Download as pdf or txt
You might also like
- Google Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformFrom EverandGoogle Cloud Platform for Data Engineering: From Beginner to Data Engineer using Google Cloud PlatformRating: 5 out of 5 stars5/5 (1)
- Weldolet Branch Connection Calculation PDFDocument3 pagesWeldolet Branch Connection Calculation PDFgaso99No ratings yet
- Solution Manual Mechanical Engineering Principles John Bird 1Document24 pagesSolution Manual Mechanical Engineering Principles John Bird 1ridwansadely100% (1)
- Terex Peiner SK415 PDFDocument6 pagesTerex Peiner SK415 PDFJhony Espinoza PerezNo ratings yet
- DSU 22317 PracticalDocument31 pagesDSU 22317 PracticalCo2I 36Rohini ShewalkarNo ratings yet
- Railway Management SystemDocument30 pagesRailway Management Systemrkjrocks0% (2)
- Traffic Flow Prediction Using The METR-LA TrafficDocument8 pagesTraffic Flow Prediction Using The METR-LA TrafficMallikarjun patilNo ratings yet
- MyPresentation 1Document11 pagesMyPresentation 1Gomathi Aashika GeorgeNo ratings yet
- Keylogger in SecurityDocument12 pagesKeylogger in Securityravikumarpcse21No ratings yet
- RRS Software Design ReportDocument25 pagesRRS Software Design ReportAakansh ShrivastavaNo ratings yet
- AptivDocument7 pagesAptivAnas TimouchNo ratings yet
- Project TemplateDocument13 pagesProject TemplatekaniuppuNo ratings yet
- Drilling Data Management - SPE PetrowikiDocument6 pagesDrilling Data Management - SPE PetrowikiWanambwa SilagiNo ratings yet
- Cognos Query Tips and GuidelinesDocument11 pagesCognos Query Tips and GuidelinesPreethy SenthilNo ratings yet
- Loan MGMT Sys NEWDocument23 pagesLoan MGMT Sys NEWrohit singhNo ratings yet
- Project TemplateDocument11 pagesProject TemplateYuvarajan YuvarajanNo ratings yet
- IoT Applications in The Maintenance IndustryDocument15 pagesIoT Applications in The Maintenance IndustrypriyalNo ratings yet
- JAVA Mini ProjectDocument26 pagesJAVA Mini ProjectCNo ratings yet
- Milestone 3: Design, Test Plan & Prototype For Workload Management SystemDocument22 pagesMilestone 3: Design, Test Plan & Prototype For Workload Management SystemfghfghjfghjvbnyjytjNo ratings yet
- Using Rapid Prototyping To Develop A Data MartDocument7 pagesUsing Rapid Prototyping To Develop A Data MartfernandojhNo ratings yet
- Engineering Design Methods and Tools: Sahar IdreesDocument14 pagesEngineering Design Methods and Tools: Sahar IdreesMian Abdullah YaseenNo ratings yet
- CabDocument65 pagesCabRamanna Aakasa67% (3)
- PM Endterm Exam ReportDocument20 pagesPM Endterm Exam Reportmohamed aliNo ratings yet
- Unit 4Document6 pagesUnit 4vivekNo ratings yet
- DWDMDocument5 pagesDWDMAnkit KumarNo ratings yet
- Project Proposal DraftDocument4 pagesProject Proposal DraftLindiwe SibandaNo ratings yet
- Bharati VidyapeethDocument21 pagesBharati VidyapeethTashu RanaNo ratings yet
- Project TemplateDocument11 pagesProject Templatemanipappa10No ratings yet
- Phace 1 Report T20Document10 pagesPhace 1 Report T20loyking05No ratings yet
- Template-Based Integrated Design: A Case Study: Ali K. Kamrani and Abhay VijayanDocument10 pagesTemplate-Based Integrated Design: A Case Study: Ali K. Kamrani and Abhay VijayanmurgadeepNo ratings yet
- Experiment No. 9 Title: Monitor Performance of Existing: Algorithmsusing Cloud AnalystDocument7 pagesExperiment No. 9 Title: Monitor Performance of Existing: Algorithmsusing Cloud AnalystAyush ShahNo ratings yet
- Term Paper of Database Management System Topic:-Bus Reservation SystemDocument26 pagesTerm Paper of Database Management System Topic:-Bus Reservation Systemkaruna1240No ratings yet
- STG sg2Document162 pagesSTG sg2Radwa EL-MahdyNo ratings yet
- 1.1 Statement of The Project: Information Science & Engineering, SjcitDocument26 pages1.1 Statement of The Project: Information Science & Engineering, SjcitashNo ratings yet
- Phase 1Document10 pagesPhase 1Dr. crazyNo ratings yet
- A Project On Online House Rental ManagementDocument11 pagesA Project On Online House Rental Managementbahauddin masumNo ratings yet
- AI Phase2Document5 pagesAI Phase2jeinjein864No ratings yet
- JamesNgondo AssignmentCosting PDFDocument11 pagesJamesNgondo AssignmentCosting PDFJayO'ConnellNo ratings yet
- CT STG sg2 PDFDocument150 pagesCT STG sg2 PDFsebadolzNo ratings yet
- SynopsisDocument9 pagesSynopsisKiran SidhuNo ratings yet
- Project ProposalDocument9 pagesProject ProposalNoman M HasanNo ratings yet
- Project TemplateDocument11 pagesProject TemplateSrikrishnarajan NatarajanNo ratings yet
- Ut4p2 1Document10 pagesUt4p2 1sakthiasphaltalphaNo ratings yet
- Interest Calculation System For A Retail Bank: Project Report OnDocument44 pagesInterest Calculation System For A Retail Bank: Project Report OnRajesh GroverNo ratings yet
- Laptop Price PredictionDocument25 pagesLaptop Price Predictionvtu19362No ratings yet
- Project Report SPDocument9 pagesProject Report SPArjun RajputNo ratings yet
- Timetablegeneratror ContentsDocument46 pagesTimetablegeneratror ContentsAnchu LalNo ratings yet
- Ds & ML Project (IBM)Document9 pagesDs & ML Project (IBM)Anirudh NairNo ratings yet
- Synopsis SukeshDocument9 pagesSynopsis Sukeshsukeshbhalke10No ratings yet
- Article MechanismMachineTheory Budinger PDFDocument17 pagesArticle MechanismMachineTheory Budinger PDFfei312chenNo ratings yet
- Using Predictive Analytics To Optimize Asset Maintenance in The Utilities IndustryDocument6 pagesUsing Predictive Analytics To Optimize Asset Maintenance in The Utilities IndustryCognizant100% (1)
- EE Computer Applications: Week 5Document14 pagesEE Computer Applications: Week 5Rainier RamosNo ratings yet
- On Case Studies For Concurrent Engineering Concept in Shipbuilding IndustryDocument16 pagesOn Case Studies For Concurrent Engineering Concept in Shipbuilding IndustryAman BaghelNo ratings yet
- ISCA Nov 14 SolvedDocument15 pagesISCA Nov 14 SolvedShravanKumarNemaniNo ratings yet
- Planning Guidelines For Water and Sewerage - Network ModellingDocument23 pagesPlanning Guidelines For Water and Sewerage - Network ModellinghajihuzefaNo ratings yet
- Unit - 3 Data Warehouse Modelling and Online Analytical Processing IIDocument50 pagesUnit - 3 Data Warehouse Modelling and Online Analytical Processing IIRuchiraNo ratings yet
- SCM APO DP OverviewDocument104 pagesSCM APO DP Overviewberater8No ratings yet
- Hackathon Statements V1Document10 pagesHackathon Statements V1AayushNo ratings yet
- Framework Modeling GuidelinesDocument20 pagesFramework Modeling GuidelinesManjeet SinghNo ratings yet
- Building AIDocument8 pagesBuilding AIchris.tionoNo ratings yet
- Online Railway Reservation System - Documentation PDFDocument25 pagesOnline Railway Reservation System - Documentation PDFAkshat Kale83% (30)
- Research Reprot 1Document7 pagesResearch Reprot 1Siyeon YeungNo ratings yet
- SOLMAN:Monitoring Best PracticeDocument16 pagesSOLMAN:Monitoring Best PracticeSaurabh PandeyNo ratings yet
- Adding Sense To The Internet of Things - An Architecture Framework For Smart Object SystemsDocument19 pagesAdding Sense To The Internet of Things - An Architecture Framework For Smart Object SystemskwxoNo ratings yet
- AI Based ProctoringDocument4 pagesAI Based ProctoringmedhaNo ratings yet
- Black Max - Mud Motor - Operations ManualDocument129 pagesBlack Max - Mud Motor - Operations ManualJatin V PaliwalNo ratings yet
- Matrices & Determinants - Practice Sheet - Varun JEE Advanced 2024Document5 pagesMatrices & Determinants - Practice Sheet - Varun JEE Advanced 2024shikharvashishtha1729No ratings yet
- Be Itc MCQ 675263Document18 pagesBe Itc MCQ 675263سيناء الحبيبةNo ratings yet
- Triangle Inequality Theorem WorksheetDocument1 pageTriangle Inequality Theorem WorksheetAleczander EstrebilloNo ratings yet
- NOTES (2023-2024) Subject: Physics Lab Manual Class: Xii Sec: A Experiment No:3 - Concave MirrorDocument5 pagesNOTES (2023-2024) Subject: Physics Lab Manual Class: Xii Sec: A Experiment No:3 - Concave MirrorKing of KingsNo ratings yet
- Compressor: HATLAPA Water-Cooled Piston Compressor W30, W40Document2 pagesCompressor: HATLAPA Water-Cooled Piston Compressor W30, W40Vanas ShahNo ratings yet
- Quakecore Opensees Training Workshop 2017: Geotechnical Analysis in OpenseesDocument70 pagesQuakecore Opensees Training Workshop 2017: Geotechnical Analysis in OpenseesTariq MahmoodNo ratings yet
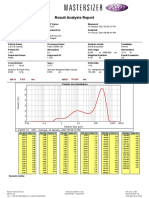
- Result Analysis Report: Um D (0.9) : 111.497 358.223 D (0.1) : Um Um 3.975 D (0.5)Document1 pageResult Analysis Report: Um D (0.9) : 111.497 358.223 D (0.1) : Um Um 3.975 D (0.5)Baher SaidNo ratings yet
- Pengaruh Pelatihan Dan Lingkungan Kerja Terhadap Kinerja KaryawanDocument10 pagesPengaruh Pelatihan Dan Lingkungan Kerja Terhadap Kinerja KaryawanferdiantiNo ratings yet
- MITx SCX KeyConcept SC4x FVDocument59 pagesMITx SCX KeyConcept SC4x FVСергей НагаевNo ratings yet
- uPSD33XX: uPSD33XX (Turbo Series) Fast 8032 MCU With Programmable LogicDocument129 pagesuPSD33XX: uPSD33XX (Turbo Series) Fast 8032 MCU With Programmable LogicSantiago SerranoNo ratings yet
- TC78H660FTG/FNG Usage ConsiderationsDocument21 pagesTC78H660FTG/FNG Usage ConsiderationsrfidguysNo ratings yet
- Tuning of A PID Controller Using Ziegler-Nichols MethodDocument7 pagesTuning of A PID Controller Using Ziegler-Nichols MethodTomKish100% (1)
- Pressure and Friction Drag I: Fluid Flow About Immersed ObjectsDocument11 pagesPressure and Friction Drag I: Fluid Flow About Immersed ObjectsBi BiNo ratings yet
- Android DatePicker Example - JavatpointDocument7 pagesAndroid DatePicker Example - JavatpointimsukhNo ratings yet
- Emerging Tech Chap 1Document9 pagesEmerging Tech Chap 1beth elNo ratings yet
- Q80 Series Heat Pumps Installation and Commissioning ManualDocument40 pagesQ80 Series Heat Pumps Installation and Commissioning ManualVoicu DragosNo ratings yet
- SqlloadDocument13 pagesSqlloadShravanUdayNo ratings yet
- Exhaust Gas Recirculation SystemDocument6 pagesExhaust Gas Recirculation SystemgustavoNo ratings yet
- Wheatstone Bridge MeasurementDocument5 pagesWheatstone Bridge MeasurementHammad AhmedNo ratings yet
- Newton's Laws of MotionDocument21 pagesNewton's Laws of MotionharlequinlhaiNo ratings yet
- A Comparison Between LDPE and HDPE Cable Insulation Properties Following Lightning Impulse AgeingDocument4 pagesA Comparison Between LDPE and HDPE Cable Insulation Properties Following Lightning Impulse AgeingGilang Satria PasekaNo ratings yet
- Circular Picture Box - Border Gradient Color + Styles - C # & WinForms - RJ Code AdvanceDocument10 pagesCircular Picture Box - Border Gradient Color + Styles - C # & WinForms - RJ Code AdvanceToan Nguyen ManhNo ratings yet
- Rotary Switch BasicsDocument2 pagesRotary Switch BasicsWBH VideosNo ratings yet