Download as pdf or txt
You might also like
- Solutions To Selected Problems-Duda, HartDocument12 pagesSolutions To Selected Problems-Duda, HartTiep VuHuu67% (3)
- Notes and Solutions For: Pattern Recognition by Sergios Theodoridis and Konstantinos Koutroumbas.Document209 pagesNotes and Solutions For: Pattern Recognition by Sergios Theodoridis and Konstantinos Koutroumbas.Mehran Salehi100% (1)
- SF-HC30A3 Manual Sensor de AlturaDocument35 pagesSF-HC30A3 Manual Sensor de AlturaRoberto Medina100% (3)
- Mondeo MY10 - 5Document135 pagesMondeo MY10 - 5t77100% (2)
- Tuo Zhao NotesDocument47 pagesTuo Zhao NotesMarc RomaníNo ratings yet
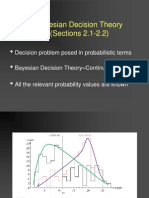
- Bayes Decision Theory: How To Make Decisions in The Presence of Uncertainty?Document16 pagesBayes Decision Theory: How To Make Decisions in The Presence of Uncertainty?Derick MendozaNo ratings yet
- 1 Review and Overview: CS229T/STATS231: Statistical Learning TheoryDocument4 pages1 Review and Overview: CS229T/STATS231: Statistical Learning TheoryyojamaNo ratings yet
- Bayesian Decision Theory: Prof. Richard ZanibbiDocument47 pagesBayesian Decision Theory: Prof. Richard Zanibbishivani_himaniNo ratings yet
- 189 Cheat Sheet Nominicards PDFDocument2 pages189 Cheat Sheet Nominicards PDFt rex422No ratings yet
- 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon UniversityDocument16 pages10-701/15-781 Machine Learning - Midterm Exam, Fall 2010: Aarti Singh Carnegie Mellon UniversityMahi SNo ratings yet
- Homework1 SolutionsDocument5 pagesHomework1 SolutionsMohan VirkhareNo ratings yet
- Statistical Learning Theory: 18.657: Mathematics of Machine LearningDocument9 pagesStatistical Learning Theory: 18.657: Mathematics of Machine LearningMega Silvia HasugianNo ratings yet
- Statistics 512 Notes 26: Decision Theory Continued: FX FX DDocument11 pagesStatistics 512 Notes 26: Decision Theory Continued: FX FX DSandeep SinghNo ratings yet
- 189 Cheat Sheet MinicardsDocument2 pages189 Cheat Sheet Minicardst rex422No ratings yet
- Math Supplement PDFDocument17 pagesMath Supplement PDFRajat GargNo ratings yet
- Assign 1Document5 pagesAssign 1darkmanhiNo ratings yet
- Linear Classification: 1 1 N N I D IDocument33 pagesLinear Classification: 1 1 N N I D ISNo ratings yet
- Estimation Theory PresentationDocument66 pagesEstimation Theory PresentationBengi Mutlu Dülek100% (1)
- Bayes&Voice RecognitionDocument76 pagesBayes&Voice RecognitionEdgar ArroyoNo ratings yet
- FormulaDocument7 pagesFormulaMàddìRèxxShìrshírNo ratings yet
- HW 1 SolDocument6 pagesHW 1 SolSekharNaikNo ratings yet
- Lec5 ClassDocument14 pagesLec5 ClassaraymundomNo ratings yet
- Informationtheory-Lecture Slides-A1 Solutions 5037558613Document0 pagesInformationtheory-Lecture Slides-A1 Solutions 5037558613gowthamkurriNo ratings yet
- Probability For Ai2Document8 pagesProbability For Ai2alphamale173No ratings yet
- STAT 538 Maximum Entropy Models C Marina Meil A Mmp@stat - Washington.eduDocument20 pagesSTAT 538 Maximum Entropy Models C Marina Meil A Mmp@stat - Washington.eduMatthew HagenNo ratings yet
- CS263 - Bayesian Decision TheoryDocument16 pagesCS263 - Bayesian Decision TheoryAaron Carl FernandezNo ratings yet
- The Method of Lagrange MultipliersDocument5 pagesThe Method of Lagrange MultipliersSaurabh TomarNo ratings yet
- An Introduction To Digital CommunicationsDocument70 pagesAn Introduction To Digital Communicationsihab411No ratings yet
- Micro Prelim SolutionsDocument32 pagesMicro Prelim SolutionsMegan JohnstonNo ratings yet
- (Some) Solutions For HW Set # 2Document3 pages(Some) Solutions For HW Set # 2Lokesh SinghNo ratings yet
- Gjpamv17n2 01Document27 pagesGjpamv17n2 01sepwandjitanguepNo ratings yet
- Representer FunctionDocument12 pagesRepresenter FunctionGauravJainNo ratings yet
- Insurance Premium Calculations With Anticipated Utility TheoryDocument14 pagesInsurance Premium Calculations With Anticipated Utility TheoryArnoldQuiranteJustinianaNo ratings yet
- Unit-Ii Bayesian Decision TheoryDocument22 pagesUnit-Ii Bayesian Decision TheoryJoyce GeorgeNo ratings yet
- Lecture Notes Week 1Document10 pagesLecture Notes Week 1tarik BenseddikNo ratings yet
- An Introduction To Variational Calculus in Machine LearningDocument7 pagesAn Introduction To Variational Calculus in Machine LearningAlexandersierraNo ratings yet
- Ec220 - ps1Document3 pagesEc220 - ps1senteliNo ratings yet
- Lecture 5Document16 pagesLecture 5Alireza MovahedianNo ratings yet
- Sec 1-1Document10 pagesSec 1-1Metin DenizNo ratings yet
- 3.1 Binary ClassificationDocument4 pages3.1 Binary ClassificationNCT DreamNo ratings yet
- 2 Entropy and Mutual Information: I (A) F (P (A) )Document27 pages2 Entropy and Mutual Information: I (A) F (P (A) )ManojkumarNo ratings yet
- ClassificationDocument19 pagesClassificationstatyoungNo ratings yet
- ch2 Online 3Document19 pagesch2 Online 3Marwan MonajjedNo ratings yet
- MTH 514 Notes CH 4,5,6,10Document69 pagesMTH 514 Notes CH 4,5,6,10t_man222No ratings yet
- Marginal and Conditional Gaussians: Ramses Acosta, Dairo QuinteroDocument4 pagesMarginal and Conditional Gaussians: Ramses Acosta, Dairo QuinteroDairo QuinteroNo ratings yet
- 复件 LinearAlgebra2Document28 pages复件 LinearAlgebra2Cleevh MabialaNo ratings yet
- Lecture01 Uppsala EQG 12Document39 pagesLecture01 Uppsala EQG 12Henz RabinoNo ratings yet
- decisiontheory_0Document13 pagesdecisiontheory_0Prof. Madya Dr. Umar Yusuf MadakiNo ratings yet
- DHSCH 2Document88 pagesDHSCH 2obsidian555No ratings yet
- 00MET03 Metric SpacesDocument5 pages00MET03 Metric SpacesAjoy SharmaNo ratings yet
- Information Theory Entropy Relative EntropyDocument60 pagesInformation Theory Entropy Relative EntropyJamesNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
- Lecture 1.3Document7 pagesLecture 1.3Jon SmithsonNo ratings yet
- Actsc 432 Review Part 1Document7 pagesActsc 432 Review Part 1osiccorNo ratings yet
- HMWK 4Document5 pagesHMWK 4Jasmine NguyenNo ratings yet
- Orthogonal P-Wavelets On R: + Yu.A. FarkovDocument23 pagesOrthogonal P-Wavelets On R: + Yu.A. FarkovukoszapavlinjeNo ratings yet
- Chapter2 PDFDocument22 pagesChapter2 PDFVikas Kumar PooniaNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Class 8 CH 5 Data Handling August 19Document3 pagesClass 8 CH 5 Data Handling August 19shayn budihardjoNo ratings yet
- Loctite Stycast 2762: Technical Data SheetDocument3 pagesLoctite Stycast 2762: Technical Data SheetankitaNo ratings yet
- OHEDocument8 pagesOHEMohammad Zakir50% (2)
- 100 X4FS140 HU B ProductData en DEDocument2 pages100 X4FS140 HU B ProductData en DEcontato.tiagogatodesouzaNo ratings yet
- PaintingDocument103 pagesPaintingJean100% (1)
- Brochuresmx 1000 SMX 1000 LC 251 e 023 ADocument18 pagesBrochuresmx 1000 SMX 1000 LC 251 e 023 ADoanh NguyenNo ratings yet
- Sec 3 Revision Test A1 A2Document4 pagesSec 3 Revision Test A1 A2Edu 4 UNo ratings yet
- Bab 2 Euclidean Vector Spaces (Compatibility Mode) PDFDocument13 pagesBab 2 Euclidean Vector Spaces (Compatibility Mode) PDFKanisha Lakshmi BakthavasalamNo ratings yet
- 2021 Pslce Ntcheu Pass-ListDocument199 pages2021 Pslce Ntcheu Pass-ListMolley KachingweNo ratings yet
- Laravel SyllabusDocument4 pagesLaravel SyllabusnandakamineniNo ratings yet
- Activity #6 SAMPLING DISTRIBUTIONSDocument8 pagesActivity #6 SAMPLING DISTRIBUTIONSleonessa jorban cortes0% (1)
- 6 - Key Management and Distribution-Final-okDocument38 pages6 - Key Management and Distribution-Final-okSaja KareemNo ratings yet
- PS3-2 - Sequences Series, Rates, and Equation TheoryDocument6 pagesPS3-2 - Sequences Series, Rates, and Equation TheoryJoseph AparisNo ratings yet
- Automatizari Complexe - Lucrarea 1: Three - Phase Asynchronous MachineDocument1 pageAutomatizari Complexe - Lucrarea 1: Three - Phase Asynchronous MachineAlexandru AichimoaieNo ratings yet
- The UniverseDocument5 pagesThe UniverseAn MaNo ratings yet
- Thales TheoremDocument3 pagesThales Theoremgitongajohn253No ratings yet
- Wmsu Shs Students Perception of Grade 11Document46 pagesWmsu Shs Students Perception of Grade 11jaywarven100% (1)
- Asm HandbookDocument2 pagesAsm HandbookLilian RoseNo ratings yet
- Chapter 5. Probability and Random Process - UpdatedDocument151 pagesChapter 5. Probability and Random Process - UpdatedHariharan S RNo ratings yet
- ICL7106 and ICL7107 VoltmeterDocument16 pagesICL7106 and ICL7107 VoltmeterAntonino ScordatoNo ratings yet
- 6.hydrogen Its CompoundDocument17 pages6.hydrogen Its CompoundpjaindakNo ratings yet
- Robot Safety Analysis MethodsDocument11 pagesRobot Safety Analysis MethodsCHUTIYANo ratings yet
- GalileoDocument9 pagesGalileoAkram KaladiaNo ratings yet
- Creating Hello World Web Widget With HTML CSS and JavascriptDocument10 pagesCreating Hello World Web Widget With HTML CSS and Javascriptrajeshlal100% (1)
- DNA DamageDocument49 pagesDNA DamagekurniaadhiNo ratings yet
- Sedemac gc1200 002 Manual For gc1200 ControllersDocument75 pagesSedemac gc1200 002 Manual For gc1200 ControllersKrishnakumar GanesanNo ratings yet
- 2014 Zhang Book Chapter Divergence GeometryDocument27 pages2014 Zhang Book Chapter Divergence GeometrysggtioNo ratings yet
- More Ebooks at Https://telegram - Me/unacademyplusdiscountsDocument473 pagesMore Ebooks at Https://telegram - Me/unacademyplusdiscountsKhushi YadavNo ratings yet