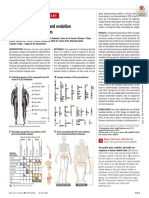
Download as pdf or txt
You might also like
- Lecture 5 Economics & Genetics 2023 - CompleteDocument44 pagesLecture 5 Economics & Genetics 2023 - CompletePobieraczNapisowNo ratings yet
- Lecture 1 Economics & Genetics 2023 - CompleteDocument40 pagesLecture 1 Economics & Genetics 2023 - CompletePobieraczNapisowNo ratings yet
- Lecture 4 Economics & Genetics 2023 - CompleteDocument64 pagesLecture 4 Economics & Genetics 2023 - CompletePobieraczNapisowNo ratings yet
- Estimation of Heritability From Limited Family Data Using Genome-Wide Identity-By-Descent SharingDocument10 pagesEstimation of Heritability From Limited Family Data Using Genome-Wide Identity-By-Descent SharingCarlos PulgarinNo ratings yet
- Brainsci 06 00064Document17 pagesBrainsci 06 00064PSPD-Sany RosafiNo ratings yet
- Mathematica Applicanda TemplateDocument8 pagesMathematica Applicanda TemplateFresh Prince Of NigeriaNo ratings yet
- What Is A Genome Wide Association Study?Document11 pagesWhat Is A Genome Wide Association Study?caritopaezNo ratings yet
- GWASDocument49 pagesGWASRafaelAndresOspinoNo ratings yet
- Power G Was InteractionDocument7 pagesPower G Was InteractionEsther HerreraNo ratings yet
- Q1a - Research - Methods (1) For Psychology IB ExamDocument6 pagesQ1a - Research - Methods (1) For Psychology IB Examudayanrawal31No ratings yet
- Units 3 - 5Document70 pagesUnits 3 - 5Fekadu GadissaNo ratings yet
- Quantitative GeneticsDocument87 pagesQuantitative Geneticsren duttNo ratings yet
- Behavioral Genetics 7th Edition Knopik Test BankDocument5 pagesBehavioral Genetics 7th Edition Knopik Test Bankdorothydoij03k100% (32)
- Behavioral Genetics 7Th Edition Knopik Test Bank Full Chapter PDFDocument26 pagesBehavioral Genetics 7Th Edition Knopik Test Bank Full Chapter PDFrowenagabrieleatq100% (15)
- Download Behavioral Genetics 7th Edition Knopik Test Bank all chaptersDocument28 pagesDownload Behavioral Genetics 7th Edition Knopik Test Bank all chapterskvirinobrade100% (8)
- Full Behavioral Genetics 7Th Edition Knopik Test Bank Online PDF All ChapterDocument28 pagesFull Behavioral Genetics 7Th Edition Knopik Test Bank Online PDF All Chaptergdetnaedmine691100% (8)
- 7a. Concept of HeritabilityDocument12 pages7a. Concept of HeritabilityNishant ShahNo ratings yet
- 20151113141104T Test Lecture 9Document33 pages20151113141104T Test Lecture 9thinagaranNo ratings yet
- Bioe 211 - Epidemiologic StudiesDocument5 pagesBioe 211 - Epidemiologic Studiesbabalegaspi09No ratings yet
- Comparison of Two GroupsDocument41 pagesComparison of Two GroupsSergioDragomiroff100% (1)
- DS-2, Week 4 - LecturesDocument4 pagesDS-2, Week 4 - LecturesPrerana VarshneyNo ratings yet
- Stat Methods 2Document31 pagesStat Methods 2Edilyn Dimapilis-ChiaoNo ratings yet
- Clustering Gene Expression Data: CS 838 WWW - Cs.wisc - Edu/ Craven/cs838.html Mark Craven Craven@biostat - Wisc.edu April 2001Document9 pagesClustering Gene Expression Data: CS 838 WWW - Cs.wisc - Edu/ Craven/cs838.html Mark Craven Craven@biostat - Wisc.edu April 2001Fadhili DungaNo ratings yet
- Variation AnswersDocument2 pagesVariation AnswersCally ChewNo ratings yet
- Paper 1Document5 pagesPaper 1tiktokarmy13No ratings yet
- 10 1002@sici1096-86281996051763@2386@@aid-Ajmg123 0 Co2-GDocument6 pages10 1002@sici1096-86281996051763@2386@@aid-Ajmg123 0 Co2-GRahul AmbawataNo ratings yet
- Researchmethodslecture 2015Document25 pagesResearchmethodslecture 2015api-300762638No ratings yet
- WK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadDocument12 pagesWK 11-Session 11 Notes-Hypothesis Testing (Two Samples) - UploadLIAW ANN YINo ratings yet
- C8511 BSC First Year Examination 2012 Research Skills in PsychologyDocument22 pagesC8511 BSC First Year Examination 2012 Research Skills in PsychologyShyamala ArumugamNo ratings yet
- Disease SubtypingDocument19 pagesDisease Subtypingspaul4uNo ratings yet
- 1 s2.0 S0002929707609884 MainDocument12 pages1 s2.0 S0002929707609884 MainDestinNo ratings yet
- Chapter 15Document27 pagesChapter 15PNo ratings yet
- Hoekstra 2007Document6 pagesHoekstra 2007Matúš KrupaNo ratings yet
- YangJian2011 GCTADocument7 pagesYangJian2011 GCTAMuhammad KamranNo ratings yet
- Lecture 2 Economics & Genetics 2023 - CompleteDocument46 pagesLecture 2 Economics & Genetics 2023 - CompletePobieraczNapisowNo ratings yet
- Lecture 06 Estimation of Differences of MeansDocument50 pagesLecture 06 Estimation of Differences of Meanssxya.community.hkNo ratings yet
- Ecological Statistics Review: Sampling StrategiesDocument14 pagesEcological Statistics Review: Sampling StrategiesMATHIXNo ratings yet
- Quantitative GeneticsDocument34 pagesQuantitative GeneticsSouraj DasNo ratings yet
- Chapter 19 Main TopicsDocument6 pagesChapter 19 Main TopicsAnusha IllukkumburaNo ratings yet
- Davis 2018Document8 pagesDavis 2018spaciugNo ratings yet
- Bio Factsheet: The Paired T-Test & When To Use ItDocument3 pagesBio Factsheet: The Paired T-Test & When To Use ItjayNo ratings yet
- Introduction To Evolutionary Computation: Algorithms Inspired From Darwin'S Theory of EvolutionDocument23 pagesIntroduction To Evolutionary Computation: Algorithms Inspired From Darwin'S Theory of EvolutionArnab RoyNo ratings yet
- Variance in Neurocognitive Performance Is Associated With Dysbindin-1 in Schizophrenia: A Preliminary StudyDocument5 pagesVariance in Neurocognitive Performance Is Associated With Dysbindin-1 in Schizophrenia: A Preliminary Studyfajar tampubolonNo ratings yet
- Genetics: Warm UpDocument48 pagesGenetics: Warm UpIzabellaNo ratings yet
- 2018 RDR YoungDocument12 pages2018 RDR Young6k7m8vfjm8No ratings yet
- 6 - Correlational ResearchDocument17 pages6 - Correlational ResearchSerra ÇevikkanNo ratings yet
- Genomewide Scan of Hoarding in Sib Pairs in Which Both Sibs Have Gilles de La Tourette SyndromeDocument9 pagesGenomewide Scan of Hoarding in Sib Pairs in Which Both Sibs Have Gilles de La Tourette SyndromeCita Tri KusumaNo ratings yet
- Stroop 2017Document17 pagesStroop 2017Lynne Ivy IllagaNo ratings yet
- 1998 - Measuring Individual Differences in Implicit Cognition, The Implicit Association TestDocument17 pages1998 - Measuring Individual Differences in Implicit Cognition, The Implicit Association TestMonica Sarai Ramirez AvilaNo ratings yet
- SMOGD User Manual Vsn2.6Document5 pagesSMOGD User Manual Vsn2.6Jaqueline Figuerêdo RosaNo ratings yet
- 2024-Lecture 09Document29 pages2024-Lecture 09Nguyễn TâmNo ratings yet
- Genes: Biological ApproachDocument35 pagesGenes: Biological ApproachEroni PuamauNo ratings yet
- Independent T Test & Paired T Test 2023Document58 pagesIndependent T Test & Paired T Test 2023wan nur adnin wan ghazaliNo ratings yet
- Measuring Individual Differences in Implicit Cognition: The Implicit Association TestDocument17 pagesMeasuring Individual Differences in Implicit Cognition: The Implicit Association TestAlba ArmeroNo ratings yet
- Confounding and Interaction III 2022Document91 pagesConfounding and Interaction III 2022kokozawNo ratings yet
- Random Forest: Prediction of Genetic Susceptibility To Complex DiseasesDocument7 pagesRandom Forest: Prediction of Genetic Susceptibility To Complex DiseasesAbid AnjumNo ratings yet
- Sample Size Formulas and ExamplesDocument26 pagesSample Size Formulas and Examplesinaw76164No ratings yet
- The Disgust Scale R A Valid and Reliable Index T - 2011 - Personality and IndivDocument6 pagesThe Disgust Scale R A Valid and Reliable Index T - 2011 - Personality and IndivTorburam LhamNo ratings yet
- Genetics Brain Teasers: Explore your Understadning of Genes, DNA, RNA, mRNA, Chromosomes, Mutation, Heredity, Evolution, and more!From EverandGenetics Brain Teasers: Explore your Understadning of Genes, DNA, RNA, mRNA, Chromosomes, Mutation, Heredity, Evolution, and more!No ratings yet
- Science - Adf8009 Genetic ArchitectureDocument13 pagesScience - Adf8009 Genetic ArchitectureHua Hidari YangNo ratings yet
- Synopsis Genetic Evaluation of Teddy Goats in PakistanDocument42 pagesSynopsis Genetic Evaluation of Teddy Goats in PakistanZulfiqar Hussan KuthuNo ratings yet
- Methods of SelectionDocument13 pagesMethods of SelectionAyushi YadavNo ratings yet
- Breeding ProgramDocument13 pagesBreeding ProgramgabNo ratings yet
- Intelligence Genes and Genomics Plomin 2004Document18 pagesIntelligence Genes and Genomics Plomin 2004ushaasrNo ratings yet
- Cow Weight in A Closed Brahman HerdDocument4 pagesCow Weight in A Closed Brahman HerdKattie ValerioNo ratings yet
- Phenotypic and Genetic Correlations Between Body Weight and Linear Body Measurements of Nigerian Local and Improved ChickensDocument4 pagesPhenotypic and Genetic Correlations Between Body Weight and Linear Body Measurements of Nigerian Local and Improved ChickensInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Chapter 18: Quantitative Genetics I - Important ConceptsDocument41 pagesChapter 18: Quantitative Genetics I - Important ConceptsRuxandra BerdeNo ratings yet
- Hans J. Eysenck and Raymond B. Cattell On Intelligence and PersonalityDocument9 pagesHans J. Eysenck and Raymond B. Cattell On Intelligence and PersonalityValentina Băcanu100% (1)
- Primer: Genome-Wide Association StudiesDocument21 pagesPrimer: Genome-Wide Association Studiesrommell AlvaradoNo ratings yet
- Pnas 2114271119Document11 pagesPnas 2114271119WolandNo ratings yet
- NEW REVISED - Supplementary File 5 - Tutorial MCMCGLMMDocument22 pagesNEW REVISED - Supplementary File 5 - Tutorial MCMCGLMMMegan KennedyNo ratings yet
- Genetic CorrelationDocument15 pagesGenetic Correlationisabella343No ratings yet
- A Scale Dependent Framework For Trade Offs, Syndromes, and Specialization in Organismal BiologyDocument25 pagesA Scale Dependent Framework For Trade Offs, Syndromes, and Specialization in Organismal BiologyDavid CultureNo ratings yet
- How Genes Influence Behaviour 2nd Edition 2020 OxfDocument2 pagesHow Genes Influence Behaviour 2nd Edition 2020 OxfPatrícia VieiraNo ratings yet
- Review Jurnal IlmulDocument9 pagesReview Jurnal IlmulFarhan DwitamaaaNo ratings yet
- Ajas 25 6 764 3Document8 pagesAjas 25 6 764 3Sheikh FirdousNo ratings yet
- Astaxanthin SalmonDocument19 pagesAstaxanthin SalmonIsworo RukmiNo ratings yet
- Iig2015 Solar Eclipse-2Document48 pagesIig2015 Solar Eclipse-2api-281558303No ratings yet
- Predicting The Future of Plant Breeding: Complementing Empirical Evaluation With Genetic PredictionDocument26 pagesPredicting The Future of Plant Breeding: Complementing Empirical Evaluation With Genetic Predictioncata2099No ratings yet
- The Genetics of Genius PDFDocument20 pagesThe Genetics of Genius PDFVisesh100% (1)
- Serbia in The Implementation of Seurop Standard For Beef Carcass Clasiffication: Legislation, Parametars and Evaluation Criteria (Part A) .Document152 pagesSerbia in The Implementation of Seurop Standard For Beef Carcass Clasiffication: Legislation, Parametars and Evaluation Criteria (Part A) .Dušica Ostojić AndrićNo ratings yet
- Response To SelectionDocument15 pagesResponse To SelectionAyushi YadavNo ratings yet
- Genetic Parameter and Genetic Trend Estimates For Reproductive Traits of Jersey Breed in Ethiopian Highland EnvironmentDocument7 pagesGenetic Parameter and Genetic Trend Estimates For Reproductive Traits of Jersey Breed in Ethiopian Highland EnvironmentKefale GetahunNo ratings yet
- Quantitative MethodsDocument39 pagesQuantitative MethodsThamil ArasanNo ratings yet
- Pleiotropy in Complex Traits: Challenges and StrategiesDocument13 pagesPleiotropy in Complex Traits: Challenges and Strategiesthe invincibleNo ratings yet
- Eynseck PersonalityDocument41 pagesEynseck PersonalityAdam ZiyyadNo ratings yet
- Prediction of Meat Quality in Bali Cattle Using Ultrasound ImagingDocument8 pagesPrediction of Meat Quality in Bali Cattle Using Ultrasound ImagingFitra Aji PamungkasNo ratings yet
- GEMMA User Manual: Xiang Zhou January 12, 2014Document27 pagesGEMMA User Manual: Xiang Zhou January 12, 2014pranjan77No ratings yet
- Reproductive Potential of Rabbit Bucks oDocument256 pagesReproductive Potential of Rabbit Bucks olwebuga mikeNo ratings yet