Download as docx, pdf, or txt
You might also like
- Ec9 - Engine Control System (r9m)Document410 pagesEc9 - Engine Control System (r9m)Eliecer Bayona100% (5)
- UntitledDocument16 pagesUntitledChristian CalmaNo ratings yet
- Exercise 1:: Solution: CodeDocument7 pagesExercise 1:: Solution: CodeAbdul Rehman AfzalNo ratings yet
- PE 06 Seepage FlownetsDocument22 pagesPE 06 Seepage FlownetsIshmam Shahid100% (1)
- Poultry Calculator v2.1Document17 pagesPoultry Calculator v2.1Desi Engineer100% (1)
- Exam (Q) Set ADocument13 pagesExam (Q) Set Aflowerpot321100% (1)
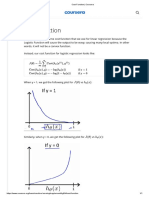
- Cost Function: (θ) =1m ∑ Cost (h (x) ,y) Cost (h (x) ,y) =−log (h (x) ) Cost (h (x) ,y) =−log (1−h (x) ) if y = 1if y = 0Document2 pagesCost Function: (θ) =1m ∑ Cost (h (x) ,y) Cost (h (x) ,y) =−log (h (x) ) Cost (h (x) ,y) =−log (1−h (x) ) if y = 1if y = 0Abdullah MahsudNo ratings yet
- Binary Logistic Regression From ScratchDocument10 pagesBinary Logistic Regression From Scratchcybersphinx85No ratings yet
- Cost Function - Coursera Week3Document1 pageCost Function - Coursera Week3Mr. KNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- Evaluating Double IntegralsDocument12 pagesEvaluating Double IntegralsVinod MoganNo ratings yet
- CS6402 - Daa 16marks With AnswersDocument20 pagesCS6402 - Daa 16marks With AnswerssharmilaNo ratings yet
- MATLAB Animation IIDocument8 pagesMATLAB Animation IIa_minisoft2005No ratings yet
- Sam HW2Document4 pagesSam HW2Ali HassanNo ratings yet
- Cost Function - CourseraDocument1 pageCost Function - CourseramehmetkseNo ratings yet
- ADS Cheat SheetDocument3 pagesADS Cheat SheetbssandeshbsNo ratings yet
- Tutorial Questions On Fuzzy Logic 1. A Triangular Member Function Shown in Figure Is To Be Made in MATLAB. Write A Function. Answer: CodeDocument13 pagesTutorial Questions On Fuzzy Logic 1. A Triangular Member Function Shown in Figure Is To Be Made in MATLAB. Write A Function. Answer: Codekiran preethiNo ratings yet
- Sample Research PaperDocument26 pagesSample Research Paperfb8ndyffmcNo ratings yet
- Vea Pa Que Se Entretenga AprendiendoDocument24 pagesVea Pa Que Se Entretenga AprendiendoJoseph Borja HernandezNo ratings yet
- Homework Set 3 SolutionsDocument15 pagesHomework Set 3 SolutionsEunchan KimNo ratings yet
- MATLABDocument24 pagesMATLABErhan KaraağaçNo ratings yet
- Linear RegressionDocument14 pagesLinear RegressionSyed Tariq NaqshbandiNo ratings yet
- (Tugas Kelas-07-10052021-B) 05111940000057Document7 pages(Tugas Kelas-07-10052021-B) 05111940000057KhaelaFortunelaNo ratings yet
- What Is Machine Learning?Document12 pagesWhat Is Machine Learning?AMISHA YELPALENo ratings yet
- Ch8 (3) Numerical IntegrationDocument19 pagesCh8 (3) Numerical Integrationআসিফ রেজাNo ratings yet
- Dynopt - Dynamic Optimisation Code For Matlab: Fikar/research/dynopt/dynopt - HTMDocument12 pagesDynopt - Dynamic Optimisation Code For Matlab: Fikar/research/dynopt/dynopt - HTMdhavalakkNo ratings yet
- Problem Set 3 Solution Numerical MethodsDocument11 pagesProblem Set 3 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- Application: Double T Sectional CharacteristicsDocument8 pagesApplication: Double T Sectional CharacteristicsAlin NegarăNo ratings yet
- Linear RegressionDocument3 pagesLinear RegressionAhly Zamalek MasryNo ratings yet
- Matlab Programming Help: Example 1Document8 pagesMatlab Programming Help: Example 1Aum4Eng HelpNo ratings yet
- Levenshtein Distance (Part 2 Gotta Go Fast) - Turnerj (Aka. James Turner)Document9 pagesLevenshtein Distance (Part 2 Gotta Go Fast) - Turnerj (Aka. James Turner)Blessing Emmanuel ArowomoleNo ratings yet
- Power Spectrum: To Compute PSDDocument8 pagesPower Spectrum: To Compute PSDKiran KumarNo ratings yet
- Khối Phần Mềm Thực Thi Mã Hóa Reed - Solomon Và Chương Trình Mô PhỏngDocument25 pagesKhối Phần Mềm Thực Thi Mã Hóa Reed - Solomon Và Chương Trình Mô Phỏnglinh duyNo ratings yet
- Signals & Systems Lab.-ManualDocument15 pagesSignals & Systems Lab.-ManualsibascribdNo ratings yet
- Insertion Sort: While Some Elements UnsortedDocument22 pagesInsertion Sort: While Some Elements Unsorteddoldrums7No ratings yet
- Polymath Fooling Tutorial Example-12-6Document12 pagesPolymath Fooling Tutorial Example-12-6Rodrigo RamosNo ratings yet
- Homework FinalDocument13 pagesHomework FinalAlin NegarăNo ratings yet
- EEE 4706 Lab 1Document6 pagesEEE 4706 Lab 1Rummanur RahadNo ratings yet
- Programming Exercise 2: Logistic Regression: Machine LearningDocument13 pagesProgramming Exercise 2: Logistic Regression: Machine LearningzonadosNo ratings yet
- ML Andrew NGDocument13 pagesML Andrew NGGuru PrasadNo ratings yet
- Application For Iterative Solutions of A PolynomialDocument6 pagesApplication For Iterative Solutions of A PolynomialGlenn ManaleseNo ratings yet
- HW1Document11 pagesHW1Tao Liu YuNo ratings yet
- Matlab Code For Radial Basis FunctionsDocument13 pagesMatlab Code For Radial Basis FunctionsSubash Chandar Adikesavan100% (2)
- 2023-2-KMU134-L13Document21 pages2023-2-KMU134-L13Efe Kağan GÜNERNo ratings yet
- Kill MeDocument23 pagesKill MeEmilyNo ratings yet
- Cost, Revenue, and Profit Function Estimates by Kutlu, Liu, and Sickles - Oct-15-2018Document66 pagesCost, Revenue, and Profit Function Estimates by Kutlu, Liu, and Sickles - Oct-15-2018Faizan MazharNo ratings yet
- Systems and Circuits: Lab 1: SignalsDocument21 pagesSystems and Circuits: Lab 1: Signalsashutosh199625No ratings yet
- (Machine Learning Coursera) Lecture Note Week 1Document8 pages(Machine Learning Coursera) Lecture Note Week 1JonnyJackNo ratings yet
- ENGM541 Lab5 Runge Kutta SimulinkstatespaceDocument5 pagesENGM541 Lab5 Runge Kutta SimulinkstatespaceAbiodun GbengaNo ratings yet
- Discussion:: Figure 1 Plot For y Exp (-2 T) . Cos (5 T)Document3 pagesDiscussion:: Figure 1 Plot For y Exp (-2 T) . Cos (5 T)BishnuNo ratings yet
- Dynopt - Dynamic Optimisation Code ForDocument12 pagesDynopt - Dynamic Optimisation Code ForVyta AdeliaNo ratings yet
- Dynamic Programming Algorithms: Based On University of Toronto CSC 364 Notes, Original Lectures by Stephen CookDocument18 pagesDynamic Programming Algorithms: Based On University of Toronto CSC 364 Notes, Original Lectures by Stephen Cookshubham guptaNo ratings yet
- Experiment No. 01 Experiment Name: Objectives:: 2.platform Independence. 3Document10 pagesExperiment No. 01 Experiment Name: Objectives:: 2.platform Independence. 3Omor FarukNo ratings yet
- Computer Vision Project - ReportDocument28 pagesComputer Vision Project - ReportPRANAV KAKKARNo ratings yet
- Introduction To Matlab Tutorial 11Document37 pagesIntroduction To Matlab Tutorial 11James Edward TrollopeNo ratings yet
- Matlab CodesDocument92 pagesMatlab Codesonlymag4u75% (8)
- Inverse Trigonometric Functions (Trigonometry) Mathematics Question BankFrom EverandInverse Trigonometric Functions (Trigonometry) Mathematics Question BankNo ratings yet
- Mathematical Formulas for Economics and Business: A Simple IntroductionFrom EverandMathematical Formulas for Economics and Business: A Simple IntroductionRating: 4 out of 5 stars4/5 (4)
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Hendrickson Assignment4Document11 pagesHendrickson Assignment4Angel Nicole SorianoNo ratings yet
- PL/SQL User Defined Types Record and Table: Please Use Speaker Notes For Additional Information!Document15 pagesPL/SQL User Defined Types Record and Table: Please Use Speaker Notes For Additional Information!sekharmcpNo ratings yet
- Math 203-1.1Document85 pagesMath 203-1.1Max ModiNo ratings yet
- Chapter 2Document37 pagesChapter 2Abdullah Ibn MasudNo ratings yet
- Selected Questions Revised 20200305 2HRDocument3 pagesSelected Questions Revised 20200305 2HRTimmy LeeNo ratings yet
- Unit 5 Cellular Energy Worksheet With AnswersDocument2 pagesUnit 5 Cellular Energy Worksheet With AnswersJohn Daniel AntolinNo ratings yet
- FluidsDocument1 pageFluidsevil geniusNo ratings yet
- 17 A02 PHExDocument6 pages17 A02 PHExPeter LeaderNo ratings yet
- LEP Asset Management PolicyDocument3 pagesLEP Asset Management PolicyMurugesh MurugesanNo ratings yet
- 专利 1 已授权 US10808172B2Document20 pages专利 1 已授权 US10808172B2Zhen BaoNo ratings yet
- Falcon Technology - Joe Zeck, DCI ChinaDocument8 pagesFalcon Technology - Joe Zeck, DCI ChinaZAMIRNo ratings yet
- STD IX - DR Homi Bhabha BalVaidyanik Competition-Question For PracticeQuestion Bank 2014Document12 pagesSTD IX - DR Homi Bhabha BalVaidyanik Competition-Question For PracticeQuestion Bank 2014Dr Mohan Savade100% (7)
- Hitachi 32hb6t41u 32284dlbn Chassis 17mb97-r2 17ips62-R2 SMDocument65 pagesHitachi 32hb6t41u 32284dlbn Chassis 17mb97-r2 17ips62-R2 SMCarlos GonçalvesNo ratings yet
- According To Use: Main Auxiliary According To Passage of Flue GasesDocument11 pagesAccording To Use: Main Auxiliary According To Passage of Flue GasesAbdallah MansourNo ratings yet
- Sony kv-sw292m50 sw292m61 sw292m80 sw292n60 Chassis bx1l Ver.2.0Document189 pagesSony kv-sw292m50 sw292m61 sw292m80 sw292n60 Chassis bx1l Ver.2.0mrcrypto223No ratings yet
- Chapter 2 SlidesDocument66 pagesChapter 2 SlidesHeriansyah NajemiNo ratings yet
- Physics 7E: Practice MidtermDocument5 pagesPhysics 7E: Practice MidtermFUSION AcademicsNo ratings yet
- Sensitivity: This Document Is Classified As "LNT Internal Use"Document6 pagesSensitivity: This Document Is Classified As "LNT Internal Use"ravi yemmadiNo ratings yet
- 5B Lesson Worksheet 7.1A: Instant Example 1 Instant Practice 1Document2 pages5B Lesson Worksheet 7.1A: Instant Example 1 Instant Practice 1Karson ChanNo ratings yet
- Micro X Ray Fluorescence Spectroscopy First Edition PDFDocument31 pagesMicro X Ray Fluorescence Spectroscopy First Edition PDFAlberto Núñez CardezoNo ratings yet
- 111 Sample ChapterDocument10 pages111 Sample ChapterAnonymous bfbxnOawNo ratings yet
- Bpe300 Um enDocument37 pagesBpe300 Um encaioalmeida492No ratings yet
- Residential Multi Split CatalogueDocument51 pagesResidential Multi Split Cataloguengocdhxd92No ratings yet
- Tdto Sae 50Document1 pageTdto Sae 50Leon Mercado RNo ratings yet
- Fall 2010-11 Course OfferingsDocument3 pagesFall 2010-11 Course OfferingsrezadigitNo ratings yet
- FrictionDocument4 pagesFrictiondanNo ratings yet