
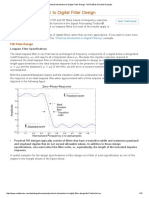
10 Timing Synchronization
10 Timing Synchronization
You might also like
- Scan Insertion - Week2&3Document48 pagesScan Insertion - Week2&3VENKATRAMAN100% (1)
- Vaibbhav Taraate - Digital Logic Design Using Verilog - Coding and RTL Synthesis (2022)Document607 pagesVaibbhav Taraate - Digital Logic Design Using Verilog - Coding and RTL Synthesis (2022)SHANKAR PNo ratings yet
- Module Descriptions 2021-2022Document77 pagesModule Descriptions 2021-2022BowackNo ratings yet
- ATPG Methodology FlowDocument37 pagesATPG Methodology FlowAdhi SuruliNo ratings yet
- ATPG Methodology FlowDocument37 pagesATPG Methodology FlowaanbalanNo ratings yet
- Spy Glass Flowfor XILINXFPGA150701112421Document6 pagesSpy Glass Flowfor XILINXFPGA150701112421Rajeev Varshney100% (1)
- Synchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasDocument5 pagesSynchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasSatya NagendraNo ratings yet
- Coincidence DetectionDocument4 pagesCoincidence Detectionjayamala adsulNo ratings yet
- Retiming Signal Flow Graphs XilinxDocument96 pagesRetiming Signal Flow Graphs Xilinxksreddy2002No ratings yet
- DownloadDocument13 pagesDownloadZoro ZoroNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationdabajiNo ratings yet
- 64 IETSMT2012May AKOHDocument9 pages64 IETSMT2012May AKOHHEIN HTET ZAWNo ratings yet
- HFNSDocument16 pagesHFNSrashmi sNo ratings yet
- SYNTHESISDocument8 pagesSYNTHESISmayur100% (2)
- Upsampling and DownsamplingDocument8 pagesUpsampling and DownsamplingAmit PrajapatiNo ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document11 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850ashishNo ratings yet
- A2 Lu PaperDocument26 pagesA2 Lu PaperspaulsNo ratings yet
- Debug and Testability Features For Multi-Protocol 10G SerdesDocument5 pagesDebug and Testability Features For Multi-Protocol 10G SerdesvelusnNo ratings yet
- Bor CelleDocument11 pagesBor CelleAdi KhardeNo ratings yet
- Implementation of A Complete GPS Receiver On The CDocument12 pagesImplementation of A Complete GPS Receiver On The CJawad HmoumaneNo ratings yet
- Ijet13 05 03 DFFGGDFDDF321Document8 pagesIjet13 05 03 DFFGGDFDDF321Navathej BangariNo ratings yet
- DSD Syllabus KtuDocument1 pageDSD Syllabus KtuAjNo ratings yet
- Module EECT505 Group Project Specification - 2011 - 2012Document9 pagesModule EECT505 Group Project Specification - 2011 - 2012Luciano BrunetteNo ratings yet
- JTS Sonntag Stonick CDRDocument8 pagesJTS Sonntag Stonick CDRAram ShishmanyanNo ratings yet
- TFT Design Flow 08Document8 pagesTFT Design Flow 08Nikhil PuriNo ratings yet
- Synthesis AlDocument7 pagesSynthesis AlAgnathavasiNo ratings yet
- Emulation MethodologyDocument7 pagesEmulation MethodologyRamakrishnaRao SoogooriNo ratings yet
- Continuously Variable Fractional Rate Decimator: Application Note: Virtex-5, Virtex-4, Spartan-3Document11 pagesContinuously Variable Fractional Rate Decimator: Application Note: Virtex-5, Virtex-4, Spartan-3ergatnsNo ratings yet
- Implementation of Reconfigurable Adaptive Filtering AlgorithmsDocument5 pagesImplementation of Reconfigurable Adaptive Filtering AlgorithmsChaitanyaNo ratings yet
- CETCME-2020 - NIET - Vineet ShekherDocument9 pagesCETCME-2020 - NIET - Vineet Shekherडाँ सूर्यदेव चौधरीNo ratings yet
- Fpga Implementation of A Phase Locked Loop Based On RandomDocument6 pagesFpga Implementation of A Phase Locked Loop Based On Random9638042No ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document10 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Fabien CallodNo ratings yet
- Epoch-Modeling and Simulation of An AllDocument40 pagesEpoch-Modeling and Simulation of An Allraducu2009No ratings yet
- Practical Introduction To Digital Filter Design - MATLAB ExampleDocument12 pagesPractical Introduction To Digital Filter Design - MATLAB ExampleEdsonNo ratings yet
- Time and Area Optimization in Processor ArchitectuDocument12 pagesTime and Area Optimization in Processor Architectubashman6744No ratings yet
- The Art of Analog Design Part 2 Monte Carlo Sampling - Analog - Custom Design - Cadence Blogs - Cadence CommunityDocument9 pagesThe Art of Analog Design Part 2 Monte Carlo Sampling - Analog - Custom Design - Cadence Blogs - Cadence CommunityMatheus LimaNo ratings yet
- DSD Lab Manual Lab 5 6 20042022 022506pmDocument7 pagesDSD Lab Manual Lab 5 6 20042022 022506pmZubair ImranNo ratings yet
- Scan Path DesignDocument54 pagesScan Path DesignaguohaqdoNo ratings yet
- SOC DFT Verification With Static Analysis and Formal Methods PDFDocument7 pagesSOC DFT Verification With Static Analysis and Formal Methods PDFSujit TikekarNo ratings yet
- FPGA Interview QuestionsDocument11 pagesFPGA Interview Questionssneha587No ratings yet
- Implementing Bit-Serial Digital Filters in At6000 FpgasDocument9 pagesImplementing Bit-Serial Digital Filters in At6000 FpgasPravesh KharelNo ratings yet
- Improvisation of Gabor Filter Design Using Verilog HDLDocument4 pagesImprovisation of Gabor Filter Design Using Verilog HDLVijay KannamallaNo ratings yet
- Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.111 - Introductory Digital Systems LaboratoryDocument10 pagesMassachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.111 - Introductory Digital Systems LaboratoryayeshaNo ratings yet
- Assignment #3: Due April 11, 2016Document6 pagesAssignment #3: Due April 11, 2016Ahmed HamoudaNo ratings yet
- Fpga Control Motor AsincronDocument7 pagesFpga Control Motor AsincronVasileSpireaNo ratings yet
- Digital IF Subsampling Using The HI5702, HSP45116 and HSP43220Document5 pagesDigital IF Subsampling Using The HI5702, HSP45116 and HSP43220chocobon_998078No ratings yet
- Scan PDFDocument49 pagesScan PDFferoz100% (1)
- DSP Lab 2Document4 pagesDSP Lab 2Abhilash OSNo ratings yet
- 16-Bit Delta-Sigma DAC With Cascade-Of-Resonators Feed-Forward Modulator and Interpolation Filter With OCSD CodeDocument4 pages16-Bit Delta-Sigma DAC With Cascade-Of-Resonators Feed-Forward Modulator and Interpolation Filter With OCSD Codealan3421407No ratings yet
- The Design of FIR Filter Base On Improved DA Algorithm and Its FPGA ImplementationDocument2 pagesThe Design of FIR Filter Base On Improved DA Algorithm and Its FPGA ImplementationLakshmi ManikantaNo ratings yet
- Vasu DFTDocument28 pagesVasu DFTsenthilkumarNo ratings yet
- Chapter 2Document8 pagesChapter 2Aldon JimenezNo ratings yet
- Power AmplifierDocument66 pagesPower Amplifiersappal73asNo ratings yet
- Implementation of The CA-CFAR Algorithm For PulsedDocument8 pagesImplementation of The CA-CFAR Algorithm For PulsedTanuja TanuNo ratings yet
- Sigma Delta Modulator ThesisDocument6 pagesSigma Delta Modulator Thesislorribynesbridgeport100% (2)
- FPGA Implimentation of Adaptive Noise Cancellation Project Report With VHDL ProgramDocument26 pagesFPGA Implimentation of Adaptive Noise Cancellation Project Report With VHDL ProgramJerin AntonyNo ratings yet
- Majzoobi2011 Chapter FPGA-BasedTrueRandomNumberGeneDocument16 pagesMajzoobi2011 Chapter FPGA-BasedTrueRandomNumberGeneRiccardo Della SalaNo ratings yet
- Adaptive Filter Implementation Using FPGADocument7 pagesAdaptive Filter Implementation Using FPGANes Alejandro CastilloNo ratings yet
- Cell Cloning For Minimizing Critical Path DelayDocument8 pagesCell Cloning For Minimizing Critical Path Delayearth v moonNo ratings yet
- Lab 3 Primer - Real Time DSP Lab ManualDocument3 pagesLab 3 Primer - Real Time DSP Lab ManualHamayunNo ratings yet
- Chat GPTDocument7 pagesChat GPTMohammed HussainNo ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- DownloadDocument13 pagesDownloadZoro ZoroNo ratings yet
- Implementation of A Verilog-Based Digital ReceiverDocument19 pagesImplementation of A Verilog-Based Digital ReceiverZoro ZoroNo ratings yet
- Verilog Based Design and Simulation of MAC and PHY Layers For Zigbee Digital TransmitterDocument9 pagesVerilog Based Design and Simulation of MAC and PHY Layers For Zigbee Digital TransmitterZoro ZoroNo ratings yet
- Ahmad 2009Document4 pagesAhmad 2009Zoro ZoroNo ratings yet
- Smart Environmental Monitoring Using Wireless Sensor NetworksDocument25 pagesSmart Environmental Monitoring Using Wireless Sensor NetworksZoro ZoroNo ratings yet
- Kibret Abebe PDFDocument88 pagesKibret Abebe PDFBharat NarumanchiNo ratings yet
- Amazon EC2 FAQsDocument89 pagesAmazon EC2 FAQsasassaNo ratings yet
- Low Cost FPGA Based Implementation of A DRFM System: Michael B. Mesarcik, Daniel W. O'Hagan, Stephen PaineDocument6 pagesLow Cost FPGA Based Implementation of A DRFM System: Michael B. Mesarcik, Daniel W. O'Hagan, Stephen PaineneerajNo ratings yet
- Peak DetectorDocument7 pagesPeak DetectorDrVikas Mahor0% (1)
- Fingerprint Minutiae Extraction Based On FPGA andDocument7 pagesFingerprint Minutiae Extraction Based On FPGA andGastón MigoneNo ratings yet
- Paper 15282Document7 pagesPaper 15282publishlambertNo ratings yet
- On FRFTDocument11 pagesOn FRFTSakshiNo ratings yet
- FPGAPhysical Design Rule Check DRCDesk ReferenceDocument25 pagesFPGAPhysical Design Rule Check DRCDesk Referencenaresh thokalaNo ratings yet
- Chapter 3Document46 pagesChapter 3Rabeea AhmadNo ratings yet
- US7825853Document24 pagesUS7825853leo trimbleNo ratings yet
- 9 .Efficient Design For Fixed Width AdderDocument45 pages9 .Efficient Design For Fixed Width Addervsangvai26No ratings yet
- s2c Single Vu440 Prodigy Logic System DatasheetDocument2 pagess2c Single Vu440 Prodigy Logic System DatasheetAmmar RedaNo ratings yet
- Go EP2SGX130GF1508I4N PDFDocument314 pagesGo EP2SGX130GF1508I4N PDFpkmagendranNo ratings yet
- Convolutional Neural Network Layers Implementation On Low-Cost Reconfigurable Edge Computing PlatformsDocument31 pagesConvolutional Neural Network Layers Implementation On Low-Cost Reconfigurable Edge Computing PlatformsSarthak GoyalNo ratings yet
- 10G 40G KintexUltraScale ReferenceDesignDocument2 pages10G 40G KintexUltraScale ReferenceDesignlitoduterNo ratings yet
- Mindray BC-2800 - Service ManualDocument108 pagesMindray BC-2800 - Service ManualSyevana TheLucky Man88% (17)
- 92077v00 Xilinx WhitePaper FinalDocument15 pages92077v00 Xilinx WhitePaper FinalUlloa JavierNo ratings yet
- Vlsi Lab Manual 2013Document64 pagesVlsi Lab Manual 2013harish33330% (1)
- LV48 Series Programmers: Power Tools For The Development EngineerDocument4 pagesLV48 Series Programmers: Power Tools For The Development EngineerahmedNo ratings yet
- Ijest10 02 12 191Document4 pagesIjest10 02 12 191wwahib2No ratings yet
- Ce PDFDocument45 pagesCe PDFFayum BirajdarNo ratings yet
- TCA.4 Kintex-7 Data Processing AMC (TCK7) - CM045: Key FeaturesDocument4 pagesTCA.4 Kintex-7 Data Processing AMC (TCK7) - CM045: Key FeatureszeniekNo ratings yet
- Vlsi Lab Wo VM PDFDocument68 pagesVlsi Lab Wo VM PDFanon_680775278No ratings yet
- Built in Self-Test: A Review On BIST Insertion Methods and Fault TracingDocument10 pagesBuilt in Self-Test: A Review On BIST Insertion Methods and Fault Tracingaditya_pundirNo ratings yet
- COA AssignmentDocument11 pagesCOA AssignmentSuraj PandaNo ratings yet
- COL215 Assignment 3: Title: Digital Image FilterDocument6 pagesCOL215 Assignment 3: Title: Digital Image FilterKatia Rania BITAMNo ratings yet
- MTech CSIT SyllabusDocument44 pagesMTech CSIT Syllabusashut911No ratings yet




























































































Download as pdf or txt
You might also like
- Scan Insertion - Week2&3Document48 pagesScan Insertion - Week2&3VENKATRAMAN100% (1)
- Vaibbhav Taraate - Digital Logic Design Using Verilog - Coding and RTL Synthesis (2022)Document607 pagesVaibbhav Taraate - Digital Logic Design Using Verilog - Coding and RTL Synthesis (2022)SHANKAR PNo ratings yet
- Module Descriptions 2021-2022Document77 pagesModule Descriptions 2021-2022BowackNo ratings yet
- ATPG Methodology FlowDocument37 pagesATPG Methodology FlowAdhi SuruliNo ratings yet
- ATPG Methodology FlowDocument37 pagesATPG Methodology FlowaanbalanNo ratings yet
- Spy Glass Flowfor XILINXFPGA150701112421Document6 pagesSpy Glass Flowfor XILINXFPGA150701112421Rajeev Varshney100% (1)
- Synchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasDocument5 pagesSynchronization For QDPSK - Costas Loop and Gardner Algorithm Using FpgasSatya NagendraNo ratings yet
- Coincidence DetectionDocument4 pagesCoincidence Detectionjayamala adsulNo ratings yet
- Retiming Signal Flow Graphs XilinxDocument96 pagesRetiming Signal Flow Graphs Xilinxksreddy2002No ratings yet
- DownloadDocument13 pagesDownloadZoro ZoroNo ratings yet
- Design and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationDocument4 pagesDesign and Implementation of Early-Late Gate Bit Synchronizer For Satellite CommunicationdabajiNo ratings yet
- 64 IETSMT2012May AKOHDocument9 pages64 IETSMT2012May AKOHHEIN HTET ZAWNo ratings yet
- HFNSDocument16 pagesHFNSrashmi sNo ratings yet
- SYNTHESISDocument8 pagesSYNTHESISmayur100% (2)
- Upsampling and DownsamplingDocument8 pagesUpsampling and DownsamplingAmit PrajapatiNo ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document11 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850ashishNo ratings yet
- A2 Lu PaperDocument26 pagesA2 Lu PaperspaulsNo ratings yet
- Debug and Testability Features For Multi-Protocol 10G SerdesDocument5 pagesDebug and Testability Features For Multi-Protocol 10G SerdesvelusnNo ratings yet
- Bor CelleDocument11 pagesBor CelleAdi KhardeNo ratings yet
- Implementation of A Complete GPS Receiver On The CDocument12 pagesImplementation of A Complete GPS Receiver On The CJawad HmoumaneNo ratings yet
- Ijet13 05 03 DFFGGDFDDF321Document8 pagesIjet13 05 03 DFFGGDFDDF321Navathej BangariNo ratings yet
- DSD Syllabus KtuDocument1 pageDSD Syllabus KtuAjNo ratings yet
- Module EECT505 Group Project Specification - 2011 - 2012Document9 pagesModule EECT505 Group Project Specification - 2011 - 2012Luciano BrunetteNo ratings yet
- JTS Sonntag Stonick CDRDocument8 pagesJTS Sonntag Stonick CDRAram ShishmanyanNo ratings yet
- TFT Design Flow 08Document8 pagesTFT Design Flow 08Nikhil PuriNo ratings yet
- Synthesis AlDocument7 pagesSynthesis AlAgnathavasiNo ratings yet
- Emulation MethodologyDocument7 pagesEmulation MethodologyRamakrishnaRao SoogooriNo ratings yet
- Continuously Variable Fractional Rate Decimator: Application Note: Virtex-5, Virtex-4, Spartan-3Document11 pagesContinuously Variable Fractional Rate Decimator: Application Note: Virtex-5, Virtex-4, Spartan-3ergatnsNo ratings yet
- Implementation of Reconfigurable Adaptive Filtering AlgorithmsDocument5 pagesImplementation of Reconfigurable Adaptive Filtering AlgorithmsChaitanyaNo ratings yet
- CETCME-2020 - NIET - Vineet ShekherDocument9 pagesCETCME-2020 - NIET - Vineet Shekherडाँ सूर्यदेव चौधरीNo ratings yet
- Fpga Implementation of A Phase Locked Loop Based On RandomDocument6 pagesFpga Implementation of A Phase Locked Loop Based On Random9638042No ratings yet
- High Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Document10 pagesHigh Speed Digital Distance Relaying Scheme Using FPGA and IEC 61850Fabien CallodNo ratings yet
- Epoch-Modeling and Simulation of An AllDocument40 pagesEpoch-Modeling and Simulation of An Allraducu2009No ratings yet
- Practical Introduction To Digital Filter Design - MATLAB ExampleDocument12 pagesPractical Introduction To Digital Filter Design - MATLAB ExampleEdsonNo ratings yet
- Time and Area Optimization in Processor ArchitectuDocument12 pagesTime and Area Optimization in Processor Architectubashman6744No ratings yet
- The Art of Analog Design Part 2 Monte Carlo Sampling - Analog - Custom Design - Cadence Blogs - Cadence CommunityDocument9 pagesThe Art of Analog Design Part 2 Monte Carlo Sampling - Analog - Custom Design - Cadence Blogs - Cadence CommunityMatheus LimaNo ratings yet
- DSD Lab Manual Lab 5 6 20042022 022506pmDocument7 pagesDSD Lab Manual Lab 5 6 20042022 022506pmZubair ImranNo ratings yet
- Scan Path DesignDocument54 pagesScan Path DesignaguohaqdoNo ratings yet
- SOC DFT Verification With Static Analysis and Formal Methods PDFDocument7 pagesSOC DFT Verification With Static Analysis and Formal Methods PDFSujit TikekarNo ratings yet
- FPGA Interview QuestionsDocument11 pagesFPGA Interview Questionssneha587No ratings yet
- Implementing Bit-Serial Digital Filters in At6000 FpgasDocument9 pagesImplementing Bit-Serial Digital Filters in At6000 FpgasPravesh KharelNo ratings yet
- Improvisation of Gabor Filter Design Using Verilog HDLDocument4 pagesImprovisation of Gabor Filter Design Using Verilog HDLVijay KannamallaNo ratings yet
- Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.111 - Introductory Digital Systems LaboratoryDocument10 pagesMassachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.111 - Introductory Digital Systems LaboratoryayeshaNo ratings yet
- Assignment #3: Due April 11, 2016Document6 pagesAssignment #3: Due April 11, 2016Ahmed HamoudaNo ratings yet
- Fpga Control Motor AsincronDocument7 pagesFpga Control Motor AsincronVasileSpireaNo ratings yet
- Digital IF Subsampling Using The HI5702, HSP45116 and HSP43220Document5 pagesDigital IF Subsampling Using The HI5702, HSP45116 and HSP43220chocobon_998078No ratings yet
- Scan PDFDocument49 pagesScan PDFferoz100% (1)
- DSP Lab 2Document4 pagesDSP Lab 2Abhilash OSNo ratings yet
- 16-Bit Delta-Sigma DAC With Cascade-Of-Resonators Feed-Forward Modulator and Interpolation Filter With OCSD CodeDocument4 pages16-Bit Delta-Sigma DAC With Cascade-Of-Resonators Feed-Forward Modulator and Interpolation Filter With OCSD Codealan3421407No ratings yet
- The Design of FIR Filter Base On Improved DA Algorithm and Its FPGA ImplementationDocument2 pagesThe Design of FIR Filter Base On Improved DA Algorithm and Its FPGA ImplementationLakshmi ManikantaNo ratings yet
- Vasu DFTDocument28 pagesVasu DFTsenthilkumarNo ratings yet
- Chapter 2Document8 pagesChapter 2Aldon JimenezNo ratings yet
- Power AmplifierDocument66 pagesPower Amplifiersappal73asNo ratings yet
- Implementation of The CA-CFAR Algorithm For PulsedDocument8 pagesImplementation of The CA-CFAR Algorithm For PulsedTanuja TanuNo ratings yet
- Sigma Delta Modulator ThesisDocument6 pagesSigma Delta Modulator Thesislorribynesbridgeport100% (2)
- FPGA Implimentation of Adaptive Noise Cancellation Project Report With VHDL ProgramDocument26 pagesFPGA Implimentation of Adaptive Noise Cancellation Project Report With VHDL ProgramJerin AntonyNo ratings yet
- Majzoobi2011 Chapter FPGA-BasedTrueRandomNumberGeneDocument16 pagesMajzoobi2011 Chapter FPGA-BasedTrueRandomNumberGeneRiccardo Della SalaNo ratings yet
- Adaptive Filter Implementation Using FPGADocument7 pagesAdaptive Filter Implementation Using FPGANes Alejandro CastilloNo ratings yet
- Cell Cloning For Minimizing Critical Path DelayDocument8 pagesCell Cloning For Minimizing Critical Path Delayearth v moonNo ratings yet
- Lab 3 Primer - Real Time DSP Lab ManualDocument3 pagesLab 3 Primer - Real Time DSP Lab ManualHamayunNo ratings yet
- Chat GPTDocument7 pagesChat GPTMohammed HussainNo ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- DownloadDocument13 pagesDownloadZoro ZoroNo ratings yet
- Implementation of A Verilog-Based Digital ReceiverDocument19 pagesImplementation of A Verilog-Based Digital ReceiverZoro ZoroNo ratings yet
- Verilog Based Design and Simulation of MAC and PHY Layers For Zigbee Digital TransmitterDocument9 pagesVerilog Based Design and Simulation of MAC and PHY Layers For Zigbee Digital TransmitterZoro ZoroNo ratings yet
- Ahmad 2009Document4 pagesAhmad 2009Zoro ZoroNo ratings yet
- Smart Environmental Monitoring Using Wireless Sensor NetworksDocument25 pagesSmart Environmental Monitoring Using Wireless Sensor NetworksZoro ZoroNo ratings yet
- Kibret Abebe PDFDocument88 pagesKibret Abebe PDFBharat NarumanchiNo ratings yet
- Amazon EC2 FAQsDocument89 pagesAmazon EC2 FAQsasassaNo ratings yet
- Low Cost FPGA Based Implementation of A DRFM System: Michael B. Mesarcik, Daniel W. O'Hagan, Stephen PaineDocument6 pagesLow Cost FPGA Based Implementation of A DRFM System: Michael B. Mesarcik, Daniel W. O'Hagan, Stephen PaineneerajNo ratings yet
- Peak DetectorDocument7 pagesPeak DetectorDrVikas Mahor0% (1)
- Fingerprint Minutiae Extraction Based On FPGA andDocument7 pagesFingerprint Minutiae Extraction Based On FPGA andGastón MigoneNo ratings yet
- Paper 15282Document7 pagesPaper 15282publishlambertNo ratings yet
- On FRFTDocument11 pagesOn FRFTSakshiNo ratings yet
- FPGAPhysical Design Rule Check DRCDesk ReferenceDocument25 pagesFPGAPhysical Design Rule Check DRCDesk Referencenaresh thokalaNo ratings yet
- Chapter 3Document46 pagesChapter 3Rabeea AhmadNo ratings yet
- US7825853Document24 pagesUS7825853leo trimbleNo ratings yet
- 9 .Efficient Design For Fixed Width AdderDocument45 pages9 .Efficient Design For Fixed Width Addervsangvai26No ratings yet
- s2c Single Vu440 Prodigy Logic System DatasheetDocument2 pagess2c Single Vu440 Prodigy Logic System DatasheetAmmar RedaNo ratings yet
- Go EP2SGX130GF1508I4N PDFDocument314 pagesGo EP2SGX130GF1508I4N PDFpkmagendranNo ratings yet
- Convolutional Neural Network Layers Implementation On Low-Cost Reconfigurable Edge Computing PlatformsDocument31 pagesConvolutional Neural Network Layers Implementation On Low-Cost Reconfigurable Edge Computing PlatformsSarthak GoyalNo ratings yet
- 10G 40G KintexUltraScale ReferenceDesignDocument2 pages10G 40G KintexUltraScale ReferenceDesignlitoduterNo ratings yet
- Mindray BC-2800 - Service ManualDocument108 pagesMindray BC-2800 - Service ManualSyevana TheLucky Man88% (17)
- 92077v00 Xilinx WhitePaper FinalDocument15 pages92077v00 Xilinx WhitePaper FinalUlloa JavierNo ratings yet
- Vlsi Lab Manual 2013Document64 pagesVlsi Lab Manual 2013harish33330% (1)
- LV48 Series Programmers: Power Tools For The Development EngineerDocument4 pagesLV48 Series Programmers: Power Tools For The Development EngineerahmedNo ratings yet
- Ijest10 02 12 191Document4 pagesIjest10 02 12 191wwahib2No ratings yet
- Ce PDFDocument45 pagesCe PDFFayum BirajdarNo ratings yet
- TCA.4 Kintex-7 Data Processing AMC (TCK7) - CM045: Key FeaturesDocument4 pagesTCA.4 Kintex-7 Data Processing AMC (TCK7) - CM045: Key FeatureszeniekNo ratings yet
- Vlsi Lab Wo VM PDFDocument68 pagesVlsi Lab Wo VM PDFanon_680775278No ratings yet
- Built in Self-Test: A Review On BIST Insertion Methods and Fault TracingDocument10 pagesBuilt in Self-Test: A Review On BIST Insertion Methods and Fault Tracingaditya_pundirNo ratings yet
- COA AssignmentDocument11 pagesCOA AssignmentSuraj PandaNo ratings yet
- COL215 Assignment 3: Title: Digital Image FilterDocument6 pagesCOL215 Assignment 3: Title: Digital Image FilterKatia Rania BITAMNo ratings yet
- MTech CSIT SyllabusDocument44 pagesMTech CSIT Syllabusashut911No ratings yet