
2022.dravidianlangtech 1.44
2022.dravidianlangtech 1.44
You might also like
- 2023 Dravidianlangtech-1 11Document8 pages2023 Dravidianlangtech-1 11natarajankr9750No ratings yet
- 1 s2.0 S2949719123000031 MainDocument17 pages1 s2.0 S2949719123000031 MainVishal KhardeNo ratings yet
- Overview of The HASOC Subtrack at FIRE 2021 Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages-T1-1Document19 pagesOverview of The HASOC Subtrack at FIRE 2021 Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages-T1-1Arup BaruahNo ratings yet
- Social Media Text Analytics of Malayalam - English Code Mixed Using Deep LearningDocument25 pagesSocial Media Text Analytics of Malayalam - English Code Mixed Using Deep Learningpsanoop2023No ratings yet
- 15056-Article Text-44992-2-10-20210906Document15 pages15056-Article Text-44992-2-10-20210906Marcel YapNo ratings yet
- 2020.icon Demos.9Document2 pages2020.icon Demos.9Yitayew TegodNo ratings yet
- Detecting Offensive Language in English, Hindi, and Marathi Using Classical Supervised Machine Learning Methods and Word/Char N-GramsDocument7 pagesDetecting Offensive Language in English, Hindi, and Marathi Using Classical Supervised Machine Learning Methods and Word/Char N-GramsgoosexsillyNo ratings yet
- FIRE Track ProposalDocument4 pagesFIRE Track ProposalPrasenjit MajumderNo ratings yet
- 2022 Dravidianlangtech-1 35Document6 pages2022 Dravidianlangtech-1 35yaqubaliyevafidanNo ratings yet
- Psuarcaya,+14767 19290 1 SM - 53 61Document9 pagesPsuarcaya,+14767 19290 1 SM - 53 61Adenins GroupNo ratings yet
- Hate Speech Detection On Indonesian Text Using Word Embedding Method-Global VectorDocument10 pagesHate Speech Detection On Indonesian Text Using Word Embedding Method-Global VectorIAES IJAINo ratings yet
- Ajol-File-Journals 624 Articles 265688 65dafbb3438d2Document15 pagesAjol-File-Journals 624 Articles 265688 65dafbb3438d2TEKLE ABEBENo ratings yet
- Speech Technologies and The Assessment of Second Language Speaking Approaches Challenges and OpportunitiesDocument17 pagesSpeech Technologies and The Assessment of Second Language Speaking Approaches Challenges and Opportunitiesleio.wuNo ratings yet
- Issues and Challenges in OpinionDocument7 pagesIssues and Challenges in Opinionpritijadhao.classNo ratings yet
- TweetsDocument12 pagesTweetsPoorna VermaNo ratings yet
- Rbipa: An Algorithm For Iterative Stemming of Tamil Language TextsDocument9 pagesRbipa: An Algorithm For Iterative Stemming of Tamil Language TextsDarrenNo ratings yet
- RBIPA: An Algorithm For Iterative Stemming of Tamil Language TextsDocument9 pagesRBIPA: An Algorithm For Iterative Stemming of Tamil Language TextsDarrenNo ratings yet
- Deep Learning-Based Language Identification in English-Hindi-Bengali Code-Mixed Social Media CorporaDocument10 pagesDeep Learning-Based Language Identification in English-Hindi-Bengali Code-Mixed Social Media CorporaApp SoulsNo ratings yet
- Lit Man 2018Document17 pagesLit Man 2018Binkei TzuyuNo ratings yet
- Code Mixing: A Challenge For Language Identification in The Language of Social MediaDocument11 pagesCode Mixing: A Challenge For Language Identification in The Language of Social MediaDevi AgustiniNo ratings yet
- Motivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HDocument42 pagesMotivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HAdibah AliasNo ratings yet
- Review of Related LiteratureDocument65 pagesReview of Related LiteratureAndhika A. Setiyono100% (1)
- Multi-Label Classification of Indonesian Hate Speech On Twitter Using Support Vector MachinesDocument7 pagesMulti-Label Classification of Indonesian Hate Speech On Twitter Using Support Vector MachinesbejowatukNo ratings yet
- Motivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HDocument42 pagesMotivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HbalureddykNo ratings yet
- 2022 Lrec-1 704Document7 pages2022 Lrec-1 704eahambaram. s.e.BharatNo ratings yet
- Technology Use in Collegiate Foreign Language Programs: Arizona Working Papers (AWP) Volume 25, 2018Document27 pagesTechnology Use in Collegiate Foreign Language Programs: Arizona Working Papers (AWP) Volume 25, 2018Paulina-No ratings yet
- Final Conference SubmissionDocument9 pagesFinal Conference SubmissionKunal KumarNo ratings yet
- One To Rule Them All: Towards Joint Indic Language Hate Speech DetectionDocument13 pagesOne To Rule Them All: Towards Joint Indic Language Hate Speech Detectionmehar bhatiaNo ratings yet
- Roman Urdu News Headline Classification Empowered With Machine LearningDocument16 pagesRoman Urdu News Headline Classification Empowered With Machine LearningDildar HussainNo ratings yet
- Discourse Markers in Journalism: A Case in Compostela Valley State College-MaragusanDocument12 pagesDiscourse Markers in Journalism: A Case in Compostela Valley State College-MaragusanIJELS Research JournalNo ratings yet
- Overview of The HASOC Subtrack at FIRE 2022 Identification of Conversational Hate-Speech in Hindi-English Code-Mixed and German Language-T7-1Document14 pagesOverview of The HASOC Subtrack at FIRE 2022 Identification of Conversational Hate-Speech in Hindi-English Code-Mixed and German Language-T7-1Arup BaruahNo ratings yet
- Language Choice and Language Use Patterns Among TeDocument12 pagesLanguage Choice and Language Use Patterns Among TeJayan NairNo ratings yet
- Overview of EmoThreat: Emotions and Threat Detection in Urdu at FIRE 2022-T4-1Document11 pagesOverview of EmoThreat: Emotions and Threat Detection in Urdu at FIRE 2022-T4-1Arup BaruahNo ratings yet
- A Systematic Review of Second Language Learning Trends and SuggestionsDocument18 pagesA Systematic Review of Second Language Learning Trends and SuggestionsYani KhalidNo ratings yet
- ICES Karaoke 2006Document11 pagesICES Karaoke 2006lalap72411No ratings yet
- Analisis de Sentimientos MultilingueDocument17 pagesAnalisis de Sentimientos MultilingueMiguel Angel PerezNo ratings yet
- This Content Downloaded From 202.92.130.115 On Wed, 03 May 2023 08:52:33 +00:00Document11 pagesThis Content Downloaded From 202.92.130.115 On Wed, 03 May 2023 08:52:33 +00:00Eon LandellNo ratings yet
- 465-Article Text-2977-4-10-20230908Document11 pages465-Article Text-2977-4-10-20230908Indra TjahyadiNo ratings yet
- PT 2Document11 pagesPT 2chinh ho trongNo ratings yet
- Exploring Amharic Sentiment Analysis From Social Media Texts: Building Annotation Tools and Classification ModelsDocument13 pagesExploring Amharic Sentiment Analysis From Social Media Texts: Building Annotation Tools and Classification Modelsbalj balhNo ratings yet
- 2022 Sigul-1 18Document9 pages2022 Sigul-1 18Defa ChaliNo ratings yet
- Gender and Language (Communication Apprehension in Second Language Learning)Document7 pagesGender and Language (Communication Apprehension in Second Language Learning)College PresidentNo ratings yet
- Paper 634Document3 pagesPaper 634Rohidas NitondeNo ratings yet
- Incorporating Sign Language To An Inclusive Classroom Setting A Meta-SynthesisDocument9 pagesIncorporating Sign Language To An Inclusive Classroom Setting A Meta-SynthesisIJRASETPublicationsNo ratings yet
- 03 Vasiliou Et AlDocument14 pages03 Vasiliou Et Almathpix2525No ratings yet
- AdalyaDocument10 pagesAdalyaSana IsamNo ratings yet
- Literature ReviewDocument7 pagesLiterature ReviewMuhammad NabeelNo ratings yet
- Nur Ain Hasma - 230025301040Document16 pagesNur Ain Hasma - 230025301040Nur Ain HasmaNo ratings yet
- The Effectiveness of Educational Technology Applications On Adult English Language Learners Writing Quality A Meta AnalysisDocument32 pagesThe Effectiveness of Educational Technology Applications On Adult English Language Learners Writing Quality A Meta Analysisvaheya9919No ratings yet
- A Transfer Learning Framework For Sentiment Analysis in Indian VernacularsDocument9 pagesA Transfer Learning Framework For Sentiment Analysis in Indian VernacularsKunal KumarNo ratings yet
- Abusive Language and Hate Speech Detection For Javanese andDocument5 pagesAbusive Language and Hate Speech Detection For Javanese andtripratiwi4586No ratings yet
- Improving Speaking Fluency Through 4/3/2 Technique and Self-AssessmentDocument14 pagesImproving Speaking Fluency Through 4/3/2 Technique and Self-AssessmentRabiya JannazarovaNo ratings yet
- Effectiveness of Using Multimodal Approaches in Teaching and Learning Listening and Speaking SkillsDocument22 pagesEffectiveness of Using Multimodal Approaches in Teaching and Learning Listening and Speaking SkillsAnnisa JannahNo ratings yet
- Detecting Offensive Tweets in Hindi-English Code-Switched Language-W18-3504Document9 pagesDetecting Offensive Tweets in Hindi-English Code-Switched Language-W18-3504Arup BaruahNo ratings yet
- GondiDocument7 pagesGondiEnvironment bellampalliNo ratings yet
- SECOND Language AcquisitionDocument14 pagesSECOND Language AcquisitionMacarena AcevedoNo ratings yet
- Written Communication in International Business Specific ConcernsDocument6 pagesWritten Communication in International Business Specific ConcernsVaibhav TateNo ratings yet
- Second Language Speaking Anxiety Among Malaysian Postgraduate Students at A Faculty ofDocument8 pagesSecond Language Speaking Anxiety Among Malaysian Postgraduate Students at A Faculty ofNur Nabila Natasya RazifNo ratings yet
- Indian Language Speech Database A ReviewDocument6 pagesIndian Language Speech Database A ReviewVR IndaNo ratings yet
- IJNRD2304119Document5 pagesIJNRD2304119natarajankr9750No ratings yet
- 2020 Wildre-1 8Document6 pages2020 Wildre-1 8natarajankr9750No ratings yet
- Deep Learning Based Sentiment Analysis For Malayalam, Tamil and Kannada LanguagesDocument9 pagesDeep Learning Based Sentiment Analysis For Malayalam, Tamil and Kannada Languagesnatarajankr9750No ratings yet
- Ce (Ad) F (SK) PF1 (Ag KM) PN (KM)Document5 pagesCe (Ad) F (SK) PF1 (Ag KM) PN (KM)natarajankr9750No ratings yet
- Stock and InventoryDocument2 pagesStock and Inventorynatarajankr9750No ratings yet
- Rules For Subject - Verb Agreement Are As Follows:: Boy BoyDocument37 pagesRules For Subject - Verb Agreement Are As Follows:: Boy BoyKumaresan RamalingamNo ratings yet
- Project Management AssignmentDocument6 pagesProject Management AssignmentNishiket DharmikNo ratings yet
- Course Title Understanding Culture, Society, & Politics Instructor Mieca Aguinaldo Course Code Course DescriptionDocument6 pagesCourse Title Understanding Culture, Society, & Politics Instructor Mieca Aguinaldo Course Code Course DescriptionSJHC 21No ratings yet
- Manual de Morocha WGT3300SQDocument36 pagesManual de Morocha WGT3300SQBeatrich PalellaNo ratings yet
- Ce24 Lesson 2Document63 pagesCe24 Lesson 2movieboxpro482No ratings yet
- IELTS Advantage Reading SkillsDocument153 pagesIELTS Advantage Reading SkillsĐặng Minh QuânNo ratings yet
- FUTURE MegoldásokDocument4 pagesFUTURE MegoldásokNikolett SzövőNo ratings yet
- Function of The Criticism by TS EliotDocument18 pagesFunction of The Criticism by TS EliotRISHIKA SINHANo ratings yet
- Kariuki, Alex K - Impact of Information Technology On Organizational Performance Case of Population Services KenyaDocument52 pagesKariuki, Alex K - Impact of Information Technology On Organizational Performance Case of Population Services KenyaJack JaviNo ratings yet
- DevOcc Middle Childhood and Education NotesDocument5 pagesDevOcc Middle Childhood and Education NotesRidz FNo ratings yet
- Medicinal Benefits of HoneyDocument8 pagesMedicinal Benefits of HoneyTauseef AshrafNo ratings yet
- Dorsett Golden ApplesDocument8 pagesDorsett Golden ApplesAndre nicholsNo ratings yet
- Tauck Australia Expands: WeeklyDocument3 pagesTauck Australia Expands: WeeklycruiseweeklyNo ratings yet
- Sample Diary Curriculum Map SUBJECT: Mathematics QUARTER: Second Grade Level: 10 TOPIC: CircleDocument3 pagesSample Diary Curriculum Map SUBJECT: Mathematics QUARTER: Second Grade Level: 10 TOPIC: CircleRichimon LicerioNo ratings yet
- Reviewer For Statcon QuizDocument18 pagesReviewer For Statcon QuizShella Hannah SalihNo ratings yet
- Microsoft Power Point - Organsiational Culture MSC Revised 1010Document6 pagesMicrosoft Power Point - Organsiational Culture MSC Revised 1010mattstewartis9589No ratings yet
- Surgical Technique: Available in Titanium and Stainless SteelDocument53 pagesSurgical Technique: Available in Titanium and Stainless SteelJorge Trinidad de la CruzNo ratings yet
- Angela's Infantwear and Accessories: InvoiceDocument1 pageAngela's Infantwear and Accessories: InvoiceAngelas InfantwearNo ratings yet
- Chapter04.pdf - How To Write A Project Report - ResearchDocument8 pagesChapter04.pdf - How To Write A Project Report - Researchbrownsugar26No ratings yet
- Online Class Student GuidelinesDocument12 pagesOnline Class Student GuidelinesElaine Fiona Villafuerte100% (1)
- Document Analysis Worksheet: Analyze A PaintingDocument4 pagesDocument Analysis Worksheet: Analyze A PaintingPatrick SanchezNo ratings yet
- 78-2017ernakulam, KannurDocument13 pages78-2017ernakulam, KannurBingo MeNo ratings yet
- IELTS Writing task 1 - Tổng hợp bài mẫu band 9 PDFDocument32 pagesIELTS Writing task 1 - Tổng hợp bài mẫu band 9 PDFVũ NguyễnNo ratings yet
- Research Paper of Vacuum Braking SystemDocument8 pagesResearch Paper of Vacuum Braking Systemwkzcoprhf100% (1)
- Rego Multiport A8574AGDocument2 pagesRego Multiport A8574AGCristobal CherigoNo ratings yet
- Hasil SKD Publish (Ok) 3Document60 pagesHasil SKD Publish (Ok) 3SolahudinNo ratings yet
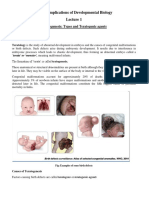
- Unit 5: Implications of Developmental Biology: Teratogenesis: Types and Teratogenic AgentsDocument12 pagesUnit 5: Implications of Developmental Biology: Teratogenesis: Types and Teratogenic AgentsAmar Kant JhaNo ratings yet
- Boq - Secuity House at IbewaDocument4 pagesBoq - Secuity House at IbewaAugustine BelieveNo ratings yet
- Bhutan Alternatives Competitive Advantage CCCDocument5 pagesBhutan Alternatives Competitive Advantage CCCSonam LodayNo ratings yet
- Submission Deadline: Week 9 (60%) : StepsDocument23 pagesSubmission Deadline: Week 9 (60%) : StepsRaja NomanNo ratings yet





























































































Download as pdf or txt
You might also like
- 2023 Dravidianlangtech-1 11Document8 pages2023 Dravidianlangtech-1 11natarajankr9750No ratings yet
- 1 s2.0 S2949719123000031 MainDocument17 pages1 s2.0 S2949719123000031 MainVishal KhardeNo ratings yet
- Overview of The HASOC Subtrack at FIRE 2021 Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages-T1-1Document19 pagesOverview of The HASOC Subtrack at FIRE 2021 Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages-T1-1Arup BaruahNo ratings yet
- Social Media Text Analytics of Malayalam - English Code Mixed Using Deep LearningDocument25 pagesSocial Media Text Analytics of Malayalam - English Code Mixed Using Deep Learningpsanoop2023No ratings yet
- 15056-Article Text-44992-2-10-20210906Document15 pages15056-Article Text-44992-2-10-20210906Marcel YapNo ratings yet
- 2020.icon Demos.9Document2 pages2020.icon Demos.9Yitayew TegodNo ratings yet
- Detecting Offensive Language in English, Hindi, and Marathi Using Classical Supervised Machine Learning Methods and Word/Char N-GramsDocument7 pagesDetecting Offensive Language in English, Hindi, and Marathi Using Classical Supervised Machine Learning Methods and Word/Char N-GramsgoosexsillyNo ratings yet
- FIRE Track ProposalDocument4 pagesFIRE Track ProposalPrasenjit MajumderNo ratings yet
- 2022 Dravidianlangtech-1 35Document6 pages2022 Dravidianlangtech-1 35yaqubaliyevafidanNo ratings yet
- Psuarcaya,+14767 19290 1 SM - 53 61Document9 pagesPsuarcaya,+14767 19290 1 SM - 53 61Adenins GroupNo ratings yet
- Hate Speech Detection On Indonesian Text Using Word Embedding Method-Global VectorDocument10 pagesHate Speech Detection On Indonesian Text Using Word Embedding Method-Global VectorIAES IJAINo ratings yet
- Ajol-File-Journals 624 Articles 265688 65dafbb3438d2Document15 pagesAjol-File-Journals 624 Articles 265688 65dafbb3438d2TEKLE ABEBENo ratings yet
- Speech Technologies and The Assessment of Second Language Speaking Approaches Challenges and OpportunitiesDocument17 pagesSpeech Technologies and The Assessment of Second Language Speaking Approaches Challenges and Opportunitiesleio.wuNo ratings yet
- Issues and Challenges in OpinionDocument7 pagesIssues and Challenges in Opinionpritijadhao.classNo ratings yet
- TweetsDocument12 pagesTweetsPoorna VermaNo ratings yet
- Rbipa: An Algorithm For Iterative Stemming of Tamil Language TextsDocument9 pagesRbipa: An Algorithm For Iterative Stemming of Tamil Language TextsDarrenNo ratings yet
- RBIPA: An Algorithm For Iterative Stemming of Tamil Language TextsDocument9 pagesRBIPA: An Algorithm For Iterative Stemming of Tamil Language TextsDarrenNo ratings yet
- Deep Learning-Based Language Identification in English-Hindi-Bengali Code-Mixed Social Media CorporaDocument10 pagesDeep Learning-Based Language Identification in English-Hindi-Bengali Code-Mixed Social Media CorporaApp SoulsNo ratings yet
- Lit Man 2018Document17 pagesLit Man 2018Binkei TzuyuNo ratings yet
- Code Mixing: A Challenge For Language Identification in The Language of Social MediaDocument11 pagesCode Mixing: A Challenge For Language Identification in The Language of Social MediaDevi AgustiniNo ratings yet
- Motivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HDocument42 pagesMotivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HAdibah AliasNo ratings yet
- Review of Related LiteratureDocument65 pagesReview of Related LiteratureAndhika A. Setiyono100% (1)
- Multi-Label Classification of Indonesian Hate Speech On Twitter Using Support Vector MachinesDocument7 pagesMulti-Label Classification of Indonesian Hate Speech On Twitter Using Support Vector MachinesbejowatukNo ratings yet
- Motivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HDocument42 pagesMotivation and Willingness To Communicate As Predictors of Reported L2 Use: The Japanese Esl Context Y HbalureddykNo ratings yet
- 2022 Lrec-1 704Document7 pages2022 Lrec-1 704eahambaram. s.e.BharatNo ratings yet
- Technology Use in Collegiate Foreign Language Programs: Arizona Working Papers (AWP) Volume 25, 2018Document27 pagesTechnology Use in Collegiate Foreign Language Programs: Arizona Working Papers (AWP) Volume 25, 2018Paulina-No ratings yet
- Final Conference SubmissionDocument9 pagesFinal Conference SubmissionKunal KumarNo ratings yet
- One To Rule Them All: Towards Joint Indic Language Hate Speech DetectionDocument13 pagesOne To Rule Them All: Towards Joint Indic Language Hate Speech Detectionmehar bhatiaNo ratings yet
- Roman Urdu News Headline Classification Empowered With Machine LearningDocument16 pagesRoman Urdu News Headline Classification Empowered With Machine LearningDildar HussainNo ratings yet
- Discourse Markers in Journalism: A Case in Compostela Valley State College-MaragusanDocument12 pagesDiscourse Markers in Journalism: A Case in Compostela Valley State College-MaragusanIJELS Research JournalNo ratings yet
- Overview of The HASOC Subtrack at FIRE 2022 Identification of Conversational Hate-Speech in Hindi-English Code-Mixed and German Language-T7-1Document14 pagesOverview of The HASOC Subtrack at FIRE 2022 Identification of Conversational Hate-Speech in Hindi-English Code-Mixed and German Language-T7-1Arup BaruahNo ratings yet
- Language Choice and Language Use Patterns Among TeDocument12 pagesLanguage Choice and Language Use Patterns Among TeJayan NairNo ratings yet
- Overview of EmoThreat: Emotions and Threat Detection in Urdu at FIRE 2022-T4-1Document11 pagesOverview of EmoThreat: Emotions and Threat Detection in Urdu at FIRE 2022-T4-1Arup BaruahNo ratings yet
- A Systematic Review of Second Language Learning Trends and SuggestionsDocument18 pagesA Systematic Review of Second Language Learning Trends and SuggestionsYani KhalidNo ratings yet
- ICES Karaoke 2006Document11 pagesICES Karaoke 2006lalap72411No ratings yet
- Analisis de Sentimientos MultilingueDocument17 pagesAnalisis de Sentimientos MultilingueMiguel Angel PerezNo ratings yet
- This Content Downloaded From 202.92.130.115 On Wed, 03 May 2023 08:52:33 +00:00Document11 pagesThis Content Downloaded From 202.92.130.115 On Wed, 03 May 2023 08:52:33 +00:00Eon LandellNo ratings yet
- 465-Article Text-2977-4-10-20230908Document11 pages465-Article Text-2977-4-10-20230908Indra TjahyadiNo ratings yet
- PT 2Document11 pagesPT 2chinh ho trongNo ratings yet
- Exploring Amharic Sentiment Analysis From Social Media Texts: Building Annotation Tools and Classification ModelsDocument13 pagesExploring Amharic Sentiment Analysis From Social Media Texts: Building Annotation Tools and Classification Modelsbalj balhNo ratings yet
- 2022 Sigul-1 18Document9 pages2022 Sigul-1 18Defa ChaliNo ratings yet
- Gender and Language (Communication Apprehension in Second Language Learning)Document7 pagesGender and Language (Communication Apprehension in Second Language Learning)College PresidentNo ratings yet
- Paper 634Document3 pagesPaper 634Rohidas NitondeNo ratings yet
- Incorporating Sign Language To An Inclusive Classroom Setting A Meta-SynthesisDocument9 pagesIncorporating Sign Language To An Inclusive Classroom Setting A Meta-SynthesisIJRASETPublicationsNo ratings yet
- 03 Vasiliou Et AlDocument14 pages03 Vasiliou Et Almathpix2525No ratings yet
- AdalyaDocument10 pagesAdalyaSana IsamNo ratings yet
- Literature ReviewDocument7 pagesLiterature ReviewMuhammad NabeelNo ratings yet
- Nur Ain Hasma - 230025301040Document16 pagesNur Ain Hasma - 230025301040Nur Ain HasmaNo ratings yet
- The Effectiveness of Educational Technology Applications On Adult English Language Learners Writing Quality A Meta AnalysisDocument32 pagesThe Effectiveness of Educational Technology Applications On Adult English Language Learners Writing Quality A Meta Analysisvaheya9919No ratings yet
- A Transfer Learning Framework For Sentiment Analysis in Indian VernacularsDocument9 pagesA Transfer Learning Framework For Sentiment Analysis in Indian VernacularsKunal KumarNo ratings yet
- Abusive Language and Hate Speech Detection For Javanese andDocument5 pagesAbusive Language and Hate Speech Detection For Javanese andtripratiwi4586No ratings yet
- Improving Speaking Fluency Through 4/3/2 Technique and Self-AssessmentDocument14 pagesImproving Speaking Fluency Through 4/3/2 Technique and Self-AssessmentRabiya JannazarovaNo ratings yet
- Effectiveness of Using Multimodal Approaches in Teaching and Learning Listening and Speaking SkillsDocument22 pagesEffectiveness of Using Multimodal Approaches in Teaching and Learning Listening and Speaking SkillsAnnisa JannahNo ratings yet
- Detecting Offensive Tweets in Hindi-English Code-Switched Language-W18-3504Document9 pagesDetecting Offensive Tweets in Hindi-English Code-Switched Language-W18-3504Arup BaruahNo ratings yet
- GondiDocument7 pagesGondiEnvironment bellampalliNo ratings yet
- SECOND Language AcquisitionDocument14 pagesSECOND Language AcquisitionMacarena AcevedoNo ratings yet
- Written Communication in International Business Specific ConcernsDocument6 pagesWritten Communication in International Business Specific ConcernsVaibhav TateNo ratings yet
- Second Language Speaking Anxiety Among Malaysian Postgraduate Students at A Faculty ofDocument8 pagesSecond Language Speaking Anxiety Among Malaysian Postgraduate Students at A Faculty ofNur Nabila Natasya RazifNo ratings yet
- Indian Language Speech Database A ReviewDocument6 pagesIndian Language Speech Database A ReviewVR IndaNo ratings yet
- IJNRD2304119Document5 pagesIJNRD2304119natarajankr9750No ratings yet
- 2020 Wildre-1 8Document6 pages2020 Wildre-1 8natarajankr9750No ratings yet
- Deep Learning Based Sentiment Analysis For Malayalam, Tamil and Kannada LanguagesDocument9 pagesDeep Learning Based Sentiment Analysis For Malayalam, Tamil and Kannada Languagesnatarajankr9750No ratings yet
- Ce (Ad) F (SK) PF1 (Ag KM) PN (KM)Document5 pagesCe (Ad) F (SK) PF1 (Ag KM) PN (KM)natarajankr9750No ratings yet
- Stock and InventoryDocument2 pagesStock and Inventorynatarajankr9750No ratings yet
- Rules For Subject - Verb Agreement Are As Follows:: Boy BoyDocument37 pagesRules For Subject - Verb Agreement Are As Follows:: Boy BoyKumaresan RamalingamNo ratings yet
- Project Management AssignmentDocument6 pagesProject Management AssignmentNishiket DharmikNo ratings yet
- Course Title Understanding Culture, Society, & Politics Instructor Mieca Aguinaldo Course Code Course DescriptionDocument6 pagesCourse Title Understanding Culture, Society, & Politics Instructor Mieca Aguinaldo Course Code Course DescriptionSJHC 21No ratings yet
- Manual de Morocha WGT3300SQDocument36 pagesManual de Morocha WGT3300SQBeatrich PalellaNo ratings yet
- Ce24 Lesson 2Document63 pagesCe24 Lesson 2movieboxpro482No ratings yet
- IELTS Advantage Reading SkillsDocument153 pagesIELTS Advantage Reading SkillsĐặng Minh QuânNo ratings yet
- FUTURE MegoldásokDocument4 pagesFUTURE MegoldásokNikolett SzövőNo ratings yet
- Function of The Criticism by TS EliotDocument18 pagesFunction of The Criticism by TS EliotRISHIKA SINHANo ratings yet
- Kariuki, Alex K - Impact of Information Technology On Organizational Performance Case of Population Services KenyaDocument52 pagesKariuki, Alex K - Impact of Information Technology On Organizational Performance Case of Population Services KenyaJack JaviNo ratings yet
- DevOcc Middle Childhood and Education NotesDocument5 pagesDevOcc Middle Childhood and Education NotesRidz FNo ratings yet
- Medicinal Benefits of HoneyDocument8 pagesMedicinal Benefits of HoneyTauseef AshrafNo ratings yet
- Dorsett Golden ApplesDocument8 pagesDorsett Golden ApplesAndre nicholsNo ratings yet
- Tauck Australia Expands: WeeklyDocument3 pagesTauck Australia Expands: WeeklycruiseweeklyNo ratings yet
- Sample Diary Curriculum Map SUBJECT: Mathematics QUARTER: Second Grade Level: 10 TOPIC: CircleDocument3 pagesSample Diary Curriculum Map SUBJECT: Mathematics QUARTER: Second Grade Level: 10 TOPIC: CircleRichimon LicerioNo ratings yet
- Reviewer For Statcon QuizDocument18 pagesReviewer For Statcon QuizShella Hannah SalihNo ratings yet
- Microsoft Power Point - Organsiational Culture MSC Revised 1010Document6 pagesMicrosoft Power Point - Organsiational Culture MSC Revised 1010mattstewartis9589No ratings yet
- Surgical Technique: Available in Titanium and Stainless SteelDocument53 pagesSurgical Technique: Available in Titanium and Stainless SteelJorge Trinidad de la CruzNo ratings yet
- Angela's Infantwear and Accessories: InvoiceDocument1 pageAngela's Infantwear and Accessories: InvoiceAngelas InfantwearNo ratings yet
- Chapter04.pdf - How To Write A Project Report - ResearchDocument8 pagesChapter04.pdf - How To Write A Project Report - Researchbrownsugar26No ratings yet
- Online Class Student GuidelinesDocument12 pagesOnline Class Student GuidelinesElaine Fiona Villafuerte100% (1)
- Document Analysis Worksheet: Analyze A PaintingDocument4 pagesDocument Analysis Worksheet: Analyze A PaintingPatrick SanchezNo ratings yet
- 78-2017ernakulam, KannurDocument13 pages78-2017ernakulam, KannurBingo MeNo ratings yet
- IELTS Writing task 1 - Tổng hợp bài mẫu band 9 PDFDocument32 pagesIELTS Writing task 1 - Tổng hợp bài mẫu band 9 PDFVũ NguyễnNo ratings yet
- Research Paper of Vacuum Braking SystemDocument8 pagesResearch Paper of Vacuum Braking Systemwkzcoprhf100% (1)
- Rego Multiport A8574AGDocument2 pagesRego Multiport A8574AGCristobal CherigoNo ratings yet
- Hasil SKD Publish (Ok) 3Document60 pagesHasil SKD Publish (Ok) 3SolahudinNo ratings yet
- Unit 5: Implications of Developmental Biology: Teratogenesis: Types and Teratogenic AgentsDocument12 pagesUnit 5: Implications of Developmental Biology: Teratogenesis: Types and Teratogenic AgentsAmar Kant JhaNo ratings yet
- Boq - Secuity House at IbewaDocument4 pagesBoq - Secuity House at IbewaAugustine BelieveNo ratings yet
- Bhutan Alternatives Competitive Advantage CCCDocument5 pagesBhutan Alternatives Competitive Advantage CCCSonam LodayNo ratings yet
- Submission Deadline: Week 9 (60%) : StepsDocument23 pagesSubmission Deadline: Week 9 (60%) : StepsRaja NomanNo ratings yet