Download as pdf or txt
You might also like
- Nitinol Af Testing StrategiesDocument5 pagesNitinol Af Testing StrategiesTodd DicksonNo ratings yet
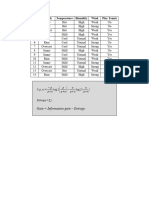
- ID3 Algorithm For Decision TreesDocument16 pagesID3 Algorithm For Decision TreesYiping HuangNo ratings yet
- Digital Performer Keyboard Shortcuts: Function/Task Shortcut Numerical KeypadDocument2 pagesDigital Performer Keyboard Shortcuts: Function/Task Shortcut Numerical Keypadriki1996No ratings yet
- BUSINESS COMMUNICATION Assignment AIMADocument8 pagesBUSINESS COMMUNICATION Assignment AIMAAkash Choudhury67% (6)
- A Step by Step ID3 Decision Tree Example by Niranjan Kumar DasDocument8 pagesA Step by Step ID3 Decision Tree Example by Niranjan Kumar DasNiranjan Kumar DasNo ratings yet
- Decision Tree Calculation For Play ExampleDocument10 pagesDecision Tree Calculation For Play ExampleParthraj SolankiNo ratings yet
- Decision TreeDocument6 pagesDecision TreeshubhNo ratings yet
- Bayes Algorithm: Ex1Document8 pagesBayes Algorithm: Ex1Thao PhamNo ratings yet
- AssignmentDocument1 pageAssignmentProf. Dinesh K VishwakarmaNo ratings yet
- Naive BayesDocument4 pagesNaive Bayesbhavya.purohit81No ratings yet
- Decision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmDocument7 pagesDecision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmMohammad SharifNo ratings yet
- Classification and Regression Trees (CART)Document6 pagesClassification and Regression Trees (CART)Pravin PanduNo ratings yet
- 05 ZeroR OneR Bayes KNNDocument76 pages05 ZeroR OneR Bayes KNNsidra shafiqNo ratings yet
- 7-Decision Trees LearningDocument51 pages7-Decision Trees Learningyshu1No ratings yet
- Decision Trees Example ProblemDocument1 pageDecision Trees Example ProblemMuneeb ButtNo ratings yet
- 3.1 C 4.5 Algorithm-19Document10 pages3.1 C 4.5 Algorithm-19nayan jainNo ratings yet
- Decision Trees For Classification - A Machine Learning Algorithm - XoriantDocument4 pagesDecision Trees For Classification - A Machine Learning Algorithm - Xoriantmaanav8098No ratings yet
- Module 4 Question Bank: Big Data AnalyticsDocument2 pagesModule 4 Question Bank: Big Data AnalyticsKaushik KapsNo ratings yet
- Practice Q Machine Learning AnsDocument54 pagesPractice Q Machine Learning Ansgauravyadav24022004No ratings yet
- Machine LearningDocument52 pagesMachine LearningaimahsiddNo ratings yet
- Legaspi Ai2333Document7 pagesLegaspi Ai2333Jher MolledaNo ratings yet
- Lec 3&4Document20 pagesLec 3&4Hariharan RavichandranNo ratings yet
- ML - Unit 2Document15 pagesML - Unit 2HamsiNo ratings yet
- Id 3Document1 pageId 3vuhp1000No ratings yet
- Part Five - Extra PDFDocument27 pagesPart Five - Extra PDFNashowan100% (1)
- MLT NotesDocument66 pagesMLT NotesAryan RajNo ratings yet
- Dataset 1 and 2Document1 pageDataset 1 and 2shirisha gowdaNo ratings yet
- ML Unit-2 Material WORDDocument25 pagesML Unit-2 Material WORDafreed khanNo ratings yet
- Decision Trees CLSDocument43 pagesDecision Trees CLSAshish TiwariNo ratings yet
- First Rule - Major RuleDocument3 pagesFirst Rule - Major RuleErik LampeNo ratings yet
- Machine Learning Notes - Lec 04 - Decision Tree LearningDocument108 pagesMachine Learning Notes - Lec 04 - Decision Tree LearningZara JamshaidNo ratings yet
- Decision - TreeDocument75 pagesDecision - Tree727721eucs170No ratings yet
- Decision TreeDocument5 pagesDecision TreePriyanka pawarNo ratings yet
- AT3 - Decision Tree ExampleDocument17 pagesAT3 - Decision Tree ExampleramadeviNo ratings yet
- Classification: Decision TreesDocument30 pagesClassification: Decision TreesAshish TiwariNo ratings yet
- Outlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoDocument1 pageOutlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoHarshali PatilNo ratings yet
- AiML 4 3Document59 pagesAiML 4 3Nox MidNo ratings yet
- Aiml Assignment 2Document2 pagesAiml Assignment 2Gem StonesNo ratings yet
- Association Rules L3Document5 pagesAssociation Rules L3u- m-No ratings yet
- BAR AssignmentDocument8 pagesBAR AssignmentAkash KumarNo ratings yet
- Lecture 19 - Decision TressDocument21 pagesLecture 19 - Decision Tressbscs-20f-0009No ratings yet
- Decision TreesDocument28 pagesDecision TreesVijay kumar Gupta .C100% (6)
- Data Mining: Classification-1Document53 pagesData Mining: Classification-1Nirmal RNo ratings yet
- Saad Assign 1 AIDocument6 pagesSaad Assign 1 AIMalik RohailNo ratings yet
- ID3 Lecture4Document25 pagesID3 Lecture4jameelkhalidalanesyNo ratings yet
- Intro To Machine LearningDocument15 pagesIntro To Machine Learningharrisondaniel0415No ratings yet
- Data Mining All SlidesDocument206 pagesData Mining All SlidesAmanat ConstructionNo ratings yet
- (Lec 6) Decision Tree MLDocument26 pages(Lec 6) Decision Tree MLMuhtasim Jawad NafiNo ratings yet
- DM Chap4 Classification - IIIDocument60 pagesDM Chap4 Classification - IIIEngin ÖnerNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument3 pagesNaïve Bayes Classifier AlgorithmHead Of Department Computer Science and EngineeringNo ratings yet
- Assignment 2 Updated AIMLDocument2 pagesAssignment 2 Updated AIMLVismitha GowdaNo ratings yet
- Laboratory 1 Intro To Machine Learning 1Document3 pagesLaboratory 1 Intro To Machine Learning 1Emmanuel AncenoNo ratings yet
- AiML 4 3 SGDocument59 pagesAiML 4 3 SGngNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument10 pagesNaïve Bayes Classifier Algorithmbhavana vashishthaNo ratings yet
- Vocab in Use - WeatherDocument3 pagesVocab in Use - WeatherAhmet BülbülNo ratings yet
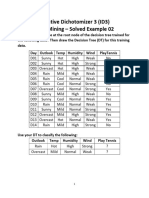
- DM DT Solved Example 02 - UnlockedDocument3 pagesDM DT Solved Example 02 - UnlockedJawaher AlbaddawiNo ratings yet
- Lec5 ActivitiesDocument1 pageLec5 Activitiestin nguyenNo ratings yet
- Decision Trees Classification: Mustafa JarrarDocument46 pagesDecision Trees Classification: Mustafa Jarrarrferreira85No ratings yet
- Module 3-Decision Tree LearningDocument33 pagesModule 3-Decision Tree Learningramya100% (1)
- Data Mining: Practical Machine Learning Tools and TechniquesDocument111 pagesData Mining: Practical Machine Learning Tools and TechniquesHenry YugoNo ratings yet
- Module 3 DecisionTree NotesDocument14 pagesModule 3 DecisionTree NotesManas HassijaNo ratings yet
- 4 Bn-EnDocument25 pages4 Bn-EnhạnhNo ratings yet
- A Kid's Guide to Weather Forecasting - Weather for Kids | Children's Earth Sciences BooksFrom EverandA Kid's Guide to Weather Forecasting - Weather for Kids | Children's Earth Sciences BooksNo ratings yet
- Sop For H3i Nefpa Simo To Mimo 251 - V1.0-JabotabekDocument14 pagesSop For H3i Nefpa Simo To Mimo 251 - V1.0-JabotabekAril GozaliNo ratings yet
- A Brief Note On Plants of Medicinal Importance To LivestockDocument84 pagesA Brief Note On Plants of Medicinal Importance To LivestockSunil100% (1)
- Contec CMS800G - User Manual PDFDocument31 pagesContec CMS800G - User Manual PDFDea GarNo ratings yet
- Lesson 4 - Visual Art and Its PurposeDocument6 pagesLesson 4 - Visual Art and Its PurposeMae CherryNo ratings yet
- Chemistry 10th Edition Whitten Test BankDocument12 pagesChemistry 10th Edition Whitten Test BankEdwinMyersbnztx100% (64)
- English Week 7 Spoken Text Quarter 1 PDFDocument32 pagesEnglish Week 7 Spoken Text Quarter 1 PDFsimaNo ratings yet
- Dir. Master File-NewDocument436 pagesDir. Master File-NewassmexellenceNo ratings yet
- 04 Prescription InterpretationDocument32 pages04 Prescription InterpretationBalsam Zahi Al-HasanNo ratings yet
- Starcraft - (1999) Hybrid - Chris Metzen PDFDocument10 pagesStarcraft - (1999) Hybrid - Chris Metzen PDFHawk RangerNo ratings yet
- TridentDocument24 pagesTridentPrajod ThiruvambattilNo ratings yet
- Jessica's C.VDocument2 pagesJessica's C.Vjess115No ratings yet
- Worksheets On Maxima & Minima (22!09!15)Document1 pageWorksheets On Maxima & Minima (22!09!15)ib elite tutorNo ratings yet
- 2014Document106 pages2014Gokul100% (1)
- SUMMATIVE TEST 1 (Quarter 3 Science 7) A4 SIZEDocument6 pagesSUMMATIVE TEST 1 (Quarter 3 Science 7) A4 SIZEZayn Daniel World of GamesNo ratings yet
- Ra 9288 Basis For Questionnaire PDFDocument22 pagesRa 9288 Basis For Questionnaire PDFHolden Mandapat ValdezNo ratings yet
- Command Center Processing and Display System ReplacementDocument2 pagesCommand Center Processing and Display System ReplacementImranNo ratings yet
- PercentagesDocument10 pagesPercentagesSinthuja KNo ratings yet
- Suryaputhran Sasidharan CVDocument4 pagesSuryaputhran Sasidharan CVSuryaputhran SasidharanNo ratings yet
- Syllabus: Cambridge Igcse First Language EnglishDocument52 pagesSyllabus: Cambridge Igcse First Language EnglishNdache PermataNo ratings yet
- Modul 9 B Inggris Kelas 4 - KD 3.9 - 4.9 PDFDocument16 pagesModul 9 B Inggris Kelas 4 - KD 3.9 - 4.9 PDFFendi SetiyantoNo ratings yet
- CV Hamza SadrijaDocument3 pagesCV Hamza SadrijaHamza SadrijaNo ratings yet
- Salesforce Pages Developers GuideDocument810 pagesSalesforce Pages Developers GuideanynameNo ratings yet
- GSX R600k7e3 PDFDocument104 pagesGSX R600k7e3 PDFAdolfoNo ratings yet
- For Which Value Of, Will The Lines Represented by The Following Pair of Linear Equations Be ParallelDocument54 pagesFor Which Value Of, Will The Lines Represented by The Following Pair of Linear Equations Be ParallelAmit SinghNo ratings yet
- Phosphoric Acid Industry - Problems & SolutionsDocument18 pagesPhosphoric Acid Industry - Problems & SolutionsRiyasNo ratings yet
- KFC225 Operating HandbookDocument25 pagesKFC225 Operating HandbooksunaryaNo ratings yet
- Ffi Ffiq D (,: Rie Frncfusru'QDocument25 pagesFfi Ffiq D (,: Rie Frncfusru'QShubham DNo ratings yet