Download as pdf or txt
You might also like
- EVERGREEN CASE - Transport & Insurance in Foreign TradeDocument16 pagesEVERGREEN CASE - Transport & Insurance in Foreign TradePhương Trâm HuỳnhNo ratings yet
- DragonFace EnglishDocument26 pagesDragonFace EnglishAngel Diaz0% (1)
- Passking: Reliable Test Question & New Testking PDF & Wonderful Pass ScoreDocument27 pagesPassking: Reliable Test Question & New Testking PDF & Wonderful Pass ScoreSasha UlizkoNo ratings yet
- Topic 4 Notes Sample DesignDocument4 pagesTopic 4 Notes Sample DesignSimon ChegeNo ratings yet
- Sampling in ResearchDocument5 pagesSampling in ResearchSimon ChegeNo ratings yet
- Chapter Four Sampling Design and ProcedureDocument27 pagesChapter Four Sampling Design and ProceduredemilieNo ratings yet
- Chapter 4 FourDocument32 pagesChapter 4 Fouramiiradem33No ratings yet
- Sampling Design - Group ThreeDocument38 pagesSampling Design - Group ThreeWasihunNo ratings yet
- Chapter III - Sampling For ResearchDocument24 pagesChapter III - Sampling For ResearchSrinadh NaikNo ratings yet
- Chapter 5 - Census and Sample SurveyDocument32 pagesChapter 5 - Census and Sample SurveySolomon EstifanosNo ratings yet
- 9Document54 pages9lloydsemolavaNo ratings yet
- CH 5 SamplingDocument5 pagesCH 5 SamplingAsaminow GirmaNo ratings yet
- Research 8 - SamplingDocument13 pagesResearch 8 - SamplingMatthew MazivanhangaNo ratings yet
- Chapter 4 Sampling DesignDocument34 pagesChapter 4 Sampling DesignYasinNo ratings yet
- Sampling Design and Techniques For Quantitative and Qualitative Study Lesson Reqular ClassDocument88 pagesSampling Design and Techniques For Quantitative and Qualitative Study Lesson Reqular ClassAnsah-Rights KingsleyNo ratings yet
- BR Chapter 6 - Sample Design and Sampling ProcedureDocument18 pagesBR Chapter 6 - Sample Design and Sampling ProcedureAsif Islam SamannoyNo ratings yet
- Reserach Methodology 3 and 4Document23 pagesReserach Methodology 3 and 4samalselmy83No ratings yet
- The Difference Between Sampling in Quantitative and Qualitative ResearchDocument8 pagesThe Difference Between Sampling in Quantitative and Qualitative ResearchVilayat AliNo ratings yet
- Chapter - 4 2015Document33 pagesChapter - 4 2015Yona TsegayeNo ratings yet
- SamplingDocument3 pagesSamplingPankaj2cNo ratings yet
- Research Ch4Document25 pagesResearch Ch4Bantamkak FikaduNo ratings yet
- CH - 6 Sampling Design and ProcedureDocument7 pagesCH - 6 Sampling Design and ProcedureAbdirahmanNo ratings yet
- Sample Survey PracticeDocument89 pagesSample Survey PracticekedirNo ratings yet
- Research CH 4Document27 pagesResearch CH 4Ebsa AbdiNo ratings yet
- LECTURE NOTES (Sampling For Research)Document3 pagesLECTURE NOTES (Sampling For Research)engr.emmancristoNo ratings yet
- Sampling TechniquesDocument15 pagesSampling TechniquesEqaza JavedNo ratings yet
- BRM Unit-2Document17 pagesBRM Unit-2PunithNo ratings yet
- Bus Research Chapter SixDocument10 pagesBus Research Chapter Sixhaymanot gizachewNo ratings yet
- Unit 4. Sampling DesignDocument49 pagesUnit 4. Sampling Designtebebe solomonNo ratings yet
- Hand Outs Lesson 16 Pr2Document5 pagesHand Outs Lesson 16 Pr2Kristina CassandraNo ratings yet
- Chapter Five Sampling Design: InfiniteDocument8 pagesChapter Five Sampling Design: InfiniteAhmed HonestNo ratings yet
- Chapter 3.2-Sampling & Sampling DesignDocument34 pagesChapter 3.2-Sampling & Sampling DesignStivanos HabtamuNo ratings yet
- Assignment: Probability Sampling DesignDocument7 pagesAssignment: Probability Sampling Designsejal chowhanNo ratings yet
- Stat II Chapter 1 and 2Document31 pagesStat II Chapter 1 and 2habtamubiniam897No ratings yet
- 1.1.1. Meaning and Definition of Sampling DesignDocument22 pages1.1.1. Meaning and Definition of Sampling Designazam49No ratings yet
- Samplin G Design: Presented By:-Siddharth KishanDocument43 pagesSamplin G Design: Presented By:-Siddharth KishanSiddharth KishanNo ratings yet
- Chapter 1: Sampling and Sampling DistributionDocument36 pagesChapter 1: Sampling and Sampling Distributionnasriibraahim507No ratings yet
- Sampling Fundamentals ModifiedDocument48 pagesSampling Fundamentals ModifiedAniket PuriNo ratings yet
- Sample Design and Sampling Procedure: Lesson PlanDocument17 pagesSample Design and Sampling Procedure: Lesson Planmk mayen kurishyNo ratings yet
- ZOO-3204 - A-06. Sampling Design[1]Document4 pagesZOO-3204 - A-06. Sampling Design[1]online3275No ratings yet
- BRM Unit 3Document42 pagesBRM Unit 3prem nathNo ratings yet
- Chapter 4 AssignmentDocument5 pagesChapter 4 AssignmentMohitur Rahman ZidanNo ratings yet
- Chapter ThreeeDocument15 pagesChapter ThreeeTadele BekeleNo ratings yet
- Sample Design AND ProcedureDocument68 pagesSample Design AND ProcedurefekadeNo ratings yet
- IntnetDocument82 pagesIntnetSamuelErmiyasNo ratings yet
- Chapter 6 SamplingDocument5 pagesChapter 6 SamplingAsaminow GirmaNo ratings yet
- Chapter Six Sample Design and Procedure: 6.1 Some Fundamental ConceptsDocument10 pagesChapter Six Sample Design and Procedure: 6.1 Some Fundamental ConceptsKalkidan TerefeNo ratings yet
- Marketing Research CH-4Document7 pagesMarketing Research CH-4tsegayegezu25No ratings yet
- Population and SamplingDocument10 pagesPopulation and SamplingDeborah PatrickNo ratings yet
- ResearchDocument4 pagesResearchKriza EstocadoNo ratings yet
- Module 9-Sampling DesignDocument7 pagesModule 9-Sampling DesignJayashree ChakrapaniNo ratings yet
- Lesson 3 - SamplingDocument32 pagesLesson 3 - SamplingrelebohilemochesaneNo ratings yet
- Introduction To Sampling TechniquesDocument9 pagesIntroduction To Sampling TechniquesMingma TamangNo ratings yet
- Research MethodologyDocument18 pagesResearch MethodologySaidu TanimuNo ratings yet
- Topic 3Document5 pagesTopic 3Lugalia KelvinNo ratings yet
- Sampling in ResearchDocument9 pagesSampling in ResearchDn Aju PhilipNo ratings yet
- Research MethodologyDocument23 pagesResearch MethodologyArshad ShaikhNo ratings yet
- SamplingDocument4 pagesSamplingJasmin EismaNo ratings yet
- Sampling DesignDocument30 pagesSampling DesignKathakali ChatterjeeNo ratings yet
- Chapter 5 Sampling MethodsDocument20 pagesChapter 5 Sampling MethodsanuragroyNo ratings yet
- SamplingDocument33 pagesSamplingsakshichitkaraNo ratings yet
- CH 7Document11 pagesCH 7fernfern dungoNo ratings yet
- Research Methods and Methods in Context Revision Notes for AS Level and A Level Sociology, AQA FocusFrom EverandResearch Methods and Methods in Context Revision Notes for AS Level and A Level Sociology, AQA FocusNo ratings yet
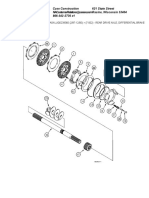
- 621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1Document3 pages621 State Street Case Construction Racine, Wisconsin 53404 866-542-2736 x1JESUSNo ratings yet
- Final Ward Secretariat DataDocument30 pagesFinal Ward Secretariat DataVS NaiduNo ratings yet
- Guaphan DM Syrup Patient Information LeafletDocument1 pageGuaphan DM Syrup Patient Information Leafletpharmacia1.comNo ratings yet
- Abbattitore Di Temperatura Mod. BE-R101 - UKDocument3 pagesAbbattitore Di Temperatura Mod. BE-R101 - UKConrado TangariNo ratings yet
- Urmet UVS Client: H.264 4CH/ 8 CH/ 16 CH DVR H.264 4CH/ 8 CH/ 16 CH/32CH NVRDocument44 pagesUrmet UVS Client: H.264 4CH/ 8 CH/ 16 CH DVR H.264 4CH/ 8 CH/ 16 CH/32CH NVRmahmudNo ratings yet
- Hooke Jeeves Method - 15Document11 pagesHooke Jeeves Method - 15Kelly SantosNo ratings yet
- Auto Confirmation of Coverage - Ahmad HleihelDocument2 pagesAuto Confirmation of Coverage - Ahmad Hleiheladamsjennifer734No ratings yet
- Interview Assessment FormDocument3 pagesInterview Assessment FormCristina BocanialaNo ratings yet
- Your Evaluation License Details.: Features (/features/) Products Case Studies Support CompanyDocument4 pagesYour Evaluation License Details.: Features (/features/) Products Case Studies Support CompanyebortolinNo ratings yet
- ReflectionDocument1 pageReflectionThess Tecla Zerauc Azodnem100% (1)
- PRV Catlogue-Samson (09!06!09)Document6 pagesPRV Catlogue-Samson (09!06!09)pkrishna984No ratings yet
- Nar Ont 1 GbpsDocument49 pagesNar Ont 1 GbpsCatalin StoicescuNo ratings yet
- Crop and Soil MonitoringDocument2 pagesCrop and Soil Monitoringمريم منيرNo ratings yet
- Hazard-Database Mining BAGUS SEKALIDocument1,156 pagesHazard-Database Mining BAGUS SEKALIherikNo ratings yet
- Introduction of NIKEDocument6 pagesIntroduction of NIKEShashank Gupta100% (1)
- DS-7104/08/16HWI-SH (-SL) : 960H Mini DVRDocument1 pageDS-7104/08/16HWI-SH (-SL) : 960H Mini DVRchorizo chorizanteNo ratings yet
- C006a JDocument44 pagesC006a JVignesh WaranNo ratings yet
- Technical Presentation: Fabricpool in Ontap 9.12.1Document151 pagesTechnical Presentation: Fabricpool in Ontap 9.12.1Venkat ChowdaryNo ratings yet
- Programme Club Inde 201113Document1 pageProgramme Club Inde 201113benteppeNo ratings yet
- PRESENTATION: Financial Sustainability of Reforms by Hiddo HuitzingDocument11 pagesPRESENTATION: Financial Sustainability of Reforms by Hiddo HuitzingADB Health Sector GroupNo ratings yet
- Ktisis Floor Coatings BrochureDocument8 pagesKtisis Floor Coatings Brochureakis5375No ratings yet
- Overleaf Keyboard ShortcutsDocument2 pagesOverleaf Keyboard ShortcutsJBBARNo ratings yet
- Intrusion Detection SystemDocument36 pagesIntrusion Detection SystemNand LalNo ratings yet
- Margo Smolyanska PortfolioDocument31 pagesMargo Smolyanska PortfolioMargo McAwesomeNo ratings yet
- Radar Enginnering (Solved FTerm) 18 2 2021 PDFDocument10 pagesRadar Enginnering (Solved FTerm) 18 2 2021 PDFAhmed ZakiNo ratings yet
- Dilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Document309 pagesDilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Leandro de Queiroz100% (3)
- Mazen Salem Baabdullah: Sales Director - Business Development ManagementDocument2 pagesMazen Salem Baabdullah: Sales Director - Business Development ManagementmazNo ratings yet







































![ZOO-3204 - A-06. Sampling Design[1]](https://imgv2-2-f.scribdassets.com/img/document/747306949/149x198/1e4c28143f/1719930791?v=1)