
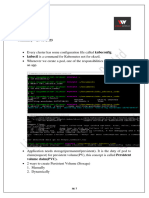
164 Creating AWS Volumes
164 Creating AWS Volumes
You might also like
- AWS NotesDocument32 pagesAWS Notespavankalluri100% (6)
- EXAMREVIEW AWSCertification CloudPractitionerDocument116 pagesEXAMREVIEW AWSCertification CloudPractitionerBitirme Tezi100% (1)
- 902, 906, & 908 Compact Wheel Loader Electrical System: Machine Harness Connector and Component LocationsDocument2 pages902, 906, & 908 Compact Wheel Loader Electrical System: Machine Harness Connector and Component Locationsait mimouneNo ratings yet
- 170 Using Storage Classes To Dynamically Provision Persistent VolumesDocument7 pages170 Using Storage Classes To Dynamically Provision Persistent VolumesAjay SinghNo ratings yet
- Amazon ECS - Free AWS Cheat SheetsDocument20 pagesAmazon ECS - Free AWS Cheat Sheetsmoon walkerNo ratings yet
- How To Design and Provision A Production-Ready EKS Cluster: Image Credit: PixabayDocument11 pagesHow To Design and Provision A Production-Ready EKS Cluster: Image Credit: Pixabaycentinel29No ratings yet
- Amazon Web Services NotesDocument37 pagesAmazon Web Services NotesTarun100% (6)
- Advance AWS InterviewquestionsDocument39 pagesAdvance AWS InterviewquestionsZubair AhmadNo ratings yet
- AWS Overview Concepts EC2Document22 pagesAWS Overview Concepts EC2Mohammad MazheruddinNo ratings yet
- Pitc Aws Chapter 8Document66 pagesPitc Aws Chapter 8Mangesh AbnaveNo ratings yet
- Cs264 Intro To Cloud ComputingDocument42 pagesCs264 Intro To Cloud ComputingnorfolktexNo ratings yet
- Elastic Block Store (Amazon EBS)Document29 pagesElastic Block Store (Amazon EBS)hanuman challisaNo ratings yet
- Docker Terraform Amazon ECS: A Quick Intro ToDocument98 pagesDocker Terraform Amazon ECS: A Quick Intro ToDodo winyNo ratings yet
- EKS Forensics & Incident ResponseDocument10 pagesEKS Forensics & Incident Responsechristopher.d.domanNo ratings yet
- What Is Elastic Block Store?Document11 pagesWhat Is Elastic Block Store?kanmaniprsnlNo ratings yet
- Aws Odd Interview QuestionsDocument36 pagesAws Odd Interview QuestionsZubair AhmadNo ratings yet
- AWS EC2 QuizDocument7 pagesAWS EC2 QuizsrihbkpNo ratings yet
- Storage - KubernetesDocument76 pagesStorage - KubernetesFantahun FkadieNo ratings yet
- 2 AWS StorageDocument16 pages2 AWS StorageAslam AnsariNo ratings yet
- Exam Quick RefrenceDocument16 pagesExam Quick RefrencesamalparthaNo ratings yet
- UntitledDocument39 pagesUntitledJoe RodriguezNo ratings yet
- Amazon EBS For MeetingDocument8 pagesAmazon EBS For MeetingSuraj KumarNo ratings yet
- Azure Data Engineer GuideDocument87 pagesAzure Data Engineer GuideEdiga VenkatadriNo ratings yet
- CH 01Document18 pagesCH 01sameo13No ratings yet
- Experiment 3 Introduction To Amazon Elastic Container ServiceDocument9 pagesExperiment 3 Introduction To Amazon Elastic Container ServicevamsiNo ratings yet
- CH 03Document14 pagesCH 03sameo13No ratings yet
- Dp203 NotesDocument87 pagesDp203 Notesİbrahim SezenNo ratings yet
- 168 Verifying The State Persistence and Exploring The FailuresDocument5 pages168 Verifying The State Persistence and Exploring The FailuresAjay SinghNo ratings yet
- Amazon ECS Lab1Document19 pagesAmazon ECS Lab1biswajitmohanty8260No ratings yet
- Build EKS Cluster With Terraform. A Simple Infrastructure-As-Code Way - by Nico Singh - Sep, 2020 - ITNEXTDocument19 pagesBuild EKS Cluster With Terraform. A Simple Infrastructure-As-Code Way - by Nico Singh - Sep, 2020 - ITNEXTaaaa100% (1)
- How To Attach and Mount An EBS Volume To EC2 Linux InstanceDocument12 pagesHow To Attach and Mount An EBS Volume To EC2 Linux Instancejai kumarNo ratings yet
- Aws Storage SolutionsDocument8 pagesAws Storage SolutionsHitesh KatariyaNo ratings yet
- 01-AZ-300T01-M2Document49 pages01-AZ-300T01-M2myrizwan807No ratings yet
- Intro To Amazon ECS: Abby Fuller, AWS @abbyfullerDocument32 pagesIntro To Amazon ECS: Abby Fuller, AWS @abbyfullerAditya GangulyNo ratings yet
- Project Hosting On AWS EKSDocument13 pagesProject Hosting On AWS EKSSreenath GNo ratings yet
- Lab 1.1 - AWS Academy Learner Lab - Associate ServicesDocument5 pagesLab 1.1 - AWS Academy Learner Lab - Associate ServicesCong Yue LimNo ratings yet
- Optimizing MySQL On AmazonDocument36 pagesOptimizing MySQL On Amazonpark hyoNo ratings yet
- Red Hat StorageDocument19 pagesRed Hat Storagejasper michaelsNo ratings yet
- AWS Services For Devops EngineerDocument6 pagesAWS Services For Devops Engineersathyanarayana medaNo ratings yet
- 3.amazon EBS PDFDocument17 pages3.amazon EBS PDFbiswajit patrasecNo ratings yet
- EU 22 Noam Moshe JS ON Security OffDocument72 pagesEU 22 Noam Moshe JS ON Security OffhumanNo ratings yet
- Case Study: Amazon AWS: CSE 40822 - Cloud Computing Prof. Douglas Thain University of Notre DameDocument33 pagesCase Study: Amazon AWS: CSE 40822 - Cloud Computing Prof. Douglas Thain University of Notre Dameawslab8No ratings yet
- Sample Q and ADocument47 pagesSample Q and AHareesha N G100% (1)
- Lab 03b - Manage Azure Resources by Using ARM Templates Student Lab ManualDocument3 pagesLab 03b - Manage Azure Resources by Using ARM Templates Student Lab ManualNoor HabibNo ratings yet
- AWS S3 Interview QuestionsDocument23 pagesAWS S3 Interview QuestionsNitin GordeNo ratings yet
- Questions AwsDocument2 pagesQuestions AwsABHI_NITTENo ratings yet
- VM OvsDocument9 pagesVM OvsdesertcoderNo ratings yet
- Datadog AWSeBook ContainerizedApplicationsDocument44 pagesDatadog AWSeBook ContainerizedApplicationsmars9990No ratings yet
- ClusteringDocument21 pagesClusteringनरेन्द्र मथुरियाNo ratings yet
- How To Configure Two Node High Availability Cluster On RHELDocument18 pagesHow To Configure Two Node High Availability Cluster On RHELslides courseNo ratings yet
- Devops Interview QDocument9 pagesDevops Interview Qindigo itNo ratings yet
- Oracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qDocument49 pagesOracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qLuis AlfredoNo ratings yet
- NodeJs Basics PracticeDocument9 pagesNodeJs Basics Practiceunofficialartist3No ratings yet
- 06 - EBS LabDocument6 pages06 - EBS LabFelipe DuqueNo ratings yet
- AWS Sysops PDFDocument138 pagesAWS Sysops PDFSayed EldawyNo ratings yet
- ECS Forensics & Incident ResponseDocument7 pagesECS Forensics & Incident Responsechristopher.d.domanNo ratings yet
- Ansible ModulesDocument12 pagesAnsible ModulesjayNo ratings yet
- 6 StorageDocument12 pages6 StoragePravin RaiNo ratings yet
- Aws Recon Webinar MaterialDocument52 pagesAws Recon Webinar MaterialManas RanjanNo ratings yet
- Openstack Ceph AdminDocument168 pagesOpenstack Ceph Adminayfbjj37832khNo ratings yet
- Definitive Guide Robot Welding Torches v1.0Document50 pagesDefinitive Guide Robot Welding Torches v1.0AlexgriNo ratings yet
- SECTEC AI WIFI YCC365 PLUS Camera Pricelist201906Document5 pagesSECTEC AI WIFI YCC365 PLUS Camera Pricelist201906Glenn JattanNo ratings yet
- Fortran CF DDocument160 pagesFortran CF DLahcen AkerkouchNo ratings yet
- Techniques For Collection, Isolation and Preservation of MicroorganismsDocument42 pagesTechniques For Collection, Isolation and Preservation of Microorganismsaziskf100% (2)
- prEN 12390-11 - DRAFTDocument32 pagesprEN 12390-11 - DRAFTCarlos GilNo ratings yet
- Audi s6 2007 5.2l ManualDocument374 pagesAudi s6 2007 5.2l ManualMisael EspañaNo ratings yet
- 6-Büşra BahatDocument4 pages6-Büşra BahatAYŞE NURNo ratings yet
- Soft Computing Module IDocument161 pagesSoft Computing Module INatarajanSubramanyamNo ratings yet
- 5 MuscleDocument3 pages5 MuscleNicolePorsueloNo ratings yet
- Introduction To Privatisation and Liberalisation in India: by Anmol SharmaDocument10 pagesIntroduction To Privatisation and Liberalisation in India: by Anmol SharmaAnmol SharmaNo ratings yet
- 42pt250b Manual ServicioDocument63 pages42pt250b Manual ServicioLuis Carlos Bonilla AldanaNo ratings yet
- Kaong PaperDocument10 pagesKaong PapermikxendyNo ratings yet
- Te 243684Document57 pagesTe 243684infoNo ratings yet
- Linear AlgebraDocument395 pagesLinear AlgebraRehan Javed100% (2)
- Department of Education: Republic of The PhilippinesDocument3 pagesDepartment of Education: Republic of The PhilippinesRhenalyn Rose Obligar PasaholNo ratings yet
- SteelDocument61 pagesSteelSonNguyenNo ratings yet
- Soal OkeDocument12 pagesSoal OkefredyNo ratings yet
- Womb World Mandala Reflections of The BuDocument11 pagesWomb World Mandala Reflections of The BuLenka MladenovićNo ratings yet
- ASHRAE-tables Lighting Power Density PDFDocument3 pagesASHRAE-tables Lighting Power Density PDFDan MolloyNo ratings yet
- GR8313 GrenergyDocument9 pagesGR8313 GrenergyAngel Luis Aquino GonzalezNo ratings yet
- 31-SDMS-03 Low Voltage Cabinet For. Pole Mounted Transformer PDFDocument20 pages31-SDMS-03 Low Voltage Cabinet For. Pole Mounted Transformer PDFMehdi SalahNo ratings yet
- Dialysis - Purpose, Types, Risks, and MoreDocument13 pagesDialysis - Purpose, Types, Risks, and MoreTino HelaNo ratings yet
- The Myth of PlutoDocument6 pagesThe Myth of PlutoZsuzsanna ZöldNo ratings yet
- Pharmaceutics 14 02240Document17 pagesPharmaceutics 14 02240oliverasrommelNo ratings yet
- Substation Construction and CommissioningDocument83 pagesSubstation Construction and CommissioningShung Tak ChanNo ratings yet
- ENS 195 - Pollution and Environmental HealthDocument54 pagesENS 195 - Pollution and Environmental HealthEdcel ZabalaNo ratings yet
- Logic Pro X Cheat Sheet (Atajos)Document14 pagesLogic Pro X Cheat Sheet (Atajos)Nazareno AltamiranoNo ratings yet
- Pdf&rendition 1Document61 pagesPdf&rendition 1Dulce DeNo ratings yet
- Lung Sounds Auscultation - 1Document3 pagesLung Sounds Auscultation - 1George BarajazNo ratings yet























































































Download as pdf or txt
You might also like
- AWS NotesDocument32 pagesAWS Notespavankalluri100% (6)
- EXAMREVIEW AWSCertification CloudPractitionerDocument116 pagesEXAMREVIEW AWSCertification CloudPractitionerBitirme Tezi100% (1)
- 902, 906, & 908 Compact Wheel Loader Electrical System: Machine Harness Connector and Component LocationsDocument2 pages902, 906, & 908 Compact Wheel Loader Electrical System: Machine Harness Connector and Component Locationsait mimouneNo ratings yet
- 170 Using Storage Classes To Dynamically Provision Persistent VolumesDocument7 pages170 Using Storage Classes To Dynamically Provision Persistent VolumesAjay SinghNo ratings yet
- Amazon ECS - Free AWS Cheat SheetsDocument20 pagesAmazon ECS - Free AWS Cheat Sheetsmoon walkerNo ratings yet
- How To Design and Provision A Production-Ready EKS Cluster: Image Credit: PixabayDocument11 pagesHow To Design and Provision A Production-Ready EKS Cluster: Image Credit: Pixabaycentinel29No ratings yet
- Amazon Web Services NotesDocument37 pagesAmazon Web Services NotesTarun100% (6)
- Advance AWS InterviewquestionsDocument39 pagesAdvance AWS InterviewquestionsZubair AhmadNo ratings yet
- AWS Overview Concepts EC2Document22 pagesAWS Overview Concepts EC2Mohammad MazheruddinNo ratings yet
- Pitc Aws Chapter 8Document66 pagesPitc Aws Chapter 8Mangesh AbnaveNo ratings yet
- Cs264 Intro To Cloud ComputingDocument42 pagesCs264 Intro To Cloud ComputingnorfolktexNo ratings yet
- Elastic Block Store (Amazon EBS)Document29 pagesElastic Block Store (Amazon EBS)hanuman challisaNo ratings yet
- Docker Terraform Amazon ECS: A Quick Intro ToDocument98 pagesDocker Terraform Amazon ECS: A Quick Intro ToDodo winyNo ratings yet
- EKS Forensics & Incident ResponseDocument10 pagesEKS Forensics & Incident Responsechristopher.d.domanNo ratings yet
- What Is Elastic Block Store?Document11 pagesWhat Is Elastic Block Store?kanmaniprsnlNo ratings yet
- Aws Odd Interview QuestionsDocument36 pagesAws Odd Interview QuestionsZubair AhmadNo ratings yet
- AWS EC2 QuizDocument7 pagesAWS EC2 QuizsrihbkpNo ratings yet
- Storage - KubernetesDocument76 pagesStorage - KubernetesFantahun FkadieNo ratings yet
- 2 AWS StorageDocument16 pages2 AWS StorageAslam AnsariNo ratings yet
- Exam Quick RefrenceDocument16 pagesExam Quick RefrencesamalparthaNo ratings yet
- UntitledDocument39 pagesUntitledJoe RodriguezNo ratings yet
- Amazon EBS For MeetingDocument8 pagesAmazon EBS For MeetingSuraj KumarNo ratings yet
- Azure Data Engineer GuideDocument87 pagesAzure Data Engineer GuideEdiga VenkatadriNo ratings yet
- CH 01Document18 pagesCH 01sameo13No ratings yet
- Experiment 3 Introduction To Amazon Elastic Container ServiceDocument9 pagesExperiment 3 Introduction To Amazon Elastic Container ServicevamsiNo ratings yet
- CH 03Document14 pagesCH 03sameo13No ratings yet
- Dp203 NotesDocument87 pagesDp203 Notesİbrahim SezenNo ratings yet
- 168 Verifying The State Persistence and Exploring The FailuresDocument5 pages168 Verifying The State Persistence and Exploring The FailuresAjay SinghNo ratings yet
- Amazon ECS Lab1Document19 pagesAmazon ECS Lab1biswajitmohanty8260No ratings yet
- Build EKS Cluster With Terraform. A Simple Infrastructure-As-Code Way - by Nico Singh - Sep, 2020 - ITNEXTDocument19 pagesBuild EKS Cluster With Terraform. A Simple Infrastructure-As-Code Way - by Nico Singh - Sep, 2020 - ITNEXTaaaa100% (1)
- How To Attach and Mount An EBS Volume To EC2 Linux InstanceDocument12 pagesHow To Attach and Mount An EBS Volume To EC2 Linux Instancejai kumarNo ratings yet
- Aws Storage SolutionsDocument8 pagesAws Storage SolutionsHitesh KatariyaNo ratings yet
- 01-AZ-300T01-M2Document49 pages01-AZ-300T01-M2myrizwan807No ratings yet
- Intro To Amazon ECS: Abby Fuller, AWS @abbyfullerDocument32 pagesIntro To Amazon ECS: Abby Fuller, AWS @abbyfullerAditya GangulyNo ratings yet
- Project Hosting On AWS EKSDocument13 pagesProject Hosting On AWS EKSSreenath GNo ratings yet
- Lab 1.1 - AWS Academy Learner Lab - Associate ServicesDocument5 pagesLab 1.1 - AWS Academy Learner Lab - Associate ServicesCong Yue LimNo ratings yet
- Optimizing MySQL On AmazonDocument36 pagesOptimizing MySQL On Amazonpark hyoNo ratings yet
- Red Hat StorageDocument19 pagesRed Hat Storagejasper michaelsNo ratings yet
- AWS Services For Devops EngineerDocument6 pagesAWS Services For Devops Engineersathyanarayana medaNo ratings yet
- 3.amazon EBS PDFDocument17 pages3.amazon EBS PDFbiswajit patrasecNo ratings yet
- EU 22 Noam Moshe JS ON Security OffDocument72 pagesEU 22 Noam Moshe JS ON Security OffhumanNo ratings yet
- Case Study: Amazon AWS: CSE 40822 - Cloud Computing Prof. Douglas Thain University of Notre DameDocument33 pagesCase Study: Amazon AWS: CSE 40822 - Cloud Computing Prof. Douglas Thain University of Notre Dameawslab8No ratings yet
- Sample Q and ADocument47 pagesSample Q and AHareesha N G100% (1)
- Lab 03b - Manage Azure Resources by Using ARM Templates Student Lab ManualDocument3 pagesLab 03b - Manage Azure Resources by Using ARM Templates Student Lab ManualNoor HabibNo ratings yet
- AWS S3 Interview QuestionsDocument23 pagesAWS S3 Interview QuestionsNitin GordeNo ratings yet
- Questions AwsDocument2 pagesQuestions AwsABHI_NITTENo ratings yet
- VM OvsDocument9 pagesVM OvsdesertcoderNo ratings yet
- Datadog AWSeBook ContainerizedApplicationsDocument44 pagesDatadog AWSeBook ContainerizedApplicationsmars9990No ratings yet
- ClusteringDocument21 pagesClusteringनरेन्द्र मथुरियाNo ratings yet
- How To Configure Two Node High Availability Cluster On RHELDocument18 pagesHow To Configure Two Node High Availability Cluster On RHELslides courseNo ratings yet
- Devops Interview QDocument9 pagesDevops Interview Qindigo itNo ratings yet
- Oracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qDocument49 pagesOracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qLuis AlfredoNo ratings yet
- NodeJs Basics PracticeDocument9 pagesNodeJs Basics Practiceunofficialartist3No ratings yet
- 06 - EBS LabDocument6 pages06 - EBS LabFelipe DuqueNo ratings yet
- AWS Sysops PDFDocument138 pagesAWS Sysops PDFSayed EldawyNo ratings yet
- ECS Forensics & Incident ResponseDocument7 pagesECS Forensics & Incident Responsechristopher.d.domanNo ratings yet
- Ansible ModulesDocument12 pagesAnsible ModulesjayNo ratings yet
- 6 StorageDocument12 pages6 StoragePravin RaiNo ratings yet
- Aws Recon Webinar MaterialDocument52 pagesAws Recon Webinar MaterialManas RanjanNo ratings yet
- Openstack Ceph AdminDocument168 pagesOpenstack Ceph Adminayfbjj37832khNo ratings yet
- Definitive Guide Robot Welding Torches v1.0Document50 pagesDefinitive Guide Robot Welding Torches v1.0AlexgriNo ratings yet
- SECTEC AI WIFI YCC365 PLUS Camera Pricelist201906Document5 pagesSECTEC AI WIFI YCC365 PLUS Camera Pricelist201906Glenn JattanNo ratings yet
- Fortran CF DDocument160 pagesFortran CF DLahcen AkerkouchNo ratings yet
- Techniques For Collection, Isolation and Preservation of MicroorganismsDocument42 pagesTechniques For Collection, Isolation and Preservation of Microorganismsaziskf100% (2)
- prEN 12390-11 - DRAFTDocument32 pagesprEN 12390-11 - DRAFTCarlos GilNo ratings yet
- Audi s6 2007 5.2l ManualDocument374 pagesAudi s6 2007 5.2l ManualMisael EspañaNo ratings yet
- 6-Büşra BahatDocument4 pages6-Büşra BahatAYŞE NURNo ratings yet
- Soft Computing Module IDocument161 pagesSoft Computing Module INatarajanSubramanyamNo ratings yet
- 5 MuscleDocument3 pages5 MuscleNicolePorsueloNo ratings yet
- Introduction To Privatisation and Liberalisation in India: by Anmol SharmaDocument10 pagesIntroduction To Privatisation and Liberalisation in India: by Anmol SharmaAnmol SharmaNo ratings yet
- 42pt250b Manual ServicioDocument63 pages42pt250b Manual ServicioLuis Carlos Bonilla AldanaNo ratings yet
- Kaong PaperDocument10 pagesKaong PapermikxendyNo ratings yet
- Te 243684Document57 pagesTe 243684infoNo ratings yet
- Linear AlgebraDocument395 pagesLinear AlgebraRehan Javed100% (2)
- Department of Education: Republic of The PhilippinesDocument3 pagesDepartment of Education: Republic of The PhilippinesRhenalyn Rose Obligar PasaholNo ratings yet
- SteelDocument61 pagesSteelSonNguyenNo ratings yet
- Soal OkeDocument12 pagesSoal OkefredyNo ratings yet
- Womb World Mandala Reflections of The BuDocument11 pagesWomb World Mandala Reflections of The BuLenka MladenovićNo ratings yet
- ASHRAE-tables Lighting Power Density PDFDocument3 pagesASHRAE-tables Lighting Power Density PDFDan MolloyNo ratings yet
- GR8313 GrenergyDocument9 pagesGR8313 GrenergyAngel Luis Aquino GonzalezNo ratings yet
- 31-SDMS-03 Low Voltage Cabinet For. Pole Mounted Transformer PDFDocument20 pages31-SDMS-03 Low Voltage Cabinet For. Pole Mounted Transformer PDFMehdi SalahNo ratings yet
- Dialysis - Purpose, Types, Risks, and MoreDocument13 pagesDialysis - Purpose, Types, Risks, and MoreTino HelaNo ratings yet
- The Myth of PlutoDocument6 pagesThe Myth of PlutoZsuzsanna ZöldNo ratings yet
- Pharmaceutics 14 02240Document17 pagesPharmaceutics 14 02240oliverasrommelNo ratings yet
- Substation Construction and CommissioningDocument83 pagesSubstation Construction and CommissioningShung Tak ChanNo ratings yet
- ENS 195 - Pollution and Environmental HealthDocument54 pagesENS 195 - Pollution and Environmental HealthEdcel ZabalaNo ratings yet
- Logic Pro X Cheat Sheet (Atajos)Document14 pagesLogic Pro X Cheat Sheet (Atajos)Nazareno AltamiranoNo ratings yet
- Pdf&rendition 1Document61 pagesPdf&rendition 1Dulce DeNo ratings yet
- Lung Sounds Auscultation - 1Document3 pagesLung Sounds Auscultation - 1George BarajazNo ratings yet