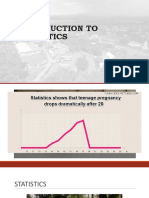
Download as docx, pdf, or txt
You might also like
- Video Manual Treffpukt BerlinDocument166 pagesVideo Manual Treffpukt Berlinclaudyema79% (24)
- CH 3 Measurement and DataDocument42 pagesCH 3 Measurement and DatadashanNo ratings yet
- Why Do You Think Kilronan Castle Hotel in Ireland, Keep The Toy Left by Customers?Document2 pagesWhy Do You Think Kilronan Castle Hotel in Ireland, Keep The Toy Left by Customers?Prettyrush. CoNo ratings yet
- Lesson 1:: Basic Terminologies in StatisticsDocument3 pagesLesson 1:: Basic Terminologies in StatisticsDmzjmb SaadNo ratings yet
- Stat Analysis Module 1Document4 pagesStat Analysis Module 1Joresol AlorroNo ratings yet
- Measurement and Scaling TechniquesDocument16 pagesMeasurement and Scaling Techniquessiva sankariNo ratings yet
- Lesson-6 - Data AnalysisDocument24 pagesLesson-6 - Data AnalysisLloyd PawaonNo ratings yet
- Biostatistics (Introduction)Document66 pagesBiostatistics (Introduction)Dr. Muhammad Bilal SiddiquiNo ratings yet
- Chapter 7Document12 pagesChapter 7fitsebigNo ratings yet
- 9 ResearchDocument15 pages9 ResearchGrace PascualNo ratings yet
- Lecture Guide in Statistics For Biology Property Of: Leo M. Aresgado 2019Document21 pagesLecture Guide in Statistics For Biology Property Of: Leo M. Aresgado 2019Anjelica OtañesNo ratings yet
- Module 3: Principles of Psychological Testing: Central Luzon State UniversityDocument14 pagesModule 3: Principles of Psychological Testing: Central Luzon State UniversityPATRICIA GOLTIAONo ratings yet
- Unit 3 Measurement ScaleDocument59 pagesUnit 3 Measurement ScaleMïçhäêł JãkšîNo ratings yet
- Module 3 - Statistics RefresherDocument16 pagesModule 3 - Statistics RefresherTapia, DarleenNo ratings yet
- BRM Unit 3: Measurement & DataDocument46 pagesBRM Unit 3: Measurement & DataAmol KareNo ratings yet
- Unit 3 BRM PDFDocument6 pagesUnit 3 BRM PDFvarshneypalak0No ratings yet
- Lesson 4 Data Management Mean Median ModeDocument3 pagesLesson 4 Data Management Mean Median ModePaul SuicoNo ratings yet
- Basic Concepts, Methods of Data Collection and PresentationDocument17 pagesBasic Concepts, Methods of Data Collection and PresentationTewodros Alemu LoveNo ratings yet
- Ch13 Zikmund Measurement and ScaleDocument31 pagesCh13 Zikmund Measurement and Scalerohitoberoi1175% (4)
- Module 4 Educ - StatDocument4 pagesModule 4 Educ - StatERICSON SABANGANNo ratings yet
- Module 3. Formulation of ResearchDocument5 pagesModule 3. Formulation of ResearchMarivica DagunaNo ratings yet
- Buss-Math Q2-W3Document6 pagesBuss-Math Q2-W3Erica AmolarNo ratings yet
- Data ManagementDocument56 pagesData ManagementAllen Kurt RamosNo ratings yet
- BBA 4 RM Unit 4Document99 pagesBBA 4 RM Unit 4kambala.yamini25No ratings yet
- Session 1 ISM May 2024Document59 pagesSession 1 ISM May 2024oishika.troisNo ratings yet
- SW1.Introduction To StatisticsDocument5 pagesSW1.Introduction To StatisticsLUIS MARTIN PUNAYNo ratings yet
- 1introduction To Statistics PDFDocument30 pages1introduction To Statistics PDFChelsea Roque100% (1)
- Research Chapter 6Document29 pagesResearch Chapter 6KalkayeNo ratings yet
- D. Hazarika: Module-1 Module-2Document25 pagesD. Hazarika: Module-1 Module-2AKANKSHA PREETINo ratings yet
- 1data Management Mamw 100Document84 pages1data Management Mamw 100Noreen Gaile100% (1)
- G.E. 4 Pre - Final HandooutDocument11 pagesG.E. 4 Pre - Final HandooutGiovani LegnesNo ratings yet
- CM5 - Mathematics As A ToolDocument17 pagesCM5 - Mathematics As A ToolLoeynahcNo ratings yet
- 001 Lecture 1 Introduction S1920Document7 pages001 Lecture 1 Introduction S1920Kisuke UraharaNo ratings yet
- M7-Research MethodologyDocument20 pagesM7-Research MethodologyLarissa Rodrigues GCHSNo ratings yet
- Stat NotesDocument17 pagesStat NotesNami's chrnclsNo ratings yet
- Research Instruments Measurement of Variables Data AnalysisDocument5 pagesResearch Instruments Measurement of Variables Data AnalysisApril OlaliaNo ratings yet
- Chapter 4 - Measurement and StatisticsDocument32 pagesChapter 4 - Measurement and Statisticsalex cabralNo ratings yet
- Data TypesDocument5 pagesData TypesguruvarshniganesapandiNo ratings yet
- Business Statistics: MBBA 501 First Semester, 2021-2022Document39 pagesBusiness Statistics: MBBA 501 First Semester, 2021-2022Maricon DimaunahanNo ratings yet
- 4 Data Analysis1Document32 pages4 Data Analysis1Mohamad AdibNo ratings yet
- Lesson 2: Types of Measurements & Measurement of ScalesDocument4 pagesLesson 2: Types of Measurements & Measurement of ScalesMa'am Ferl GshsNo ratings yet
- Eps 400 New Notes Dec 15-1Document47 pagesEps 400 New Notes Dec 15-1BRIAN MWANGINo ratings yet
- Probability and Statistics: (MATH-361)Document33 pagesProbability and Statistics: (MATH-361)Nihal AhmadNo ratings yet
- HME 108 Quantitative Data AnalysisDocument85 pagesHME 108 Quantitative Data AnalysisPatience TomeNo ratings yet
- Qualitative Data AnalysisDocument52 pagesQualitative Data AnalysisMarielle Dominique De la CruzNo ratings yet
- Module 1 LESSON4 - Variables and HypothesisDocument6 pagesModule 1 LESSON4 - Variables and HypothesisyanzydevezonNo ratings yet
- Chapter 7 Maam KiranDocument51 pagesChapter 7 Maam KiranNeehan FatimaNo ratings yet
- Mathematics As A Tool NewDocument62 pagesMathematics As A Tool NewFaith Daphne Jill MatugasNo ratings yet
- Research Quiz 1Document5 pagesResearch Quiz 1Ellen CatedralNo ratings yet
- Psychological Assessment RationalizationDocument7 pagesPsychological Assessment RationalizationFLORLYN VERALNo ratings yet
- ISM Session 1-8+webinar1,2 MergedDocument718 pagesISM Session 1-8+webinar1,2 Mergedygaurav160599No ratings yet
- M8-Research MethodologyDocument21 pagesM8-Research MethodologyLarissa Rodrigues GCHSNo ratings yet
- Attitude Measurement - MKTG 526Document13 pagesAttitude Measurement - MKTG 526mahiaryaNo ratings yet
- Measurement of Variables and Data TypesDocument26 pagesMeasurement of Variables and Data TypessureshNo ratings yet
- Chapter 3: Organization, Utilization, and Communication of Test ResultsDocument25 pagesChapter 3: Organization, Utilization, and Communication of Test ResultsAlvin manahanNo ratings yet
- Reviewer PR2Document10 pagesReviewer PR2Jhon Laurence DumendengNo ratings yet
- Practical Research 2: Chapter 1: Nature of Inquiry and ResearchDocument4 pagesPractical Research 2: Chapter 1: Nature of Inquiry and ResearchJonwille Mark CastroNo ratings yet
- Group 5 ReportDocument50 pagesGroup 5 Reportkathtolentino.55No ratings yet
- MMW Reviewer Data ManagementDocument17 pagesMMW Reviewer Data ManagementgwenayatsNo ratings yet
- Course Introduction Inferential Statistics Prof. Sandy A. LerioDocument46 pagesCourse Introduction Inferential Statistics Prof. Sandy A. LerioKnotsNautischeMeilenproStundeNo ratings yet
- MATH 2207 - Basics of StatisticsDocument21 pagesMATH 2207 - Basics of StatisticsNiaz KhanNo ratings yet
- Fall 2015 Supplementary Course Outline Addendum - Section BBDocument7 pagesFall 2015 Supplementary Course Outline Addendum - Section BBdvrkNo ratings yet
- Day Urban Camp OfficerUserManualDocument12 pagesDay Urban Camp OfficerUserManualSatish JhaNo ratings yet
- Ch11 MarcelDanesi 2023 11INTERACTIVEANDIMMER PopularCultureIntroduDocument24 pagesCh11 MarcelDanesi 2023 11INTERACTIVEANDIMMER PopularCultureIntroduphiliplam1130No ratings yet
- Media Conflictology As A Field of Research WorkingDocument10 pagesMedia Conflictology As A Field of Research WorkingSome ComNo ratings yet
- Chapter 4 of English As A Global LanguageDocument2 pagesChapter 4 of English As A Global LanguageAMAL CERULLINo ratings yet
- Simple Film Sponsorship ProposalDocument7 pagesSimple Film Sponsorship Proposalmuhamad azriNo ratings yet
- Bill BrandtDocument3 pagesBill BrandtAmalia Amely0% (2)
- Website MapDocument8 pagesWebsite MapPia LatojaNo ratings yet
- Safer Internet Day Primary 3rd 4th ClassDocument26 pagesSafer Internet Day Primary 3rd 4th ClassDarla KocoNo ratings yet
- 4thGradeMathTaskCardsEstimatingSumsandDifferencesFREEBIE 2Document14 pages4thGradeMathTaskCardsEstimatingSumsandDifferencesFREEBIE 2safaa nadarNo ratings yet
- Teacher Day PPT: Presentation PowerpointDocument52 pagesTeacher Day PPT: Presentation PowerpointLimberg ArhuataNo ratings yet
- Zenith y Otras AntiguasDocument9 pagesZenith y Otras AntiguasJuan SettiNo ratings yet
- Design - January 2024Document12 pagesDesign - January 2024ArtdataNo ratings yet
- KAD1Document1 pageKAD1bbobi1991No ratings yet
- Gundam Wars I - Project Z - Gundam WikiDocument2 pagesGundam Wars I - Project Z - Gundam WikiMark AbNo ratings yet
- Facebook MarketingDocument26 pagesFacebook Marketinghimanshi100% (1)
- Contemporary Philippine Arts From The Regions (CPAR) Notes For Second SemesterDocument2 pagesContemporary Philippine Arts From The Regions (CPAR) Notes For Second SemesterJoana Domingo0% (1)
- Heidegger The Concept of Time in The Science of History CompressDocument9 pagesHeidegger The Concept of Time in The Science of History Compresshermouetmarius46No ratings yet
- Unit-5 Designing and Implementing Brand Strategies Designing and Implementing Brand StrategiesDocument6 pagesUnit-5 Designing and Implementing Brand Strategies Designing and Implementing Brand Strategiesnidhi dubeyNo ratings yet
- Sublimation Paper ListDocument8 pagesSublimation Paper ListJeshu ValleNo ratings yet
- Aim BotDocument3 pagesAim BotJulia AtrazadaNo ratings yet
- Empathy Map - Jenna TorresDocument1 pageEmpathy Map - Jenna Torresapi-514920611No ratings yet
- Three (3) Things That I Significantly Learned From The ReadingsDocument2 pagesThree (3) Things That I Significantly Learned From The ReadingsCherine Fates MangulabnanNo ratings yet
- Hunger Games Class UnitDocument10 pagesHunger Games Class UnitTheHungerGames50% (2)
- Request Letter - Carmina's Flower ShopDocument2 pagesRequest Letter - Carmina's Flower ShopNathaniel ZyanNo ratings yet
- Il PDFDocument681 pagesIl PDFjulio1mar1a1fern1ndeNo ratings yet
- Poetry Recitation Competition: Rules and GuidelinesDocument5 pagesPoetry Recitation Competition: Rules and GuidelinesMOHD NORIZAM SAARINo ratings yet
- Orders (Sample Superstore Subset Excel) - Migrated DataDocument651 pagesOrders (Sample Superstore Subset Excel) - Migrated DataAnkit SharmaNo ratings yet