
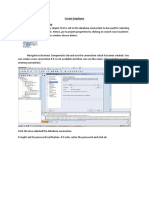
Dcs 7302
Dcs 7302
You might also like
- How To Store BI Report Output As A Document Record Using HCM ExtractsDocument21 pagesHow To Store BI Report Output As A Document Record Using HCM ExtractsRahh SlNo ratings yet
- DWM May 19Document3 pagesDWM May 19Muhammad ShanuNo ratings yet
- Data Warehousing and Data MiningDocument6 pagesData Warehousing and Data MiningtigerankurNo ratings yet
- CST466 DATA MINING, OCTOBER 2023.pdf - CrdownloadDocument3 pagesCST466 DATA MINING, OCTOBER 2023.pdf - Crdownload20b739No ratings yet
- Answer All Questions, Each Carries3 Marks.: Page 1 of 2Document2 pagesAnswer All Questions, Each Carries3 Marks.: Page 1 of 2SUNEESHKUMAR PNo ratings yet
- Answer All Questions, Each Carries3 Marks.: Page 1 of 2Document2 pagesAnswer All Questions, Each Carries3 Marks.: Page 1 of 2SUNEESHKUMAR PNo ratings yet
- 2021 December PG M.SC (It) M.SC (It)Document36 pages2021 December PG M.SC (It) M.SC (It)BI195824161 Personal AccountingNo ratings yet
- Cia1 PaperDocument2 pagesCia1 PapervikNo ratings yet
- A H192009 Pages: 3: Answer All Questions, Each Carries 4 MarksDocument3 pagesA H192009 Pages: 3: Answer All Questions, Each Carries 4 MarksSrinivas R PaiNo ratings yet
- r05321204 Data Warehousing and Data MiningDocument5 pagesr05321204 Data Warehousing and Data MiningSRINIVASA RAO GANTANo ratings yet
- MCS-043 (1) Question PaperDocument4 pagesMCS-043 (1) Question PaperNilofer VarisNo ratings yet
- CS467 ADocument3 pagesCS467 AE3 TechNo ratings yet
- Answer All Questions, Each Carries 4 MarksDocument3 pagesAnswer All Questions, Each Carries 4 MarksKarthikaNo ratings yet
- IT7C4 IR December 2019Document3 pagesIT7C4 IR December 2019KIRTAN DOBARIYANo ratings yet
- Tribhuvan University: Group-A Attempt Any Two Questions (10 X 2 20)Document9 pagesTribhuvan University: Group-A Attempt Any Two Questions (10 X 2 20)Ashish UpadhayaNo ratings yet
- B.tech 2017 Sem7 Daie Sessional IDocument1 pageB.tech 2017 Sem7 Daie Sessional IJay SamaniNo ratings yet
- CS402 Data Mining and Warehousing Question BankDocument6 pagesCS402 Data Mining and Warehousing Question BankJunaid M FaisalNo ratings yet
- Advanced DatabasesDocument2 pagesAdvanced DatabasesbillasankarNo ratings yet
- BCA May 2018 Question Papers PDFDocument45 pagesBCA May 2018 Question Papers PDFsakthivelNo ratings yet
- Final Exam BWA44603Document4 pagesFinal Exam BWA44603Mohd Asrul Affendi AbdullahNo ratings yet
- 2020 - December - UG - B.SC (CS) - B.SC (CS)Document29 pages2020 - December - UG - B.SC (CS) - B.SC (CS)Deepak's PageNo ratings yet
- Rlmca204 QPDocument2 pagesRlmca204 QPLiz GeorgeNo ratings yet
- Jss Mahavidyapeetha: AY 2019-20 (Even Semester)Document2 pagesJss Mahavidyapeetha: AY 2019-20 (Even Semester)vikNo ratings yet
- CST204 Database Management Systems, January 2024Document4 pagesCST204 Database Management Systems, January 2024binnytmzNo ratings yet
- DWDM Assignment 1Document4 pagesDWDM Assignment 1jyothibellary2754No ratings yet
- Model Cs 8 PDFDocument17 pagesModel Cs 8 PDFPoomani PunithaNo ratings yet
- 2020-09-22SupplementaryCS467CS467-E - Ktu QbankDocument3 pages2020-09-22SupplementaryCS467CS467-E - Ktu Qbanksabitha sNo ratings yet
- Sample Paper 1 (Solved) : Class Xii Informatics Practices (New)Document4 pagesSample Paper 1 (Solved) : Class Xii Informatics Practices (New)Harsh Vardhan SinghNo ratings yet
- Ec6301 Oopds Nov - Dec2016Document2 pagesEc6301 Oopds Nov - Dec2016sdarunprasadNo ratings yet
- Btech Cs 6 Sem Data Warehousing and Data Mining Ncs 066 2016 17Document2 pagesBtech Cs 6 Sem Data Warehousing and Data Mining Ncs 066 2016 17MonikaNo ratings yet
- DBMS RetestDocument2 pagesDBMS RetestSamNo ratings yet
- Department of Computer Science and EngineeringDocument3 pagesDepartment of Computer Science and EngineeringMd.Ashiqur RahmanNo ratings yet
- Rlmca208 QPDocument2 pagesRlmca208 QPLiz GeorgeNo ratings yet
- Assign em NTDocument2 pagesAssign em NTKholiator sssNo ratings yet
- 15A05602 Data Warehousing & MiningDocument2 pages15A05602 Data Warehousing & MiningChitra Madhuri YashodaNo ratings yet
- (WWW - Entrance-Exam - Net) - MU BE in IT 7th Sem. Data Warehousing, Mining and Business Intelligence Sample Paper 2Document1 page(WWW - Entrance-Exam - Net) - MU BE in IT 7th Sem. Data Warehousing, Mining and Business Intelligence Sample Paper 2saurAbhNo ratings yet
- Jntuworld: R07 Set No. 2Document7 pagesJntuworld: R07 Set No. 2Bhargavramudu JajjaraNo ratings yet
- MCS-023 11Document5 pagesMCS-023 11Yourfriend 2113No ratings yet
- Important Questions of Machine LearningDocument5 pagesImportant Questions of Machine Learningzeeshanahmad12030No ratings yet
- E D1071 Pages: 4: Limit Answers To The Required Points. Answer All Questions, Each Carries 3 MarksDocument4 pagesE D1071 Pages: 4: Limit Answers To The Required Points. Answer All Questions, Each Carries 3 MarksAnandu ChickuNo ratings yet
- MST 001Document8 pagesMST 001shekhawatsp101No ratings yet
- 6th Sem CSE PYQDocument27 pages6th Sem CSE PYQcoderabhi2003shuklaNo ratings yet
- VU C5 T P Data Structure 2021Document4 pagesVU C5 T P Data Structure 2021enabarunmondal2004No ratings yet
- CE003323 ADS Exam2Document5 pagesCE003323 ADS Exam2Ramesh BishwasNo ratings yet
- @vtucode - in Model Paper 2018 Scheme Set 2 DBMSDocument3 pages@vtucode - in Model Paper 2018 Scheme Set 2 DBMSAstra DemonNo ratings yet
- DS Model - QP - S2Document2 pagesDS Model - QP - S2Ramya RadhakrishnanNo ratings yet
- ECS305 (OOS) 2nd SessionalDocument3 pagesECS305 (OOS) 2nd SessionalAshutosh SinghNo ratings yet
- Set CDocument2 pagesSet Cᴀʙʜɪsʜᴇᴋ ᴄʜɪɴᴄʜᴏʟᴇNo ratings yet
- 2013 MainDocument1 page2013 MainAnjali ReddyNo ratings yet
- Bangladesh Army University of Engineering & Technology: (Bauet)Document2 pagesBangladesh Army University of Engineering & Technology: (Bauet)Avishak 31No ratings yet
- Itt206 Database Management Systems, July 2021Document4 pagesItt206 Database Management Systems, July 2021sona sasikumarNo ratings yet
- Database Technology and NosqlDocument2 pagesDatabase Technology and NosqlakashbabuchovvattukunnelNo ratings yet
- AD3301Document2 pagesAD3301palaniperumal041979No ratings yet
- Data Warehousing and Data MiningDocument8 pagesData Warehousing and Data MiningkhajaimadNo ratings yet
- Data Mining Worksheet OneDocument2 pagesData Mining Worksheet OneAbrham DanailNo ratings yet
- DM HW2 SolDocument4 pagesDM HW2 SolWafaa BasilNo ratings yet
- Cse Aids Dec 2021Document14 pagesCse Aids Dec 2021RitikaNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological Universityfeyayel990No ratings yet
- Machine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionFrom EverandMachine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionNo ratings yet
- CH 2Document42 pagesCH 2Rishab Jain 2027203No ratings yet
- IT Certification Guaranteed, The Easy Way!Document5 pagesIT Certification Guaranteed, The Easy Way!Shefali Anand100% (1)
- Data Warehousing and Data Minining Answer Key - Anna University (16M & 2M With Answers)Document139 pagesData Warehousing and Data Minining Answer Key - Anna University (16M & 2M With Answers)Rohith D'SouzaNo ratings yet
- SQL NotesDocument40 pagesSQL NotesMounikaNo ratings yet
- Trafodion Messages GuideDocument386 pagesTrafodion Messages GuideaNo ratings yet
- Stock Market PredictionDocument15 pagesStock Market Predictionuday nayaka100% (1)
- ChaitanyaDocument8 pagesChaitanyamukthesh9No ratings yet
- SQL Quick Reference IIIDocument2 pagesSQL Quick Reference IIIEmma-Leena VinterNo ratings yet
- It Sample Paper 1Document5 pagesIt Sample Paper 1Payal PolNo ratings yet
- Fuzzy Set and Possibility TheoryDocument14 pagesFuzzy Set and Possibility TheoryMohamed Hechmi JERIDINo ratings yet
- SAP HealthcareDocument107 pagesSAP HealthcarevenkatNo ratings yet
- Module 4Document37 pagesModule 4Aryan VNo ratings yet
- Iit Data ScienceDocument20 pagesIit Data Sciencegiriprasadkovai1No ratings yet
- SAP Hana Frequently Asked Interview QuestionsDocument12 pagesSAP Hana Frequently Asked Interview Questionsr99100% (1)
- Manual 1 For Datamine RMDocument15 pagesManual 1 For Datamine RMNursultan IliyasNo ratings yet
- Installing MariaDB On RHEL 8Document15 pagesInstalling MariaDB On RHEL 8Andinet EndayilaluNo ratings yet
- Cambridge IGCSE: Information and Communication Technology 0417/21Document12 pagesCambridge IGCSE: Information and Communication Technology 0417/21obedingwa moyoNo ratings yet
- DFo 1 3Document19 pagesDFo 1 3Donna HernandezNo ratings yet
- Electronic Record Keeping IMR664Document19 pagesElectronic Record Keeping IMR664Amirull AdlanNo ratings yet
- Subject Code: 80359 Subject Name: Data Warehousing and Data Mining Common Subject Code (If Any)Document9 pagesSubject Code: 80359 Subject Name: Data Warehousing and Data Mining Common Subject Code (If Any)Manish JagtapNo ratings yet
- Day 3 - PeopleCodeDocument27 pagesDay 3 - PeopleCodeprabindasNo ratings yet
- OAF-Create Employee PageDocument43 pagesOAF-Create Employee Pagejaggaraju8100% (1)
- Assignment 1: Health Informatics Department HCI 111Document3 pagesAssignment 1: Health Informatics Department HCI 111habibNo ratings yet
- Knitting ManagementDocument53 pagesKnitting ManagementESWARAN SANTHOSHNo ratings yet
- Research Paper On Oracle DatabaseDocument4 pagesResearch Paper On Oracle Databaseqptwukrif100% (1)
- Unit 6 Fds 2023Document67 pagesUnit 6 Fds 2023Anuja WaghNo ratings yet
- Tuning Database Locks & Latches: Hamid R. MinouiDocument60 pagesTuning Database Locks & Latches: Hamid R. MinouiSrikanth LingalaNo ratings yet
- Case Study - Online Assessment System (OAS)Document10 pagesCase Study - Online Assessment System (OAS)SurabhiNo ratings yet
- SAP S4HANA 1809 Release Information NoteDocument12 pagesSAP S4HANA 1809 Release Information NoteRodrigoPepelascovNo ratings yet
























































































Download as pdf or txt
You might also like
- How To Store BI Report Output As A Document Record Using HCM ExtractsDocument21 pagesHow To Store BI Report Output As A Document Record Using HCM ExtractsRahh SlNo ratings yet
- DWM May 19Document3 pagesDWM May 19Muhammad ShanuNo ratings yet
- Data Warehousing and Data MiningDocument6 pagesData Warehousing and Data MiningtigerankurNo ratings yet
- CST466 DATA MINING, OCTOBER 2023.pdf - CrdownloadDocument3 pagesCST466 DATA MINING, OCTOBER 2023.pdf - Crdownload20b739No ratings yet
- Answer All Questions, Each Carries3 Marks.: Page 1 of 2Document2 pagesAnswer All Questions, Each Carries3 Marks.: Page 1 of 2SUNEESHKUMAR PNo ratings yet
- Answer All Questions, Each Carries3 Marks.: Page 1 of 2Document2 pagesAnswer All Questions, Each Carries3 Marks.: Page 1 of 2SUNEESHKUMAR PNo ratings yet
- 2021 December PG M.SC (It) M.SC (It)Document36 pages2021 December PG M.SC (It) M.SC (It)BI195824161 Personal AccountingNo ratings yet
- Cia1 PaperDocument2 pagesCia1 PapervikNo ratings yet
- A H192009 Pages: 3: Answer All Questions, Each Carries 4 MarksDocument3 pagesA H192009 Pages: 3: Answer All Questions, Each Carries 4 MarksSrinivas R PaiNo ratings yet
- r05321204 Data Warehousing and Data MiningDocument5 pagesr05321204 Data Warehousing and Data MiningSRINIVASA RAO GANTANo ratings yet
- MCS-043 (1) Question PaperDocument4 pagesMCS-043 (1) Question PaperNilofer VarisNo ratings yet
- CS467 ADocument3 pagesCS467 AE3 TechNo ratings yet
- Answer All Questions, Each Carries 4 MarksDocument3 pagesAnswer All Questions, Each Carries 4 MarksKarthikaNo ratings yet
- IT7C4 IR December 2019Document3 pagesIT7C4 IR December 2019KIRTAN DOBARIYANo ratings yet
- Tribhuvan University: Group-A Attempt Any Two Questions (10 X 2 20)Document9 pagesTribhuvan University: Group-A Attempt Any Two Questions (10 X 2 20)Ashish UpadhayaNo ratings yet
- B.tech 2017 Sem7 Daie Sessional IDocument1 pageB.tech 2017 Sem7 Daie Sessional IJay SamaniNo ratings yet
- CS402 Data Mining and Warehousing Question BankDocument6 pagesCS402 Data Mining and Warehousing Question BankJunaid M FaisalNo ratings yet
- Advanced DatabasesDocument2 pagesAdvanced DatabasesbillasankarNo ratings yet
- BCA May 2018 Question Papers PDFDocument45 pagesBCA May 2018 Question Papers PDFsakthivelNo ratings yet
- Final Exam BWA44603Document4 pagesFinal Exam BWA44603Mohd Asrul Affendi AbdullahNo ratings yet
- 2020 - December - UG - B.SC (CS) - B.SC (CS)Document29 pages2020 - December - UG - B.SC (CS) - B.SC (CS)Deepak's PageNo ratings yet
- Rlmca204 QPDocument2 pagesRlmca204 QPLiz GeorgeNo ratings yet
- Jss Mahavidyapeetha: AY 2019-20 (Even Semester)Document2 pagesJss Mahavidyapeetha: AY 2019-20 (Even Semester)vikNo ratings yet
- CST204 Database Management Systems, January 2024Document4 pagesCST204 Database Management Systems, January 2024binnytmzNo ratings yet
- DWDM Assignment 1Document4 pagesDWDM Assignment 1jyothibellary2754No ratings yet
- Model Cs 8 PDFDocument17 pagesModel Cs 8 PDFPoomani PunithaNo ratings yet
- 2020-09-22SupplementaryCS467CS467-E - Ktu QbankDocument3 pages2020-09-22SupplementaryCS467CS467-E - Ktu Qbanksabitha sNo ratings yet
- Sample Paper 1 (Solved) : Class Xii Informatics Practices (New)Document4 pagesSample Paper 1 (Solved) : Class Xii Informatics Practices (New)Harsh Vardhan SinghNo ratings yet
- Ec6301 Oopds Nov - Dec2016Document2 pagesEc6301 Oopds Nov - Dec2016sdarunprasadNo ratings yet
- Btech Cs 6 Sem Data Warehousing and Data Mining Ncs 066 2016 17Document2 pagesBtech Cs 6 Sem Data Warehousing and Data Mining Ncs 066 2016 17MonikaNo ratings yet
- DBMS RetestDocument2 pagesDBMS RetestSamNo ratings yet
- Department of Computer Science and EngineeringDocument3 pagesDepartment of Computer Science and EngineeringMd.Ashiqur RahmanNo ratings yet
- Rlmca208 QPDocument2 pagesRlmca208 QPLiz GeorgeNo ratings yet
- Assign em NTDocument2 pagesAssign em NTKholiator sssNo ratings yet
- 15A05602 Data Warehousing & MiningDocument2 pages15A05602 Data Warehousing & MiningChitra Madhuri YashodaNo ratings yet
- (WWW - Entrance-Exam - Net) - MU BE in IT 7th Sem. Data Warehousing, Mining and Business Intelligence Sample Paper 2Document1 page(WWW - Entrance-Exam - Net) - MU BE in IT 7th Sem. Data Warehousing, Mining and Business Intelligence Sample Paper 2saurAbhNo ratings yet
- Jntuworld: R07 Set No. 2Document7 pagesJntuworld: R07 Set No. 2Bhargavramudu JajjaraNo ratings yet
- MCS-023 11Document5 pagesMCS-023 11Yourfriend 2113No ratings yet
- Important Questions of Machine LearningDocument5 pagesImportant Questions of Machine Learningzeeshanahmad12030No ratings yet
- E D1071 Pages: 4: Limit Answers To The Required Points. Answer All Questions, Each Carries 3 MarksDocument4 pagesE D1071 Pages: 4: Limit Answers To The Required Points. Answer All Questions, Each Carries 3 MarksAnandu ChickuNo ratings yet
- MST 001Document8 pagesMST 001shekhawatsp101No ratings yet
- 6th Sem CSE PYQDocument27 pages6th Sem CSE PYQcoderabhi2003shuklaNo ratings yet
- VU C5 T P Data Structure 2021Document4 pagesVU C5 T P Data Structure 2021enabarunmondal2004No ratings yet
- CE003323 ADS Exam2Document5 pagesCE003323 ADS Exam2Ramesh BishwasNo ratings yet
- @vtucode - in Model Paper 2018 Scheme Set 2 DBMSDocument3 pages@vtucode - in Model Paper 2018 Scheme Set 2 DBMSAstra DemonNo ratings yet
- DS Model - QP - S2Document2 pagesDS Model - QP - S2Ramya RadhakrishnanNo ratings yet
- ECS305 (OOS) 2nd SessionalDocument3 pagesECS305 (OOS) 2nd SessionalAshutosh SinghNo ratings yet
- Set CDocument2 pagesSet Cᴀʙʜɪsʜᴇᴋ ᴄʜɪɴᴄʜᴏʟᴇNo ratings yet
- 2013 MainDocument1 page2013 MainAnjali ReddyNo ratings yet
- Bangladesh Army University of Engineering & Technology: (Bauet)Document2 pagesBangladesh Army University of Engineering & Technology: (Bauet)Avishak 31No ratings yet
- Itt206 Database Management Systems, July 2021Document4 pagesItt206 Database Management Systems, July 2021sona sasikumarNo ratings yet
- Database Technology and NosqlDocument2 pagesDatabase Technology and NosqlakashbabuchovvattukunnelNo ratings yet
- AD3301Document2 pagesAD3301palaniperumal041979No ratings yet
- Data Warehousing and Data MiningDocument8 pagesData Warehousing and Data MiningkhajaimadNo ratings yet
- Data Mining Worksheet OneDocument2 pagesData Mining Worksheet OneAbrham DanailNo ratings yet
- DM HW2 SolDocument4 pagesDM HW2 SolWafaa BasilNo ratings yet
- Cse Aids Dec 2021Document14 pagesCse Aids Dec 2021RitikaNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological Universityfeyayel990No ratings yet
- Machine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionFrom EverandMachine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionNo ratings yet
- CH 2Document42 pagesCH 2Rishab Jain 2027203No ratings yet
- IT Certification Guaranteed, The Easy Way!Document5 pagesIT Certification Guaranteed, The Easy Way!Shefali Anand100% (1)
- Data Warehousing and Data Minining Answer Key - Anna University (16M & 2M With Answers)Document139 pagesData Warehousing and Data Minining Answer Key - Anna University (16M & 2M With Answers)Rohith D'SouzaNo ratings yet
- SQL NotesDocument40 pagesSQL NotesMounikaNo ratings yet
- Trafodion Messages GuideDocument386 pagesTrafodion Messages GuideaNo ratings yet
- Stock Market PredictionDocument15 pagesStock Market Predictionuday nayaka100% (1)
- ChaitanyaDocument8 pagesChaitanyamukthesh9No ratings yet
- SQL Quick Reference IIIDocument2 pagesSQL Quick Reference IIIEmma-Leena VinterNo ratings yet
- It Sample Paper 1Document5 pagesIt Sample Paper 1Payal PolNo ratings yet
- Fuzzy Set and Possibility TheoryDocument14 pagesFuzzy Set and Possibility TheoryMohamed Hechmi JERIDINo ratings yet
- SAP HealthcareDocument107 pagesSAP HealthcarevenkatNo ratings yet
- Module 4Document37 pagesModule 4Aryan VNo ratings yet
- Iit Data ScienceDocument20 pagesIit Data Sciencegiriprasadkovai1No ratings yet
- SAP Hana Frequently Asked Interview QuestionsDocument12 pagesSAP Hana Frequently Asked Interview Questionsr99100% (1)
- Manual 1 For Datamine RMDocument15 pagesManual 1 For Datamine RMNursultan IliyasNo ratings yet
- Installing MariaDB On RHEL 8Document15 pagesInstalling MariaDB On RHEL 8Andinet EndayilaluNo ratings yet
- Cambridge IGCSE: Information and Communication Technology 0417/21Document12 pagesCambridge IGCSE: Information and Communication Technology 0417/21obedingwa moyoNo ratings yet
- DFo 1 3Document19 pagesDFo 1 3Donna HernandezNo ratings yet
- Electronic Record Keeping IMR664Document19 pagesElectronic Record Keeping IMR664Amirull AdlanNo ratings yet
- Subject Code: 80359 Subject Name: Data Warehousing and Data Mining Common Subject Code (If Any)Document9 pagesSubject Code: 80359 Subject Name: Data Warehousing and Data Mining Common Subject Code (If Any)Manish JagtapNo ratings yet
- Day 3 - PeopleCodeDocument27 pagesDay 3 - PeopleCodeprabindasNo ratings yet
- OAF-Create Employee PageDocument43 pagesOAF-Create Employee Pagejaggaraju8100% (1)
- Assignment 1: Health Informatics Department HCI 111Document3 pagesAssignment 1: Health Informatics Department HCI 111habibNo ratings yet
- Knitting ManagementDocument53 pagesKnitting ManagementESWARAN SANTHOSHNo ratings yet
- Research Paper On Oracle DatabaseDocument4 pagesResearch Paper On Oracle Databaseqptwukrif100% (1)
- Unit 6 Fds 2023Document67 pagesUnit 6 Fds 2023Anuja WaghNo ratings yet
- Tuning Database Locks & Latches: Hamid R. MinouiDocument60 pagesTuning Database Locks & Latches: Hamid R. MinouiSrikanth LingalaNo ratings yet
- Case Study - Online Assessment System (OAS)Document10 pagesCase Study - Online Assessment System (OAS)SurabhiNo ratings yet
- SAP S4HANA 1809 Release Information NoteDocument12 pagesSAP S4HANA 1809 Release Information NoteRodrigoPepelascovNo ratings yet