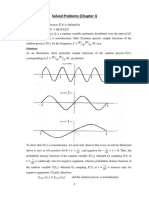
Download as pdf or txt
You might also like
- 5 - WQU - 622 CTSP - M5 - CompiledContentDocument34 pages5 - WQU - 622 CTSP - M5 - CompiledContentJoe NgNo ratings yet
- Com Solved Proble4ms IDocument6 pagesCom Solved Proble4ms INatyBNo ratings yet
- Autoregressive Processes Backshift Operator and ACFDocument7 pagesAutoregressive Processes Backshift Operator and ACFSrikanth ShenoyNo ratings yet
- 3 - WQU - 622 CTSP - M3 - CompiledContentDocument31 pages3 - WQU - 622 CTSP - M3 - CompiledContentJoe Ng100% (1)
- 872-892 Chapter 11Document26 pages872-892 Chapter 11kahinaNo ratings yet
- 1.2 Discrete-Time Random Processes: 1.2.1 Sample Spaces and EventsDocument7 pages1.2 Discrete-Time Random Processes: 1.2.1 Sample Spaces and EventsÖmer Faruk DemirNo ratings yet
- Rolle, MVT TheoremDocument16 pagesRolle, MVT Theorem01795494168nazmulhasanNo ratings yet
- VL2018199000767 Da02Document2 pagesVL2018199000767 Da02mounish sagarNo ratings yet
- Stationarity Examples White Noise Random Walks and Moving AveragesDocument5 pagesStationarity Examples White Noise Random Walks and Moving AveragesEmilio ZuluagaNo ratings yet
- Assignment 4&5Document3 pagesAssignment 4&5ARAVIND ELANo ratings yet
- Power Analysis in Alternating CurrentDocument20 pagesPower Analysis in Alternating CurrentGlenn VirreyNo ratings yet
- Continuous Probability DistributionsDocument7 pagesContinuous Probability DistributionsAlaa FaroukNo ratings yet
- Std-EEE F 342 - Mod-3 - L 20 To 22 (AC Modelling)Document48 pagesStd-EEE F 342 - Mod-3 - L 20 To 22 (AC Modelling)DEEPIKA PANTNo ratings yet
- 0512.3543.2022a1 SolDocument8 pages0512.3543.2022a1 SolSapir HarelNo ratings yet
- Vasin 2020Document7 pagesVasin 2020Chatchawan PanraksaNo ratings yet
- Week 1 - Slides WhiteDocument72 pagesWeek 1 - Slides WhiteEmilio ZuluagaNo ratings yet
- Network Capacitance Designing SynthesisDocument2 pagesNetwork Capacitance Designing Synthesisashish_soni234No ratings yet
- Synthesis AerodynamicsDocument12 pagesSynthesis AerodynamicsMarcoNo ratings yet
- Ajms 482 23Document7 pagesAjms 482 23BRNSS Publication Hub InfoNo ratings yet
- ARMA Properties and A Little TheoryDocument5 pagesARMA Properties and A Little Theoryjainaastha28_1951858No ratings yet
- Controllability For A Wave Equation With Moving BoundaryDocument7 pagesControllability For A Wave Equation With Moving Boundary37 TANNUNo ratings yet
- AnalysisDocument11 pagesAnalysisNISHANK KANSARANo ratings yet
- REVISIONDocument8 pagesREVISIONBún CáNo ratings yet
- NCS21 - 03 - Describing Function Analysis - 03Document4 pagesNCS21 - 03 - Describing Function Analysis - 03zain khuramNo ratings yet
- TS PartIIDocument50 pagesTS PartIIأبوسوار هندسة100% (1)
- Lecture 2 WavesDocument7 pagesLecture 2 WavesMessiah GamingNo ratings yet
- Vector Fields As Differential OperatorsDocument3 pagesVector Fields As Differential OperatorsSpud CrowleyNo ratings yet
- Math ExamDocument9 pagesMath ExamMalik AsadNo ratings yet
- H Optimization and H Infinity OptimizationDocument13 pagesH Optimization and H Infinity OptimizationKenneth LandichoNo ratings yet
- SDFSDFSDDocument5 pagesSDFSDFSDElyssa JaneNo ratings yet
- ECEN 214 Lab 8Document8 pagesECEN 214 Lab 8Shoaib AhmedNo ratings yet
- Laplace Transforms For PBL - P2027Document4 pagesLaplace Transforms For PBL - P2027Jean Orveil PAMBOUNo ratings yet
- MATH 1023/1024 Lecture Notes Chapter 4 - Riemann Integrals: Hong Kong University of Science and Technology July 29, 2023Document5 pagesMATH 1023/1024 Lecture Notes Chapter 4 - Riemann Integrals: Hong Kong University of Science and Technology July 29, 2023Taylor ZhangNo ratings yet
- Lecture 9Document7 pagesLecture 9Milind BhatiaNo ratings yet
- Lab 3Document7 pagesLab 3ARSLAN HAIDERNo ratings yet
- Signals and Systems: DR Tania StathakiDocument20 pagesSignals and Systems: DR Tania StathakikentNo ratings yet
- Sampling Process and TheoremsDocument15 pagesSampling Process and TheoremsIzzat AzmanNo ratings yet
- Laplace InverseDocument3 pagesLaplace InversemarwanNo ratings yet
- Laplace TransformDocument28 pagesLaplace TransformLoku VelNo ratings yet
- 1.5 Vector AlgebraDocument8 pages1.5 Vector Algebra七海未来No ratings yet
- Integral Calculus NotesDocument43 pagesIntegral Calculus NotesArjay S. Bazar100% (1)
- Assignment 5Document4 pagesAssignment 5Daniyal MasoodNo ratings yet
- A New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayDocument6 pagesA New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayWaj DINo ratings yet
- Laplace and Z-TransformsDocument23 pagesLaplace and Z-TransformsHussam AliraqiNo ratings yet
- Chapter 3 - Control System ModellingDocument21 pagesChapter 3 - Control System ModellingMustafa ManapNo ratings yet
- EEE 3153-Control System: Lecture-On State Space Modeling & AnalysisDocument42 pagesEEE 3153-Control System: Lecture-On State Space Modeling & AnalysisShojeb ShojolNo ratings yet
- Continuous Probability Distribution.Document10 pagesContinuous Probability Distribution.Hassan El-kholy100% (1)
- EC-1 Assignment 1 (22-S1) - Solution Walkthro (27 Aug 2022)Document5 pagesEC-1 Assignment 1 (22-S1) - Solution Walkthro (27 Aug 2022)Vipul PatilNo ratings yet
- Solution of Quasi OneDocument4 pagesSolution of Quasi OneEdwin TomNo ratings yet
- CE50p ProjectDocument5 pagesCE50p ProjectEarl TuazonNo ratings yet
- Laplace Transform PDFDocument34 pagesLaplace Transform PDFمنتظر احمد حبيترNo ratings yet
- Univariate Time Series Model NotesDocument16 pagesUnivariate Time Series Model NotesTrần Việt HằngNo ratings yet
- Applications of Differential CalculusDocument2 pagesApplications of Differential Calculuslouise.hippyNo ratings yet
- Low Pass & High Pass Pi Section Filter Lab ManualDocument17 pagesLow Pass & High Pass Pi Section Filter Lab ManualRiya MaityNo ratings yet
- Pgmath2023 SolutionsDocument3 pagesPgmath2023 Solutionspublicacc71No ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Newbold Chapter 7Document62 pagesNewbold Chapter 7AshutoshNo ratings yet
- (Anas+Osho+Umar) Food Price InflationDocument13 pages(Anas+Osho+Umar) Food Price InflationAnas IbrahimNo ratings yet
- College of Economics and Social Sciences Tutorial 2Document4 pagesCollege of Economics and Social Sciences Tutorial 2khairul amirNo ratings yet
- Improved Comparison of Ili Data and Field ExcavationsDocument4 pagesImproved Comparison of Ili Data and Field ExcavationsEfvan Adhe Putra PradanaNo ratings yet
- A Tutorial On Stochastic Programming PDFDocument35 pagesA Tutorial On Stochastic Programming PDFmzbloguerNo ratings yet
- F-Test Testing of HypothesisDocument22 pagesF-Test Testing of HypothesisSankalp PanchalNo ratings yet
- Variance Reduction Techniques in Monte Carlo Methods: SSRN Electronic Journal November 2010Document19 pagesVariance Reduction Techniques in Monte Carlo Methods: SSRN Electronic Journal November 2010Mayank SinghNo ratings yet
- ECON1203 PASS Week 3Document4 pagesECON1203 PASS Week 3mothermonkNo ratings yet
- Simple and Multiple Regression AnalysisDocument48 pagesSimple and Multiple Regression AnalysisUmair Khan NiaziNo ratings yet
- The Moment Generating Function of The Binomial Distribution: Msc. Econ: Mathematical Statistics, 1996Document3 pagesThe Moment Generating Function of The Binomial Distribution: Msc. Econ: Mathematical Statistics, 1996Behin SamNo ratings yet
- Parametric and Non-Parametric TestsDocument2 pagesParametric and Non-Parametric TestsM S Sridhar100% (1)
- AS-Statistics-Facts-and-Definitions-Quiz Answers PT 1Document2 pagesAS-Statistics-Facts-and-Definitions-Quiz Answers PT 1cokonkwoNo ratings yet
- BBA (Statistics) - Imp QuesDocument4 pagesBBA (Statistics) - Imp Quesnidhi dubeyNo ratings yet
- Notes From preMBA StatsDocument4 pagesNotes From preMBA StatsMadhura BanerjeeNo ratings yet
- Density EstimationDocument17 pagesDensity EstimationGraciela MarquesNo ratings yet
- Applied Econometrics With RDocument5 pagesApplied Econometrics With RSebastian GuatameNo ratings yet
- Proc MI and Proc MianalyzeDocument11 pagesProc MI and Proc MianalyzepritishzNo ratings yet
- Autoregressive ModelsDocument57 pagesAutoregressive ModelsDang Khoa NgoNo ratings yet
- Chapter 2Document31 pagesChapter 2Pesala WelangalleNo ratings yet
- Fandi Ct6 201009 Exam FinalDocument6 pagesFandi Ct6 201009 Exam FinalKeithNo ratings yet
- Slides, Modelos Arima Dr. BanegasDocument57 pagesSlides, Modelos Arima Dr. BanegasByron Alexis Palazzi SalinasNo ratings yet
- Test DuncanDocument9 pagesTest DuncanCodrutaNo ratings yet
- DataDocument11 pagesDataLAKSHMI JNo ratings yet
- PROBABILITY It Is A Numerical Measure Which Indicates The ChanceDocument20 pagesPROBABILITY It Is A Numerical Measure Which Indicates The ChancePolice stationNo ratings yet
- Statistical Sample: Noor Faizah Binti ZohardinDocument9 pagesStatistical Sample: Noor Faizah Binti ZohardinNajib SharilNo ratings yet
- One-Way ANOVADocument41 pagesOne-Way ANOVASyarifah Shameerah AlJunidNo ratings yet
- Module 5: Peer Reviewed Assignment: OutlineDocument55 pagesModule 5: Peer Reviewed Assignment: OutlineAshutosh KumarNo ratings yet
- ADC Unit 3Document26 pagesADC Unit 3Alok kumarNo ratings yet
- Modern Psychometrics With R - Patrick MairDocument464 pagesModern Psychometrics With R - Patrick MairRicardo Narváez89% (9)
- Statistical Intervals.: INEN 5320 Statistical Decision Making Dr. Alberto Marquez Lamar UniversityDocument20 pagesStatistical Intervals.: INEN 5320 Statistical Decision Making Dr. Alberto Marquez Lamar UniversityVamsi KrishnaNo ratings yet