RL 2024 Wa1Rahul me20b145No ratings yet
- Remedial Measures Purdue - EduDocument28 pagesRemedial Measures Purdue - EduDash CorderoNo ratings yet
- Estimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseDocument17 pagesEstimating The Population Mean in Stratified Population Using Auxiliary Information Under Non-ResponseScience DirectNo ratings yet
- Sales Force Modeling State of The Field and ResearDocument19 pagesSales Force Modeling State of The Field and Researsreenandan.kbNo ratings yet
- 4123-Article Text-15297-1-10-20211020Document16 pages4123-Article Text-15297-1-10-20211020Endi TiyasNo ratings yet
- Exact InferenceDocument18 pagesExact InferenceRoger Asencios NuñezNo ratings yet
- 2019-A New Two-Par (Exponentiated Shanker) Distr Properties and ApplicationsDocument14 pages2019-A New Two-Par (Exponentiated Shanker) Distr Properties and ApplicationsssssNo ratings yet
- Croon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsDocument23 pagesCroon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsPhuoc NguyenNo ratings yet
- 2 Simple Regression ModelDocument55 pages2 Simple Regression Modelfitra purnaNo ratings yet
- Noc20-Cs28 Week 06 Assignment 001 PDFDocument3 pagesNoc20-Cs28 Week 06 Assignment 001 PDFUKANI VEDANTNo ratings yet
- TutorialDocument42 pagesTutorialRevathi BelurNo ratings yet
- Regression Analysis With ScilabDocument57 pagesRegression Analysis With Scilabwakko29No ratings yet
- Lampiran Uji Regresi Linear BergandaDocument3 pagesLampiran Uji Regresi Linear Bergandakhrisna02No ratings yet
- University of Dhaka Department of Statistics Syllabus For 4-Year B.S. (Honors) Starting Sessions: 2017-2018Document45 pagesUniversity of Dhaka Department of Statistics Syllabus For 4-Year B.S. (Honors) Starting Sessions: 2017-2018Janus MalikNo ratings yet
- Jawa TengahDocument20 pagesJawa Tengahayu desiNo ratings yet
- Z Score TablesDocument5 pagesZ Score TablesErlangga SatryaNo ratings yet
- GMM With StataDocument53 pagesGMM With StataDevin-KonulRichmondNo ratings yet
- Chapter 2 SLRMDocument40 pagesChapter 2 SLRMmerondemekets12347No ratings yet
- 20 MASTER Exercise Answers MBADocument38 pages20 MASTER Exercise Answers MBASimbarashe Stewart KamwendoNo ratings yet
- Assignment 4Document3 pagesAssignment 4godlionwolfNo ratings yet
- Assignment 2 QTBDocument5 pagesAssignment 2 QTBTamanna KotnalaNo ratings yet
- Jackknife Bias Estimator, Standard Error and Pseudo-ValueDocument14 pagesJackknife Bias Estimator, Standard Error and Pseudo-ValueSherena KhatunNo ratings yet
- (Applied Optimization) Michael Doumpos, Constantin Zopounidis - Multicriteria Decision Aid Classification Methods - Springer (2002) PDFDocument263 pages(Applied Optimization) Michael Doumpos, Constantin Zopounidis - Multicriteria Decision Aid Classification Methods - Springer (2002) PDFothmanheathNo ratings yet
- Homework 1: Is Normally DistributedDocument2 pagesHomework 1: Is Normally DistributedAndres OrtizNo ratings yet
- Discrete Choice Models 2Document19 pagesDiscrete Choice Models 2Pebri HerryNo ratings yet
- Regression An OvaDocument24 pagesRegression An Ovaatul_sanchetiNo ratings yet
- Simultaneous Equations ModelsDocument30 pagesSimultaneous Equations ModelsNISHANTNo ratings yet
- Part 1: Simple Exponential Smoothing (α = 0.4) : t t t tDocument3 pagesPart 1: Simple Exponential Smoothing (α = 0.4) : t t t tTushNo ratings yet
- M.Sc. Statistics and ComputingDocument27 pagesM.Sc. Statistics and Computingsneha raoNo ratings yet
- Reliability Analysis For RepairableDocument261 pagesReliability Analysis For RepairableMuhammad GhufranNo ratings yet