
Postgresql 12 US 3
Postgresql 12 US 3
You might also like
- Project Appraisal - Hotel Project in Sri LankaDocument15 pagesProject Appraisal - Hotel Project in Sri Lankachathura ravilal hapuarachchiNo ratings yet
- Troubleshooting Transactional Replication in SQL ServerDocument89 pagesTroubleshooting Transactional Replication in SQL ServerKaushik MajumderNo ratings yet
- PostgreSQL Quick StartDocument57 pagesPostgreSQL Quick StartChris AslaNo ratings yet
- O Try To Create A Database. A Running PostgreSQL Server Can Manage Many Databases. Typically, A Separate Database Is Used For Each Project or For Each User.Document18 pagesO Try To Create A Database. A Running PostgreSQL Server Can Manage Many Databases. Typically, A Separate Database Is Used For Each Project or For Each User.voterdeskjaioaNo ratings yet
- How To Set Up Oracle GoldenGate Microservices 12.3Document6 pagesHow To Set Up Oracle GoldenGate Microservices 12.3Ashok ThiyagarajanNo ratings yet
- PostgreSQL For Data Architects - Sample ChapterDocument23 pagesPostgreSQL For Data Architects - Sample ChapterPackt PublishingNo ratings yet
- Postgre SQLEMDocument3 pagesPostgre SQLEMLaljaseh KipgenNo ratings yet
- Database Servers TutorialDocument44 pagesDatabase Servers TutorialTri DewantoNo ratings yet
- How To Set Up PostgreSQL For High Availability and Replication With Hot StandbyDocument11 pagesHow To Set Up PostgreSQL For High Availability and Replication With Hot Standbygoosie66No ratings yet
- National University of Singapore: Due: 11:59pm February 22, 2010 (Monday)Document8 pagesNational University of Singapore: Due: 11:59pm February 22, 2010 (Monday)Santhom PalaniNo ratings yet
- Downloading and Installing Postgresql On Windows 10Document4 pagesDownloading and Installing Postgresql On Windows 10Shiksha SurekaNo ratings yet
- Mum PSP SQLDocument24 pagesMum PSP SQLafonsobdsNo ratings yet
- How To Set Up PostgreSQL For High Availability and Replication With Hot Standby - Solutions Google Cloud PlatformDocument6 pagesHow To Set Up PostgreSQL For High Availability and Replication With Hot Standby - Solutions Google Cloud PlatformMohammed Abdalla RajabNo ratings yet
- Postgresql Tutorial For Beginners: Learn Basic PSQL in 3 DaysDocument3 pagesPostgresql Tutorial For Beginners: Learn Basic PSQL in 3 DaysKarthikeyan PerumalNo ratings yet
- Postgresql Tuning Guide: Postgresql Architecture: Key TakeawaysDocument8 pagesPostgresql Tuning Guide: Postgresql Architecture: Key TakeawaysTonny KusdarwantoNo ratings yet
- RapidAnalytics ManualDocument23 pagesRapidAnalytics ManualansanaNo ratings yet
- Barman Tutorial - enDocument21 pagesBarman Tutorial - enBatas AtasNo ratings yet
- WP Idera Init Replication From BackupDocument8 pagesWP Idera Init Replication From Backupssk_altec_grNo ratings yet
- Debugging and Error HandelingDocument17 pagesDebugging and Error Handelingapi-3841500No ratings yet
- CSC 3326 01 LabDocument6 pagesCSC 3326 01 LabAbde AeNo ratings yet
- Causes of SQL Server Cluster Installation Failures: Updating The StatsDocument8 pagesCauses of SQL Server Cluster Installation Failures: Updating The StatsSyed NoumanNo ratings yet
- Postgis IntroductionDocument36 pagesPostgis IntroductionClaudio Bautista AguilarNo ratings yet
- Capstone FAQDocumentDocument13 pagesCapstone FAQDocumentjonNo ratings yet
- Installation Process of NewGenLib ApplicationDocument19 pagesInstallation Process of NewGenLib ApplicationKishor Sakariya100% (1)
- SQL Server Database Administrator's Roadmap - Database Tutorials - DBA GuiaDocument9 pagesSQL Server Database Administrator's Roadmap - Database Tutorials - DBA GuiaAlexsander Martins dos SantosNo ratings yet
- Rapid Analytics 1.0.000 ManualDocument22 pagesRapid Analytics 1.0.000 ManualRoshan DanielNo ratings yet
- Replication Important Interview Qus & AnsDocument14 pagesReplication Important Interview Qus & Ansgrsrik100% (1)
- Test Lab Guide: Ebook For Sharepoint Server 2013 Intranet and Team SitesDocument41 pagesTest Lab Guide: Ebook For Sharepoint Server 2013 Intranet and Team SitesRémi VernierNo ratings yet
- Troubleshooting PostgreSQL - Sample ChapterDocument15 pagesTroubleshooting PostgreSQL - Sample ChapterPackt Publishing100% (1)
- Rob Conery - Using Entity Framework 6 With PostgreSQLDocument11 pagesRob Conery - Using Entity Framework 6 With PostgreSQLAlexandre CustodioNo ratings yet
- EStore DocumentationDocument23 pagesEStore Documentationrony royNo ratings yet
- PostgreSQL DBA GuideDocument105 pagesPostgreSQL DBA GuidePrasanth ChandranNo ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationGabriel RomanNo ratings yet
- Setting Up and Connecting To A Remote MongoDB Database - by Mithilesh Said - Founding Ithaka - MediumDocument6 pagesSetting Up and Connecting To A Remote MongoDB Database - by Mithilesh Said - Founding Ithaka - MediumYusto Malik OmondiNo ratings yet
- PL SQL Chapter 2Document32 pagesPL SQL Chapter 2designwebargentinaNo ratings yet
- How To Install RoundcubeDocument3 pagesHow To Install RoundcubeHM BossNo ratings yet
- Metasploit Guide InstallDocument6 pagesMetasploit Guide InstallImnot AndyNo ratings yet
- Using Ms Access With PostgresqlDocument15 pagesUsing Ms Access With Postgresqlacalderab537750% (2)
- UserDocument6 pagesUserBenjamin CulkinNo ratings yet
- What Is Transaction Replication in SQL Server?: Advantages or Use Cases For Transactional ReplicationDocument15 pagesWhat Is Transaction Replication in SQL Server?: Advantages or Use Cases For Transactional ReplicationkowsalyaNo ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationFrancesco MartinoNo ratings yet
- Instalan Guide DrupalDocument69 pagesInstalan Guide DrupalIlham AdNo ratings yet
- How To Create A Shared Database: An Example Using Postgresql and Pgadmin4Document19 pagesHow To Create A Shared Database: An Example Using Postgresql and Pgadmin4Freddy IANo ratings yet
- Postgresql Database ConfigurationDocument3 pagesPostgresql Database Configurationpiotroxp100% (1)
- Postgresql On Solaris 10: Solaris™ 10 How To GuidesDocument18 pagesPostgresql On Solaris 10: Solaris™ 10 How To Guideskencan14No ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationsuyonoNo ratings yet
- Weblogic Interview Q&ADocument6 pagesWeblogic Interview Q&Araguram_govindarajNo ratings yet
- Hands-On Lab: Views in PostgresqlDocument28 pagesHands-On Lab: Views in Postgresql4672 Nathan PereiraNo ratings yet
- Java Database Interview QuestionsDocument19 pagesJava Database Interview QuestionsVenkata Subbarao CherukuriNo ratings yet
- PostgreSQL HowtoDocument108 pagesPostgreSQL Howtohans_lbsNo ratings yet
- Geoportal Server Setup On LinuxDocument27 pagesGeoportal Server Setup On LinuxRiza AnsoriNo ratings yet
- 1 Overview: Installation Guide For Contineo 3.0Document9 pages1 Overview: Installation Guide For Contineo 3.0Pier Synder MonteroNo ratings yet
- Installation: Installing The ServerDocument28 pagesInstallation: Installing The ServermailramkNo ratings yet
- DagDocument27 pagesDagRajeev SrivastavaNo ratings yet
- PostgreSQL Administration Essentials Sample ChapterDocument25 pagesPostgreSQL Administration Essentials Sample ChapterPackt PublishingNo ratings yet
- HerokuPostgres Workbooks Web FinalDocument16 pagesHerokuPostgres Workbooks Web FinaltansisonaNo ratings yet
- How To Configure Outlook To A Specific Global Catalog Server or To The Closest Global Catalog ServerDocument4 pagesHow To Configure Outlook To A Specific Global Catalog Server or To The Closest Global Catalog ServerLekhamani YadavNo ratings yet
- PostgreSQL for Jobseekers: Introduction to PostgreSQL administration for modern DBAs (English Edition)From EverandPostgreSQL for Jobseekers: Introduction to PostgreSQL administration for modern DBAs (English Edition)No ratings yet
- Sql : The Ultimate Beginner to Advanced Guide To Master SQL Quickly with Step-by-Step Practical ExamplesFrom EverandSql : The Ultimate Beginner to Advanced Guide To Master SQL Quickly with Step-by-Step Practical ExamplesNo ratings yet
- A Step By Step Tutorial Using JSP For Web Development With Derby DatabaseFrom EverandA Step By Step Tutorial Using JSP For Web Development With Derby DatabaseNo ratings yet
- Temario Glue ETLDocument2 pagesTemario Glue ETLgcarreongNo ratings yet
- Postgresql 12 US NDocument6 pagesPostgresql 12 US NgcarreongNo ratings yet
- Temario Glue ETL IntermedioDocument2 pagesTemario Glue ETL IntermediogcarreongNo ratings yet
- Temario Open LDAPDocument3 pagesTemario Open LDAPgcarreongNo ratings yet
- Instalar Swing BenchDocument26 pagesInstalar Swing BenchgcarreongNo ratings yet
- Temario MambuDocument3 pagesTemario MambugcarreongNo ratings yet
- UC Berkeley DigitalTransformation-Brochure-28!10!21 V32Document20 pagesUC Berkeley DigitalTransformation-Brochure-28!10!21 V32gcarreongNo ratings yet
- Resumen Ggplot2Document2 pagesResumen Ggplot2gcarreongNo ratings yet
- StatspackDocument6 pagesStatspackgcarreongNo ratings yet
- Referencia Ggplot2Document284 pagesReferencia Ggplot2gcarreongNo ratings yet
- ProCapture-WP Quick Start GuideDocument15 pagesProCapture-WP Quick Start GuidegcarreongNo ratings yet
- ProCapture-WP Quick Start GuideDocument15 pagesProCapture-WP Quick Start GuidegcarreongNo ratings yet
- SolarWindsPortScanner 2020.11.05 01-02-55Document44 pagesSolarWindsPortScanner 2020.11.05 01-02-55gcarreongNo ratings yet
- SQL Server 2019 Editions DatasheetDocument3 pagesSQL Server 2019 Editions DatasheetgcarreongNo ratings yet
- Lab Manual PDFDocument120 pagesLab Manual PDFgcarreongNo ratings yet
- Database Security For OracleDocument13 pagesDatabase Security For OraclegcarreongNo ratings yet
- Temario Spring MicroserviciosDocument5 pagesTemario Spring MicroserviciosgcarreongNo ratings yet
- Linux Administration I. Process ManagementDocument2 pagesLinux Administration I. Process ManagementgcarreongNo ratings yet
- 365admin Room Manager Implementation GuideDocument72 pages365admin Room Manager Implementation GuidegcarreongNo ratings yet
- Temario Troubleshooting LinuxDocument6 pagesTemario Troubleshooting LinuxgcarreongNo ratings yet
- Pepsi CoDocument2 pagesPepsi CoKeine LeeNo ratings yet
- DACUM-Talent Management ConsultantDocument6 pagesDACUM-Talent Management ConsultantDinoSetiawanAbdullahNo ratings yet
- Simple MetallurgyDocument10 pagesSimple MetallurgyMahendra Singh0% (1)
- The Excretory System (The Urinary System) : Responsible For The Processing and Elimination of Metabolic Waste Consists ofDocument8 pagesThe Excretory System (The Urinary System) : Responsible For The Processing and Elimination of Metabolic Waste Consists ofDeeptanshu PrakashNo ratings yet
- b155166 California Caselaw Child SupportDocument5 pagesb155166 California Caselaw Child SupportJOEMAFLAGENo ratings yet
- Microsoft: Programming in Html5 With Javascript and Css3Document11 pagesMicrosoft: Programming in Html5 With Javascript and Css3Mazen SEGNINo ratings yet
- Stair DesignDocument7 pagesStair DesignRifat Bin KamalNo ratings yet
- Establishing A Continuous Professional Learning Culture-Shanaye Packineau-WilliamsDocument6 pagesEstablishing A Continuous Professional Learning Culture-Shanaye Packineau-Williamsapi-529462240No ratings yet
- Research Paper On Logic GatesDocument5 pagesResearch Paper On Logic Gatesafedoeike100% (1)
- Consumer ActDocument35 pagesConsumer ActAnnabelle RafolsNo ratings yet
- Modeling and Simulation of Scheduling Algorithms in LTE NetworksDocument62 pagesModeling and Simulation of Scheduling Algorithms in LTE Networksمهند عدنان الجعفريNo ratings yet
- Factors Influencing Artificial Intelligence Adoption in The Accounting Profession - The Case of Public Sector in KuwaitDocument25 pagesFactors Influencing Artificial Intelligence Adoption in The Accounting Profession - The Case of Public Sector in Kuwaittoky daikiNo ratings yet
- 6 - Enthalpy ChangeDocument28 pages6 - Enthalpy Changenamopoopp123456789No ratings yet
- Charles Wellons v. Miami Dade County, 11th Cir. (2015)Document15 pagesCharles Wellons v. Miami Dade County, 11th Cir. (2015)Scribd Government DocsNo ratings yet
- 032 Itp For Painting and Coatingpdf PDF FreeDocument19 pages032 Itp For Painting and Coatingpdf PDF FreeAli KayaNo ratings yet
- Q4 & FY22 Results PresentationDocument52 pagesQ4 & FY22 Results PresentationThems OclauanjNo ratings yet
- Ccna NotesDocument67 pagesCcna NotesIrshad KhanNo ratings yet
- Leap PDFDocument5 pagesLeap PDFMiguel Angel MartinNo ratings yet
- E ToiletDocument39 pagesE ToiletEram Scientific100% (1)
- Inner Product SpaceDocument3 pagesInner Product SpaceDharmendra KumarNo ratings yet
- Industrial Crops & Products: Didem Sutay Kocabas, Merve Erkoç Akçelik, Erinç Bahçegül, Hatice Neval OzbekDocument13 pagesIndustrial Crops & Products: Didem Sutay Kocabas, Merve Erkoç Akçelik, Erinç Bahçegül, Hatice Neval Ozbekjans carlosNo ratings yet
- Iot Based Smart Agriculture: A Study: Review PapersDocument9 pagesIot Based Smart Agriculture: A Study: Review Papersgurram krishna vamsiNo ratings yet
- SAALM03Document33 pagesSAALM03jorge arturo meza lopezNo ratings yet
- EE3302 Laboratory: Ziegler-Nichols & Relay Tuning ExperimentsDocument10 pagesEE3302 Laboratory: Ziegler-Nichols & Relay Tuning ExperimentsKai Hee GohNo ratings yet
- Hippopotamus DefenceDocument4 pagesHippopotamus DefenceCarlo Edoardo CapponiNo ratings yet
- Robes-Francisco v. CFIDocument2 pagesRobes-Francisco v. CFIElaiza OngNo ratings yet
- Manual HF GeneratorsDocument50 pagesManual HF GeneratorsHưng Phạm VănNo ratings yet
- Taylor Vs Wright (The Taliño)Document3 pagesTaylor Vs Wright (The Taliño)AlexandraSoledadNo ratings yet
- 1.12 Anitei Craif Model de Diagnoză A Culturii OrganizaţionaleDocument17 pages1.12 Anitei Craif Model de Diagnoză A Culturii OrganizaţionaleOana Mateescu100% (1)























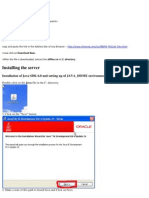





















































































Download as pdf or txt
You might also like
- Project Appraisal - Hotel Project in Sri LankaDocument15 pagesProject Appraisal - Hotel Project in Sri Lankachathura ravilal hapuarachchiNo ratings yet
- Troubleshooting Transactional Replication in SQL ServerDocument89 pagesTroubleshooting Transactional Replication in SQL ServerKaushik MajumderNo ratings yet
- PostgreSQL Quick StartDocument57 pagesPostgreSQL Quick StartChris AslaNo ratings yet
- O Try To Create A Database. A Running PostgreSQL Server Can Manage Many Databases. Typically, A Separate Database Is Used For Each Project or For Each User.Document18 pagesO Try To Create A Database. A Running PostgreSQL Server Can Manage Many Databases. Typically, A Separate Database Is Used For Each Project or For Each User.voterdeskjaioaNo ratings yet
- How To Set Up Oracle GoldenGate Microservices 12.3Document6 pagesHow To Set Up Oracle GoldenGate Microservices 12.3Ashok ThiyagarajanNo ratings yet
- PostgreSQL For Data Architects - Sample ChapterDocument23 pagesPostgreSQL For Data Architects - Sample ChapterPackt PublishingNo ratings yet
- Postgre SQLEMDocument3 pagesPostgre SQLEMLaljaseh KipgenNo ratings yet
- Database Servers TutorialDocument44 pagesDatabase Servers TutorialTri DewantoNo ratings yet
- How To Set Up PostgreSQL For High Availability and Replication With Hot StandbyDocument11 pagesHow To Set Up PostgreSQL For High Availability and Replication With Hot Standbygoosie66No ratings yet
- National University of Singapore: Due: 11:59pm February 22, 2010 (Monday)Document8 pagesNational University of Singapore: Due: 11:59pm February 22, 2010 (Monday)Santhom PalaniNo ratings yet
- Downloading and Installing Postgresql On Windows 10Document4 pagesDownloading and Installing Postgresql On Windows 10Shiksha SurekaNo ratings yet
- Mum PSP SQLDocument24 pagesMum PSP SQLafonsobdsNo ratings yet
- How To Set Up PostgreSQL For High Availability and Replication With Hot Standby - Solutions Google Cloud PlatformDocument6 pagesHow To Set Up PostgreSQL For High Availability and Replication With Hot Standby - Solutions Google Cloud PlatformMohammed Abdalla RajabNo ratings yet
- Postgresql Tutorial For Beginners: Learn Basic PSQL in 3 DaysDocument3 pagesPostgresql Tutorial For Beginners: Learn Basic PSQL in 3 DaysKarthikeyan PerumalNo ratings yet
- Postgresql Tuning Guide: Postgresql Architecture: Key TakeawaysDocument8 pagesPostgresql Tuning Guide: Postgresql Architecture: Key TakeawaysTonny KusdarwantoNo ratings yet
- RapidAnalytics ManualDocument23 pagesRapidAnalytics ManualansanaNo ratings yet
- Barman Tutorial - enDocument21 pagesBarman Tutorial - enBatas AtasNo ratings yet
- WP Idera Init Replication From BackupDocument8 pagesWP Idera Init Replication From Backupssk_altec_grNo ratings yet
- Debugging and Error HandelingDocument17 pagesDebugging and Error Handelingapi-3841500No ratings yet
- CSC 3326 01 LabDocument6 pagesCSC 3326 01 LabAbde AeNo ratings yet
- Causes of SQL Server Cluster Installation Failures: Updating The StatsDocument8 pagesCauses of SQL Server Cluster Installation Failures: Updating The StatsSyed NoumanNo ratings yet
- Postgis IntroductionDocument36 pagesPostgis IntroductionClaudio Bautista AguilarNo ratings yet
- Capstone FAQDocumentDocument13 pagesCapstone FAQDocumentjonNo ratings yet
- Installation Process of NewGenLib ApplicationDocument19 pagesInstallation Process of NewGenLib ApplicationKishor Sakariya100% (1)
- SQL Server Database Administrator's Roadmap - Database Tutorials - DBA GuiaDocument9 pagesSQL Server Database Administrator's Roadmap - Database Tutorials - DBA GuiaAlexsander Martins dos SantosNo ratings yet
- Rapid Analytics 1.0.000 ManualDocument22 pagesRapid Analytics 1.0.000 ManualRoshan DanielNo ratings yet
- Replication Important Interview Qus & AnsDocument14 pagesReplication Important Interview Qus & Ansgrsrik100% (1)
- Test Lab Guide: Ebook For Sharepoint Server 2013 Intranet and Team SitesDocument41 pagesTest Lab Guide: Ebook For Sharepoint Server 2013 Intranet and Team SitesRémi VernierNo ratings yet
- Troubleshooting PostgreSQL - Sample ChapterDocument15 pagesTroubleshooting PostgreSQL - Sample ChapterPackt Publishing100% (1)
- Rob Conery - Using Entity Framework 6 With PostgreSQLDocument11 pagesRob Conery - Using Entity Framework 6 With PostgreSQLAlexandre CustodioNo ratings yet
- EStore DocumentationDocument23 pagesEStore Documentationrony royNo ratings yet
- PostgreSQL DBA GuideDocument105 pagesPostgreSQL DBA GuidePrasanth ChandranNo ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationGabriel RomanNo ratings yet
- Setting Up and Connecting To A Remote MongoDB Database - by Mithilesh Said - Founding Ithaka - MediumDocument6 pagesSetting Up and Connecting To A Remote MongoDB Database - by Mithilesh Said - Founding Ithaka - MediumYusto Malik OmondiNo ratings yet
- PL SQL Chapter 2Document32 pagesPL SQL Chapter 2designwebargentinaNo ratings yet
- How To Install RoundcubeDocument3 pagesHow To Install RoundcubeHM BossNo ratings yet
- Metasploit Guide InstallDocument6 pagesMetasploit Guide InstallImnot AndyNo ratings yet
- Using Ms Access With PostgresqlDocument15 pagesUsing Ms Access With Postgresqlacalderab537750% (2)
- UserDocument6 pagesUserBenjamin CulkinNo ratings yet
- What Is Transaction Replication in SQL Server?: Advantages or Use Cases For Transactional ReplicationDocument15 pagesWhat Is Transaction Replication in SQL Server?: Advantages or Use Cases For Transactional ReplicationkowsalyaNo ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationFrancesco MartinoNo ratings yet
- Instalan Guide DrupalDocument69 pagesInstalan Guide DrupalIlham AdNo ratings yet
- How To Create A Shared Database: An Example Using Postgresql and Pgadmin4Document19 pagesHow To Create A Shared Database: An Example Using Postgresql and Pgadmin4Freddy IANo ratings yet
- Postgresql Database ConfigurationDocument3 pagesPostgresql Database Configurationpiotroxp100% (1)
- Postgresql On Solaris 10: Solaris™ 10 How To GuidesDocument18 pagesPostgresql On Solaris 10: Solaris™ 10 How To Guideskencan14No ratings yet
- Building Your First Laravel ApplicationDocument38 pagesBuilding Your First Laravel ApplicationsuyonoNo ratings yet
- Weblogic Interview Q&ADocument6 pagesWeblogic Interview Q&Araguram_govindarajNo ratings yet
- Hands-On Lab: Views in PostgresqlDocument28 pagesHands-On Lab: Views in Postgresql4672 Nathan PereiraNo ratings yet
- Java Database Interview QuestionsDocument19 pagesJava Database Interview QuestionsVenkata Subbarao CherukuriNo ratings yet
- PostgreSQL HowtoDocument108 pagesPostgreSQL Howtohans_lbsNo ratings yet
- Geoportal Server Setup On LinuxDocument27 pagesGeoportal Server Setup On LinuxRiza AnsoriNo ratings yet
- 1 Overview: Installation Guide For Contineo 3.0Document9 pages1 Overview: Installation Guide For Contineo 3.0Pier Synder MonteroNo ratings yet
- Installation: Installing The ServerDocument28 pagesInstallation: Installing The ServermailramkNo ratings yet
- DagDocument27 pagesDagRajeev SrivastavaNo ratings yet
- PostgreSQL Administration Essentials Sample ChapterDocument25 pagesPostgreSQL Administration Essentials Sample ChapterPackt PublishingNo ratings yet
- HerokuPostgres Workbooks Web FinalDocument16 pagesHerokuPostgres Workbooks Web FinaltansisonaNo ratings yet
- How To Configure Outlook To A Specific Global Catalog Server or To The Closest Global Catalog ServerDocument4 pagesHow To Configure Outlook To A Specific Global Catalog Server or To The Closest Global Catalog ServerLekhamani YadavNo ratings yet
- PostgreSQL for Jobseekers: Introduction to PostgreSQL administration for modern DBAs (English Edition)From EverandPostgreSQL for Jobseekers: Introduction to PostgreSQL administration for modern DBAs (English Edition)No ratings yet
- Sql : The Ultimate Beginner to Advanced Guide To Master SQL Quickly with Step-by-Step Practical ExamplesFrom EverandSql : The Ultimate Beginner to Advanced Guide To Master SQL Quickly with Step-by-Step Practical ExamplesNo ratings yet
- A Step By Step Tutorial Using JSP For Web Development With Derby DatabaseFrom EverandA Step By Step Tutorial Using JSP For Web Development With Derby DatabaseNo ratings yet
- Temario Glue ETLDocument2 pagesTemario Glue ETLgcarreongNo ratings yet
- Postgresql 12 US NDocument6 pagesPostgresql 12 US NgcarreongNo ratings yet
- Temario Glue ETL IntermedioDocument2 pagesTemario Glue ETL IntermediogcarreongNo ratings yet
- Temario Open LDAPDocument3 pagesTemario Open LDAPgcarreongNo ratings yet
- Instalar Swing BenchDocument26 pagesInstalar Swing BenchgcarreongNo ratings yet
- Temario MambuDocument3 pagesTemario MambugcarreongNo ratings yet
- UC Berkeley DigitalTransformation-Brochure-28!10!21 V32Document20 pagesUC Berkeley DigitalTransformation-Brochure-28!10!21 V32gcarreongNo ratings yet
- Resumen Ggplot2Document2 pagesResumen Ggplot2gcarreongNo ratings yet
- StatspackDocument6 pagesStatspackgcarreongNo ratings yet
- Referencia Ggplot2Document284 pagesReferencia Ggplot2gcarreongNo ratings yet
- ProCapture-WP Quick Start GuideDocument15 pagesProCapture-WP Quick Start GuidegcarreongNo ratings yet
- ProCapture-WP Quick Start GuideDocument15 pagesProCapture-WP Quick Start GuidegcarreongNo ratings yet
- SolarWindsPortScanner 2020.11.05 01-02-55Document44 pagesSolarWindsPortScanner 2020.11.05 01-02-55gcarreongNo ratings yet
- SQL Server 2019 Editions DatasheetDocument3 pagesSQL Server 2019 Editions DatasheetgcarreongNo ratings yet
- Lab Manual PDFDocument120 pagesLab Manual PDFgcarreongNo ratings yet
- Database Security For OracleDocument13 pagesDatabase Security For OraclegcarreongNo ratings yet
- Temario Spring MicroserviciosDocument5 pagesTemario Spring MicroserviciosgcarreongNo ratings yet
- Linux Administration I. Process ManagementDocument2 pagesLinux Administration I. Process ManagementgcarreongNo ratings yet
- 365admin Room Manager Implementation GuideDocument72 pages365admin Room Manager Implementation GuidegcarreongNo ratings yet
- Temario Troubleshooting LinuxDocument6 pagesTemario Troubleshooting LinuxgcarreongNo ratings yet
- Pepsi CoDocument2 pagesPepsi CoKeine LeeNo ratings yet
- DACUM-Talent Management ConsultantDocument6 pagesDACUM-Talent Management ConsultantDinoSetiawanAbdullahNo ratings yet
- Simple MetallurgyDocument10 pagesSimple MetallurgyMahendra Singh0% (1)
- The Excretory System (The Urinary System) : Responsible For The Processing and Elimination of Metabolic Waste Consists ofDocument8 pagesThe Excretory System (The Urinary System) : Responsible For The Processing and Elimination of Metabolic Waste Consists ofDeeptanshu PrakashNo ratings yet
- b155166 California Caselaw Child SupportDocument5 pagesb155166 California Caselaw Child SupportJOEMAFLAGENo ratings yet
- Microsoft: Programming in Html5 With Javascript and Css3Document11 pagesMicrosoft: Programming in Html5 With Javascript and Css3Mazen SEGNINo ratings yet
- Stair DesignDocument7 pagesStair DesignRifat Bin KamalNo ratings yet
- Establishing A Continuous Professional Learning Culture-Shanaye Packineau-WilliamsDocument6 pagesEstablishing A Continuous Professional Learning Culture-Shanaye Packineau-Williamsapi-529462240No ratings yet
- Research Paper On Logic GatesDocument5 pagesResearch Paper On Logic Gatesafedoeike100% (1)
- Consumer ActDocument35 pagesConsumer ActAnnabelle RafolsNo ratings yet
- Modeling and Simulation of Scheduling Algorithms in LTE NetworksDocument62 pagesModeling and Simulation of Scheduling Algorithms in LTE Networksمهند عدنان الجعفريNo ratings yet
- Factors Influencing Artificial Intelligence Adoption in The Accounting Profession - The Case of Public Sector in KuwaitDocument25 pagesFactors Influencing Artificial Intelligence Adoption in The Accounting Profession - The Case of Public Sector in Kuwaittoky daikiNo ratings yet
- 6 - Enthalpy ChangeDocument28 pages6 - Enthalpy Changenamopoopp123456789No ratings yet
- Charles Wellons v. Miami Dade County, 11th Cir. (2015)Document15 pagesCharles Wellons v. Miami Dade County, 11th Cir. (2015)Scribd Government DocsNo ratings yet
- 032 Itp For Painting and Coatingpdf PDF FreeDocument19 pages032 Itp For Painting and Coatingpdf PDF FreeAli KayaNo ratings yet
- Q4 & FY22 Results PresentationDocument52 pagesQ4 & FY22 Results PresentationThems OclauanjNo ratings yet
- Ccna NotesDocument67 pagesCcna NotesIrshad KhanNo ratings yet
- Leap PDFDocument5 pagesLeap PDFMiguel Angel MartinNo ratings yet
- E ToiletDocument39 pagesE ToiletEram Scientific100% (1)
- Inner Product SpaceDocument3 pagesInner Product SpaceDharmendra KumarNo ratings yet
- Industrial Crops & Products: Didem Sutay Kocabas, Merve Erkoç Akçelik, Erinç Bahçegül, Hatice Neval OzbekDocument13 pagesIndustrial Crops & Products: Didem Sutay Kocabas, Merve Erkoç Akçelik, Erinç Bahçegül, Hatice Neval Ozbekjans carlosNo ratings yet
- Iot Based Smart Agriculture: A Study: Review PapersDocument9 pagesIot Based Smart Agriculture: A Study: Review Papersgurram krishna vamsiNo ratings yet
- SAALM03Document33 pagesSAALM03jorge arturo meza lopezNo ratings yet
- EE3302 Laboratory: Ziegler-Nichols & Relay Tuning ExperimentsDocument10 pagesEE3302 Laboratory: Ziegler-Nichols & Relay Tuning ExperimentsKai Hee GohNo ratings yet
- Hippopotamus DefenceDocument4 pagesHippopotamus DefenceCarlo Edoardo CapponiNo ratings yet
- Robes-Francisco v. CFIDocument2 pagesRobes-Francisco v. CFIElaiza OngNo ratings yet
- Manual HF GeneratorsDocument50 pagesManual HF GeneratorsHưng Phạm VănNo ratings yet
- Taylor Vs Wright (The Taliño)Document3 pagesTaylor Vs Wright (The Taliño)AlexandraSoledadNo ratings yet
- 1.12 Anitei Craif Model de Diagnoză A Culturii OrganizaţionaleDocument17 pages1.12 Anitei Craif Model de Diagnoză A Culturii OrganizaţionaleOana Mateescu100% (1)