
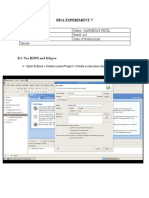
DSBDA GRP B Print
DSBDA GRP B Print
You might also like
- Operating Systems Q&A - 16-1&2Document43 pagesOperating Systems Q&A - 16-1&2Mazen SeniorNo ratings yet
- READMEDocument2 pagesREADMEkumar0% (3)
- Kaspersky Lab Scan ExclusionsDocument29 pagesKaspersky Lab Scan Exclusionsdrage26No ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDocument61 pagesPractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- Map Reduce ExampleDocument6 pagesMap Reduce ExampleJajang NurjamanNo ratings yet
- SalesData Map ReduceDocument3 pagesSalesData Map Reducebhavana16686No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Document13 pagesCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- MapReduce ExampleDocument3 pagesMapReduce ExampleRavi ChanderNo ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- Part B Assignment - No - 1Document6 pagesPart B Assignment - No - 1opscoldyNo ratings yet
- BDF Lab1Document6 pagesBDF Lab1shaliniiiiNo ratings yet
- Step 2 - First MapReduce ProgramDocument25 pagesStep 2 - First MapReduce ProgramSantosh Kumar DesaiNo ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- Assignment 2-033Document13 pagesAssignment 2-033DHARSHANA C PNo ratings yet
- Bda Final 11janDocument7 pagesBda Final 11janG dileep KumarNo ratings yet
- Big Data - ASSIGNMENT 2Document15 pagesBig Data - ASSIGNMENT 2DHARSHANA C PNo ratings yet
- Prácticas Bigdata: 1. Lanzar Un Proceso Mapreduce Contra El ClusterDocument3 pagesPrácticas Bigdata: 1. Lanzar Un Proceso Mapreduce Contra El ClusterChristiam NiñoNo ratings yet
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- To Count Using Map and Reduce Program: Wordcount - JavaDocument2 pagesTo Count Using Map and Reduce Program: Wordcount - JavaRamya DeviNo ratings yet
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocument11 pagesTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- Exp 4 Word CountDocument4 pagesExp 4 Word Countmunish kumar agarwalNo ratings yet
- HadoopDocument51 pagesHadoopRavitej TadinadaNo ratings yet
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDocument5 pagesWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNo ratings yet
- Installation of Apache Hadoop 2. Word Count ProgramDocument25 pagesInstallation of Apache Hadoop 2. Word Count Programnecn cse-b 2nd-yearNo ratings yet
- Big DataDocument25 pagesBig DataAnu GraphicsNo ratings yet
- 12 CodigoNetbeansDocument5 pages12 CodigoNetbeansMiguel AngelNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Hadoop Char CountDocument1 pageHadoop Char Countkavya kavNo ratings yet
- Hadoop Training in HyderabadDocument49 pagesHadoop Training in HyderabadkellytechnologiesNo ratings yet
- ContarPalabras JavaDocument2 pagesContarPalabras JavaYeisson MirandaNo ratings yet
- Developing A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanDocument22 pagesDeveloping A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanKaushal PrajapatiNo ratings yet
- Map ReduceDocument4 pagesMap Reducechetanruparel07awsNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Experiment No: 1: Create Different Entities DynamicallyDocument43 pagesExperiment No: 1: Create Different Entities Dynamicallyvinay DeshmukhNo ratings yet
- Big DataDocument67 pagesBig DataB21A4530 AshrithaNo ratings yet
- Cloudera Academic Partnership 4 PDFDocument38 pagesCloudera Academic Partnership 4 PDFEL MAMOUN ABDELLAHNo ratings yet
- Analyzing The Data With HadoopDocument13 pagesAnalyzing The Data With HadoopVyshnavi ThottempudiNo ratings yet
- Execute Java Map Reduce Sample Using EclipseDocument9 pagesExecute Java Map Reduce Sample Using EclipseArjun SNo ratings yet
- Big DataDocument23 pagesBig DataYashika SinghNo ratings yet
- Word Count Problem: INT 312 Hargobind SinghDocument18 pagesWord Count Problem: INT 312 Hargobind SinghAyush Kumar GuptaNo ratings yet
- Hadoop Administrator Training - Lab Hand BookDocument12 pagesHadoop Administrator Training - Lab Hand BookdebkrcNo ratings yet
- 1ST PROGRAM HadoopDocument5 pages1ST PROGRAM Hadoopakshithasonia333No ratings yet
- PalakDocument10 pagesPalakDolly MehraNo ratings yet
- Word CountDocument3 pagesWord Countniharika sunkaraNo ratings yet
- Hadoop WordCountDocument2 pagesHadoop WordCountkavya kavNo ratings yet
- Eco System NotesDocument15 pagesEco System Noteszammy officialNo ratings yet
- Lecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)Document22 pagesLecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)kumarNo ratings yet
- Department of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3Document4 pagesDepartment of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3IshanNo ratings yet
- Prerequisites: Single Node Setup Cluster SetupDocument5 pagesPrerequisites: Single Node Setup Cluster Setupmartha quingaNo ratings yet
- Big Data Fundamentals and Platforms Assginment 3Document6 pagesBig Data Fundamentals and Platforms Assginment 3sagar srivastavaNo ratings yet
- Big Data Lab MaterialDocument45 pagesBig Data Lab MaterialGaurav NagarNo ratings yet
- Week 10Document4 pagesWeek 10THANU SREENo ratings yet
- Module-2-Introduction To HDFS and ToolsDocument38 pagesModule-2-Introduction To HDFS and ToolsshreyaNo ratings yet
- Lecture Slide 2Document26 pagesLecture Slide 2Maharabur Rahman ApuNo ratings yet
- Exercise (Disk&File)Document22 pagesExercise (Disk&File)vaibhavNo ratings yet
- Device Drivers For Your Girlfriend Sysplay Dot inDocument163 pagesDevice Drivers For Your Girlfriend Sysplay Dot inmyhomenet1191881No ratings yet
- YozologDocument6 pagesYozologRicky EstebanNo ratings yet
- Red Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFDocument567 pagesRed Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFCourtney RoseNo ratings yet
- Lab 2.1 - System Hierarchy N Basic CommandsDocument3 pagesLab 2.1 - System Hierarchy N Basic CommandsDhiraj PhuyalNo ratings yet
- The Fork System CallDocument10 pagesThe Fork System Callpriya1788ekNo ratings yet
- Linux Scenario QuestionsDocument7 pagesLinux Scenario QuestionsVineet Vidyavilas PathakNo ratings yet
- Lecture 3 PDCDocument21 pagesLecture 3 PDCAhsan SaeedNo ratings yet
- Symantec NetBackup Interview Questions and Answers - TeczDocument3 pagesSymantec NetBackup Interview Questions and Answers - Teczmondrathi.kiran50% (2)
- BScCSIT Transaction DBMSDocument30 pagesBScCSIT Transaction DBMSakyadav123No ratings yet
- Windows Power Shell CommandsDocument7 pagesWindows Power Shell CommandsssprudhviNo ratings yet
- Systemd in Suse Linux Enterprise 12 White PaperDocument16 pagesSystemd in Suse Linux Enterprise 12 White PaperhazardhapNo ratings yet
- Latest Releases: Wine 4.0 (/announce/4.0) Wine 4.4 (/announce/4.4)Document3 pagesLatest Releases: Wine 4.0 (/announce/4.0) Wine 4.4 (/announce/4.4)José LuisNo ratings yet
- Deadlock Prevention and Avoidance-1Document2 pagesDeadlock Prevention and Avoidance-1YogiNo ratings yet
- Multitasking and Resource Sharing in Embedded SystemsDocument31 pagesMultitasking and Resource Sharing in Embedded SystemsKhaled RelaTivNo ratings yet
- Windows Live ResponseDocument14 pagesWindows Live ResponseShafeeque Olassery KunnikkalNo ratings yet
- Linux Performance 2018: Brendan GreggDocument26 pagesLinux Performance 2018: Brendan Greggtejas kumarNo ratings yet
- Mellanox OFED Linux Release Notes 3 4-1 0 0 0Document66 pagesMellanox OFED Linux Release Notes 3 4-1 0 0 0carlosNo ratings yet
- Backup LogDocument3 pagesBackup Logsadessnuk1No ratings yet
- Log 1Document5 pagesLog 1Ejsjdjdjdjdjd OitavoanjoNo ratings yet
- Lom LogDocument17 pagesLom LogCesar Javier PolancoNo ratings yet
- MobaXterm 192.168.181.159root 20210615 181356Document688 pagesMobaXterm 192.168.181.159root 20210615 181356Vaibhav JayasNo ratings yet
- 1: Setting Up Xen ( 10minutes) : 1.1: Install and Configure Virtual Box ( 2 Minutes)Document19 pages1: Setting Up Xen ( 10minutes) : 1.1: Install and Configure Virtual Box ( 2 Minutes)Vinod Kumar UttaravalliNo ratings yet
- State Subha SyllabusDocument10 pagesState Subha Syllabusanii Bibek JoshiNo ratings yet
- Ipv5 ManualDocument95 pagesIpv5 ManualFathin NazeeraNo ratings yet
























































































Download as pdf or txt
You might also like
- Operating Systems Q&A - 16-1&2Document43 pagesOperating Systems Q&A - 16-1&2Mazen SeniorNo ratings yet
- READMEDocument2 pagesREADMEkumar0% (3)
- Kaspersky Lab Scan ExclusionsDocument29 pagesKaspersky Lab Scan Exclusionsdrage26No ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDocument61 pagesPractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- Map Reduce ExampleDocument6 pagesMap Reduce ExampleJajang NurjamanNo ratings yet
- SalesData Map ReduceDocument3 pagesSalesData Map Reducebhavana16686No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Document13 pagesCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- MapReduce ExampleDocument3 pagesMapReduce ExampleRavi ChanderNo ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- Part B Assignment - No - 1Document6 pagesPart B Assignment - No - 1opscoldyNo ratings yet
- BDF Lab1Document6 pagesBDF Lab1shaliniiiiNo ratings yet
- Step 2 - First MapReduce ProgramDocument25 pagesStep 2 - First MapReduce ProgramSantosh Kumar DesaiNo ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- Assignment 2-033Document13 pagesAssignment 2-033DHARSHANA C PNo ratings yet
- Bda Final 11janDocument7 pagesBda Final 11janG dileep KumarNo ratings yet
- Big Data - ASSIGNMENT 2Document15 pagesBig Data - ASSIGNMENT 2DHARSHANA C PNo ratings yet
- Prácticas Bigdata: 1. Lanzar Un Proceso Mapreduce Contra El ClusterDocument3 pagesPrácticas Bigdata: 1. Lanzar Un Proceso Mapreduce Contra El ClusterChristiam NiñoNo ratings yet
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- To Count Using Map and Reduce Program: Wordcount - JavaDocument2 pagesTo Count Using Map and Reduce Program: Wordcount - JavaRamya DeviNo ratings yet
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocument11 pagesTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- Exp 4 Word CountDocument4 pagesExp 4 Word Countmunish kumar agarwalNo ratings yet
- HadoopDocument51 pagesHadoopRavitej TadinadaNo ratings yet
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDocument5 pagesWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNo ratings yet
- Installation of Apache Hadoop 2. Word Count ProgramDocument25 pagesInstallation of Apache Hadoop 2. Word Count Programnecn cse-b 2nd-yearNo ratings yet
- Big DataDocument25 pagesBig DataAnu GraphicsNo ratings yet
- 12 CodigoNetbeansDocument5 pages12 CodigoNetbeansMiguel AngelNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Hadoop Char CountDocument1 pageHadoop Char Countkavya kavNo ratings yet
- Hadoop Training in HyderabadDocument49 pagesHadoop Training in HyderabadkellytechnologiesNo ratings yet
- ContarPalabras JavaDocument2 pagesContarPalabras JavaYeisson MirandaNo ratings yet
- Developing A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanDocument22 pagesDeveloping A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanKaushal PrajapatiNo ratings yet
- Map ReduceDocument4 pagesMap Reducechetanruparel07awsNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Experiment No: 1: Create Different Entities DynamicallyDocument43 pagesExperiment No: 1: Create Different Entities Dynamicallyvinay DeshmukhNo ratings yet
- Big DataDocument67 pagesBig DataB21A4530 AshrithaNo ratings yet
- Cloudera Academic Partnership 4 PDFDocument38 pagesCloudera Academic Partnership 4 PDFEL MAMOUN ABDELLAHNo ratings yet
- Analyzing The Data With HadoopDocument13 pagesAnalyzing The Data With HadoopVyshnavi ThottempudiNo ratings yet
- Execute Java Map Reduce Sample Using EclipseDocument9 pagesExecute Java Map Reduce Sample Using EclipseArjun SNo ratings yet
- Big DataDocument23 pagesBig DataYashika SinghNo ratings yet
- Word Count Problem: INT 312 Hargobind SinghDocument18 pagesWord Count Problem: INT 312 Hargobind SinghAyush Kumar GuptaNo ratings yet
- Hadoop Administrator Training - Lab Hand BookDocument12 pagesHadoop Administrator Training - Lab Hand BookdebkrcNo ratings yet
- 1ST PROGRAM HadoopDocument5 pages1ST PROGRAM Hadoopakshithasonia333No ratings yet
- PalakDocument10 pagesPalakDolly MehraNo ratings yet
- Word CountDocument3 pagesWord Countniharika sunkaraNo ratings yet
- Hadoop WordCountDocument2 pagesHadoop WordCountkavya kavNo ratings yet
- Eco System NotesDocument15 pagesEco System Noteszammy officialNo ratings yet
- Lecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)Document22 pagesLecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)kumarNo ratings yet
- Department of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3Document4 pagesDepartment of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3IshanNo ratings yet
- Prerequisites: Single Node Setup Cluster SetupDocument5 pagesPrerequisites: Single Node Setup Cluster Setupmartha quingaNo ratings yet
- Big Data Fundamentals and Platforms Assginment 3Document6 pagesBig Data Fundamentals and Platforms Assginment 3sagar srivastavaNo ratings yet
- Big Data Lab MaterialDocument45 pagesBig Data Lab MaterialGaurav NagarNo ratings yet
- Week 10Document4 pagesWeek 10THANU SREENo ratings yet
- Module-2-Introduction To HDFS and ToolsDocument38 pagesModule-2-Introduction To HDFS and ToolsshreyaNo ratings yet
- Lecture Slide 2Document26 pagesLecture Slide 2Maharabur Rahman ApuNo ratings yet
- Exercise (Disk&File)Document22 pagesExercise (Disk&File)vaibhavNo ratings yet
- Device Drivers For Your Girlfriend Sysplay Dot inDocument163 pagesDevice Drivers For Your Girlfriend Sysplay Dot inmyhomenet1191881No ratings yet
- YozologDocument6 pagesYozologRicky EstebanNo ratings yet
- Red Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFDocument567 pagesRed Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFCourtney RoseNo ratings yet
- Lab 2.1 - System Hierarchy N Basic CommandsDocument3 pagesLab 2.1 - System Hierarchy N Basic CommandsDhiraj PhuyalNo ratings yet
- The Fork System CallDocument10 pagesThe Fork System Callpriya1788ekNo ratings yet
- Linux Scenario QuestionsDocument7 pagesLinux Scenario QuestionsVineet Vidyavilas PathakNo ratings yet
- Lecture 3 PDCDocument21 pagesLecture 3 PDCAhsan SaeedNo ratings yet
- Symantec NetBackup Interview Questions and Answers - TeczDocument3 pagesSymantec NetBackup Interview Questions and Answers - Teczmondrathi.kiran50% (2)
- BScCSIT Transaction DBMSDocument30 pagesBScCSIT Transaction DBMSakyadav123No ratings yet
- Windows Power Shell CommandsDocument7 pagesWindows Power Shell CommandsssprudhviNo ratings yet
- Systemd in Suse Linux Enterprise 12 White PaperDocument16 pagesSystemd in Suse Linux Enterprise 12 White PaperhazardhapNo ratings yet
- Latest Releases: Wine 4.0 (/announce/4.0) Wine 4.4 (/announce/4.4)Document3 pagesLatest Releases: Wine 4.0 (/announce/4.0) Wine 4.4 (/announce/4.4)José LuisNo ratings yet
- Deadlock Prevention and Avoidance-1Document2 pagesDeadlock Prevention and Avoidance-1YogiNo ratings yet
- Multitasking and Resource Sharing in Embedded SystemsDocument31 pagesMultitasking and Resource Sharing in Embedded SystemsKhaled RelaTivNo ratings yet
- Windows Live ResponseDocument14 pagesWindows Live ResponseShafeeque Olassery KunnikkalNo ratings yet
- Linux Performance 2018: Brendan GreggDocument26 pagesLinux Performance 2018: Brendan Greggtejas kumarNo ratings yet
- Mellanox OFED Linux Release Notes 3 4-1 0 0 0Document66 pagesMellanox OFED Linux Release Notes 3 4-1 0 0 0carlosNo ratings yet
- Backup LogDocument3 pagesBackup Logsadessnuk1No ratings yet
- Log 1Document5 pagesLog 1Ejsjdjdjdjdjd OitavoanjoNo ratings yet
- Lom LogDocument17 pagesLom LogCesar Javier PolancoNo ratings yet
- MobaXterm 192.168.181.159root 20210615 181356Document688 pagesMobaXterm 192.168.181.159root 20210615 181356Vaibhav JayasNo ratings yet
- 1: Setting Up Xen ( 10minutes) : 1.1: Install and Configure Virtual Box ( 2 Minutes)Document19 pages1: Setting Up Xen ( 10minutes) : 1.1: Install and Configure Virtual Box ( 2 Minutes)Vinod Kumar UttaravalliNo ratings yet
- State Subha SyllabusDocument10 pagesState Subha Syllabusanii Bibek JoshiNo ratings yet
- Ipv5 ManualDocument95 pagesIpv5 ManualFathin NazeeraNo ratings yet