Download as pdf or txt
You might also like
- Scale SkillsDocument35 pagesScale Skillspengwang728100% (1)
- Elephant Love MedleyDocument4 pagesElephant Love MedleyDanielDuarteNo ratings yet
- Chords With Color: Making Normal Chords More ColorfulDocument14 pagesChords With Color: Making Normal Chords More ColorfulMario MendozaNo ratings yet
- Jazz Chord Progression PDFDocument4 pagesJazz Chord Progression PDFMusic0% (1)
- Prepare Vegetable and Seafood DishesDocument120 pagesPrepare Vegetable and Seafood DishesJoeven Pantaleon67% (3)
- H1 Visa Interview Sample Questions and AnswersDocument5 pagesH1 Visa Interview Sample Questions and AnswersNoore Alam SarkarNo ratings yet
- (SI) Compiler Lecture 5Document21 pages(SI) Compiler Lecture 5Mahfuzur RahmanNo ratings yet
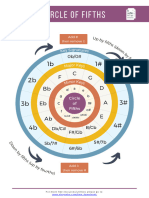
- Circle of Keys TREBLE CLEFDocument1 pageCircle of Keys TREBLE CLEFJairo MezaNo ratings yet
- Partituradebanda - Band Folio - Book 2 - Sax TenorDocument25 pagesPartituradebanda - Band Folio - Book 2 - Sax TenorDennis FernandesNo ratings yet
- Lexi CalDocument38 pagesLexi CalPRATIKSH KUMARNo ratings yet
- Four Note String Set #5Document4 pagesFour Note String Set #5drewdrew525No ratings yet
- Unit 1 RE DFA DirectDocument34 pagesUnit 1 RE DFA DirectRitesh SuryawanshiNo ratings yet
- Circle of Fifths Practice No. 1Document3 pagesCircle of Fifths Practice No. 1lusifer kpNo ratings yet
- Cycle of 5thsDocument1 pageCycle of 5thsJoe HarrisNo ratings yet
- c2 2 PDFDocument28 pagesc2 2 PDFHI itsmeabiNo ratings yet
- Introduction To The Nashville Numbering System: Page 1 of 4Document4 pagesIntroduction To The Nashville Numbering System: Page 1 of 4Сергей КрасногородскийNo ratings yet
- Partituradebanda - Band Folio - Book 2 - SX BaritonoDocument25 pagesPartituradebanda - Band Folio - Book 2 - SX BaritonoDennis FernandesNo ratings yet
- Dfa 1Document23 pagesDfa 1api-3828940No ratings yet
- MAP READING - Activity in PE 9 - Q4Document4 pagesMAP READING - Activity in PE 9 - Q4Pedro GenosasNo ratings yet
- Compiler: by Noor Wali Khan UochDocument11 pagesCompiler: by Noor Wali Khan UochAbdul MateenNo ratings yet
- Y4 Co-Ordinates TuesdayDocument5 pagesY4 Co-Ordinates TuesdaykwamboeddyNo ratings yet
- Questions - Homework - 9th - Maths - 2024-02-19T0633Document7 pagesQuestions - Homework - 9th - Maths - 2024-02-19T0633Priya PankajNo ratings yet
- Al To Trombone PositionDocument2 pagesAl To Trombone PositionGa AdNo ratings yet
- Coordinates ExtraDocument4 pagesCoordinates ExtraMr Matthew BAKERNo ratings yet
- 3 - Lecture 07Document70 pages3 - Lecture 07Akarsh KusumanchiNo ratings yet
- Baulkham Hills 2012 2U Prelim Yearly & SolutionsDocument11 pagesBaulkham Hills 2012 2U Prelim Yearly & SolutionsYe ZhangNo ratings yet
- c37To0-Written Theory ExamDocument5 pagesc37To0-Written Theory ExamJessica SanzNo ratings yet
- Slidechart 03 PDFDocument1 pageSlidechart 03 PDFAndrewNo ratings yet
- Circle of FifthsDocument1 pageCircle of Fifthsncase_roNo ratings yet
- Ejercicio de Clase 11 - 10Document3 pagesEjercicio de Clase 11 - 10pajaro numero dosNo ratings yet
- Fpga Based System Design: Introduction To FpgasDocument73 pagesFpga Based System Design: Introduction To FpgasMoayid AldeebNo ratings yet
- Compression: Safeen H. Rasool Assist. LecturerDocument27 pagesCompression: Safeen H. Rasool Assist. Lecturerasmahan abdulwahidNo ratings yet
- Regular Expression & AutometaDocument62 pagesRegular Expression & AutometaJYOTI SAXENANo ratings yet
- Ghost - Respite On The Spitalfields Guitar SoloDocument2 pagesGhost - Respite On The Spitalfields Guitar Soloraphael aguerrecheNo ratings yet
- Translation Coordinates Graph 1Document2 pagesTranslation Coordinates Graph 1milkiasbelay131No ratings yet
- Barre Chord ChartDocument1 pageBarre Chord ChartorlandoNo ratings yet
- Barre Chord ChartDocument1 pageBarre Chord ChartorlandoNo ratings yet
- SolfegietoDocument3 pagesSolfegietoAndreea SavanciucNo ratings yet
- Mrs Robinson Part G1Document1 pageMrs Robinson Part G1BeaucourtNo ratings yet
- Compiler: Noor Wali Khan UochDocument12 pagesCompiler: Noor Wali Khan UochAbdul MateenNo ratings yet
- CSI 409: DFA Design Problems Some Answers and HintsDocument3 pagesCSI 409: DFA Design Problems Some Answers and HintsFaizan RaheemNo ratings yet
- 1 Chords and ChartsDocument38 pages1 Chords and ChartslightbulbdanceNo ratings yet
- On Air - B1-Test Pack-KeyDocument4 pagesOn Air - B1-Test Pack-KeyIsabel VieiraNo ratings yet
- Scale Degrees Handout 1Document1 pageScale Degrees Handout 1pkeadsNo ratings yet
- Más II-V-IDocument15 pagesMás II-V-Igabriel4castellano100% (1)
- Key SignaturesDocument38 pagesKey SignaturesFroilan TinduganNo ratings yet
- Escales FàcilsDocument2 pagesEscales FàcilsIvan OVNo ratings yet
- Circle of ThirdsDocument1 pageCircle of ThirdsramirezzunigaNo ratings yet
- Class-Practice-Plus 4B06 Exp ExtractedDocument9 pagesClass-Practice-Plus 4B06 Exp ExtractedRaistlin ChanNo ratings yet
- Guitar (Dadgad) Chords E6thDocument2 pagesGuitar (Dadgad) Chords E6thAndre Oliveira MendonçaNo ratings yet
- Bach - Menuet in BB YeniDocument2 pagesBach - Menuet in BB YeniPascal NoumaNo ratings yet
- OTM Set Relation Function Dec 23Document10 pagesOTM Set Relation Function Dec 23rajmhatre346No ratings yet
- Retaining Wall of Map PH - I SiteDocument15 pagesRetaining Wall of Map PH - I SiteM ShahidNo ratings yet
- Q&A 7.6 Base Plates With Bolts Outside The Column FlangeDocument1 pageQ&A 7.6 Base Plates With Bolts Outside The Column FlangeNimeshkumar PatelNo ratings yet
- Seeing Major Key Scales & Chords With Circle of Fifths MAJOR KEY SCALES ANSWER KEYDocument1 pageSeeing Major Key Scales & Chords With Circle of Fifths MAJOR KEY SCALES ANSWER KEYAmeer Marco LawanNo ratings yet
- (악보) Tears In HeavenDocument6 pages(악보) Tears In HeavenHyunsoo JoNo ratings yet
- Jiyuu No TsubasaDocument58 pagesJiyuu No TsubasaIgor AraújoNo ratings yet
- Europe - Prisoners in Paradise Guitar SoloDocument5 pagesEurope - Prisoners in Paradise Guitar SolojulianbreNo ratings yet
- 2018 WrittenDocument24 pages2018 Writtenex.g7c.habiba.adelNo ratings yet
- Monthly-Habit-Tracker MarchDocument1 pageMonthly-Habit-Tracker MarchLakad ChowdhuryNo ratings yet
- Workout PlanDocument2 pagesWorkout PlanLakad ChowdhuryNo ratings yet
- Annex - Bubt.edu - BD Global File Routine - PHP P 006&SemNo 608,062&print TrueDocument78 pagesAnnex - Bubt.edu - BD Global File Routine - PHP P 006&SemNo 608,062&print TrueLakad ChowdhuryNo ratings yet
- Monthly-Habit-Tracker MarchDocument2 pagesMonthly-Habit-Tracker MarchLakad ChowdhuryNo ratings yet
- DLD Project 1Document22 pagesDLD Project 1Lakad ChowdhuryNo ratings yet
- Innovation in Computational Architecture and DesigDocument14 pagesInnovation in Computational Architecture and DesigLakad ChowdhuryNo ratings yet
- 08Document1 page08Lakad ChowdhuryNo ratings yet
- Hand NoteDocument40 pagesHand NoteLakad ChowdhuryNo ratings yet
- Elastic Energy Proportional Edge Computing Infrastructure Solution Brief 793758v1Document13 pagesElastic Energy Proportional Edge Computing Infrastructure Solution Brief 793758v1Lakad ChowdhuryNo ratings yet
- Senzori de CurgereDocument128 pagesSenzori de CurgerebuturcasNo ratings yet
- 1SS133Document2 pages1SS133Nam TàoNo ratings yet
- Sunita S BettakusugalDocument4 pagesSunita S Bettakusugalfexmy indiaNo ratings yet
- Canadian Importers Lists - Coconut OilDocument4 pagesCanadian Importers Lists - Coconut OilIndo Coconut PremiumNo ratings yet
- Efficient Approach For ISL Using MLDocument4 pagesEfficient Approach For ISL Using MLsugar cubeNo ratings yet
- DR SW Config Matrix - 6K0323 - January 2016Document62 pagesDR SW Config Matrix - 6K0323 - January 2016Mastin SneadNo ratings yet
- Adce Parameter of 2gDocument4 pagesAdce Parameter of 2gAmit DevNo ratings yet
- Ficha Técnica Cable VFD Trex-OnicsDocument1 pageFicha Técnica Cable VFD Trex-OnicsMario Alonso Ruiz CherresNo ratings yet
- Cloze Test PowerPointDocument14 pagesCloze Test PowerPointsetdangNo ratings yet
- JR - English Practice - Qps.apDocument20 pagesJR - English Practice - Qps.apnsmviiif08chakravarthyygsNo ratings yet
- Ibs Company ProfileDocument52 pagesIbs Company ProfileFaeez ZainNo ratings yet
- Coke - Ethical Issues: The RecallDocument7 pagesCoke - Ethical Issues: The RecallPriya JainNo ratings yet
- PDFDocument111 pagesPDFmohanNo ratings yet
- Electron ConfigurationDocument23 pagesElectron ConfigurationJenny Claire CrusperoNo ratings yet
- Homemade RicottaDocument3 pagesHomemade RicottaJules PaulkNo ratings yet
- Tshangs Dbyangs Gsung MgurDocument135 pagesTshangs Dbyangs Gsung MgurTalbo02No ratings yet
- A System View To Urban Planning: An IntroductionDocument34 pagesA System View To Urban Planning: An IntroductionAzad RazaNo ratings yet
- FrootiDocument5 pagesFrootiRachel MonisNo ratings yet
- Marketing Analysis 1. What Company Did You Choose, and Why?Document4 pagesMarketing Analysis 1. What Company Did You Choose, and Why?Tatiana PosseNo ratings yet
- Change Your Water Change Your Life!Document72 pagesChange Your Water Change Your Life!Jack MekwanNo ratings yet
- Operations Management A Supply Chain Process Approach 1st Edition Wisner Solutions ManualDocument10 pagesOperations Management A Supply Chain Process Approach 1st Edition Wisner Solutions Manualsiccadyeingiyp100% (29)
- 521 Lesson 2Document4 pages521 Lesson 2api-322060627No ratings yet
- Seguridad en Nuestra Vidas SAFESTARTDocument19 pagesSeguridad en Nuestra Vidas SAFESTARTEfrain ZeballosNo ratings yet
- Pros & Cons Impacts of Social MediaDocument2 pagesPros & Cons Impacts of Social MediaWan NursyakirinNo ratings yet
- Nischay Baghel Response CurveDocument21 pagesNischay Baghel Response CurveManish TandanNo ratings yet
- Ej1068743 PDFDocument8 pagesEj1068743 PDFJessa Joy Alano LopezNo ratings yet
- Teamcenter Polarion OSLC Integration 6Document77 pagesTeamcenter Polarion OSLC Integration 6VENKATESHNo ratings yet
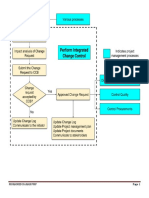
- Perform Integrated Change Control (Step-By-Step)Document4 pagesPerform Integrated Change Control (Step-By-Step)Justin M. FowlkesNo ratings yet